毕方智能云沙箱
一、目标问题与意义价值
1.1 恶意软件
恶意软件是指为达成某种恶意目的而编写的可执行程序,包括病毒、蠕虫和特洛伊木马。其中勒索软件给社会造成了严重影响,勒索软件主要采用邮件钓鱼、账号爆破和漏洞利用等方式攻击企业、政府和教育等中大型政企机构,从中牟取暴利。同时,恶意软件的数量也在逐年增加,如2020年,安全社区已知的恶意可执行软件的数量已经超过11亿,而且这个数字可能还会持续增长。造成恶意软件数量增加的原因有以下三点:
- 随着网络技术的高速发展,恶意软件的传播途径也越来越多,如下载盗版电影、搜索热话题和安装来路不明的防病毒软件等。
- 自动化恶意软件生成工具的滥用导致恶意软件变体数量的增多。
- 恶意软件犯罪团伙逐渐形成规模化的商业运行,形成新的恶意软件合作生态。
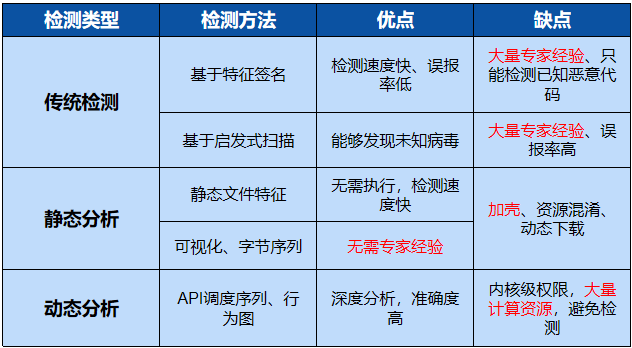
目前恶意软件检测方法对比如下:
1.2 恶意软件造成的财富损失
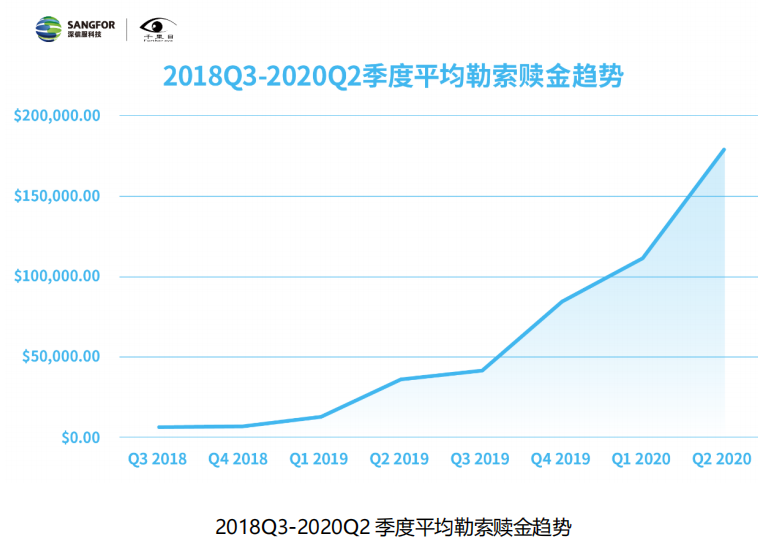
随着全球信息化的飞速发展,整个国家和社会对网络的依赖程度也越来越大,网络已经成为社会和经济发展的强大推动力。其中网络面临的各种威胁,防范和消除这些威胁变的越来越重要。报告统计2022年国内网络安全市场规模预计达到759.27亿元。从2021开年到现在,已有近30家安全企业宣布完成融资,其中基于人工智能技术的新兴公司别受青睐,悬镜安全、墨云科技、微步在线、观安信息、数美科技等基于人工智能赋能安全领域的公司均融资逾亿元。其中微步在线专注于威胁情报领域,凭借其优秀的威胁分析能力和威胁情报数据能力融资5亿元。所以目前对于类似智能云沙箱的威胁分析平台需求极大,有很高的市场价值。
恶意软件的检测是威胁分析中的一个重要问题,尤其是随着社会越来越依赖于计算机系统。恶意软件的单一事件已经可以造成数百万美元的损失。反病毒产品提供了一些针对恶意软件的保护,但对这个问题越来越无效。沙箱作为重要的恶意软件分析工具使用基于签名的检测方法,其中签名根据大量专家经验来手动构建的规则使得传统沙箱无法识别未知的恶意软件。
尽管勒索软件约占恶意软件总事件的3%,,但相比其他恶意软件破坏力更大,一旦遭遇勒索,企业将面临业务中断、高额赎金的风险。根据 Coveware 的数据显示,与 2019 年相比,2020 年第二季度的赎金要求同比增加了 4 倍。
1.3 沙箱
沙箱的介绍
沙箱(sandbox)在计算机领域指一种虚拟技术,且多用于计算机安全技术。安全软件可以先让它在沙盒中运行。沙箱中的所有改动对操作系统不会造成任何损失。通常这种技术被计算机技术人员广泛使用,尤其是计算机反病毒行业,沙箱是一个观察计算机病毒的重要环境。影子系统即是利用了这种技术的软件之一。沙箱早期主要用于测试可疑软件等,比如黑客们为了试用某种病毒或者不安全产品,往往可以将它们在沙箱环境中运行。经典的沙箱系统的实现途径一般是通过拦截系统调用,监视程序行为,然后依据用户定义的策略来控制和限制程序对计算机资源的使用,比如改写注册表,读写磁盘等。
沙箱的工作原理
沙箱的工作原理为通过重定向技术,把程序生成和修改的文件,定向到本身的文件夹中。这也包括数据的变更,包括注册表和一些系统的核心数据。通过加载自身的驱动来保护底层数据,属于驱动级别的保护。如果我们用沙箱来测试病毒的,在里面运行病毒可以说也是安全操作。所以,绝大多数的病毒软件都有沙箱的功能。
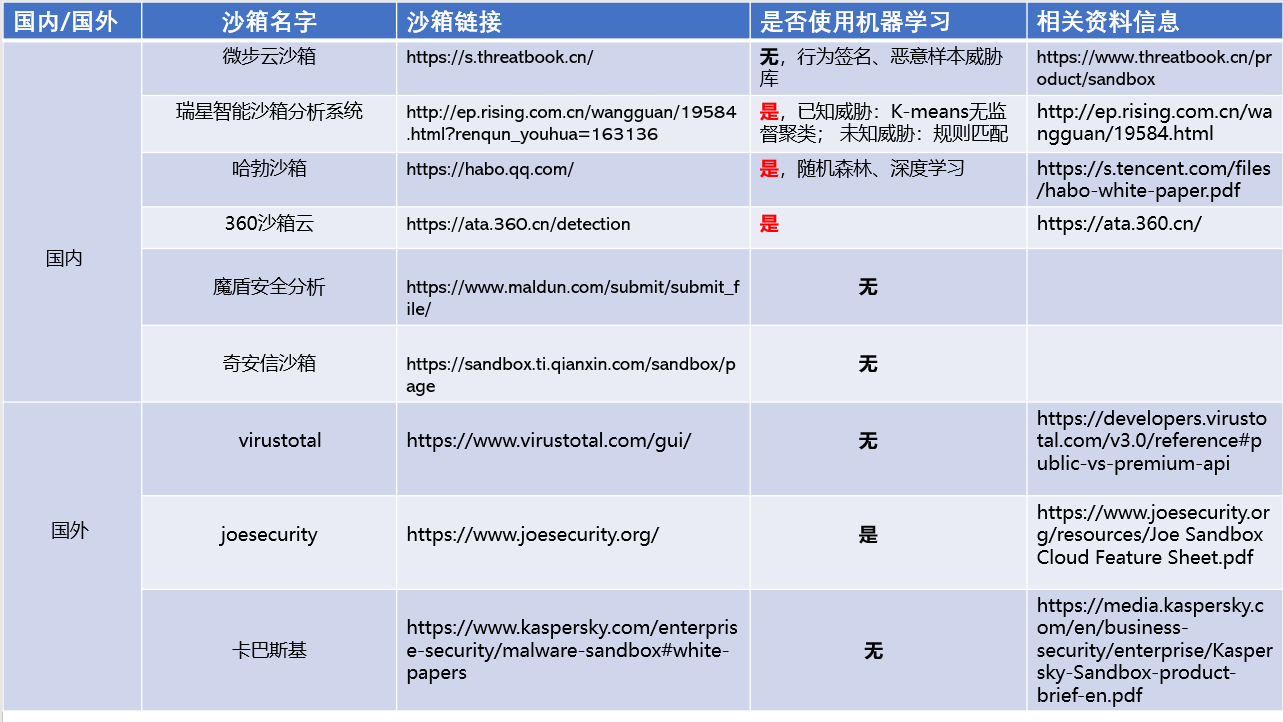
1.4 沙箱深度调研对
国内外基于机器学习安全产品现在如下:
二、设计思路与方案
阐述作品解决问题的主要设计思路与技术路线,以及详细的设计方案。
2.1 内容设计
2.1.1 核心组成部分
-
主机(一台):系统的核心服务器端,运行着云沙箱的核心组件,负责恶意软件分析任务的启动和分析结果报告的生成,同时负责管理多个客户机。
-
客户机(若干):多个独立的隔离环境(即多台虚拟机),负责提供虚拟环境供恶意软件样本运行,同时检测目标样本的运行情况,并将检测到的数据反馈给主机。
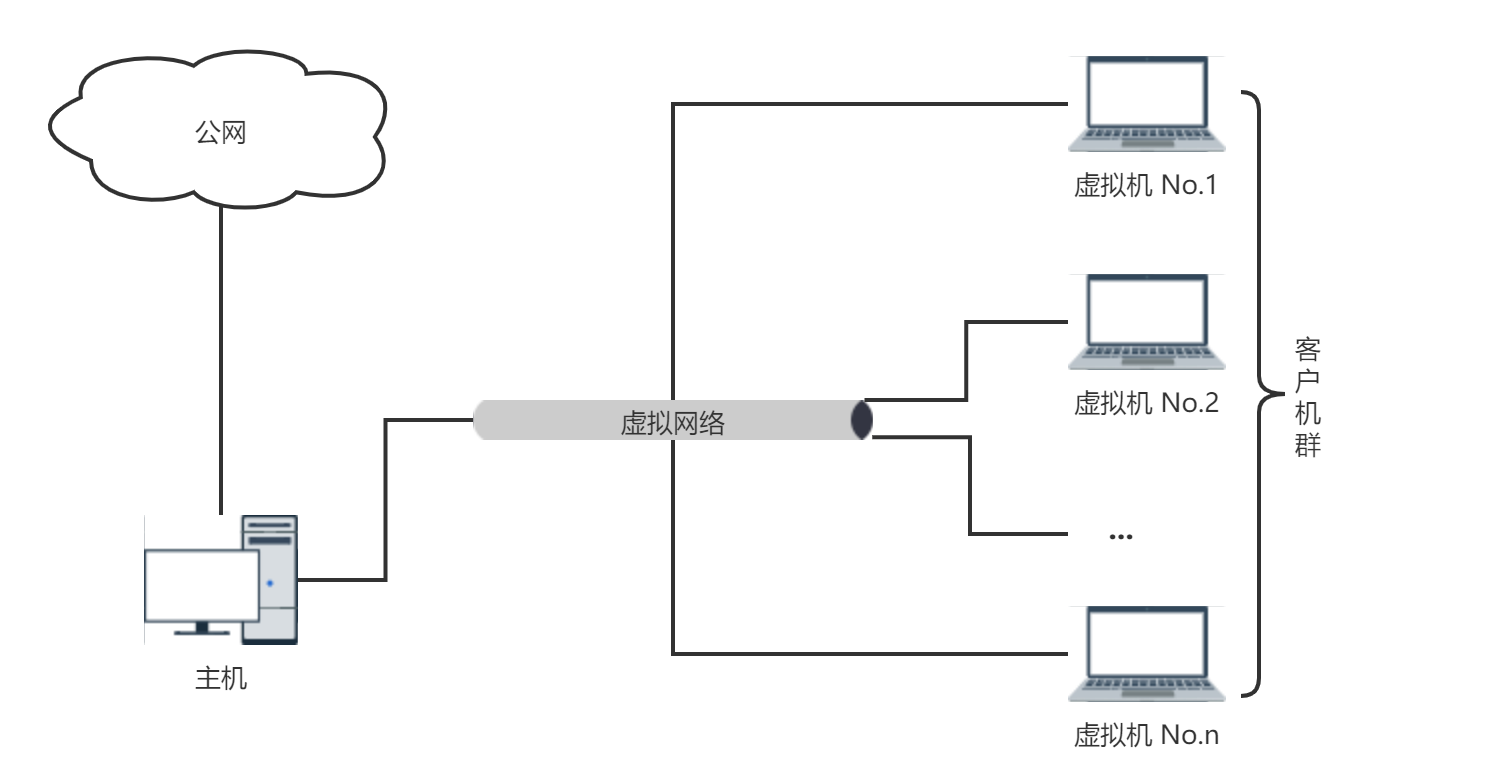
2.1.2 系统架构图
主机和客户机之间通过虚拟网络连接,多个客户机与主机共同组成一个局域网
2.1.3 系统部署环境
| 名称 | 版本 |
|---|---|
| 主机 | 16.04 |
| 客户机 | Windows XP(32-bits) |
| Django | 1.8.4 |
| Python | 2.7 |
| … | … |
2.1.4 工作目录
工作目录CWD(Contain Working Directory)存放程序所有使用的文件(代理、分析脚本、配置文件、日志、注入程序、签名、结果目录、Web设置、白名单、Yara规则和MongoDB数据库等),其CWD内容如下:
- agent代理文件
- agent.py
- analyzer文件分析脚本
- windows
- android (可扩展)
- linux (可扩展)
- conf配置文件
- auxiliary.conf 辅助模块
- cuckoo.conf 沙箱主机
- processing.conf 结果处理模块
- detection.conf 机器学习模块
- reporting.conf 报告生成模块
- virualbox.conf 虚拟机管理软件
- log 日志
- monitor 进程注入的DLL
- signatures 签名
- models 模型
- 静态特征
- string.model
- malconv.model
- 动态特征
- apistats.model
- storage
- analyses
- task_id 结果目录
- 结果容器
- report
- web 前端配置文件
- whitelist 白名单
- yara yara规则
- cuckoo.db 数据库
2.1.5 功能列表
文件对象
数据集描述
- 数据说明:本数据集提供了一组已知的恶意代码文件,它们代表9个不同的家族。每个恶意代码文件都有一个 Id(唯一标识文件的散列值)和一个类别标记(恶意代码可能属于的9个家族之一)。
- 数据类型:对于每个恶意代码文件,分别存在两种格式
- 原始数据文件(.bytes),包含文件二进制内容的十六进制表示,没有PE头(以确保不可执行)
- 元数据清单日志(.asm),包含从二进制文件中提取的各种元数据信息,如函数调用、字符串等
- 数据分布
-
数据说明:本数据集来自每天从现网捕获的大量挖矿型恶意代码和非挖矿型恶意代码,经过数据清洗、代码相似性分析等方法对样本进行处理,并已抹去样本PE结构中的MZ头、PE头、导入导出表等区域。
-
数据类型:对于每个恶意代码,提供包含文件二进制内容的原始数据文件
-
数据分布
pie title Mining Malware - 6000 entries "Mining": 2000 "Non-mining": 4000
检测信息
1)辅助信息
| 辅助模块名称 | 辅助模块功能 |
|---|---|
| sniffer | 负责执行tcpdump以转储沙箱样本分析过程中生成的网络流量 |
2)结果信息
| 处理模块名称 | 处理木模块功能 |
|---|---|
| Analysisinfo | 生成当前分析的一些基本信息,例如时间戳、沙箱的版本等 |
| BehaviorAnalysis | 解析原始行为日志并执行一些初始转换和解释,包括完整的流程跟踪、行为摘要和流程树 |
| Buffer | 丢弃缓冲区分析 |
| Debug | 包括错误和analysis.log由文本分析模块生成 |
| Dropped | 恶意软件丢弃文件的信息 |
| Memory | 在内存上执行 Volatility 工具 |
| NetworkAnalysis | 解析PCAP文件并提取一些网络信息,例如DNS流量、域、ip、HTTP请求、IRC和SMTP流量 |
| Screenshots | 屏幕截图 |
| StaticAnalysis | 对文件执行一些静态分析 |
| String | 从分析的二进制文件中提取字符串 |
| TargetInfo | 包括有关分析文件的信息,如哈希,ssdeep等 |
| VirusTotal | 搜索VirusTotal.com分析文件的防病毒签名 |
核心检测方法
1)签名检测(500+开源签名)
| 签名名称 | 签名描述 |
|---|---|
| antidbg_windows | 检查是否存在来自调试器和取证工具的已知窗口 |
| generic_metrics | 使用GetSystem |
| modifies_wallpaper | 尝试修改桌面墙纸 |
| … | … |
2)Yara匹配
| 类型 | 内容 |
|---|---|
| braries | 恶意软件类yara规则 |
| office | office文档类yara规则 |
| scripts | scripts类yara规则 |
| shellcode | shellcode类yara规则 |
| urls | url类yara规则 |
| Packers | 加壳类yara规则 |
| … | … |
3)基于机器学习的恶意软件模型
| 名称 | 类型 | 特征 | 算法模型 |
|---|---|---|---|
| Malconv | 静态分析 | 字节序列 | Malconv卷积神经网络 |
| String | 静态分析 | 字符串序列 | XGBoost集成学习模型 |
| API_gram | 动态分析 | API调用序列 | XGBoost集成学习模型 |
2.1.6 功能模块组成
| 模块名称 | 模块功能 |
|---|---|
| 辅助功能 | 定义了一些需要与每个分析过程并行执行的功能 |
| 机器交互 | 定义了与虚拟化软件的交互过程 |
| 文件分析 | 定义了在客户机环境中执行并分析给定的文件的过程 |
| 结果处理 | 定义了处理生成的原始分析结果的方法,并将一些信息附加到一个全局结果容器中 |
| 家族签名 | 定义了一些特定的"签名",用于表示特定的恶意行为模式或特征指标 |
| 机器学习 | 定义了一些基于机器学习的恶意软件检测模型,生成检测结果 |
| 报告生成 | 定义了将全局结果容器保存格式,并存储到数据库中 |
| 用户交互 | 定义了用户的提交样本和样本报告显示形式 |
2.1.7 沙箱运行流程
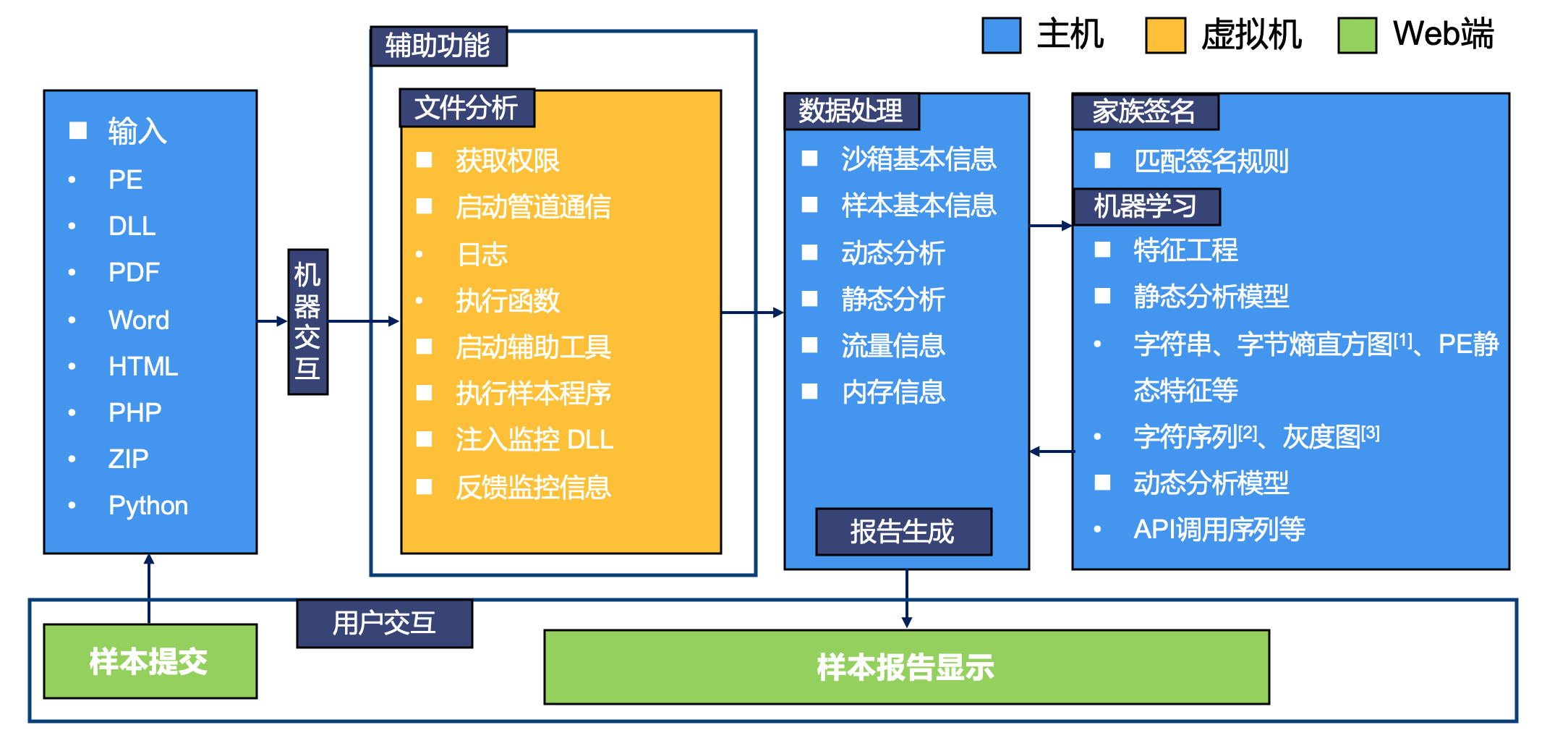
2.2 功能全景图
核心函数调用流程如下所示:
高清图下载
https://pan.baidu.com/s/1VH9RjcjwDEDqnus6lm5hlQ 提取码: s2xb
三、方案实现
3.1 开发环境配置
3.1.1 Python环境配置
在使用到一些全新的Python库之后,代码的开发和测试流程与以前相比略有不同。由于在首次使用Bold-Falcon之前必须先进行安装,这使得常规的"修改——测试"的迭代开发过程无法像以前一样独立进行。 下面我们将概述如何在使用Bold-Falcon的同时开发和测试新的特性。
-
初始化一个新的虚拟环境。考虑到放置在
/tmp目录下的虚拟环境在重启后便不会继续保存,因此可以设置一个单独的存储目录路径,例如,~/venv/bold-falcon-development(即用于在通用的~/venv目录下为所有的虚拟环境设置一个名为bold-falcon-development的存储子目录)。$ virtualenv /tmp/bold-falcon-development -
激活该虚拟环境。该操作必须在每次启动新的shell会话时完成(除非将该命令放入
~/.bashrc或者类似的配置文件中)。$ . /tmp/bold-falcon-development/bin/activate -
为了创建一个Bold-Falcon分发包,需要从社区库中获取一些匹配监控二进制文件。这里我们提供了一个简单易用的脚本来半自动地执行这一操作。通过在当前库的根目录下按以下方式运行,即可自动获取上述二进制文件。
(bold-falcon-development)$ python stuff/monitor.py -
在开发者模式下安装Bold-Falcon,在执行期间将使用当前目录下的相关文件。
(bold-falcon-development)$ python setup.py sdist develop
完成以上步骤后,现在可以修改和测试代码文件了,代码文件位于Bold-Falcon目录下。实际上,即使是对当前库的开发版本进行测试,Cuckoo Working Directory和Cuckoo Working Directory Usage中的所有规则仍然有效。
3.1.2 Pycharm环境配置
在这一节中,我们将在Bold-Falcon开发的背景下介绍大量的Pycharm配置选项,并尝试在Pycharm IDE下开展Bold-Falcon的运行和开发任务。
网页端界面
本节会介绍基于Django框架运行的Bold-Falcon网页端界面。这一部分的代码修改以及自定义特性的新增工作比较容易。
路径和概念
- Bold-Falcon网页端提供了Web接口和RESTAPI
- Django项目根目录位于
Bold-Falcon/web - 配置位于
Bold-Falcon/web/web/settings.py - URL调度程序位于
Bold-Falcon/web/web/urls.py,以及其他路径下,包括但不限于Bold-Falcon/web/analysis/urls.py - HTML模板使用Django模板语言。
- 前端中与Bold-Falcon相关的JavaScript内容位于
Bold-Falcon/web/static/js/cuckoo/,其中源代码位于Bold-Falcon/web/static/js/cuckoo/src/目录下。 - 所谓的"控制器"用于代替基于类的视图,其中控制器负责不属于视图函数的操作(通常是后端)。例如:
Bold-Falcon/web/controllers/analysis/analysis.py - 视图函数是视图使用的函数,位于
routes.py。例如:Bold-Falcon/web/controllers/analysis/routes.py - API函数是API使用的函数,位于
api.py。例如:Bold-Falcon/web/controllers/analysis/api.py
运行和调试
直接使用PyCharm运行和调试Bold-Falcon,可以直接绕过Bold-Falcon启动程序并使用PyCharm的内置Django服务器,而且无需对源代码进行任何修改即可做到这一点。 首先,建议全程在虚拟环境中操作,从而将Bold-Falcon所需的依赖项与系统范围内安装的Python隔离开来。其次,建议在开发模式下安装Bold-Falcon. 假设Bold-Falcon成功安装(并且有一个正在使用的工作目录,参见Cuckoo Working Directory Installation);启动PyCharm并打开Bold-Falcon目录。选择Run->Edit Configurations并单击+,选择"Django服务器"。服务器配置使用下列参数值:
- Name - web
- Host - 127.0.0.1
- Port - 8080
- Environment variables -单击
...并增加CUCKOO_APP:web - Python interpreter - 选择之前配置的虚拟环境。如果该虚拟环境不存在,请使用
File->Settings->Project: Cuckoo->Project Interpreter将该虚拟环境添加到本项目中。 - Working directory -Django项目根目录的绝对路径,例如:
/home/test/PycharmProjects/virtualenv/Bold-Falcon/web/
此时,可以使用PyCharm运行和调试Bold-Falcon了,通过选择Run->Run->web即可启动网页端服务器。
JavaScript传输
Bold-Falcon前端中的Javascript代码是基于ECMAScript 6标准开发的。为了兼容浏览器,需要将它转回ECMAScript 5标准。 首先,配置PyCharm使其能够识别并理解ECMAScript 6的语法。选择File->Settings->Languages & Frameworks->Javascript并从"Javascript语言版本"下拉列表中选择"ECMAScript 6"。然后选择Apply. 然后,使用Babel传输Javascript代码。在Bold-Falcon项目根目录中安装Babel(需要npm):
(bold-falcon) test:$ pwd
/home/test/PycharmProjects/virtualenv/bold-falcon
(bold-falcon) test:$ npm install --save-dev babel-cl
它将在Bold-Falcon项目根目录下创建一个名为node_modules的文件夹。切换回PyCharm并打开cuckoo/web/static/js/cuckoo/src路径下的任意js文件,PyCharm将询问是否要为该文件配置一个文件监视程序。点击Add watcher(如果此选项不可用,请在File->Settings->Tools->File watchers下找到"file watcher"位置)。 在弹出屏幕"Edit Watcher"中,输入下列值:
- Name - Babel ES6->ES5
- Description - Transpiles ECMAScript 6 code to ECMAScript 5
- Output filters - None
- Show console - Error
- Immediate file synchronisation - yes
- Track only root files - yes
- Trigger watcher regardless of syntax errors - no
- File type - Javascript
- Scope - 单击
...->+(添加范围) ->local->OK. 在文件浏览器中,进入Bold-Falcon/web/static/js/cuckoo/src/目录下并选择src文件夹,单击include.src中的文件现在应该会变成绿色。选择OK. - Program - 应该是
node_modules/.bin/babel的绝对路径,例如:/home/test/PycharmProjects/virtualenv/cuckoo/node_modules/.bin/babel. 再次检查输入的路径是否反映文件node_modules/.bin/babel的实际位置。 - Arguments -
--source-maps --out-file $FileNameWithoutExtension$.js $FilePath$ - Working directory - 浏览并选择
Bold-Falcon/web/static/js/cuckoo - Output paths to refresh
$FileNameWithoutExtension$-compiled.js:$FileNameWithoutExtension$-compiled.js.map
最后,需要创建一个manage.py mock文件,以便PyCharm将其视为Django项目。文件Bold-Falcon/web/manage.py的内容如下:
#!/usr/bin/env python
import sys
if __name__ == "__main__":
from django.core.management import execute_from_command_line
execute_from_command_line(sys.argv)
转到File->Settings->Languages & Frameworks->Django,然后配置如下:
- Django Project root -
Bold-Falcon/web - Settings -
web/settings.py - Manage script -
manage.py
测试
到目前为止,项目配置已经完成,可以使用PyCharm运行和调试Bold-Falcon了!
3.2 辅助功能模块
3.2.1 实现说明
辅助功能模块定义了一些需要与每个样本分析过程并行执行的辅助功能,例如:记录并为用户提供分析样本的网络流量、中间人代理、客户端重启等辅助功能。全部辅助模块放在 Bold-Falcon/moduls/auxiliary/ 目录下,全部辅助模块配置选项在 Bold-Falcon/conf/auxiliary.conf 文件下。
1)辅助功能定义函数
from lib.cuckoo.common.abstracts import Auxiliary
class MyAuxiliary(Auxiliary):
"""定义辅助模块"""
def start(self):
# 定义辅助功能
def stop(self):
# 定义模块关闭
- start():将在主机启动客户机并有效执行提交的恶意文件之前执行
- stop():将在分析过程的最后以及启动处理和报告过程之前执行
2)辅助功能运行函数
class RunAuxiliary(object):
"""辅助模块管理"""
def __init__(self, task, machine, guest_manager):
# 辅助功能模块初始化
def start(self):
# 辅助功能模块配置
options = config2("auxiliary", module_name)
def callback(self, name, *args, **kwargs):
# 辅助功能模块加载
MyAuxiliary.start()
def stop(self):
# 辅助功能模块关闭
MyAuxiliary.stop()
- __init__(): 辅助功能模块初始化(任务号、虚拟机软件、客户机IP映射等)
- start(): 根据
Bold-Falcon/conf/auxiliary.conf下的配置选择辅助功能模块列表 - callback(): 开启辅助功能模块列表的辅助功能
- stop(): 关闭辅助功能模块列表的辅助功能
3)辅助功能列表
| 辅助模块名称 | 辅助模块功能 |
|---|---|
| sniffer | 负责执行tcpdump以转储沙箱样本分析过程中生成的网络流量 |
| mitm | 负责执行mitmdump以提供中间人代理功能 |
| reboot | 负责提供重启分析支持 |
3.2.2 实现流程
1) 辅助功能模块时序图
2)辅助功能模块实现流程
- 启动沙箱主机
- 初始化沙箱配置
- 辅助功能模块初始化
- 辅助功能模块加载
- 辅助功能模块开启
- 样本上传
- 样本分析
- 分析结果存储
- 辅助功能模块存储
- 辅助功能模块关闭
3.3 机器交互模块
3.3.1 实现说明
机器交互模块定义了沙箱主机与虚拟化软件的交互过程,包括开启虚拟机、启动任务调度、上传样本、上传分析模块和分析配置文件、在数据库中记录虚拟机的状态等操作。全部机器交互模块放在 Bold-Falcon/modules/mechinery/目录下,我们默认使用了VirtualBox虚拟机软件。全部辅助模块配置选项在 Bold-Falcon/conf/virualbox.conf文件下。
沙箱主机与客户机网络配置中使用Host-Only连接方式。对于一个恶意软件,当其被安装配置了Bold-Falcon的主机提交到各个客户机进行运行分析时,主机是想要知道客户机的所有流量信息的,因为绝大部分的恶意软件都需要依赖网络来执行恶意行为。此时只有设置Host-Only连接,主机才能截获客户机与互联网之间流经的所有流量,进而更好地分析恶意软件的行为方式。
1)机器交互定义函数
from lib.cuckoo.common.abstracts import Machinery
from lib.cuckoo.common.exceptions import CuckooMachineError
class MyMachinery(Machinery):
def start(self, label):
# 开启定义虚拟机管理软件
try:
revert(label)
start(label)
except SomethingBadHappens:
raise CuckooMachineError("oops!")
def initialize(self, module_name):
# 初始化配置信息
self._initialize(module_name)
def stop(self, label):
# 关闭定义虚拟机管理软件
try:
stop(label)
except SomethingBadHappens:
raise CuckooMachineError("oops!")
- start():开启定义虚拟机管理软件
- stop():关闭定义虚拟机管理软件
- initialize():根据指定的配置信息(标签、平台、IP等)生成可用客户机的列表
2)机器交互管理函数
class AnalysisManager(threading.Thread):
def __init__(self, task_id, error_queue):
# 读取任务的消息、配置文件中的服务端ip和端口
def init(self):
# 初始化分析, 创建分析结果存储目录
def acquire_machine(self):
# 开启配置虚拟机
def launch_analysis(self):
# 开启分析任务
self.init():
self.acquire_machine()
# 开启虚拟机如:machinery/virtualbox.py 中 VirtualBox.start
machinery.start(self.machine.label, self.task)
return succeeded
- __init__(): 读取任务的消息(指明分析时间、系统类型、开始时间、结束时间、指明分析状态);配置文件中的服务端ip和端口(我这里设置的是192.168.56.1和2042)
- init():创建文件夹, 用于存放分析结果和样本文件,将target指向的文件存放到
storage/binaries下 - acquire_machine(): 开启配置虚拟机
- launch_analysis(): 开启分析任务,各个模块的清理工作
3)客户端代理函数
Host和Client端的数据传输,客户端代理 agent.py 脚本在客户机运行
class MiniHTTPRequestHandler(SimpleHTTPServer.SimpleHTTPRequestHandler):
# 用作对不同路径的不同函数处理(响应)
server_version = "Cuckoo Agent"
def do_GET(self):
# 响应GET请求
def do_POST(self):
# 响应POST请求
# host与client之间的数据传输, 格式为multipart/form-data
- do_GET(): 响应GET请求
- do_POST():
- 响应POST请求
- host与client之间的数据传输, 格式为multipart/form-data,可以理解为key:value形式
- 如: analysis.conf, 分析模块, 样本等,这些数据在传输的时候, 都要带有filename字段
AGENT_VERSION = "0.10"
AGENT_FEATURES = [
"execpy", "pinning", "logs", "largefile", "unicodepath",
]
@app.route("/")
def get_index():
@app.route("/environ")
def get_environ():
@app.route("/mktemp", methods=["GET", "POST"])
def do_mktemp():
@app.route("/mkdtemp", methods=["GET", "POST"])
def do_mkdtemp():
@app.route("/extract", methods=["POST"])
def do_extract():
@app.route("/store", methods=["POST"])
def do_store():
@app.route("/execpy", methods=["POST"])
def do_execpy():
@app.route("/status")
def get_status():
-
get_index(): agent的一些基本信息
-
浏览器输入
192.168.56.2:8000返回:{"message": "Cuckoo Agent!", "version": "0.10", "features": ["execpy", "pinning", "logs", "largefile", "unicodepath"]}
-
-
get_environ(): 获取client端环境变量,以便后面后续的一些命令执行
-
do_mktemp() 和 do_mkdtemp()
- 两个创建临时文件夹的命令: mktemp和mkdtemp,但二者创建的位置不一样
- mkdtemp –> 在%SYSTEMDRIVE%(C:)下创建一个随机文件夹
- mktemp –> 在%TEMP%(C:\Users\bill\AppData\Local\Temp)下创建一个随机文件夹
-
do_extract(): 将分析模块以zip格式压缩,发送给client端;发送extrac命令, 将分析模块解压到上一步创建的文件夹中。
-
do_store():
- 执行store命令, 写入analysis.conf 到 C:/tmppx7scx/analysis.conf
analysis.conf 内容 category file target /tmp/cuckoo-tmp-pwnmelife/tmpZ3SA0v/maze.exe (host端的样本地址) package exe file_type PE32 executable (GUI) Intel 80386, for MS Windows file_name maze.exe clock 20200620T09:28:00 id 1 timeout 120 ip 192.168.56.1 port 2042 - 执行store命令, 写入simple.bin 到 C:\Users\bill\AppData\Local\Temp\simple.bin
-
do_execpy(): 执行分析脚本
-
get_status(): 不断获取样本分析状态
4)客户端管理函数
class GuestManager(object):
def __init__(self, vmid, ipaddr, platform, task_id, analysis_manager):
# 初始化信息
def stop(self):
# 关闭客户端分析
def upload_analyzer(self, monitor):
# 上传分析模块
def add_config(self, options):
# 上传分析脚本
def start_analysis(self, options, monitor):
# 客户端开启分析
self.upload_analyzer(monitor)
self.add_config(options)
# 执行store命令 --> 在系统中执行写入analysis.conf
self.post("/store", files=files, data=data)
# 执行execpy命令 --> 在系统中执行python analyzer.py
self.post("/execpy", data=data)
# 执行execute命令, execute(command)
self.post("/execute", data=data)
def wait_for_completion(self):
# 不断获取客户端分析状态
- __init__(): 初始化IP、端口号、系统、任务号、保存路径信息
- stop(): 关闭客户端分析
- upload_analyzer():
- 分析模块的文件位于
Bold-Falcon/data/analyzer/(android, darwin, linux, windows) - analyzer_zipfile 也会将 dumpmem.yarac 和Monitor 写入到压缩文件流中
- 分析模块的文件位于
- add_config(): 上传分析脚本,将options中的内容传入client中, 写入到self.analyzer_path的analysis.conf中
- start_analysis(): 客户端开启分析,client 端也开启了http server, 获取agent(配置的时候,需要在虚拟机中放置agent.py)的信息
- wait_for_completion(): 不断获取客户端分析状态
3.3.2 实现流程
1) 机器交互模块时序图
2) 机器交互模块实现流程
- 启动沙箱主机
- 初始化沙箱配置
- 启动虚拟机管理软件
- 根据指定的配置信息(标签、平台、IP等)生成可用客户机的列表
- 创建文件夹, 用于存放分析结果和样本文件,将target指向的文件存放到storage/binaries下
- 开启分析任务、开启客户端
- 使用GET/index访问代理
- 获取agent的一些基本信息
- 使用GET/environ访问代理
- 获取client端环境变量,以便后面后续的一些命令执行
- 使用GET/mktemp访问代理
- mkdtemp –> 在%SYSTEMDRIVE%(C:)下创建一个随机文件夹
- 使用GET/mkdtemp访问代理
- mktemp –> 在%TEMP%(C:\Users\bill\AppData\Local\Temp)下创建一个随机文件夹
- 使用POST/extract访问代理
- 将分析模块以zip格式压缩,发送给client端. 发送extrac命令, 将分析模块解压到上一步创建的文件夹中.
- 使用POST/store访问代理
- 写入analysis.conf 到 C:/tmppx7scx/analysis.conf
- 使用POST/store访问代理
- 写入simple.bin 到 C:\Users\bill\AppData\Local\Temp\simple.bin
- 使用POST/execpy访问代理
- 执行分析脚本
- 使用POST/status访问代理
- 不断获取样本分析状态
- 关闭客户端
- 关闭虚拟机管理软件
3.4 文件分析模块
3.4.1 实现说明
文件分析模块定义了分析组件在客户机环境中执行并分析给定的文件的过程。可以通过设置一个包含对所有类型的文件的通用处理方法的基类Package,然后使用多态的形式为不同类型的文件实现不同的启动分析方式。可供样本运行的客户机环境包括Windows、Linux、Android系统等,模块代码存放在Bold-Falcon/data/analyzer/目录下,包含所有用户指定选项的配置存储在self.options文件中。
1)文件分析定义函数
from lib.api.process import Process
from lib.common.exceptions import CuckooPackageError
class Package(object):
"""定义文件分析模块"""
def start(self):
# 定义文件分析初始化操作
raise NotImplementedError
def check(self):
# 执行重复操作
return True
def execute(self, path, args):
# 启动分析进程
dll = self.options.get("dll")
free = self.options.get("free")
suspended = True
if free:
suspended = False
p = Process()
if not p.execute(path=path, args=args, suspended=suspended):
raise CuckooPackageError(
"Unable to execute the initial process, analysis aborted."
)
if not free and suspended:
p.inject(dll)
p.resume()
p.close()
return p.pid
def finish(self):
# 转储进程内存
if self.options.get("procmemdump"):
for pid in self.pids:
p = Process(pid=pid)
p.dump_memory()
return True
- start():进行所有初始化操作,包括运行恶意软件进程、启动其他应用程序、拍摄内存快照等。
- check():执行任何类型的重复操作(每秒),可用于分析终止条件的触发机制。
- execute():封装恶意软件执行和DLL注入两个操作。
- finish():在完成分析并关闭客户机之前执行,用于转储所有受监控进程的进程内存。
2)分析进程定义函数
以Windows环境中的分析进程为例:
Class Process(object):
"""Windows分析进程"""
def execute(self):
# 执行样本分析
# 启动inject.exe作为中间人,负责启动目标样本进程并挂起主线程
argv = [
inject_exe,
"--app", path,
"--only-start",
]
subprocess_checkoutput(argv, env)
# 再次启动inject.exe作为中间人,执行dll注入功能
argv = [
inject_exe,
"--resume-thread",
"--pid", "%s" % self.pid,
"--tid", "%s" % self.tid,
]
if free:
argv.append("--free")
else:
argv += [
"--apc",
"--dll", dllpath,
]
subprocess_checkoutput(argv, env)
3)管道通信定义函数
Class PipeServer(threading.Thread):
# 接收传入的管道句柄,创建新线程
def run(self):
handler.start()
Class PipeForwarder(threading.Thread):
# 将通过管道接收的数据发送给中心服务器
def run(self):
socket.create_connection()
socket.sendall()
4)Windows分析模块运行函数
以分析通用Windows可执行文件的默认方法为例:
from lib.common.abstracts import Package
class Exe(Package):
"""EXE分析包"""
def start(self, path):
args = self.options.get("arguments")
return self.execute(path, args)
5)Linux分析模块运行函数(后期扩展)
class Generic(Package):
"""基于Shell的通用执行分析包"""
def start(self, path):
os.chmod(path, 0o755)
return self.execute(["sh", "-c", path])
6)Android分析模块运行函数(后期扩展)
class Apk(Package):
"""APK分析包"""
def start(self, path):
install_sample(path)
execute_sample(self.package, self.activity)
7)分析脚本运行函数
class Analyzer(object):
"""Windows分析脚本"""
def prepare(self):
# 配置分析环境
def run(self):
# 启动分析进程
self.prepare()
Package()
# 根据文件类型选择对应的分析包
package = choose_package()
Auxiliary()
# 启动一系列辅助分析工具
aux.init()
aux.start()
# 隐藏进程
zer0m0n.hidepid(self.pid)
zer0m0n.hidepid(self.ppid)
# 开始执行分析包
package.start()
package.execute()
- prepare(): 为分析进程配置环境,包括授予权限、启动管道服务器等
- run(): 启动分析进程,首先启动一系列辅助分析工具,并根据上传的文件类型选择其对应的文件包,在隐藏当前进程及其父进程后,执行分析包
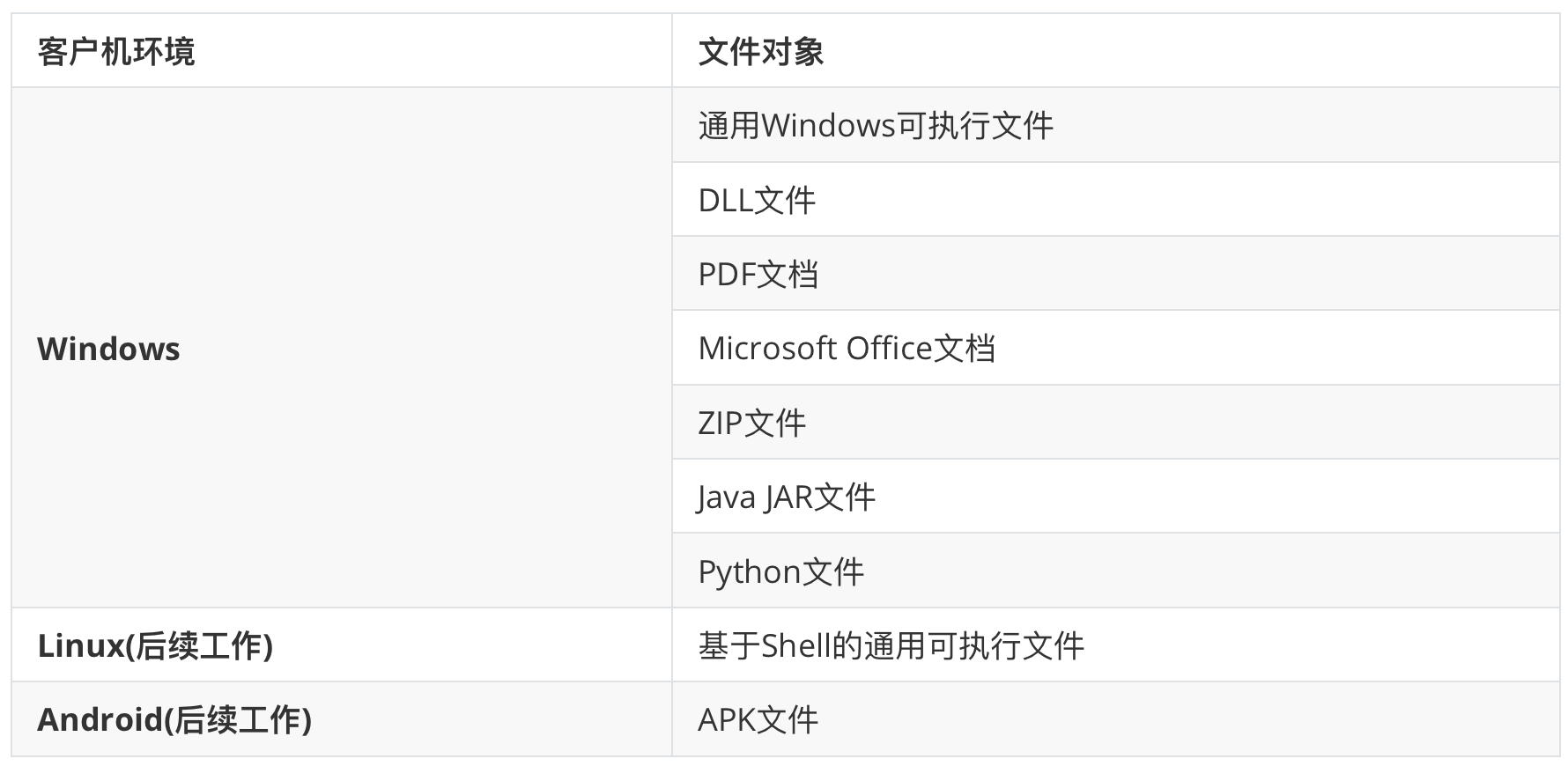
8)文件分析对象列表
| 客户机环境 | 文件对象 |
|---|---|
| Windows | 通用Windows可执行文件 |
| DLL文件 | |
| PDF文档 | |
| Microsoft Office文档 | |
| ZIP文件 | |
| Java JAR文件 | |
| Python文件 | |
| ...... | |
| Linux | 基于Shell的通用可执行文件 |
| Android | APK文件 |
3.4.2 实现流程
1)文件分析模块时序图
2)文件分析模块实现流程
- 分析环境准备
- 授予当前进程两个新权限,用于后续操作样本所在进程和加载驱动使用
- 启动两个管道服务器与目标样本进程交互,分别用于传输代码执行日志和函数调用记录日志
- 启动一系列辅助分析工具,主要包括截屏工具、驱动加载工具等
- 调用Package类,根据上传的文件类型选择其对应的文件包来启动分析
- 调用驱动功能,实现对当前进程(Analyzer进程)和父进程(Agent)的隐藏,防止目标检测到沙箱的存在
- 启动目标样本的分析进程
- 挂起主线程
- 输出目标样本进程pid和主线程tid,退出
- 再次启动目标样本进程,注入monitor.dll
- 唤醒主线程,执行样本
- monitor_init()
- 配置读取初始化
- hook初始化
- 管道初始化,连接前面Analyzer进程开启的两个管道
- sleep初始化,针对sleep函数进行特殊处理
- monitor模块的自我隐藏:抹去PE头数据+从PEB中的模块链表中将自己摘掉
-
process.py
-
工具脚本,处理对象为根据不同功能分成的rst文件(file.rst、process.rst、network.rst等等)
- 提取rst文件中所有需要HOOK的函数的信息,包括函数所在的模块名,函数名称、函数的所有参数信息、函数的返回值等
- 将所有rst文件通过一个hooks.c的代码模板渲染出来,得到完整的hooks.c文件,该代码文件里面定义了一个全局的g_hooks的数组,来记录所有待hook的函数信息
-
- monitor_hook():安装HOOK,生成函数调用记录
- 通过管道发送代码执行日志和函数调用记录日志
- 通过Socket通信发送代码执行日志和函数调用记录日志到中心服务器
- 中心服务器对文件分析结果进行各种形式的存储(分析日志、数据库、结果文件夹等),分析结果放置在
Bold-Falcon/storage/analyse/{task_id}目录下,供后续结果处理模块使用
3.5 结果处理模块
3.5.1 实现说明
结果处理模块允许自定义方法来分析沙盒生成的原始结果,并将一些信息附加到一个全局结果容器中,该结果容器稍后将由家族签名模块、机器学习模块和报告生成模块使用。Bold-Falcon/mol/processing/目录 中提供的所有处理模块,都属于结果处理模块。每个模块在 Bold-Falcon/conf/processing.conf中都应该有一个专门的配置选项,供用户选择结果处理功能。
结果处理模块都将被初始化和执行,返回的数据将被附加到一个名为全局结果容器的数据结构中。这个容器仅仅是一个大的Python字典,它包含了由所有按标识键分类的模块生成的抽象结果。每次分析的全局结果容器被储存在 Bold-Falcon/storage/analysis/task_id 文件夹下。
1)结果处理定义函数
from lib.cuckoo.common.exceptions import CuckooProcessingError
from lib.cuckoo.common.abstracts import Processing
class MyModule(Processing):
def run(self):
self.key = "key"
try:
data = do_something()
except SomethingFailed:
raise CuckooProcessingError("Failed")
return data
- run():self.key 该属性定义要用作返回 data 的子容器的名称。
- 将 data 附加到全局容器中(列表、字典、字符串等)。
- 可以指定一个order值,允许按顺序运行可用的处理模块。
2)结果处理运行函数
class RunProcessing(object):
def __init__(self, task):
# 初始化信息
def process(self, module, results):
# 执行一个结果处理模块
def run(self):
# 执行所有结果处理模块,返回全局结果容器
# 获得 processing 功能列表
processing_list = cuckoo.processing.plugins
for module in processing_list:
# 执行功能
key, result = self.process(module, results)
# If the module provided results, append it to the fat dict.
if key and result:
results[key] = result
return results
- __init__(): 初始化任务信息、虚拟机信息、分析结果存储路径
- process():
- 执行一个结果处理模块
- 初始化对应处理功能
- 如果在配置中禁用了处理模块,请跳过它
- 获得分析结果存储路径
- 执行对应处理功能
- 返回关键字,对应处理功能结果
- run(): 执行所有结果处理模块,返回全局结果容器
3)结果处理功能列表
| 处理模块名称 | 处理模块功能 |
|---|---|
| Analysisinfo | 生成有关当前分析的一些基本信息,例如时间戳、沙箱版本等 |
| BehaviorAnalysis | 解析原始行为日志,执行一些初始转换并提供解释,包括完整的进程跟踪、行为摘要和进程树 |
| Buffer | 丢弃缓冲区分析 |
| Debug | 包括错误和分析程序生成的analysis.log |
| Dropped | 包括由恶意软件丢弃并由沙箱转储的文件的信息 |
| Memory | 在完整的内存转储上执行 Volatility 内存取证分析工具 |
| NetworkAnalysis | 解析PCAP文件并提取一些网络信息,例如DNS流量、域、ip、HTTP请求、IRC和SMTP流量 |
| Screenshots | 屏幕截图和OCR分析 |
| StaticAnalysis | 对文件执行一些静态分析 |
| Strings | 从分析的二进制文件中提取字符串 |
| TargetInfo | 包括当前所分析文件的信息,如哈希,ssdeep等 |
| VirusTotal | 在VirusTotal.com上搜索所分析文件的反病毒签名 |
| ApkInfo | 生成有关当前APK分析的一些基本信息(Android分析) |
| Baseline | 从采集的信息中获取基线结果 |
| Drioidmon | 从Droidmon日志中提取动态API调用信息 |
| DumpTls | 交叉引用从监控程序中提取的TLS主密钥和从PCAP提取的密钥信息以转储主密钥文件 |
| GooglePlay | 有关分析会话过程的Google Play信息 |
| Irma | IRMA连接器 |
| Misp | MISP连接器 |
| ProcMemory | 执行进程内存转储的分析,并能够处理用户自定义的Yara规则 |
| ProcMon | 从procmon.exe的输出中提取事件 |
| Snort | Snort处理 |
| Suricata | Suricata处理 |
4)全局结果容器内容
全局结果容器为python的字典格式,为家族签名模块、机器学习模块和报告生成模块提供信息,最后保存在 Bold-Falcon/storage/analyses/{task_id}/reports/report.json 文件中。
- info
- added/strarted/ended: 上传样本, 启动分析与结束分析的时间戳
- duration: 分析时长
- id: ={task_id}, 数据库中的任务id
- package: 文件类型
- machine: 样本运行环境
- signatures
- families: 恶意软件家族
- description: 签名描述
- severity: 安全等级
- references: URL列表
- name: 签名名称
- target
- file
- yara: yara规则匹配
- sha-1/sha256/sha512/md5: 文件哈希值
- name: 文件名
- type: 文件类型(包括运行系统与压缩加壳方式)
- crc32: 校验码
- path: 文件二进制形式存储路径
- size: 文件大小
- network
- tls/udp/http/icmp/smtp/tcp/dns: 协议解析字段
- pcap_sha256: 流量包哈希值
- static
- pe_imports: 导入地址表(IAT), 列出了动态链接库和它们的函数
- imported_dll_count: DLL数量
- pe_resources: 资源节, 列出了文件中的可打印字符串/图形图像/按钮图标等信息
- pe_sections: 文件节区信息, 包括节区大小/虚拟地址/熵/加壳方式/虚拟内存等
- behavior
- generic
- process_path: 进程启动路径
- process_name: 进程执行程序名
- pid: 进程id
- first_seen: 进程启动时间戳
- ppid: 父进程id
- processes
- modules: 样本运行时调用的系统文件信息, 包括被调用文件名/路径/基地址及其大小
- time: 运行时间
- processtree
- children: 子进程列表
- debug: analysis.log分析结果
- screenshots: 指定运行截图存储路径
- strings: 文件中的可打印字符串列表
5)结果处理模块属性
结果处理模块提供了一些属性,可用于访问当前分析任务的原始结果:
- self.analysis_path:存储分析结果的目录路径,例如:
Bold-Falcon/storage/analysis/1 - self.log_path:analysis.log文件的路径
- self.file_path:所分析文件的路径
- self.dropped_path:存储丢弃文件的目录路径
- self.logs_path:存储原始行为日志的目录路径
- self.pcap_path:网络pcap转储的路径
- self.memory_path:完整的内存转储的路径(如果已创建)
- self.pmemory_path:进程内存转储的路径(如果已创建)
使用这些属性,能够轻松地访问由Bold-Falcon存储的所有原始结果,并对它们执行分析操作。
3.5.2 实现流程
1)结果处理模块时序图
2)结果处理模块设计流程
- 启动结果处理模块
- 初始化任务信息、虚拟机信息、分析结果存储路径
- 获得处理功能列表
- 执行一个结果处理功能
- 初始化对应处理功能
- 获得分析数据读取路径
- 执行对应处理功能
- 返回关键字,对应处理功能结果
- 执行所有结果处理模块,返回全局结果容器
3.6 家族签名模块
3.6.1 实现说明
家族签名模块定义了一些特定的"签名",用于表示特定的恶意行为模式或特征指标,一定程度上实现特定的恶意软件家族的类别划分,并将一些信息附加到一个全局容器中。这类特征简化了结果的解释,也可以自动识别感兴趣的恶意软件样本。所有签名位于Bold-Falcon/modules/signatures/目录或社区库的Bold-Falcon/data/signatures/目录下。
-
通过隔离一些独特的行为(如文件名或互斥)来识别您感兴趣的特定恶意软件系列
-
发现恶意软件在系统上执行的修改活动,例如安装设备驱动程序
-
通过隔离通常由银行特洛伊木马或勒索软件执行的典型操作,识别特定的恶意软件类别
-
将样本分类为恶意软件/未知类别,无法识别未知的样本
1)家族签名定义函数
例:检查是否有以".exe"结尾的文件:在这种情况下,它将返回True,表示签名匹配,否则返回False
from lib.cuckoo.common.abstracts import Signature
class CreatesExe(Signature):
name = "creates_exe"
description = "Creates a Windows executable on the filesystem"
severity = 2
categories = ["generic"]
authors = ["Cuckoo Developers"]
minimum = "2.0"
def on_complete(self):
return self.check_file(pattern=".*\\.exe$", regex=True)
def on_call(self, call, pid, tid):
# 只用于事件签名
- 初始签名属性
- name:签名的标识符
- description:签名所代表内容的简要描述
- severity:标识匹配事件严重性的数字(通常在1到3之间)
- categories:描述匹配事件类型的类别列表,例如:banker, injection, anti-vm, Bold-Falcon.
- families:恶意软件家族名称列表(如果签名与已知签名高度匹配)
- authors:签名作者的列表
- references:提供签名上下文的引用(URL)列表
- enable:如果设置为False,则跳过签名
- alert:如果设置为True,则可用于指定应报告的签名
- minimum:成功运行此签名所需的最低沙箱版本
- maximum:成功运行此签名所需的最高沙箱版本
- on_complete():特征匹配签名函数,在签名进程结束时被调用
- on_call():签名匹配时执行的回调函数
2)家族签名运行函数
所有签名都将并行执行,并通过API调用集合为一个单循环中的每个签名调用回调函数on_call().
class RunSignatures(object):
def __init__(self, results):
# 初始化签名,记录标签API
def call_signature(self, signature, handler, *args, **kwargs):
# 签名的包装器。这个包装器将事件产生给签名,并递归地处理匹配的签名
def process_yara_matches(self):
def process_extracted(self):
def run(self):
self.process_yara_matches()
# 遍历所有Yara匹配项
self.process_extracted()
for sig in self.signatures:
self.call_signature(sig, sig.on_extract, ExtractedMatch(item))
# 遍历所有提取的匹配项
self.matched.append(signature.results())
# 分数计算
score += signature.severity
# 按严重性级别对匹配的签名进行排序,并将其放入结果字典
self.matched.sort(key=lambda key: key["severity"])
self.results["signatures"] = self.matched
if "info" in self.results:
self.results["info"]["score"] = score / 5.0
required = ["creates_exe", "badmalware"]
def on_signature(self, matched_sig):
# 将识别异常的多个签名组合为一个签名分类实例(恶意软件警报)
if matched_sig in self.required:
self.required.remove(matched_sig)
if not self.required:
return True
return False
3)生成的签名结果、
如果签名匹配成功,生成的签名结果将被添加到全局容器中。
"signatures": [
{
"severity": 2,
"description": "Creates a Windows executable on the filesystem",
"alert": false,
"references": [],
"data": [
{
"file_name": "C:\\d.exe"
}
],
"name": "creates_exe"
}
]
4)Yara规则
Yara是一个能够帮助恶意软件研究人员识别和分类恶意软件样本的工具,使用Yara可以基于文本或二进制模式创建恶意软件家族描述信息。每一条YARA规则都由一系列字符串和一个布尔型表达式构成,并阐述其逻辑。Yara规则可以提交给正在运行的进程,以帮助系统识别其样本是否属于某个已进行规则描述的恶意软件家族。Yara规则语法类似于C语言,每个规则都以关键字"rule"开头,后面跟着一个规则标识符。规则示例如下:
rule Test : Trojan
{
//规则描述
meta:
author = "Sunset"
date = "2021-04-21"
description = "Trojan Detection"
//规则字符串
strings:
$a = {6A 40 68 00 30 00 00 6A 14 8D 91}
$b = {8D 4D B0 2B C1 83 C0 27 99 6A 4E 59 F7 F9}
$c = "UVODFRYSIHLNWPEJXQZAKCBGMT"
//条件表达式
condition:
$a or $b or $c
}
根据已有的恶意软件家族的专家知识,现在一般将Yara规则分为11类:
- Antidebug_AntiVM:反调试/反沙箱类yara规则
- Crypto:加密类yara规则
- CVE_Rules:CVE漏洞利用类yara规则
- email:恶意邮件类yara规则
- Exploit-Kits:EK类yara规则
- Malicious_Documents:恶意文档类yara规则
- malware:恶意软件类yara规则
- Mobile_Malware:移动恶意软件类yara规则
- Packers:加壳类yara规则
- capabilities:通用类yara规则
- Webshells:Webshell类yara规则
3.6.2 实现流程
1) 家族签名模块时序图
2)家族签名模块流程设计
- 文件分析模块
- 结果处理模块
- 启动家族签名模块
- 初试化所有可用签名,记录标签API
- 遍历所有匹配的Yara规则
- 遍历所匹配的签名
- 分数计算
- 按严重性级别对匹配的签名进行排序
- 将签名结果放入结果字典
3.7 机器学习模块
3.7.1 实现说明
机器学习模块定义一些基于机器学习的Windows恶意软件检测模型(其他文件检测模型后续添加),用于检测恶意软件,并将一些信息附加到一个全局容器中。
**1) 检测模型定义函数 **
from lib.cuckoo.common.exceptions import CuckooDetectionError
class Detection(object):
"""
Base abstract class for detection module.
"""
def set_options(self, options):
""" Set report options."""
def set_path(self, analysis_path):
"""Set paths."""
def set_task(self, task):
"""Add task information."""
def load_instance(self, results):
"""
Initialize the sample instance and load the dictionary
need a class Instance """
def run(self):
""" Start detection."""
raise NotImplementedError
class MyDetection(Detection):
def load_features(self)
# 数据预处理
def load_model(self):
# 加载模型训练
def run(self, Y)
# 预测目标值
return predict
- extract_features():数据预处理
- fit():模型训练
- predict():预测目标值
2)检测模型运行函数
class RunDetection(object):
""" plugins.py """
def __init__(self, task):
# 初始化模型信息
def process(self, module, results):
# 执行一个检测模块
def run(self):
# 执行所有结果检测模块,返回全局结果容器
# 获得 detection 功能列表
detection_list = cuckoo.detection.plugins
for module in detection_list:
# 执行功能
model_name,predict = self.process(module, results)
if model_name and predict:
results[model_name] = predict
return results
- __init__(): 初始化检测模型
- process():
- 执行一个检测模块
- 初始化对应检测功能
- 如果在配置中禁用了检测模块,请跳过它
- 读取分析数据路径
- 加载预训练检测模型
- 特征工程
- 返回关键字,预测结果
- run(): 执行所有检测模块,返回全局结果容器
3)检测模型列表
| 名称 | 类型 | 特征 | 算法模型 |
|---|---|---|---|
| Malconv | 静态分析 | 字节序列 | Malconv卷积神经网络 |
| String | 静态分析 | 字符串序列 | XGBoost集成学习模型 |
| Apistats | 动态分析 | API调用序列 | XGBoost集成学习模型 |
3.7.2 实现流程
1)模型检测模块时序图
2)模型检测模块设计流程
- 启动机器学习模块
- 初始化检测模型
- 获得检测模型功能列表
- 执行一个检测模块
- 初始化对应检测功能
- 如果在配置中禁用了检测模块,请跳过它
- 读取分析数据路径
- 加载预训练检测模型
- 特征工程
- 返回关键字,对应预测结果
- 执行所有检测模块
- 保存到全局结果容器
- 机器学习模块结束
3.8 报告生成模块
3.8.1 实现说明
在结果处理模块、家族签名模块、机器学习模块处理之后,报告生成模块定义了恶意软件分析报告生成的不同格式,将全局结果容器转化为json,将分析目录保存到非关系数据库 (MongoDB) 中。Bold-Falcon/modules/reporting/目录 中提供的所有处理模块,都属于结果处理模块。每个模块在 Bold-Falcon/conf/reporting.conf中都应该有一个专门的配置选项,供用户选择结果处理功能。
1)Json报告模块
接收结果处理模块生成的全局容器,将其转换为Json并写入文件
from lib.cuckoo.common.abstracts import Report
class JsonDump(Report):
def erase_calls(self, results):
# 通过将调用替换为空列表,暂时从报表中删除
def run(self, results)
# 将report.json写入report文件夹
- erase_calls(): 通过将调用替换为空列表,暂时从报表中删除
- run(): 将report.json写入report文件夹
2) MongoDB存储函数
class MongoDB(Report):
@classmethod
def init_once(cls):
# 初始化mongo数据库
def store_file(self, file_obj, filename=""):
# 存储成 GridFS 文件格式.
def run(self, results):
# 创建词典的副本。这样做是为了不修改原始字典,并可能损害以下报告模块
# 依次读取结果容器字段,并保存
self.db.analysis.save(report)
- init_once(): 初始化mongo数据库
- store_file(): 储成 GridFS 文件格式
- run():
- 创建词典的副本。这样做是为了不修改原始字典,并可能损害以下报告模块
- 依次读取结果容器字段,并保存
3)报告生成运行函数
class RunReporting(object):
def __init__(self, task, results):
# 初始化任务、结果容器、任务目录
def process(self, module):
# 执行一个生成功能模块
# 初始化生成功能模块
# 获得分析任务目录
# 执行对应处理功能
current.run(self.results)
def run(self):
#依次执行report模块jsondump,mongodb
reporting_list = cuckoo.reporting.plugins
for module in reporting_list:
self.process(module)
3.8.2 实现流程
1)报告生成模块时序图
2)报告生成模块实现流程
-
启动报告生成模块
- 初始化 任务、结果容器、任务目录
- 获得报告生成功能列表(jsondump,mongodb)
- 执行一个jsondump生成功能
- 初始化对应生成功能
- 通过将调用替换为空列表,暂时从报表中删除
- 将report.json写入report文件夹
- 执行一个mongodb生成功能
- 初始化对应生成功能
- 创建词典的副本
- 依次读取结果容器字段
- 保存到数据库
- 报告生成模块结束
3.9 用户交互模块
3.9.1 实现说明
1)前端框架Django
前端基于Python的Django框架开发,Django是一个开源的Web应用框架,采用MTV的框架模式:Model(模型), Template(模板), Views(视图)
| 模块 | 功能 |
|---|---|
| Model | 数据存取层,处理和数据相关的所有事物 |
| Template | 表现层,处理与表现相关的决定 |
| Views | 业务逻辑层,存取模型以及调取恰当的模板,是模板和模型之间的桥梁 |

2)Django的一些特性:
| 特性 | 内容 |
|---|---|
| URL设计 | 可以设计任意的URL,而且还支持使用正则表达式匹配 |
| 模板系统 | 提供可扩展的模板语言,并且模板之间具有继承性 |
| Nginx | Nginx是一款轻量级的Web服务器,占用内存少,并发性强 |
| WSGI | 是一种为Python语言定义的Web服务器和Web应用程序或框架之间的通用的接口协议 |
3)WSGI的三级架构:

4)项目配置说明
项目应用路径为Bold-Falcon/web,项目总体设置:Bold-Falcon/web/web/setting.py文件中,包含了整个应用的配置信息,包括数据库连接、静态资源和url的路径定义、中间件和cookie的配置、模板文件的配置等
mongo.connect()
DATABASES = {}
#数据库连接
STATIC_URL = "/static/"
STATICFILES_DIRS = (
...#添加静态资源路径
)
SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
#配置https
SESSION_ENGINE = "django.contrib.sessions.backends.signed_cookies"
SESSION_COOKIE_HTTPONLY = True
#配置cookie
STATICFILES_FINDERS = (
...#finder函数用来寻找静态文件
)
MIDDLEWARE_CLASSES = (
...#配置中间件
)
ROOT_URLCONF = "web.urls"
#配置路由路径
TEMPLATES = [
...#配置模板文件路径
]
WSGI_APPLICATION = "web.wsgi.application"
#注册WSGI服务
INSTALLED_APPS = (
...#注册应用
)
项目url配置:Bold-Falcon/web/web/urls.py文件中配置了视图类views绑定页面的url
urlpatterns = [
...#自定义URL绑定视图函数
]
handler404 = web.errors.handler404
handler500 = web.errors.handler500
#错误页面绑定自定义视图
数据库配置:前端数据库使用非关系型数据库MongoDB.数据库配置信息:lib/cuckoo/common/config.py
"mongodb": {
"enabled": Boolean(False),
"host": String("127.0.0.1"),
"port": Int(27017),
"db": String("cuckoo"),
"store_memdump": Boolean(True),
"paginate": Int(100),
"username": String(),
"password": String(),
},
在Django前端框架中配置并连接数据库:Bold-Falcon/web/web/setting.py
mongo.connect()
class Mongo(object):
def init(self):
#初始化
def drop(self):
#删除数据库表
def close(self):
#关闭数据库链接
def connect(self):
#连接数据库
API接口:获取数据库Analysis表的数据的API接口定义在Bold-Falcon/web/controllers/analysis/api.py
db = Database()
#数据库连接
class AnalysisApi(object):
def tasks_list(request, body):
#获取任务列表
def task_info(request, task_id):
#获取指定任务信息
def task_delete(request, task_id):
#删除指定任务
def task_screenshots(request, task_id, screenshot=None):
#获取指定任务截图
def tasks_stats(request, body):
#返回任务状态
def tasks_recent(request, body):
#返回最近任务
...
四、运行结果/应用效果
毕方智能云沙箱名字来源:Bold-Falcon译为无畏的雄鹰,其中取首字母毕方为山海经神鸟之一。
4.1 沙箱提交界面
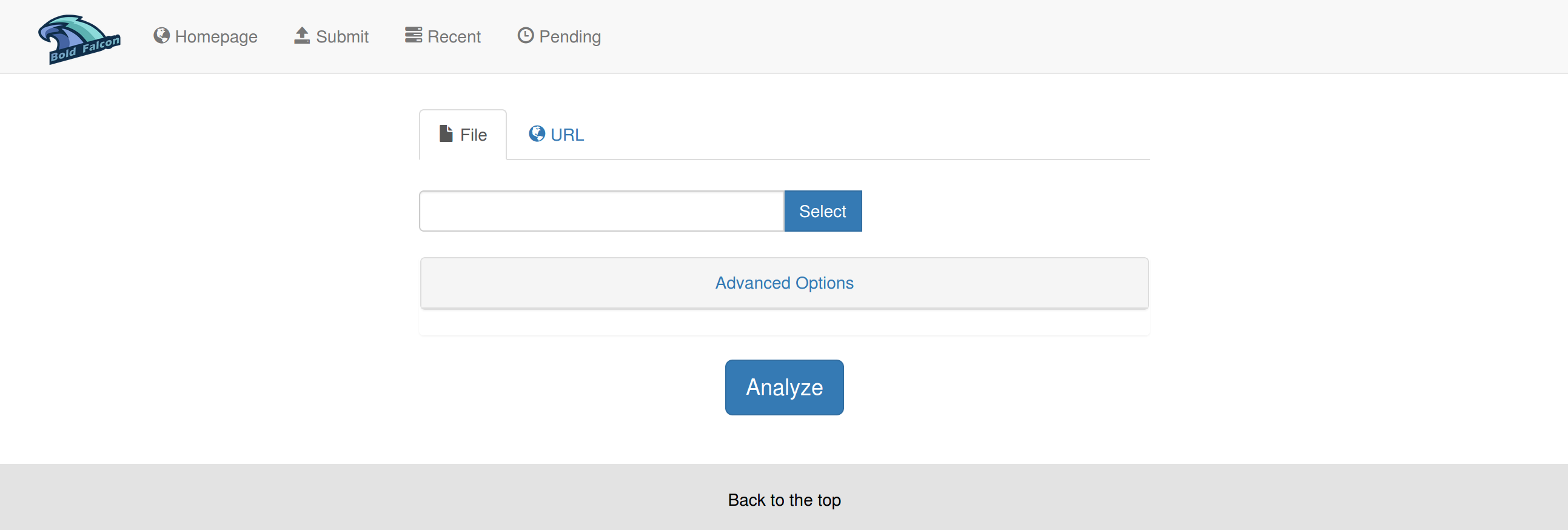
4.2 样本分析界面
(1)摘要分析报告
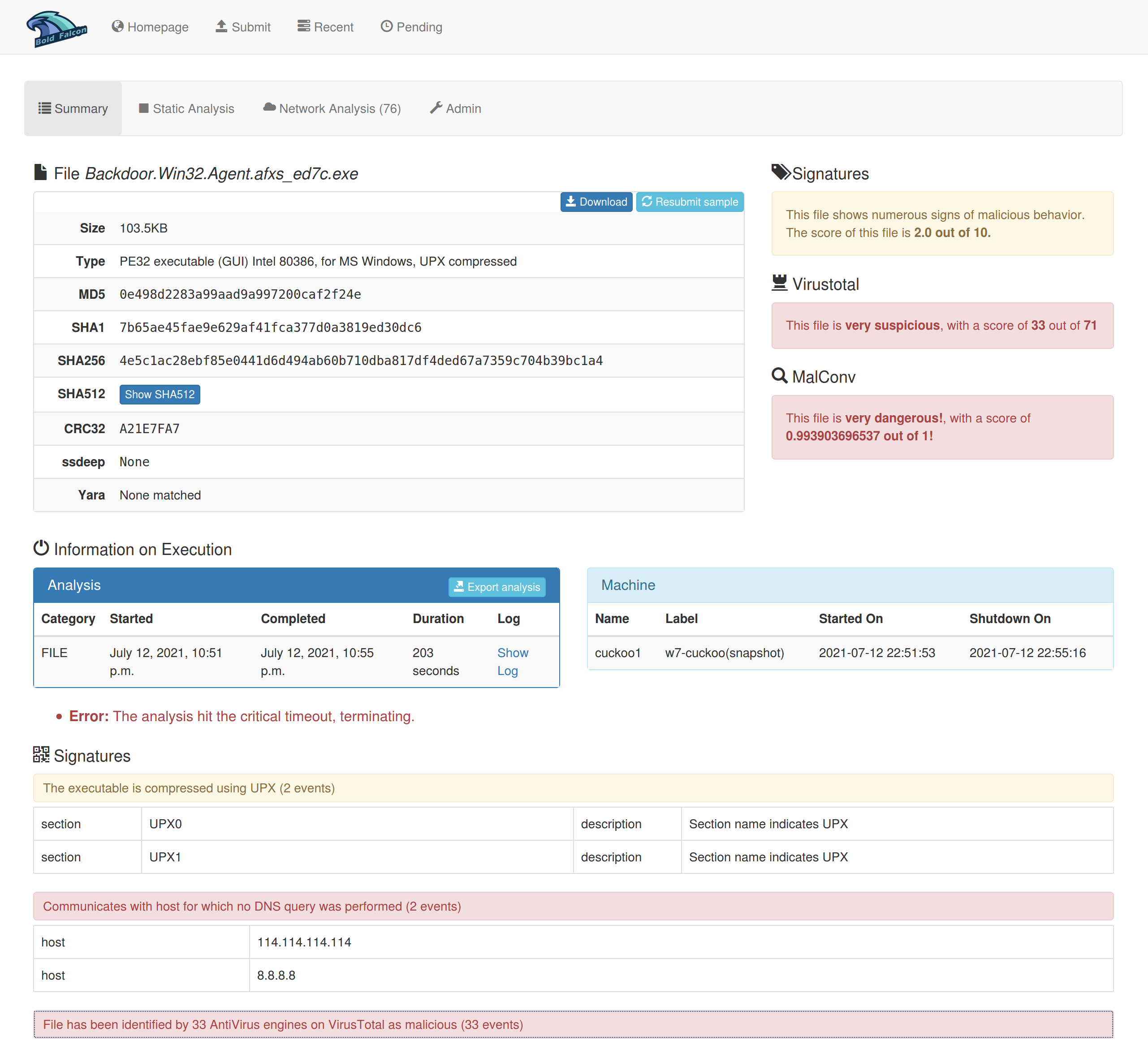
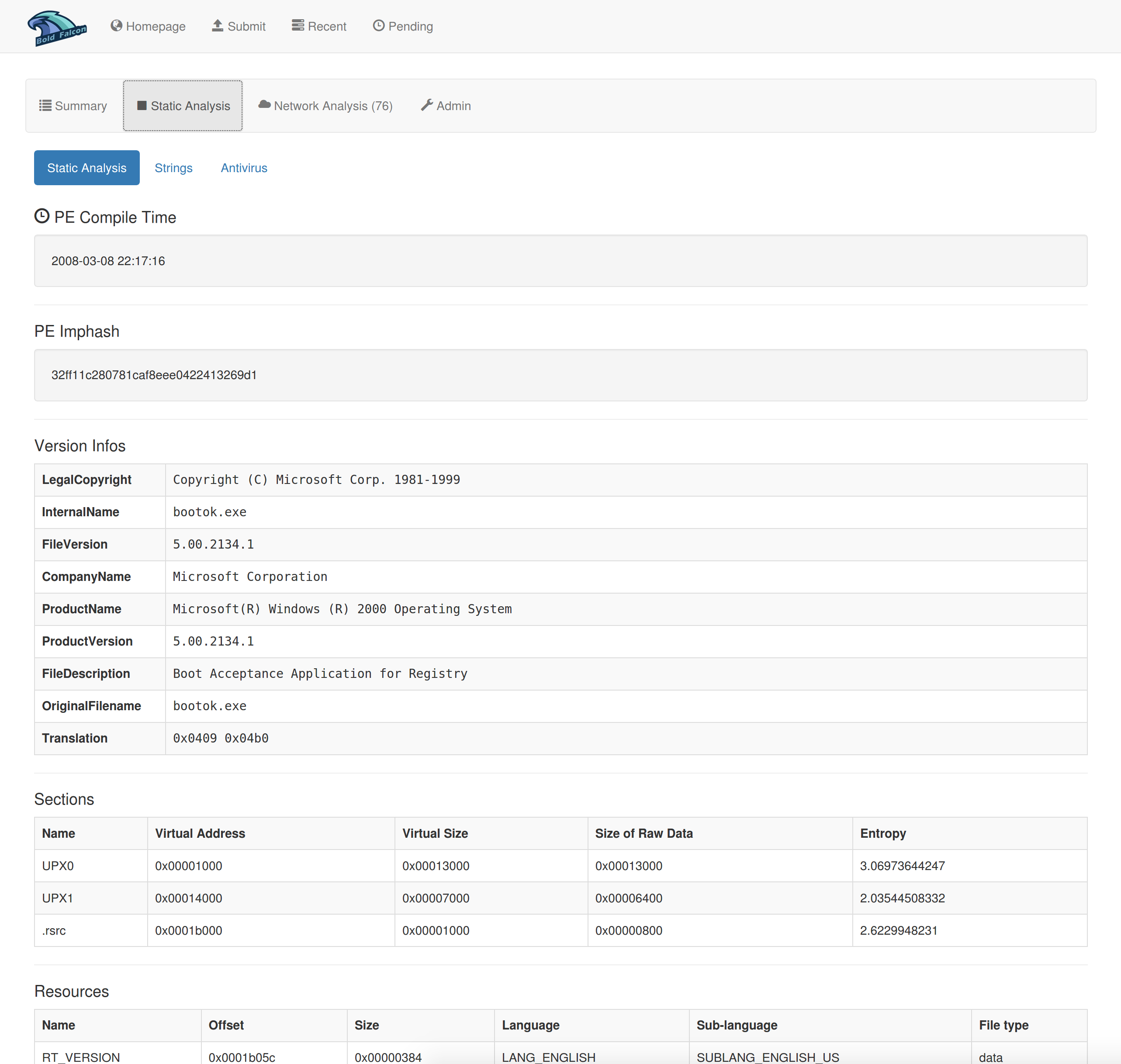
(2)静态分析报告
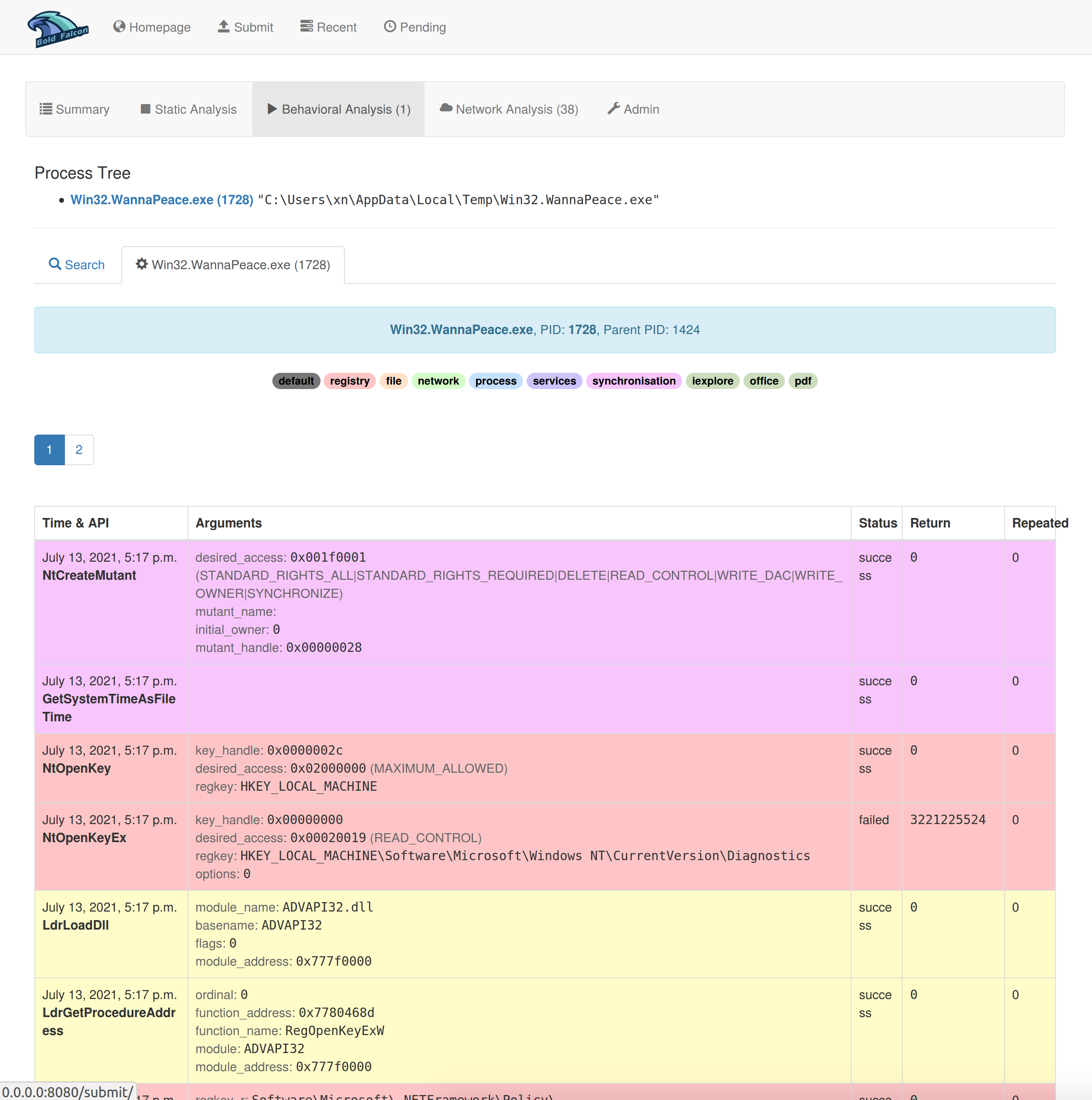
(3)动态分析报告
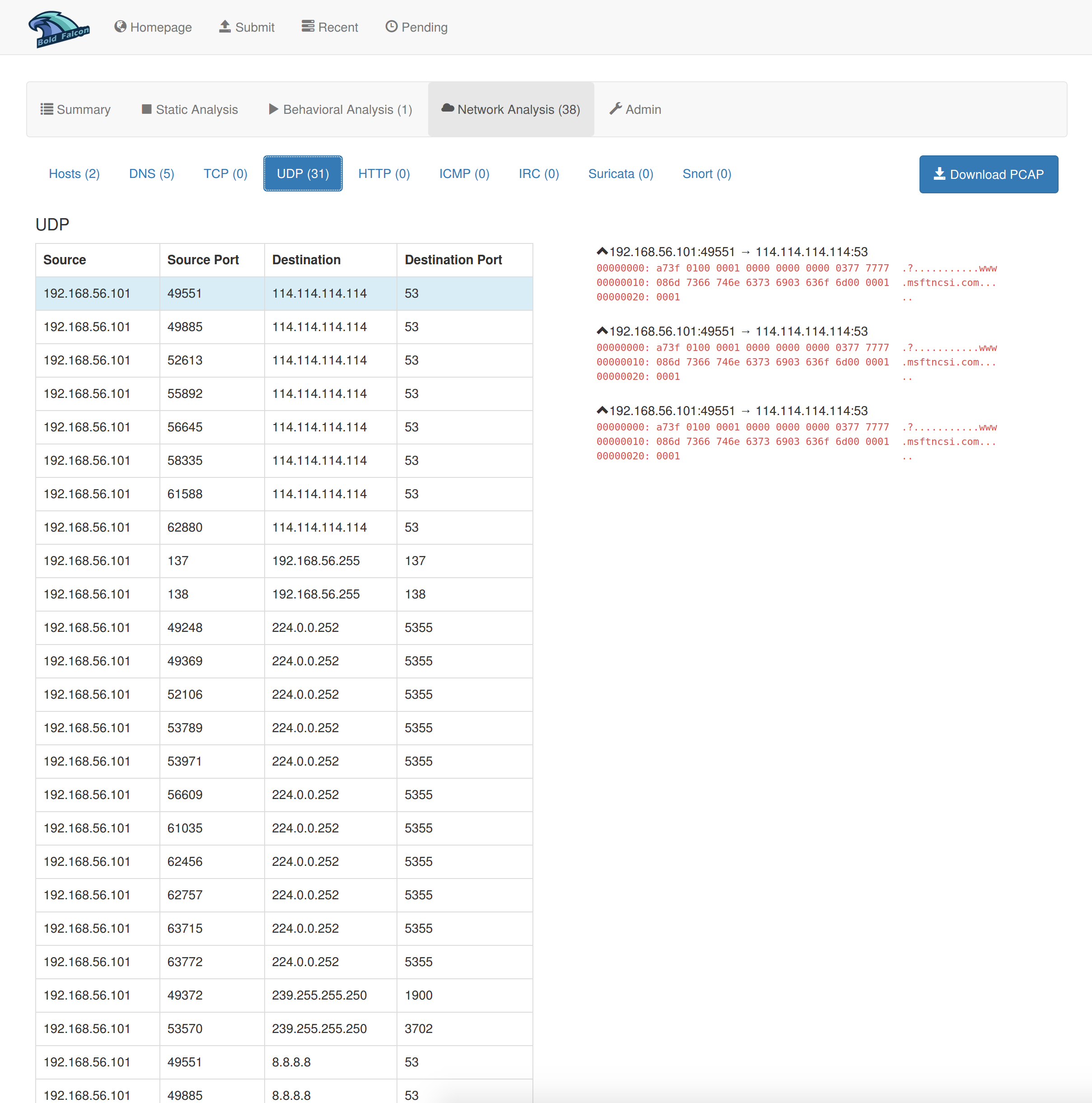
(4)流量分析报告
4.3 历史报告查询
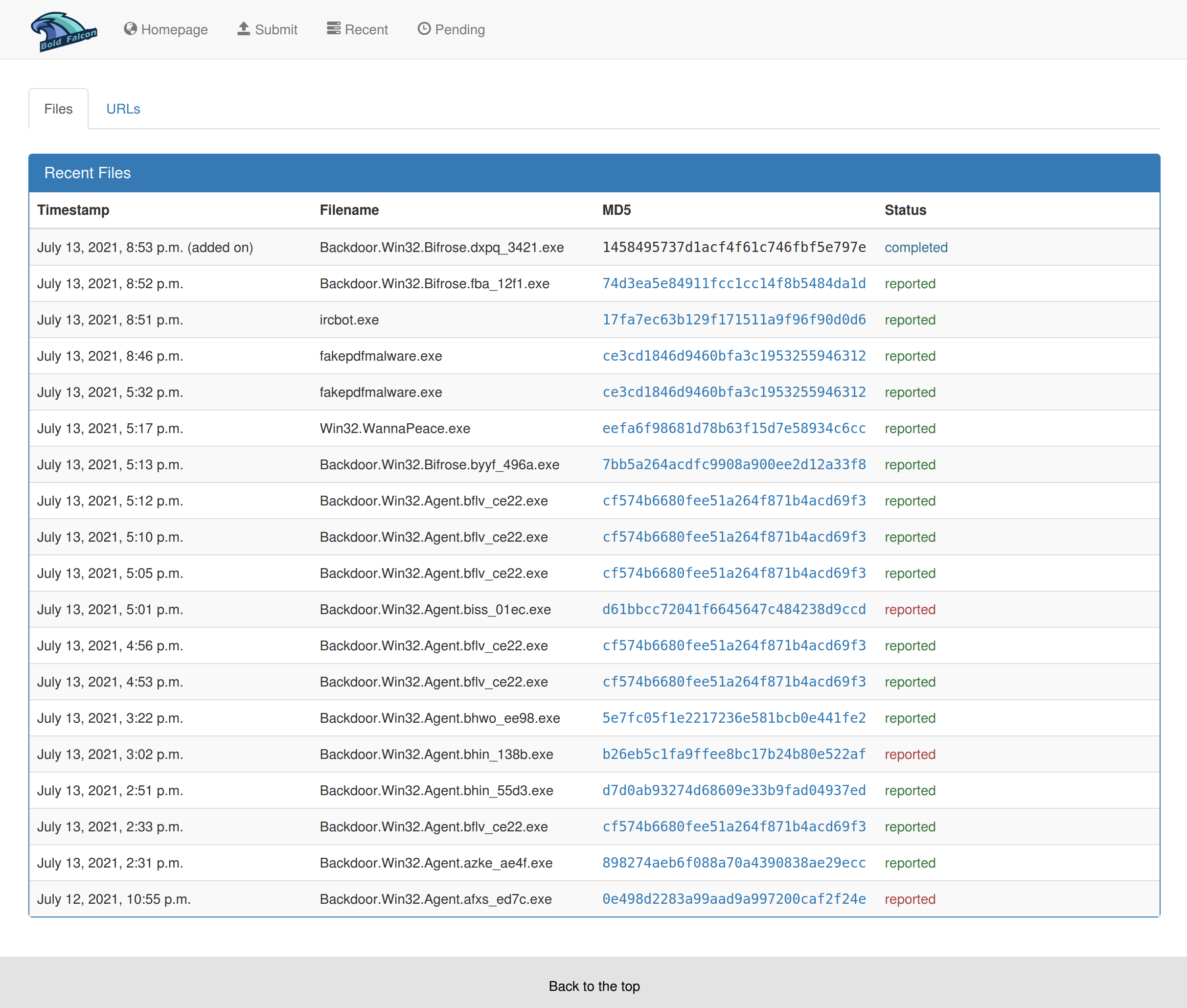
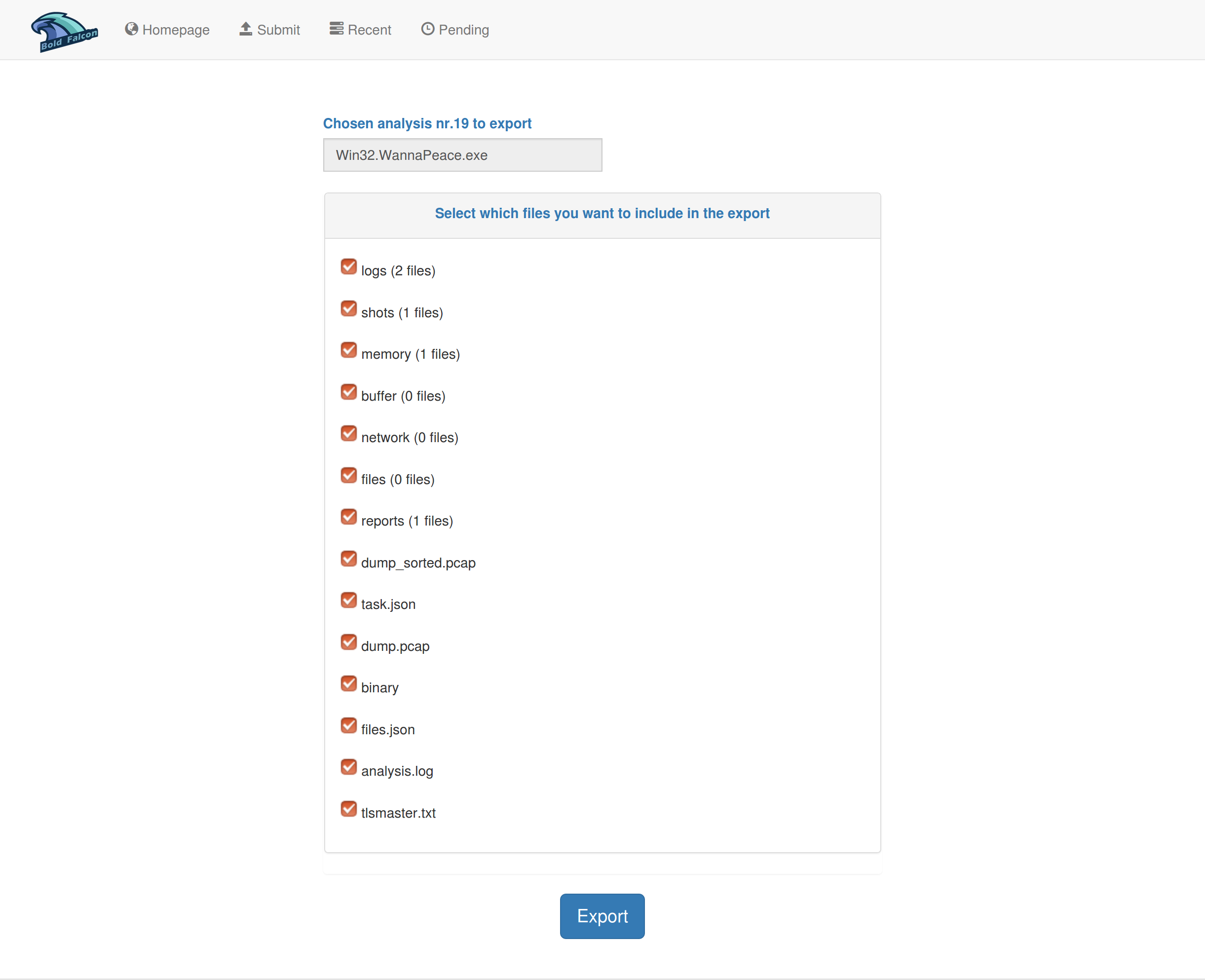
2.3.4 分析结果下载
五、创新与特色
本作品针对传统沙箱不能识别未知的恶意软件的痛点,将基于机器学习的恶意软件检测技术赋能到传统沙箱中,增加了目前最先进的基于人工智能的恶意软件检测技术实现对未知恶意软件检测的功能。其检测方法中除了使用基于静态分析和动态分析提取的恶意软件检测器需要的特征信息之外,还实现了无需特征提取的基于深度学习的恶意软件检测模型,使沙箱在对恶意软件检测效率和准确率都得到了很大的提升。本作品整体架构由一个沙箱主机和多个独立的虚拟机组成,包括辅助功能、机器交互、文件分析、结果处理、家族签名、机器学习、报告生成、用户交互八个功能模块。实现了如下核心功能:
- 本作品实现自动在虚拟运行和分析exe、dll、pdf、office、zip、jar、python等格式文件并收集流量、进程调用、内存、家族签名、样本静态信息等分析结果。
- 本作品兼容Cuckoo沙箱的开源社区,它是一个致力于社区贡献的开源数据库。可以使用最新的代理agent、注入脚本monitor和分析脚本analzyer等功能模块。
- 本作品不仅实现使用基于字节熵直方图、PE静态特征、字符串序列等静态特征的检测模型。还实现了基于API调用序列等动态特征的检测模型。并且封装了沙箱所有特征提取方法供研究人员自定义机器学习的检测模型。
- 本作品实现了目前最先进的基于字节序列的深度学习检测模型MalConv。无需专家经验,无需特征提取和处理,亦可实现快速高效的检测恶意软件。
六、使用
这部分解释如何使用Bold-Falcon沙箱。
6.1 启动沙箱
使用如下命令启动 Bold-Falcon沙箱:
$ cuckoo
你会得到如下类似的输出:
____ _ _ _____ _
| __ ) ___ | | __| | | ___|_ _| | ___ ___ _ __
| _ \ / _ \| |/ _` |_____| |_ / _` | |/ __/ _ \| '_ \
| |_) | (_) | | (_| |_____| _| (_| | | (_| (_) | | | |
|____/ \___/|_|\__,_| |_| \__,_|_|\___\___/|_| |_|
Bold-Falcon Sandbox 2.0-dev
https://github.com/PowerLZY/Bold-Falcon
Copyright (c) 2020-2021
2021-07-12 21:58:45,841 [lib.cuckoo.core.resultserver] WARNING: Cannot bind ResultServer on port 2042, trying another port.
2021-07-12 21:58:45,843 [lib.cuckoo.core.scheduler] INFO: Using "virtualbox" as machine manager
2021-07-12 21:58:47,256 [lib.cuckoo.core.scheduler] INFO: Loaded 1 machine/s
2021-07-12 21:58:47,270 [lib.cuckoo.core.scheduler] INFO: Waiting for analysis tasks.
你可以使用一些命令行选项,比如cuckoo --help
$ cuckoo --help
usage: cuckoo.py [-h] [-q] [-d] [-v] [-a] [-t] [-m MAX_ANALYSIS_COUNT]
[-u USER] [--ml] [--clean]
optional arguments:
-h, --help show this help message and exit
-q, --quiet Display only error messages
-d, --debug Display debug messages
-v, --version show program's version number and exit
-a, --artwork Show artwork
-t, --test Test startup
-m MAX_ANALYSIS_COUNT, --max-analysis-count MAX_ANALYSIS_COUNT
Maximum number of analyses
-u USER, --user USER Drop user privileges to this user
--ml CuckooML: cluster reports and compare new samples
--clean Remove all tasks and samples and their associated data
6.2 样本提交
Bold-Falcon沙箱有Django Web、SubmitandAPI三种分析样本的方法。
6.2.1 Django Web
Bold-Falcon以Django应用程序的形式提供了一个完整的web界面。此界面将允许您提交文件、浏览报告以及统计所有分析结果。
配置
Web界面从Mongo数据库中提取数据,因此在reporting模块中启用了Mongo 模块。配置文件是Web界面运行所必需的。Bold-Falcon/web/local_settings.py配置文件中存在一些其他配置选项。
启动Web界面
要启动web界面,只需从Bold-Falcon/web目录运行以下命令:
$ manage.py
如果要将web界面配置为侦听指定端口上的任何IP,可以使用以下命令启动它(用所需的端口号替换端口):
$ manage.py 0.0.0.0:PORT
6.2.2 Submit脚本
提交分析的最简单方法是在utils\submit.py 使用Bold-Falcon submit实用程序。它目前有以下可用选项:
$ submit --help
usage: submit.py [-h] [-d] [--remote REMOTE] [--url] [--package PACKAGE]
[--custom CUSTOM] [--owner OWNER] [--timeout TIMEOUT]
[-o OPTIONS] [--priority PRIORITY] [--machine MACHINE]
[--platform PLATFORM] [--memory] [--enforce-timeout]
[--clock CLOCK] [--tags TAGS] [--baseline] [--max MAX]
[--pattern PATTERN] [--shuffle] [--unique] [--quiet]
[target]
positional arguments:
target URL, path to the file or folder to analyze
optional arguments:
-h, --help show this help message and exit
-d, --debug Enable debug logging
--remote REMOTE Specify IP:port to a Cuckoo API server to submit
remotely
--url Specify whether the target is an URL
--package PACKAGE Specify an analysis package
--custom CUSTOM Specify any custom value
--owner OWNER Specify the task owner
--timeout TIMEOUT Specify an analysis timeout
-o OPTIONS, --options OPTIONS
Specify options for the analysis package (e.g.
"name=value,name2=value2")
--priority PRIORITY Specify a priority for the analysis represented by an
integer
--machine MACHINE Specify the identifier of a machine you want to use
--platform PLATFORM Specify the operating system platform you want to use
(windows/darwin/linux)
--memory Enable to take a memory dump of the analysis machine
--enforce-timeout Enable to force the analysis to run for the full
timeout period
--clock CLOCK Set virtual machine clock
--tags TAGS Specify tags identifier of a machine you want to use
--baseline Run a baseline analysis
--max MAX Maximum samples to add in a row
--pattern PATTERN Pattern of files to submit
--shuffle Shuffle samples before submitting them
--unique Only submit new samples, ignore duplicates
--quiet Only print text on failure
以下是一些用法示例:
(1) 提交一个本地文件
$ submit /path/to/binary
(2) 提交一个本地文件并明确优先级
$ submit --priority 5 /path/to/binary
(3) 提交一个本地文件并明确分析60s
$ submit --timeout 60 /path/to/binary
6.2.3 API访问
正如提交分析中所提到的,Bold-Falcon沙箱兼容cuckoo沙箱提供了一个简单而轻量级的restapi服务器,它是使用Flask实现的。
开启API服务器
在Bold-Falcon\utils使用如下命令启动 API服务:
$ api
$ * Running on http://localhost:8090/ (Press CTRL+C to quit)
默认情况下,它绑定的服务是localhost:8090, 如果你想要的去改变这些值,可以使用如下语法:
$ cuckoo api --host 0.0.0.0 --port 1337
$ cuckoo api -H 0.0.0.0 -p 1337
使用API需要进行身份验证,必须将cuckoo.conf的api_token的值填充在Authorization: Bearer <token>中。
资源
以下是当前可用资源的列表以及每个资源的简要说明。有关详细信息,请单击资源名称。
| 访问方式 | 描述 |
|---|---|
POST /tasks/create/file | 将文件添加到待处理任务列表中并分析 |
POST /tasks/create/url | 将URL添加到待处理任务列表中并分析 |
POST /tasks/create/submit | 将一个或多个文件添加到待分析的任务列表中 |
GET /tasks/list | 返回一个存储在内部Bold-Falcon数据库的任务列表 |
GET /tasks/sample | 返回一个存储在内部Bold-Falcon数据库的样本列表 |
GET /tasks/view | 返回一个对应ID的任务信息 |
GET /tasks/delete | 删除一个数据库中的任务信息 |
GET /tasks/report | 返回一个对应ID任务生成的json报告 |
GET /tasks/summary | 返回一个对应ID任务生成的摘要json报告 |
GET /tasks/screenshots | 返回一个对应ID任务生成的所有截图文件 |
GET /files/view | 返回一个对应ID的MD5、SHA256等标识 |
GET /files/get | 返回二进制样本内容和对应SHA256 |
GET /pcap/get | 返回相关任务的PCAP网络流量包 |
GET /machines/list | 返回目前Bold-Falcon依赖的虚拟机列表 |
GET /cuckoo/status | 返回目前Bold-Falcon的版本和状态 |
GET /exit | 关闭API服务器 |
以下是一些用法示例:
(1)POST /tasks/create/file
将文件添加到待处理任务列表中并分析
请求示例:
curl -H "Authorization: Bearer S4MPL3" -F file=@/path/to/file http://localhost:8090/tasks/create/file
使用Python的请求示例
import requests
REST_URL = "http://localhost:8090/tasks/create/file"
SAMPLE_FILE = "/path/to/malwr.exe"
HEADERS = {"Authorization": "Bearer S4MPL3"}
with open(SAMPLE_FILE, "rb") as sample:
files = {"file": ("temp_file_name", sample)}
r = requests.post(REST_URL, headers=HEADERS, files=files)
# Add your code to error checking for r.status_code.
task_id = r.json()["task_id"]
# Add your code for error checking if task_id is None.
响应示例
{
"task_id" : 1
}
(2)POST /tasks/create/url
将URL添加到待处理任务列表中并分析
请求示例
curl -H "Authorization: Bearer S4MPL3" -F url="http://www.malicious.site" http://localhost:8090/tasks/create/url
使用Python的请求示例
import requests
REST_URL = "http://localhost:8090/tasks/create/url"
SAMPLE_URL = "http://example.org/malwr.exe"
HEADERS = {"Authorization": "Bearer S4MPL3"}
data = {"url": SAMPLE_URL}
r = requests.post(REST_URL, headers=HEADERS, data=data)
# Add your code to error checking for r.status_code.
task_id = r.json()["task_id"]
# Add your code to error checking if task_id is None.
(3)POST /tasks/create/submit
将一个或多个文件添加到待分析的任务列表中
请求示例
# Submit two executables.
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/tasks/create/submit -F files=@1.exe -F files=@2.exe
# Submit http://google.com
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/tasks/create/submit -F strings=google.com
# Submit http://google.com & http://facebook.com
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/tasks/create/submit -F strings=$'google.com\nfacebook.com'
使用Python的请求示例
import requests
HEADERS = {"Authorization": "Bearer S4MPL3"}
# Submit one or more files.
r = requests.post("http://localhost:8090/tasks/create/submit", files=[
("files", open("1.exe", "rb")),
("files", open("2.exe", "rb")),
], headers=HEADERS)
# Add your code to error checking for r.status_code.
submit_id = r.json()["submit_id"]
task_ids = r.json()["task_ids"]
errors = r.json()["errors"]
# Add your code to error checking on "errors".
# Submit one or more URLs or hashes.
urls = [
"google.com", "facebook.com", "cuckoosandbox.org",
]
r = requests.post(
"http://localhost:8090/tasks/create/submit",
headers=HEADERS,
data={"strings": "\n".join(urls)}
)
响应事例
{
"submit_id": 1,
"task_ids": [1, 2],
"errors": []
}
(4) GET /files/get/ (str: sha256)
返回二进制样本内容和对应SHA256
请求示例
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/files/get/e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 > sample.exe
(5)GET /machines/list
返回目前Bold-Falcon依赖的虚拟机列表
请求示例
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/machines/list
响应示例
{
"machines": [
{
"status": null,
"locked": false,
"name": "cuckoo1",
"resultserver_ip": "192.168.56.1",
"ip": "192.168.56.101",
"tags": [
"32bit",
"acrobat_6",
],
"label": "cuckoo1",
"locked_changed_on": null,
"platform": "windows",
"snapshot": null,
"interface": null,
"status_changed_on": null,
"id": 1,
"resultserver_port": "2042"
}
]
}
(6)GET /exit
如果处于调试模式并使用werkzeug服务器,则关闭服务器。
请求示例
curl -H "Authorization: Bearer S4MPL3" http://localhost:8090/exit
6.3 社区
Bold-Falcon沙箱兼容Cuckoo沙箱的开源社区,它是一个致力于社区贡献的开放存储库。在这里,您可以提交为布谷鸟沙盒设置编写的自定义模块,并希望与社区的其他成员共享这些模块。其中包括代理agent、分析脚本analzyer和各种功能模块。
如果想要从开源社区下载对应数据到Bold-Falcon\data下,可以使用Bold-Falcon\utils\community:
$ cummunity -h
usage: community.py [-h] [-a] [-s] [-p] [-m] [-n] [-M] [-g] [-r] [-f] [-w]
[-b BRANCH]
[archive]
positional arguments:
archive Install a stored archive
optional arguments:
-h, --help show this help message and exit
-a, --all Download everything
-s, --signatures Download Cuckoo signatures
-p, --processing Download processing modules
-m, --machinery Download machine managers
-n, --analyzer Download analyzer modules
-M, --monitor Download monitoring binaries
-g, --agent Download agent modules
-r, --reporting Download reporting modules
-f, --force Install files without confirmation
-w, --rewrite Rewrite existing files
-b BRANCH, --branch BRANCH
例:重写所有开源数据到最新版
$ cummunity -waf
6.4 分析样本获取
6.4.1 样本分享
Bold-Falcon沙箱分享了200个已经分析完成的json报告在百度云盘如下链接:
https://pan.baidu.com/s/19TRWbQSRWJHetUBpNtMj_w 提取码: r7gk
Bold-Falcon沙箱分享了一些32bit的windows样本在百度云盘如下链接:
https://pan.baidu.com/s/1x6a9j7D7Ktp242fcJhT5aA 提取码: qxbp
6.4.2 开源样本
如果你想要获取更多的恶意样本请访问查询:
推荐:
- Blue Hexagon Open Dataset for Malware AnalysiS (BODMAS)
- EMBER - Endgame Malware BEnchmark for Research
- Malware Training Sets: A machine learning dataset for everyone (data)
- SoReL-20M - Sophos-ReversingLabs 20 Million dataset.
- Virusshare
其他:
- Samples of Security Related Dats
- DARPA Intrusion Detection Data Sets
- Stratosphere IPS Data Sets
- Open Data Sets
- Data Capture from National Security Agency
- The ADFA Intrusion Detection Data Sets
- NSL-KDD Data Sets
- Malicious URLs Data Sets
- Multi-Source Cyber-Security Events
- Malware Training Sets: A machine learning dataset for everyone
如果你想要获取更多的良性样本请在如下等网络自行爬取: