风控反欺诈(3)Fraudar:二部图反欺诈
Fraudar:二部图反欺诈
图异常检测系列文章:
可以说电商的发展,滋生并带火了一个由出资店铺、刷单中介、各级代理、刷手、空包物流组成的刷单产业。
一、黑产与反欺诈
关系网络与二部图
不同于对个体自身特征的分析,网络提供了对多个对象的关系之间另一种看问题的视角。把对象看做结点,把交互看成边,对象间的发生的各种关联自然会构成一张关系网络。从图论的角度出发,根据结点属性的不同可以把网络分为同构图和异构图。同构图是由同一种结点组成的关系网络,如家庭亲属关系、社交好友关系、论文间的引用关系等。历史上对于同构图的网络表示有很多研究,早在十九世纪就形成了几何拓扑学这一数学分支。在现代的同构关系研究中也逐步提出了基于网页链接的谷歌PageRank网页评级、基于结点关系紧密度的Louvian社区发现等重要算法。不过异构图在生活中的表现更为广泛,异构图是由不同属性的结点组成的关系网络,如由买方卖方以及中介组成的交易网络、由大V和其关注者组成的关注网络、由手机号。二部图(也叫二分图)是异构网络的一种,它由两类结点组成,并且同类结点之间通常没有关联。前述的刷单欺诈,即是以出资店铺和刷手这两类结点组成的交易关系二部图。

二部图下的欺诈
两类结点组成的欺诈场景还可以举出很多例子,如电商场景下用户对商户的薅羊毛、刷好评,如社交场景下水军账号的虚假关注、转发,又如消金场景下用户与商户勾结对平台的消费贷套现欺诈。 这些行为都会使两类结点之间出现异常的连接分布,从整体网络看来其呈现出了一张致密的双边连接子图,且该子图内的结点与图外结点联系相对较少。我们把这种大量的、同步的非正常关联行为模式称之为Lockstep,即在本不应出现聚集行为的二部图自然关系网络中,出现了双边聚集性行为。
只要能把欺诈行为总结成一种模式,自然可以将其分离出来。但是欺诈者往往会对自己做出某种伪装以使自己看起来有向好的一面,意图绕过风控系统。如在刷单欺诈场景下,为了尽量贴近真实用户的购买习惯,刷单平台会对刷手提出一系列要求,比如要求货比三家、要求最低浏览时长、要求滚动浏览高度及停留时间、要求对于正常热销商品做一定购买等,这些行为都会导致风控经验指标和模型特征的部分失效。在二部图交易网络中,对于正常热销商品的购买体现为刷手为自己增加了一些优异的边连接,使自己看起来更像一个正常的消费者结点。 我们需要一种能从这种复杂关系网络中对抗伪装、抽丝剥茧的提取出异常致密子图的算法。接下来对症下药引入Fraudar。Fraudar算法来源于2016年的KDD会议,并获得了当年的最佳论文奖。
二、Fraudar算法介绍- 无监督异常簇检测
FRAUDAR: Bounding Graph Fraud in the Face of Camouflagedl.acm.org/doi/pdf/10.1145/2939672.2939747
简单来说,Fraudar定义了一个可以表达结点平均可疑度的全局度量G(·),在逐步贪心移除可疑度最小结点的迭代过程中,使G(·)达到最大的留存结点组成了可疑度最高的致密子图。接下来我们稍微细化一下算法过程,以刷单交易场景为例(定义二部图结点集合S=[A,B],其中A、B分别代表消费者和店铺的结点集合),看Fraudar是如何从交易网络剥离出刷手和其出资店铺的。
网络水军、刷量刷单等行为在互联网中屡见不鲜,如何检测网络中的该类行为,即异常簇,是值得研究的问题。本文介绍一种图异常簇检测方案-FRAUDAR,该方法在具有14.7亿条边的Twitter社交网络中成功检测出了一系列刷量账户。
2.1 论文贡献
- 提出了一组满足公理的指标,且兼具多种优点。
- 提出了一个可证明的界限,即某个欺诈账户可以在图中有多少欺诈行为而不被抓获,即使是在伪装的情况下。接着通过新的优化改进了该界限,使其能够更好地区分真实数据中的欺诈行为和正常行为。
- 该算法在超大规模的Twitter网络中被证明了是有效的且能够在接近线性时间复杂度内完成任务。
2.2 欺诈行为的特点
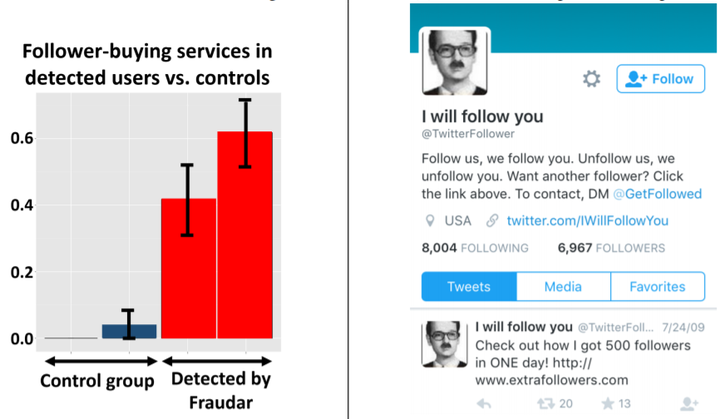
网络中存在不少水军刷量刷单的现象,该类欺诈行为在社交网络中尤其显著,其中"刷量者"可称为follower,"刷单目标"可以称为followee。下图展示了Twitter中的“僵尸粉”购买服务案例:左图红色和蓝色颜色的柱子分别代表了正常用户和欺诈用户,用户所属的两个柱子中左柱子表示followee的数量,右柱子表示follower的数量;右图展示了某个刷量账号,其个人简介中表示“只要你follow他那么他就会follow你”。
欺诈行为在网络的邻接矩阵视角下具有显著特征,某些“聪明”的刷量分子为了逃避检测往往会采取伪装(camouflage)来让自己看起来更像普通用户。下图从左到右分别展示了邻接矩阵中的随机伪装者、偏置伪装者和被劫持账户参与刷量行为。
2.3 FRAUDAR算法
FRAUDAR算法基于二部图表示,即网络中存在两种类型的节点Users和Objects。文中假设可能存在一个或多个User受到相关某个实体的控制,进而与Objects的某个子集交互而产生连边。算法所需的符号表示如下:

算法的目标是找到一个 \(S\), 并使得 \(S\) 构成子图的嫌疑指标 \(g(S)\) 最大。
子图内节点嫌疑度,即密集度指标 (density metrics) 可描述为: \(g(S)=\frac{f(S)}{|S|}\)
子图总嫌疑度 (total suspiciousness) 可描述为: \[ \begin{aligned} f(S) & =f_\nu(S)+f_{\varepsilon}(S) \\ & =\sum_{i \in S} a_i+\sum_{i, j \in S \wedge(i, j) \in \varepsilon} c_{i j}\end{aligned} \] 其中, \(a_i\) 和 \(c_{i j}\) 都是大于 0 的常数, \(a_i\) 即某个节点 \(i\) 的嫌疑度, 而 \(c_{i j}=\frac{1}{\log \left(d_j+c\right)}\) 可即边 \((i, j)\) 的嫌疑度, \(d_j\) 表示Object \(j\) 的度, \(c\) 是一个较小的常量。
由此,FRAUDAR算法可描述为如下过程:
- 将优先级最高的节点移出二部图
- 更新与移出节点相关的节点可疑度
- 反复执行步骤1和步骤2,直至所有节点都被移出
- 最后比较各轮迭代中节点的可疑度,找到最大可疑度对应的子图

算法中有如下两点值得注意:
1. 如何构造优先树
优先树本质上是一个小顶堆,其叶子节点为二部图中的Users或Objects,排序规则依赖于节点的嫌疑度。由此,根结点将记录全局嫌疑度最小的节点,将根节点从二部图中移出使得新子图中的节点具有最大的平均嫌疑度。
2. 如何更新可疑度
删除网络中的节点导致二部图结构被改变,因此每轮迭代后都需要在保持边可疑度不变的前提下,更新与被删除节点相关的节点可疑度,即相关节点减去被删节点的嫌疑度。