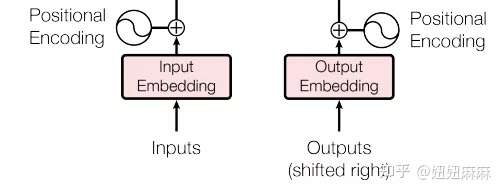
Positional Encodding位置编码的作用是为模型提供当前时间步的前后出现顺序的信息。因为Transformer不像RNN那样的循环结构有前后不同时间步输入间天然的先后顺序,所有的时间步是同时输入,并行推理的,因此在时间步的特征中融合进位置编码的信息是合理的。位置编码可以有很多选择,可以是固定的,也可以设置成可学习的参数。这里,我们使用固定的位置编码。具体地,使用不同频率的sin和cos函数来进行位置编码,如下所示:
\[
\begin{gathered}
P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{2 i / d_{\text {model
}}}\right) \\
P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\text {model
}}}\right)
\end{gathered}
\]
其中pos代表时间步的下标索引,向量也就是第pos个时间步的位置编码,编码长度同Embedding层,这里我们设置的是512。上面有两个公式,代表着位置编码向量中的元素,奇数位置和偶数位置使用两个不同的公式。思考:为什么上面的公式可以作为位置编码?我的理解:在上面公式的定义下,
时间步p和时间步p+k的位置编码的内积,即是与p无关,只与k有关的定值(不妨自行证明下试试)。也就是说,任意两个相距k个时间步的位置编码向量的内积都是相同的,这就相当于蕴含了两个时间步之间相对位置关系的信息。此外,每个时间步的位置编码又是唯一的,这两个很好的性质使得上面的公式作为位置编码是有理论保障的。下面是位置编码模块的代码实现:
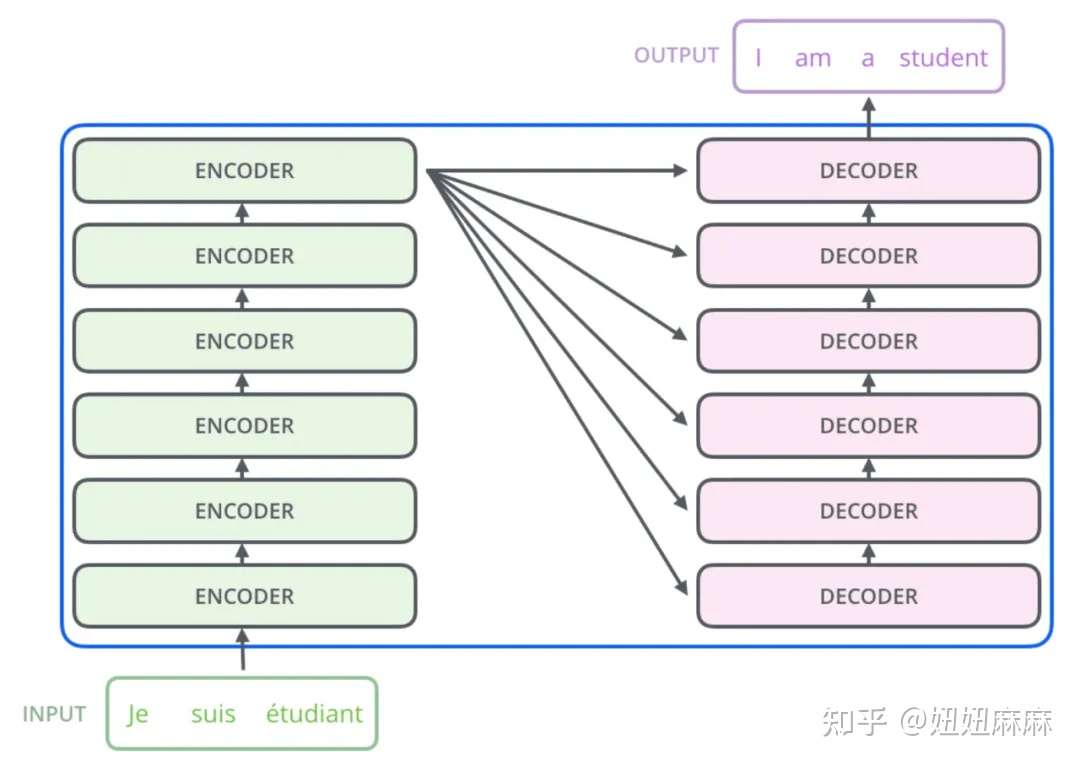
怎么理解?假设我们现在做的是一个法语-英语的机器翻译任务,想把Je suis étudiant翻译为I am a student。那么我们输入给编码器的就是时间步数为3的embedding数组,编码器只进行一次并行推理,即获得了对于输入的法语句子所提取的若干特征信息。而对于解码器,是循环推理,逐个单词生成结果的。最开始,由于什么都还没预测,我们会将编码器提取的特征,以及一个句子起始符传给解码器,解码器预期会输出一个单词I。然后有了预测的第一个单词,我们就将I输入给解码器,会再预测出下一个单词am,再然后我们将I am作为输入喂给解码器,以此类推直到预测出句子终止符完成预测。
# 定义一个clones函数,来更方便的将某个结构复制若干份 defclones(module, N): "Produce N identical layers." return nn.ModuleList([copy.deepcopy(module) for _ inrange(N)])
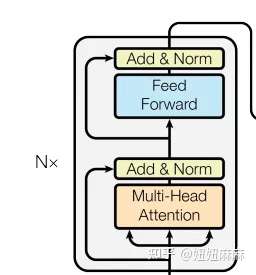
classEncoder(nn.Module): """ Encoder The encoder is composed of a stack of N=6 identical layers. """ def__init__(self, layer, N): super(Encoder, self).__init__() # 调用时会将编码器层传进来,我们简单克隆N分,叠加在一起,组成完整的Encoder self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) defforward(self, x, mask): "Pass the input (and mask) through each layer in turn." for layer in self.layers: x = layer(x, mask) return self.norm(x)
classMultiHeadedAttention(nn.Module): def__init__(self, h, d_model, dropout=0.1): #在类的初始化时,会传入三个参数,h代表头数,d_model代表词嵌入的维度,dropout代表进行dropout操作时置0比率,默认是0.1 super(MultiHeadedAttention, self).__init__() #在函数中,首先使用了一个测试中常用的assert语句,判断h是否能被d_model整除,这是因为我们之后要给每个头分配等量的词特征,也就是embedding_dim/head个 assert d_model % h == 0 #得到每个头获得的分割词向量维度d_k self.d_k = d_model // h #传入头数h self.h = h #创建linear层,通过nn的Linear实例化,它的内部变换矩阵是embedding_dim x embedding_dim,然后使用,为什么是四个呢,这是因为在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,因此一共是四个 self.linears = clones(nn.Linear(d_model, d_model), 4) #self.attn为None,它代表最后得到的注意力张量,现在还没有结果所以为None self.attn = None self.dropout = nn.Dropout(p=dropout) defforward(self, query, key, value, mask=None): #前向逻辑函数,它输入参数有四个,前三个就是注意力机制需要的Q,K,V,最后一个是注意力机制中可能需要的mask掩码张量,默认是None if mask isnotNone: # Same mask applied to all h heads. #使用unsqueeze扩展维度,代表多头中的第n头 mask = mask.unsqueeze(1) #接着,我们获得一个batch_size的变量,他是query尺寸的第1个数字,代表有多少条样本 nbatches = query.size(0) # 1) Do all the linear projections in batch from d_model => h x d_k # 首先利用zip将输入QKV与三个线性层组到一起,然后利用for循环,将输入QKV分别传到线性层中,做完线性变换后,开始为每个头分割输入,这里使用view方法对线性变换的结构进行维度重塑,多加了一个维度h代表头,这样就意味着每个头可以获得一部分词特征组成的句子,其中的-1代表自适应维度,计算机会根据这种变换自动计算这里的值,然后对第二维和第三维进行转置操作,为了让代表句子长度维度和词向量维度能够相邻,这样注意力机制才能找到词义与句子位置的关系,从attention函数中可以看到,利用的是原始输入的倒数第一和第二维,这样我们就得到了每个头的输入 query, key, value = \ [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x inzip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch. # 得到每个头的输入后,接下来就是将他们传入到attention中,这里直接调用我们之前实现的attention函数,同时也将mask和dropout传入其中 x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear. # 通过多头注意力计算后,我们就得到了每个头计算结果组成的4维张量,我们需要将其转换为输入的形状以方便后续的计算,因此这里开始进行第一步处理环节的逆操作,先对第二和第三维进行转置,然后使用contiguous方法。这个方法的作用就是能够让转置后的张量应用view方法,否则将无法直接使用,所以,下一步就是使用view重塑形状,变成和输入形状相同。 x = x.transpose(1, 2).contiguous() \ .view(nbatches, -1, self.h * self.d_k) #最后使用线性层列表中的最后一个线性变换得到最终的多头注意力结构的输出 return self.linears[-1](x)
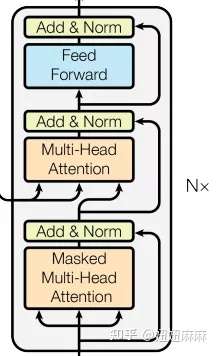
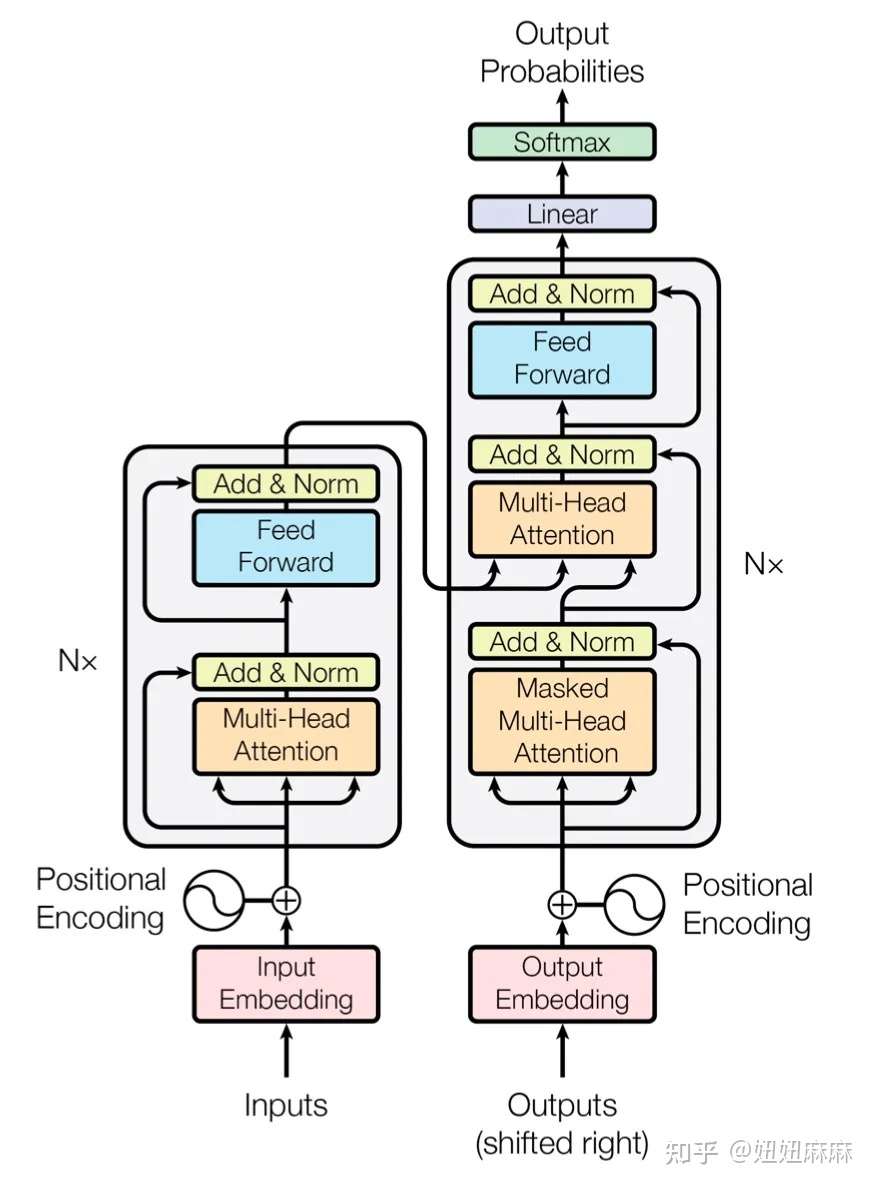
有一个细节需要注意,第一个子层的多头注意力和编码器中完全一致,
第二个子层,它的多头注意力模块中,query来自上一个子层,key 和 value
来自编码器的输出。可以这样理解,就是第二层负责,利用解码器已经预测出的信息作为query,去编码器提取的各种特征中,查找相关信息并融合到当前特征中,来完成预测。
hidden(32 x 512 x 768) -> Q(32 x 512 x 768) -> 32 x 12 x 512 x
64 hidden(32 x 512 x 768) -> K(32 x 512 x 768) -> 32 x 12 x 512 x
64 hidden(32 x 512 x 768) -> V(32 x 512 x 768) -> 32 x 12 x 512 x
64
step2:然后Q和K之间做attention,得到一个32 x 12 x
512 x 512的权重矩阵(时间复杂度O(
)),然后根据这个权重矩阵加权V中切分好的向量,得到一个32 x 12 x 512 x 64
的向量,拉平输出为768向量。
32 x 12 x 512 x 64(query_hidden) * 32 x 12 x 64 x 512(key_hidden)
-> 32 x 12 x 512 x 512 32 x 12 x 64 x 512(value_hidden) * 32 x 12 x
512 x 512 (权重矩阵) -> 32 x 12 x 512 x 64
然后再还原成 -> 32 x 512 x 768
。简言之是12个头,每个头都是一个64维度,分别去与其他的所有位置的hidden
embedding做attention然后再合并还原。
![[公式]](https://www.zhihu.com/equation?tex=A%28Q%2CK%2CV%29%3D%5Cmathrm%7BSoftmax%7D%28QK%5ET%29V+%5C%5C+)
![[公式]](https://www.zhihu.com/equation?tex=Q%2CK%2CV%3An%5Ctimes+d)
:
与
运算,得到
矩阵,复杂度为
,则n行的复杂度为
; 对于受限的self-attention,每个元素仅能和周围
个元素进行交互,即和
维向量做内积运算,复杂度为
,则
个元素的总时间复杂度为
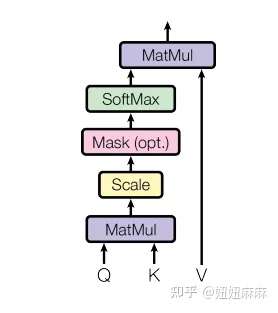
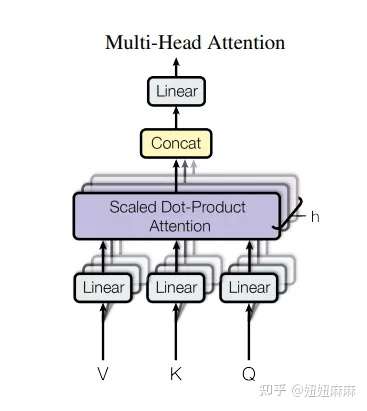
![[公式]](https://www.zhihu.com/equation?tex=%5Cmathrm%7BMultiHead%7D%28Q%2CK%2CV%29%3D%5Cmathrm%7BConcat%28head_1%2C...%2Chead_h%29%7DW%5EO+%5C%5C+%5Cmathrm%7Bwhere%5Cquad+head_i%7D%3DA%28QW_i%5EQ%2CKW_i%5EK%2CVW_i%5EV%29%5C%5C)
个head,这里
维度。这里考虑一种简化情况:
。(对于dot-attention计算方式,
与
可以不同)。
与
运算,忽略常系数,复杂度为
。
与
运算,复杂度为
计算,复杂度为