推荐算法(3)DeepFM模型
一、DeepFM
吃透论文——推荐算法不可不看的DeepFM模型 - 梁唐的文章 - 知乎 https://zhuanlan.zhihu.com/p/343343016
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,翻译过来就是DeepFM:一个基于深度神经网络的FM模型。这篇paper的作者来自哈工大和华为,不得不说在人工智能领域的很多论文都是国产的,作为从业者还是非常欣喜能看到这点的。
1.1 简介
对推荐场景来说,CTR是最关键的指标,除了广告系统会按照CTR x bid来进行排序之外,推荐系统一般都会严格地按照预估的CTR进行排序。所以这其中的关键问题就是准确地预估CTR。
常规的推荐系统当中的特征分为四个部分:
- 用户特征:关于用户的一些信息。比如是男是女,是否是高收入群体,是否是高消费群体,成为平台的用户多久了,偏好平台当中什么类目的商品等等。
- 商品特征:关于item的一些信息,比如价格、类目、折扣、评价等等。
- 上下文特征:比如当前的时间,是早上还是晚上,比如item展示的位置等等。
- 用户实时的行为:比如用户在浏览这个商品之前还看过哪些其他的商品,他登陆平台多久了,等等。
显然用户是否会点击某一个item是由以上这四个部分的信息共同作用的,也就是说商品的特征和用户的特征之间是存在逻辑上的关联的,我们一般称为特征的交叉。
这些交叉信息往往是隐式的,也就是我们不能直接描述和形容出来的。人的喜好是很复杂的,我们很难用固定的规则去描述。所以这就需要模型能有这样的能力去学习这些特征之间的潜在联系,对这些潜在交叉信息把握越好的模型,一般也都拥有越好的效果。
比如我们分析了主流的app store市场之后发现,在饭点的时候,用户经常会下载外卖类的app,这说明了app的类别和时间之间存在交叉关系。再比如我们发现年轻的男生往往喜欢设计类游戏,这说明了app的类别与用户的性别之间也存在交叉关系。像是这样的交叉信息还有很多,从Wide & Deep模型的经验当中我们可以学到考虑低维和高维交叉特征之后,模型的效果会更好。
1.2 算法
训练集当中一共有 \(n\) 条样本, 每一条样本可以写成 \((\chi, y)\) 。其中的 \(\chi\) 是一个 \(m\) 个field组成的向量, 包含了用户和 item组成的特征。 \(y \in\{0,1\}, y=0\) 表示用户没有点击,相反, \(y=1\) 表示用户点击。 - 类别特征:比如性别、地理位置、收入情况等等。 - 连续性特征, 比如平均花费、平均停留时间等等
类别特征 (categorical feature) 一般被表示成一个one-hot之后的向量, 而一个连续特征, 一般就是表示它自 己, 当然也可以离散化成one-hot向量。我们把这些特征全部处理完之后, 整个向量会转化成 得x向量变得非常稀疏。所以我们要做的就是在这样特征比较稀疏的样本上简历一个CTR预测模型。
1.3 DeepFM
我们希望能够设计模型能够更好地学习低维和高维特征之间的交互,基于这点,我们在深度模型的基础上结合了FM,推出了DeepFM模型。它的整体结构如下图:
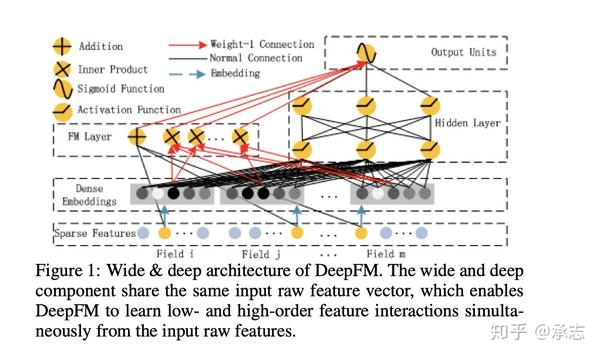
这张图看起来可能会有点乱,我们可以先忽略一些局部的细节,先从整体上把握。这个模型可以分成两个部分,分别是FM部分以及Deep部分。这两个部分的输入是一样的,并没有像Wide & Deep模型那样做区分。
- 神经网络也就是Deep的部分用来训练这些特征的一维的关联以及联系
- FM模型会通过隐藏向量V的形式来计算特征之间的二维交叉的信息。最后一维和二维的信息汇总到一起,进入sigmoid层,获得最终的结果。
用公式来表达的话,大概是这样:
\[ \hat{y}=\operatorname{sigmoid}\left(y_{F M}+y_{D N N}\right) \]
1.4 FM部分

FM部分其实就是因子分解机, 我们在之前的文章当中曾经专门剖析过。FM会考虑所有特征之间两两交叉的情况, 相当于人为对左右特征做了交叉。但是由于 \(n\) 个特征交叉的组合是 \(n^2\) 这个量级, 所以FM设计了一种新的方案, 对 于每一个特征i训练一个向量 \(V_i\), 当i和 \(\mathrm{j}\) 两个特征交叉的时候, 通过 \(V_i \cdot V_j\) 来计算两个特征交叉之后的权重。这样 大大降低了计算的复杂度。 这当中涉及一些公式的推导和计算, 我们在之前的文章当中已经详细推导过了, 这里就不多㥿述了。最终我们可以 得到这部分的公式: \[ y_{F M}=<w, x>+\sum_{i=1}^d \sum_{j=i+1}^d<V_i, V_j>x_i \cdot x_j \]
1.5 Deep部分
Deep部分就是经典的前馈网络,用来学习特征之间的高维交叉。
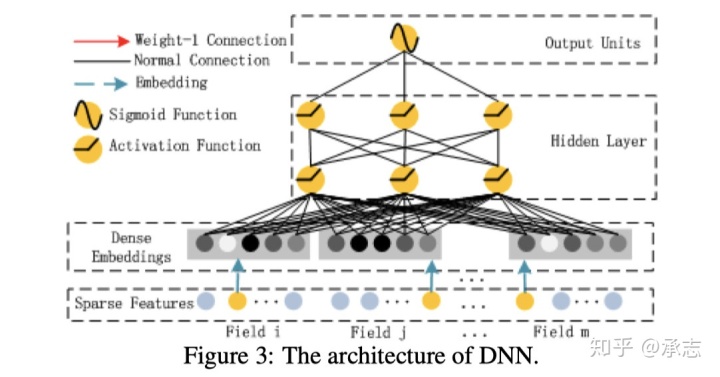
图3展示的就是模型当中Deep这个部分,从图中我们可以看到,所有的特征都会被转化成embedding向量作为Deep部分的输入( 每个01向量对应自己的嵌入层,不同向量的嵌入过程相互独立)。CTR预估的模型和图片以及音频处理的模型有一个很大的不同,就是它的维度会更大,并且特征会非常稀疏,还伴有类别连续、混合、聚合的特点。在这种情况下,使用embedding向量来把原始特征当中的信息压缩到低维的向量就是一种比较好的做法了,这样模型的泛化能力会更强,要比全是01组成的multi-hot输入好得多。

这张图展示了这个部分局部的结构,我们可以看到所有特征转成的embedding向量拥有相同的维度k。并且和FM模型当中的维度也是一样的,并且这个embedding的初始化也是借用FM当中的二维矩阵V来实现的。我们都知道V是一个d x k的二维矩阵,而模型原始输入是一个d维的01向量,那么和V相乘了之后,自然就转化成了d x k的embedding了。
这里要注意的一点是,在一些其他DNN做CTR预估的论文当中,会使用预训练的FM模型来进行Deep部分的向量初始化。但这里的做法略有不同,它不是使用训练好的FM来进行初始化,而是和FM模型的部分共享同样的V。这样做会有两个非常重要的好处:
- 它可以同时学习到低维以及高维的特征交叉信息,预训练的FM来进行向量初始化得到的embedding当中可能只包含了二维交叉的信息。
- 这样可以避免像是Wide & Deep那样多余的特征工程。
##### 数据选择
我们选择了两份数据用来评估DeepFM与其他模型的性能,一份是Criteo数据集,其中包含了4500w用户的点击数据,由13个连续型特征以及26个类别特征组成。我们把90%做成训练数据,10%做成测试数据。第二份数据是公司内部(华为)的数据,由连续7天用户在华为app store游戏中心的点击数据组成训练数据(约10亿条),1天的数据作为测试数据。
##### 评估指标
我们主要评估模型的指标有两个,一个是AUC另一个是Logloss(交叉熵)。从这个评估指标上来看是比较中肯的,没有像有一些paper当中自己定义一种新的评估指标。
DeepFM Q&A
DeepFM对连续特征的处理?
deepfm原文提到,连续变量可以直接作为单个值输入,或者离散化作为一个向量输入。那么目前可获取的包 deepctr中的deepfm是怎样处理的?
这里直接看源码,红色方框:

可以看到连续特征(dense_value) 直接作为DNN的输入,不参与FM的输入。我们也可以连续变量离散化后,同时作为DNN和FM的输入,这样连续变量也和类别变量有二阶特征交互,或许可以带来更多的信息,增强模型表达。