集成学习(7)总结
一、集成学习
常见的集成学习框架有三种:Bagging,Boosting 和 Stacking。三种集成学习框架在基学习器的产生和综合结果的方式上会有些区别,我们先做些简单的介绍。

本文主要介绍基于集成学习的决策树,其主要通过不同学习框架生产基学习器,并综合所有基学习器的预测结果来改善单个基学习器的识别率和泛化性。
模型的准确度可由偏差和方差共同决定: \[ \text { Error }=\text { bias }^{2}+\operatorname{var}+\xi \]
模型总体期望: \[ \begin{aligned} E(F) &=E\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} r_{i} E\left(f_{i}\right) \end{aligned} \] 模型总体方差: \[ \begin{aligned} \operatorname{Var}(F) &=\operatorname{Var}\left(\sum_{i}^{m} r_{i} f_{i}\right) \\ &=\sum_{i}^{m} \operatorname{Var}\left(r_{i} f_{i}\right)+\sum_{i \neq j}^{m} \operatorname{Cov}\left(r_{i} f_{i}, r_{j} f_{j}\right) \\ &=\sum_{i}^{m} r_{i}{ }^{2} \operatorname{Var}\left(f_{i}\right)+\sum_{i \neq j}^{m} \rho r_{i} r_{j} \sqrt{\operatorname{Var}\left(f_{i}\right)} \sqrt{\operatorname{Var}\left(f_{j}\right)} \\ &=m r^{2} \sigma^{2}+m(m-1) \rho r^{2} \sigma^{2} \\ &=m r^{2} \sigma^{2}(1-\rho)+m^{2} r^{2} \sigma^{2} \rho \end{aligned} \]
| 集成学习 | Bagging | Boosting | Stacking |
|---|---|---|---|
| 思想 | 对训练集进行有放回抽样得到子训练集 | 基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习;基于贪心策略的前向加法 | 预测值将作为训练样本的特征值,进行训练得到最终预测结果。 |
| 样本抽样 | 有放回地抽取数据集 | 训练集不变 | |
| 样本权重 | 样本权重相等 | 不断调整样本的权重 | |
| 优化目标 | 减小的是方差 | 减小的是偏差 | |
| 基模型 | 强模型(偏差低,方差高) | 弱模型(偏差高,方差低)而整体模型的偏差由基模型累加而成,故基模型需要为弱模型。 | 强模型(偏差低,方差高) |
| 相关性 | 对于 Boosting 来说,由于基模型共用同一套训练集,所以基模型间具有强相关性,故模型间的相关系数近似等于 1 | ||
| 模型偏差 | 整体模型的偏差与基模型近似。(\(\mu\)) | 基于贪心策略的前向加法,随着基模型数的增多,偏差减少。 | |
| 模型方差 | 随着模型的增加可以降低整体模型的方差,故其基模型需要为强模型;(\(\frac{\sigma^{2}(1-\rho)}{m}+\sigma^{2} \rho\)) | 整体模型的方差与基模型近似(\(\sigma^{2}\)) |
1.1 Bagging
Bagging 全称叫 Bootstrap aggregating,,每个基学习器都会对训练集进行有放回抽样得到子训练集,比较著名的采样法为 0.632 自助法(Bootstrap)。每个基学习器基于不同子训练集进行训练,并综合所有基学习器的预测值得到最终的预测结果。Bagging 常用的综合方法是投票法,票数最多的类别为预测类别。
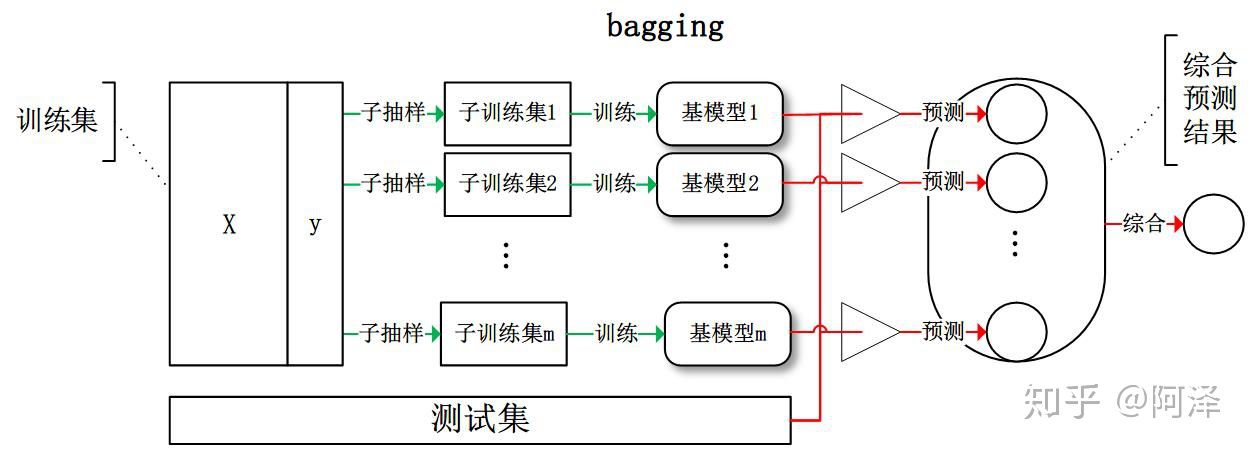
1.2 Boosting
Boosting 训练过程为阶梯状,基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果,用的比较多的综合方式为加权法。
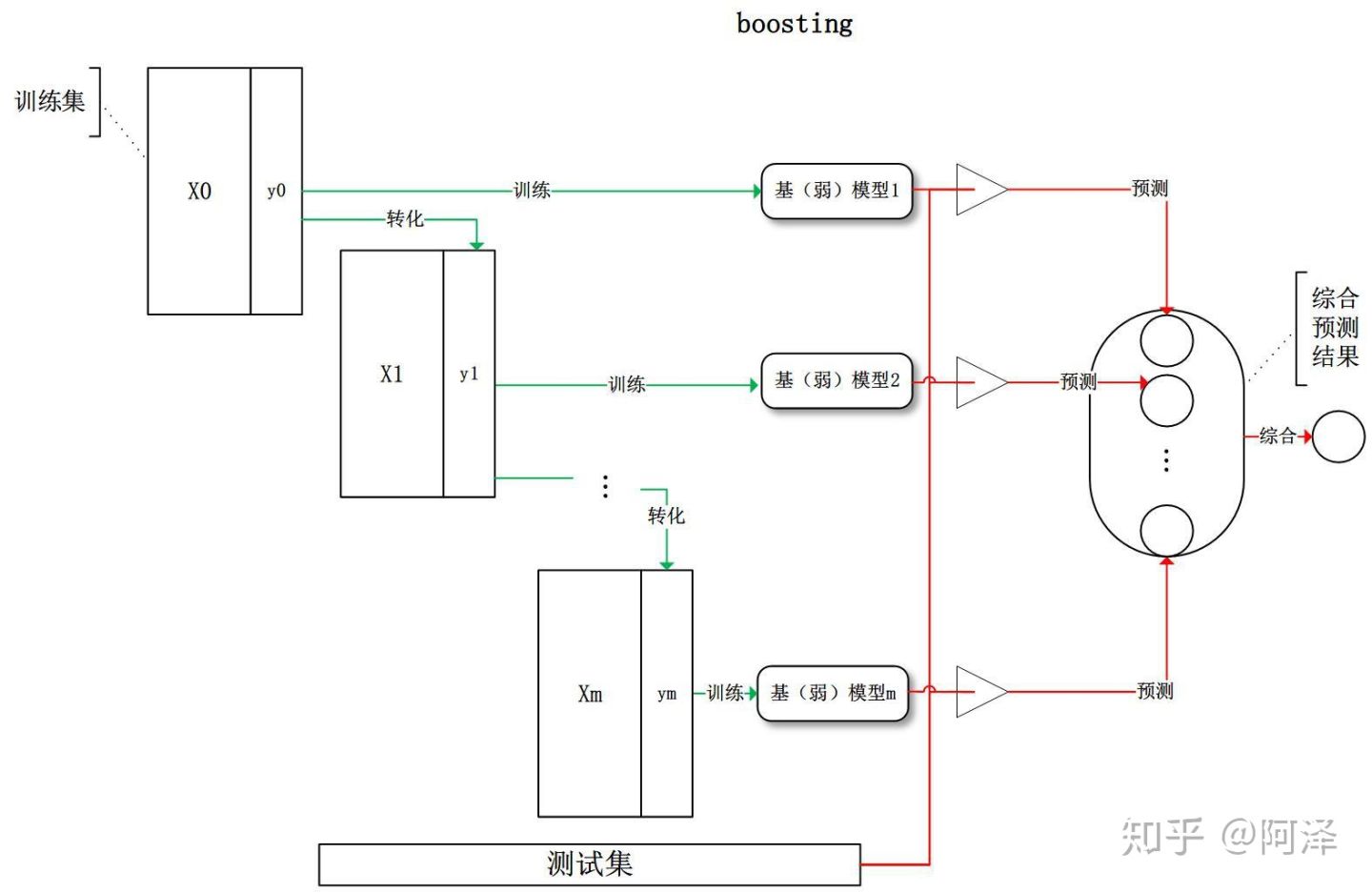
1.3 Stacking
Stacking 是先用全部数据训练好基模型,然后每个基模型都对每个训练样本进行的预测,其预测值将作为训练样本的特征值,最终会得到新的训练样本,然后基于新的训练样本进行训练得到模型,然后得到最终预测结果。

那么,为什么集成学习会好于单个学习器呢?原因可能有三:
训练样本可能无法选择出最好的单个学习器,由于没法选择出最好的学习器,所以干脆结合起来一起用;
假设能找到最好的学习器,但由于算法运算的限制无法找到最优解,只能找到次优解,采用集成学习可以弥补算法的不足;
可能算法无法得到最优解,而集成学习能够得到近似解。比如说最优解是一条对角线,而单个决策树得到的结果只能是平行于坐标轴的,但是集成学习可以去拟合这条对角线。
1.4 Stacking vs 神经网络
- https://zhuanlan.zhihu.com/p/32896968
本文的核心观点是提供一种对于stacking的理解,即与神经网络对照来看。当然,在阿萨姆:为什么做stacking之后,准确率反而降低了?中我已经说过stacking不是万能药,但往往很有效。通过与神经网络的对比,读者可以从另一个角度加深对stacking的理解。
1.4.1 Stacking是一种表示学习(representation learning)
表示学习指的是模型从原始数据中自动抽取有效特征的过程,比如深度学习就是一种表示学习的方法。关于表示学习的理解可以参考:阿萨姆:人工智能(AI)是如何处理数据的?
原始数据可能是杂乱无规律的。在stacking中,通过第一层的多个学习器后,有效的特征被学习出来了。从这个角度来看,stacking的第一层就是特征抽取的过程。在[1]的研究中,上排是未经stacking的数据,下排是经过stacking(多个无监督学习算法)处理后的数据,我们显著的发现红色和蓝色的数据在下排中分界更为明显。数据经过了压缩处理。这个小例子说明了,有效的stacking可以对原始数据中的特征有效的抽取。
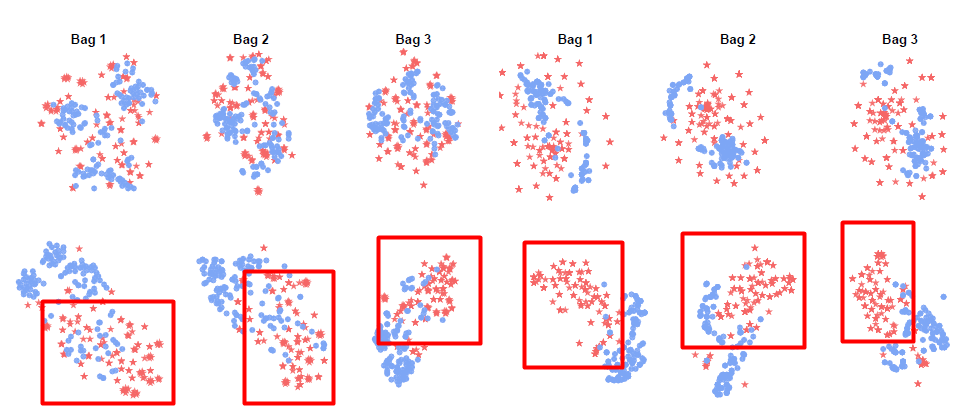
1.4.2 Stacking和神经网络从某种角度看有异曲同工之妙,神经网络也可以被看作是集成学习
承接上一点,stacking的学习能力主要来自于对于特征的表示学习,这和神经网络的思路是一致的。这也是为什么我说“第一层”,“最后一层”。
而且神经网络也可以被看做是一种集成学习,主要取决于不同神经元、层对于不同特征的理解不同。从浅层到深层可以理解为一种从具体到抽象的过程。
Stacking中的第一层可以等价于神经网络中的前 n-1层,而stacking中的最终分类层可以类比于神经网络中最后的输出层。不同点在于,stacking中不同的分类器通过异质来体现对于不同特征的表示,神经网络是从同质到异质的过程且有分布式表示的特点(distributed representation)。Stacking中应该也有分布式的特点,主要表现在多个分类器的结果并非完全不同,而有很大程度的相同之处。
但同时这也提出了一个挑战,多个分类器应该尽量在保证效果好的同时尽量不同,stacking集成学习框架的对于基分类器的两个要求:
- 差异化(diversity)要大
- 准确性(accuracy)要高
1.4.3 Stacking 的输出层为什么用逻辑回归?
表示学习的过拟合问题:
- 仅包含学习到的特征
- 交叉验证
- 简单模型:逻辑回归
如果你看懂了上面的两点,你应该可以理解stacking的有效性主要来自于特征抽取。而表示学习中,如影随形的问题就是过拟合,试回想深度学习中的过拟合问题。
在[3]中,周志华教授也重申了stacking在使用中的过拟合问题。因为第二层的特征来自于对于第一层数据的学习,那么第二层数据中的特征中不该包括原始特征,以降低过拟合的风险。举例:
- 第二层数据特征:仅包含学习到的特征
- 第二层数据特征:包含学习到的特征 + 原始特征
另一个例子是,stacking中一般都用交叉验证来避免过拟合,足可见这个问题的严重性。
为了降低过拟合的问题,第二层分类器应该是较为简单的分类器,广义线性如逻辑回归是一个不错的选择。在特征提取的过程中,我们已经使用了复杂的非线性变换,因此在输出层不需要复杂的分类器。这一点可以对比神经网络的激活函数或者输出层,都是很简单的函数,一点原因就是不需要复杂函数并能控制复杂度。
1.4.4 Stacking是否需要多层?第一层的分类器是否越多越好?
通过以上分析,stacking的表示学习不是来自于多层堆叠的效果,而是来自于不同学习器对于不同特征的学习能力,并有效的结合起来。一般来看,2层对于stacking足够了。多层的stacking会面临更加复杂的过拟合问题,且收益有限。
第一层分类器的数量对于特征学习应该有所帮助,经验角度看越多的基分类器越好。即使有所重复和高依赖性,我们依然可以通过特征选择来处理,问题不大。
二、偏差与方差
上节介绍了集成学习的基本概念,这节我们主要介绍下如何从偏差和方差的角度来理解集成学习。
2.1 集成学习的偏差与方差
偏差(Bias)描述的是预测值和真实值之差;方差(Variance)描述的是预测值作为随机变量的离散程度。放一场很经典的图:

模型的偏差与方差
- 偏差:描述样本拟合出的模型的预测结果的期望与样本真实结果的差距,要想偏差表现的好,就需要复杂化模型,增加模型的参数,但这样容易过拟合,过拟合对应上图的 High Variance,点会很分散。低偏差对应的点都打在靶心附近,所以喵的很准,但不一定很稳;
- 方差:描述样本上训练出来的模型在测试集上的表现,要想方差表现的好,需要简化模型,减少模型的复杂度,但这样容易欠拟合,欠拟合对应上图 High Bias,点偏离中心。低方差对应就是点都打的很集中,但不一定是靶心附近,手很稳,但不一定瞄的准。
我们常说集成学习中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型,但并不是所有集成学习框架中的基模型都是弱模型。Bagging 和 Stacking 中的基模型为强模型(偏差低,方差高),而Boosting 中的基模型为弱模型(偏差高,方差低)。
2.2 Bagging 的偏差与方差
- 整体模型的期望等于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。
- 整体模型的方差小于等于基模型的方差,当且仅当相关性为 1 时取等号,随着基模型数量增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于 1 吗?并不一定,当基模型数增加到一定程度时,方差公式第一项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。
2.3 Boosting 的偏差与方差
- 整体模型的方差等于基模型的方差,如果基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,Boosting 框架中的基模型必须为弱模型。
- 此外 Boosting 框架中采用基于贪心策略的前向加法,整体模型的期望由基模型的期望累加而成,所以随着基模型数的增多,整体模型的期望值增加,整体模型的准确度提高。
2.4 小结
- 我们可以使用模型的偏差和方差来近似描述模型的准确度;
- 对于 Bagging 来说,整体模型的偏差与基模型近似,而随着模型的增加可以降低整体模型的方差,故其基模型需要为强模型;
- 对于 Boosting 来说,整体模型的方差近似等于基模型的方差,而整体模型的偏差由基模型累加而成,故基模型需要为弱模型。
三、GBDT、XGBoost、LIghtGBM
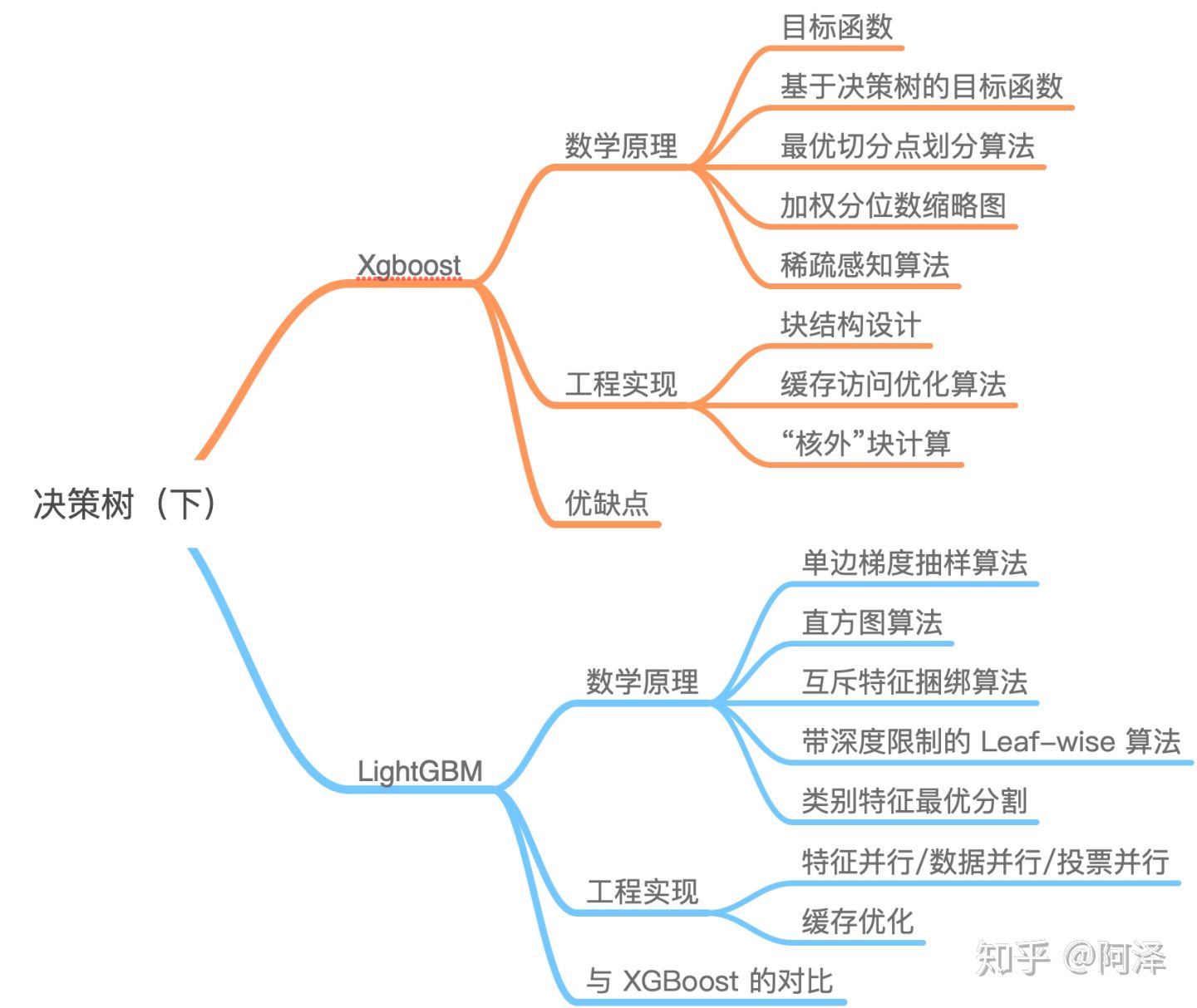
| Boosting 算法 | GBDT | XGBoost | LightGBM |
|---|---|---|---|
| 思想 | 回归树、梯度迭代、缩减;GBDT 的每一步残差计算其实变相地增大了被分错样本的权重,而对与分对样本的权重趋于 0 | 二阶导数、线性分类器、正则化、缩减、列抽样、并行化 | 更快的训练速度和更低的内存使用 |
| 目标函数 | \(y-F_{k}(x)\) | \(\Omega\left(f_{t}\right)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}\) | \(\Omega\left(f_{t}\right)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}\) |
| 损失函数 | 最小均方损失函数、绝对损失或者 Huber 损失函数 | 【线性】最小均方损失函数、sigmod和softmax | - |
| 基模型 | CART模型 | CART模型/ 回归模型 | - |
| 抽样算法 | 无 | 列抽样:借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算; | 单边梯度抽样算法;根据样本梯度来对梯度小的这边样本进行采样,一部分大梯度和随机分布 |
| 切分点算法 | CART模型 | 预排序、贪心算法、近似算法(加权分位数缩略图) | 直方图算法:内存消耗降低,计算代价减少;(不需要记录特征到样本的索引) |
| 缺失值算法 | CART模型 | 稀疏感知算法:选择增益最大的枚举项即为最优缺省方向。【 稀疏数据优化不足】【gblinear 补0】 | 互斥特征捆绑算法:互斥指的是一些特征很少同时出现非0值。稀疏感知算法;【gblinear 补0】 |
| 建树策略 | Level-wise:基于层进行生长,直到达到停止条件; | Level-wise:基于层进行生长,直到达到停止条件; | Leaf-wise:每次分裂增益最大的叶子节点,直到达到停止条件。 |
| 正则化 | 无 | L1 和 L2 正则化项 | L1 和 L2 正则化项 |
| Shrinkage(缩减) | 有 | 有 | 有 |
| 类别特征优化 | 无 | 无 | 类别特征最优分割:many-vs-many |
| 并行化设计 | 无 | 块结构设计、 | 特征并行、 数据并行、投票并行 |
| 缓存优化 | 无 | 为每个线程分配一个连续的缓存区、“核外”块计算 | 1、所有的特征都采用相同的方法获得梯度;2、其次,因为不需要存储特征到样本的索引,降低了存储消耗 |
| 缺点 | 对异常点敏感; | 预排序:仍需要遍历数据集; 不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。 | 内存更小: 索引值、特征值边bin、互斥特征捆绑; 速度更快:遍历直方图;单边梯度算法过滤掉梯度小的样本;基于 Leaf-wise 算法的增长策略构建树,减少了很多不必要的计算量;特征并行、数据并行方法加速计算 |
四、集成学习Q&A
4.1 为什么gbdt和随机森林(稍好点)都不太适用直接用高维稀疏特征训练集?
原因:
gbdt这类boosting或者rf这些bagging集成分类器模型的算法,是典型的贪心算法,在当前节点总是选择对当前数据集来说最好的选择
一个6层100树的模型,要迭代2^(5 4 3 2 1 0)*100次,每次都根据当前节点最大熵或者最小误差分割来选择变量
那么,高维稀疏数据集里很多“小而美”的数据就被丢弃了,因为它对当前节点来说不是最佳分割方案(比如,关联分析里,支持度很低置信度很高的特征)
但是高维数据集里面,对特定的样本数据是有很强预测能力的,比如你买叶酸,买某些小的孕妇用品品类,对应这些人6个月后买奶粉概率高达40%,但叶酸和孕妇用品销量太小了,用户量全网万分之一都不到,这种特征肯定是被树算法舍弃的,哪怕这些特征很多很多。。它仍是被冷落的份。。。
方法:【LightGBM 互斥捆绑算法】
选择svm和lr这种能提供最佳分割平面的算法可能会更好;
但如果top.特征已经能够贡献很大的信息量了,比如刚才孕妇的案例,你用了一个孕妇用品一级类目的浏览次数购买金额购买次数这样的更大更强的特征包含了这些高维特征的信息量,那可能gbdt会更好
实际情况的数据集是,在数据仓库里的清洗阶段,你可以选择把它做成高维的特征,也可以选择用算法把它做成低维的特征,一般有
1-在数据清洗阶段,或用类目升级(三级类目升级到二三级类目)范围升级的方式来做特征,避免直接清洗出来高维特征
2-在特征生成后,利用数据分析结论简单直接的用多个高维特征合并(加减乘除逻辑判断都行,随你合并打分)的方式来做特征,前提你hold得住工作量判断量,但这个如果业务洞察力强效果有可能特别好
3-在特征工程的特征处理阶段,我们可以用PCA因子构建等降维算法做特征整合,对应训练集,也这么搞,到时候回归或预测的时候,就用这个因子或者主成分的值来做特征
4.1 为什么集成学习的基分类器通常是决策树?还有什么?
基分类器通常是决策树:样本权重、方便调节、随机性;
- 决策树可以较方便地将样本权重整合到训练过程中,而不需要通过过采样来调整样本权重。
- 树的表达能力和泛化能力,方便调节(可以通过树的层数来调节)
- 样本的扰动对决策树的影响较大, 因此不同子样本集合生成的决策树基分类器随机性较大。这样的不稳定的分类器更适合作为基分类器。此外树节点分类时随机选择一个特征子集,从中找出最优分裂属性,很好地引入了随机性。
4.2 可以将随机森林的基分类器,由决策树替换成线性分类器或K-NN吗?
Bagging主要好处是集成后的方差,比基分类器小。bagging采用的基分类,最好是本身对样本分布较为敏感。而线性分类器和K-NN都是较为稳定的分类器(参数模型?)甚至可能因为采样,而导致他们再训练中更难收敛,从而增大了集成分类器的偏差。
4.3 为什么可以利用GBDT算法实现特征组合和筛选?【GBDT+LR】
GBDT模型是有一组有序的树模型组合起来的,前面的树是由对大多数样本有明显区分度的特征分裂构建而成,经过前面的树,仍然存在少数残差较大的样本,后面的树主要由能对这些少数样本有区分度的特征分裂构建。优先选择对整体有区分度的特征,然后再选择对少数样本有区分度的特征,这样才更加合理,所以GBDT子树节点分裂是一个特征选择的过程,而子树的多层结构则对特征组合的过程,最终实现特征的组合和筛选。
GBDT+LR融合方案:
(1)利用GBDT模型训练数据,最终得到一系列弱分类器的cart树。
(2)生成新的训练数据。将原训练数据重新输入GBDT模型,对于每一个样本,都会经过模型的一系列树,对于每棵树,将样本落到的叶子节点置为1,其他叶子为0,然后将叶子节点的数字从左至右的拼接起来,形成该棵树的特征向量,最后将所有树的特征向量拼接起来,形成新的数据特征,之后保留原样本标签形成新的训练数据。
(3)将上一步得到的训练数据作为输入数据输入到LR模型中进行训练
参考文献
【机器学习】决策树(中)——Random Forest、Adaboost、GBDT (非常详细):https://zhuanlan.zhihu.com/p/86263786
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
机器学习算法中GBDT与Adaboost的区别与联系是什么? - Frankenstein的回答 - 知乎 https://www.zhihu.com/question/54626685/answer/140610056
GBDT学习笔记 - 许辙的文章 - 知乎 https://zhuanlan.zhihu.com/p/169382376
GBDT - 王多鱼的文章 - 知乎 https://zhuanlan.zhihu.com/p/38057220