流量反作弊(3)2023 BlackHat-Leveraging Streaming-Based Outlier Detection and SliceLine to Stop Heavily Distributed Bot Attacks

在本篇文章中我们将讨论DataDome公司[1]是如何利用基于流的异常值检测和 SliceLine 来快速安全地生成大量可用于阻止恶意流量的规则/签名。虽然机器学习(ML)的使用变得越来越普遍,但在安全环境中规则仍然很重要。事实上,公司已经投资了大量有效的规则引擎,能够快速评估大量规则。此外,规则通常更方便创建、操作和解释,因此在ML方法之外仍然很有价值。
虽然 SliceLine 最初设计用于识别 ML 模型表现不佳的数据子集,但它的使用可以适应以无监督方式生成大量与攻击相关的规则,即不使用标记数据。此外,利用机器人检测问题来说明如何使用 SliceLine 即时生成大量恶意签名。
该研究还将展示优化的 SliceLine Python 开源实现,并展示如何将其用于特定但困难的机器人检测子集:分布式凭证填充攻击,攻击者利用数千个受感染的 IP 地址进行攻击和绕过传统的安全机制,例如速率限制策略。通过一个真实世界的例子,该研究将首先解释如何使用基于流的检测来检测此类攻击,以及该研究如何使用数据建模在服务器端信号(HTTP 标头、TLS 指纹、IP 地址等)上应用 SliceLine 来识别并生成与分布式攻击相关的阻止签名。这种方法使该研究能够在去年阻止 59 位客户超过 2.85 亿次恶意登录尝试。
最后,该研究将解释这种方法如何推广到除机器人检测之外的其他安全用例,以及如何在不同的规则引擎中使用它。
一、说明
机器人检测是指识别和区分人类用户和自动化软件程序(Bot:Program to automate actions)的过程。术语“bot”可以指各种程序,包括搜索引擎爬虫和设计用于进行抢购或拒绝服务攻击的恶意bot。
机器人检测很重要,因为机器人可用于各种目的,其中一些可能是有害或不道德的。例如,机器人可用于进行欺诈活动,如账户接管或凭证填充,从网站中获取敏感信息,或在社交媒体平台上自动发布垃圾邮件。
- 凭证填充/账户接管→ 窃取用户帐户;
- DDoS攻击→ 使网站/移动应用程序不可用;
- Carding→ 测试被盗的信用卡;
- 操纵投票→ 生成虚假的浏览量,增加点赞、转发等数量。
可以使用多种技术和信号进行机器人检测,包括使用ML分析用户行为模式[2]、浏览器指纹识别[3][4]和其他形式的指纹识别,如TLS指纹识别[5]。一些常见的机器人活动指标包括高频请求、用户行为不一致的模式和使用非标准用户代理或其他识别信息。
有效的机器人检测是维护在线系统和平台安全和完整性的重要组成部分,并被广泛应用于各种组织,包括电子商务网站、社交媒体平台和金融机构。尽管ML技术越来越多地用于机器人检测,但大多数公司仍有高效的规则引擎可与ML算法配合使用。规则的优点是可以立即部署以减轻攻击,并且高度可解释,使它们成为ML机器人检测的良好补充。
在本文中,重点关注使用可以在应用层收集的信息进行机器人检测,更具体地说是HTTP头和客户端信息。特别是,该研究将解释如何使用流算法分析大量流量数据,识别异常事件或异常值,并分析底层流量签名以推断规则。这些技术可以转移到其他机器人检测信号和其他网络安全领域中,其中可以执行行为分析,以识别可疑数据部分,然后使用这些信息提取规则。
越来越多机器人使用的IP代理+社区驱动的反检测框架的绕过技术。利用数千个住宅代理分散他们的攻击,不断更改和伪造他们的签名/指纹。
- 使用代理分发攻击:避免基于IP的速率限制。
- 使用住宅代理分发攻击:避免基于信誉的阻止。
- 使用与目标网站位于同一国家/地区的住宅代理进行分布式攻击:避免地理阻塞。

二、手动检测和阻止分布式攻击
2.1 检测流量峰值

2.2 深入了解不同字段

2.3 观察一个规则
1 | Country=Russia && User Agent=Mozilla/5.0 (Macintosh;Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 |
指纹解析网站:https://www.useragentstring.com/Chrome99.0.4844.84_id_19983.php
How to automate the analysis?
三、使用 Sliceline检测和阻止分布式攻击
整体流程概述:
对用户进行聚合统计【有token实体的内容?】:
唯一User Agent的数量;
唯一IP的数量;
会话数量;
使用基于z-score的异常检测算法检测结果时间序列上的异常值【发现异常开始时间】;
推送描述攻击的事件(客户、开始时间);
在流式处理中实施(使用Apache Flink),使用Sliceline自动化生成规则;
3.1 Sliceline 说明
(1)原理解析
Sliceline是由Sagadeeva等人提出的算法[1],可用于ML模型调试。在训练ML模型时,通常会计算模型在一些保留数据集上的平均性能(模型评估)。Sliceline允许找到特征空间中哪些区域负责非常高的==错误率==。换句话说,它找到特征切片,即模型表现低于平均水平的特征空间的子空间。这些切片实际上表示为特征条件的合取式,可以轻松转换为规则。
该算法以数据集和数据集中每个样本的错误作为输入。它要求数据集中的特征是分类的。这适用于机器人检测问题,因为收集的数据大多是分类数据,例如用户代理、国家或有关设备类型的信息(GPU型号等)。请注意,这并不意味着它不能与连续特征一起使用。在连续特征的情况下,我们需要应用预处理来定义不同的间隔并将每个值分配到一个间隔中。这个过程称为二值化,将连续特征转换为分类特征。【这里应该是指离散化处理】
我们使用一个简单的例子来说明Sliceline的预期用例:调试ML模型。在下面例子中,考虑一个只有3个特征f1、f2和f3的数据集。此外,假设训练了一个分类模型,并计算了保留数据集中每个样本相关的对数损失(交叉熵损失函数)。
二分类交叉熵损失函数:对数损失(log loss)是一种用于评估分类模型预测结果的损失函数。对数损失通常用于二元分类问题,它测量了模型预测的概率分布与实际标签的差异。对数损失越小,表示模型的预测结果越接近于真实标签,因此模型的性能越好。对数损失的取值范围是0到正无穷,当模型的预测完全准确时,对数损失为0,而当模型的预测完全错误时,对数损失趋近于正无穷。对数损失越大,表示模型的预测与真实标签之间的差异越大,因此模型的性能越差。
\[ J(\theta)=-\frac{1}{N} \sum_{i=1}^N y^{(i)} \log \left(h_\theta\left(x^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right) \]
图1:具有3个分类特征和相关的每个样本错误的示例数据集

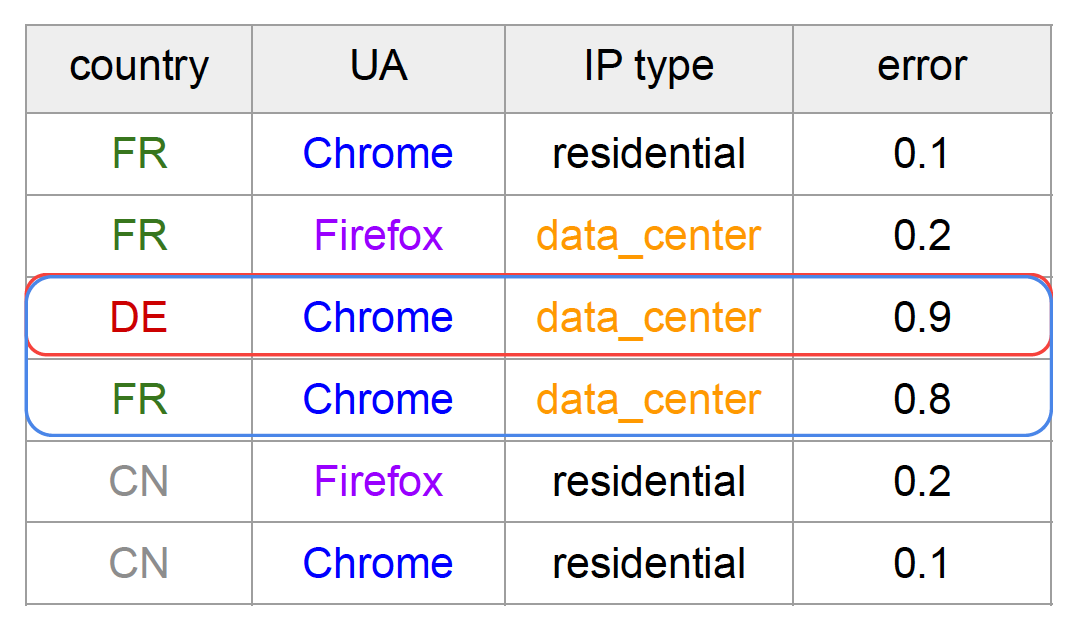
Sliceline可以通过此输入找到的切片示例有:
- f1 = b的平均误差为0.9;
- f2 = d ∧ f3 = f的平均误差为0.85;
这两个切片的误差都高于数据集的平均误差0.38。
原则上,我们寻找的切片可以是许多特征的组合,可能的切片空间随着特征的数量和基数的增加呈指数级增长。Sliceline通过使用两种技术来探索这个空间:【本质上是把原始数据转换为二进制向量,用逻辑运算与矩阵运算来代替数据扫描,加快速度】
- 枚举和评估使用稀疏线性代数的切片,这可以从现有的高效实现中获益;(Enumerating and evaluating slices using sparse linear algebra that can profit from existing efficient implementations.)
- 基于平衡切片大小和平均切片误差的分数,无需访问数据即可修剪切片候选项。(Pruning of slice candidates without accessing the data based on a score that balances between the slice size and the average slice error.)
这些技术使算法高效且可扩展,其确切复杂度高度依赖于数据集的细节。
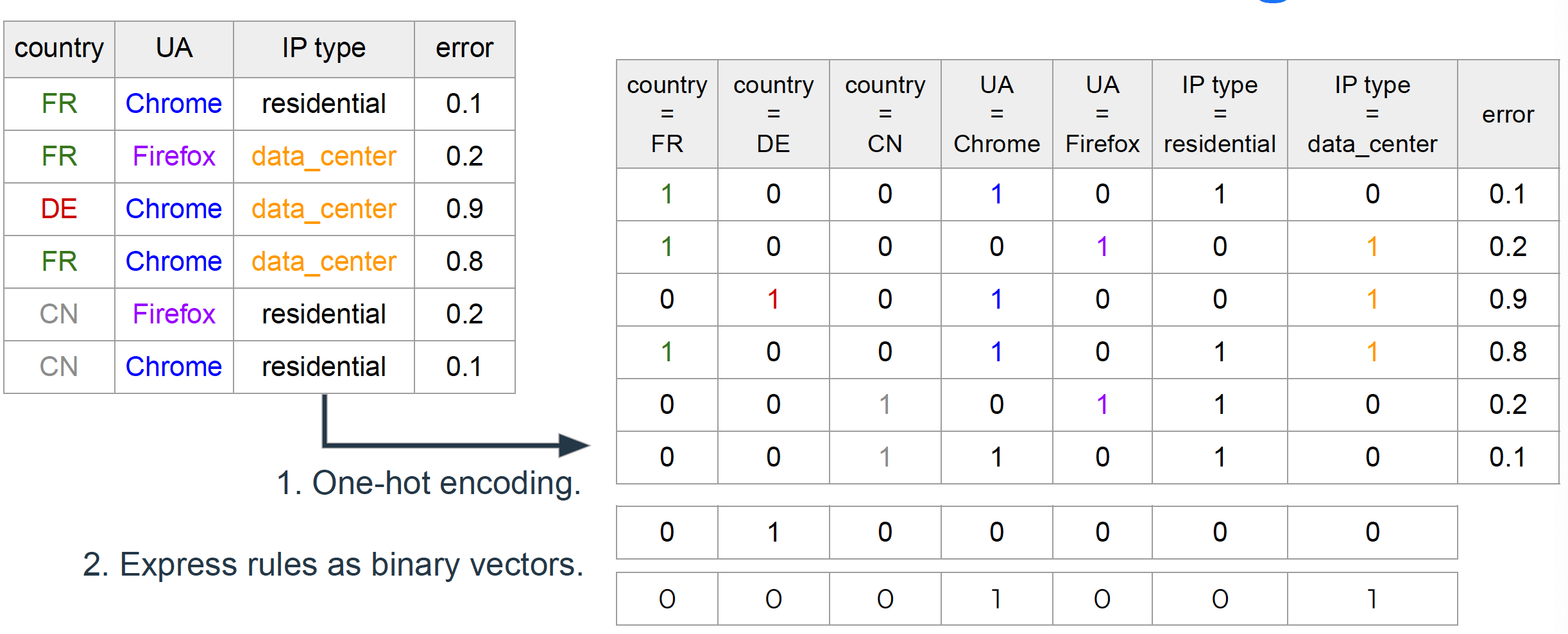
虽然在本文中我们不会详细介绍Sliceline算法的实现细节,但我们希望为读者提供一些有关使用线性代数评估和生成规则的直觉。首先,我们从玩具数据集开始,并进行第一次转换:独热编码。独热编码是一种方法,可以通过创建每个特征值的一列来将分类数据编码为数字。在下面的示例中,特征f1有3个值a、b和c,因此为了对其进行编码,我们创建了3个二进制列,如下所示。
图2:展示如何使用矩阵乘法来查找匹配样本的示例

同样的转换也允许我们将规则表示为二进制向量:向量将在实施条件的位置包含值1。例如,对于规则f1 = b,二进制向量的第二个元素将是1,因为此条件在独热编码空间的第二列中表示。我们可以用这种方式表示所有候选规则,并轻松计算指示哪个样本符合每个规则的掩码。如果我们将独热编码的特征矩阵F和规则矩阵R表示为F和R,则矩阵乘积FxR的结果正好给出了这一点:一个掩码,其中行对应于样本,列对应于规则。该矩阵的第i行第j列元素等于1,这意味着样本i与规则j匹配。

有了这个掩码L,我们可以轻松计算每个切片的平均误差,即与某个规则匹配的样本集的平均误差。这个计算在Sliceline算法中非常重要,因为它允许计算得分,根据这个得分,可以探索可能的切片空间。因此,为了计算平均切片误差,我们首先计算误差向量与掩码L的矩阵乘积,这给出了切片中的总误差(ET * L)。我们也可以计算L与单位向量的乘积,有效地计算匹配每个规则的样本数。最后,我们可以逐元素地将总误差和切片大小相除,以获得平均误差。这就是使用线性代数操作评估规则的主要思想。
图3:显示如何使用点积计算平均切片误差的示例

虽然Sliceline最初是作为一种模型调试技术提出的,但我们可以重新利用它,并将其用于生成针对特定数据组的规则。在网络安全的背景下,我们处于这样一种情况:防御者收集了来自两个数据组的数据:
- Group 0:一个被认为是正常的群体,主要由非恶意样本组成。
- Group 1:另一个数据组,包含恶意和正常流量样本。
可以将Group 0分配给正常数据,将Group 1分配给可疑数据。如果我们将该组视为我们提供给Sliceline算法的错误,它将找到针对可疑组的切片,因为它是具有更高误差的一组。我们在下面展示了相同的样例数据集,其中错误被组替换。
图4:具有3个分类特征和相关组的示例数据集

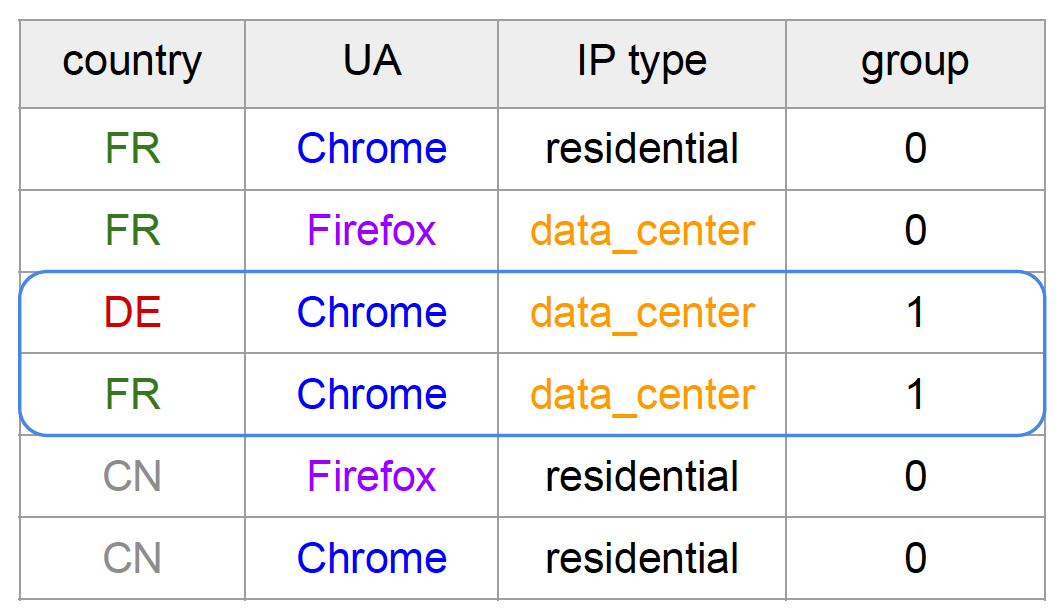
这种简单的技术允许我们生成针对机器人流量的规则,前提是我们可以定义两组不同的数据。
(1)Sliceline的Python开源优化实现
原论文作者[6]提供了R和Apache SystemDS的算法实现。我们决定使用Python实现它,并将其作为一个包开源给社区。我们首先重新使用Python实现了逻辑,然后实现了一些性能改进,这使得与R实现相比速度提高了1000倍。这是可能的,因为我们使用了可用的Python库,如Numpy,这些库利用底层的C++代码和稀疏矩阵。此外,我们还用矩阵乘法替换了一些for循环结构,进一步提高了速度。该包的源代码可在GitHub上获取[7],与pandas python库兼容,并遵循scikit-learn API规范。
(2)应用Sliceline到一个Demo-Bot检测数据集
在本节中,我们将Sliceline应用于一个简单的玩具数据集,该数据集由HTTP头和上下文信息组成,用于Bot检测问题。为简单起见,我们创建了一个流量数据集,具有人类和Bot的特征。我们使用了来自一个法国电子商务网站的数据。我们收集了来自法语国家的旧会话数据,并将它们分配给Group 0。我们还收集了来自同一网站的来自非法语国家的数据,这些数据使用数据中心IP地址或最近被标记为代理的IP,将Group 1分配给可疑流量。
图5:由人类(第0组)和潜在机器人(第1组)流量组成的真实世界电子商务流量数据集示例

以下Python代码示例展示了我们如何将Sliceline应用于数据集。我们使用pandas数据帧df存储数据集:
1 | from sliceline.slicefinder import Slicefinder |
一旦将算法拟合到数据上,我们就可以使用找到的切片来生成最适合我们需求的语法规则。例如,我们可以这样做:
1 | for slice, stats in zip(sf.top_slices_, sf.top_slices_statistics_): |
在我们的案例中,这段简单的代码给出了以下规则:
1 | `Country`=`Germany` | slice size: 4149.0 |
这意味着,对于这个特定的网站,攻击来自德国,使用Chrome和特定的接受语言标头。
3.2 分布式攻击的应用
Sliceline可以应用于分布式Bot攻击检测问题,通过定义两个不同的流量组【用攻击前和攻击期间的来标签,使任务做到无监督】:
- 攻击前的流量:这部分流量仅包含人类数据(Group 0);
- 攻击期间的流量:这部分流量包含人类和Bot流量(Group 1);
请注意,在实际情况下,Group 0可能包含一些残留的Bot流量。它如何影响Sliceline生成的规则的质量取决于Group 0中Bot流量的比例以及它与Group 1中也存在的Bot流量的相似程度。
图6:时间序列图,说明Sliceline使用的2个组:攻击前的人类流量(绿色,Group 0)和混合的Bot和人类流量(红色,Group 1)

上图中展示了这个想法,假设异常检测算法提供了攻击开始时间,然后稍后触发流量分析。如果我们将攻击前的流量标识为Group 0,将攻击期间的流量标识为Group 1,那么通过应用Sliceline,我们将找到针对Bot流量的规则。
我们提出的检测分布式攻击的方法不依赖于IP或会话的流量分析。相反,我们分析每个【客户】的全局流量。为此,我们计算几个聚合并分析它们随时间的演变。我们计算的聚合的示例包括:
- 请求的数量;
- 唯一User Agent的数量;
- 唯一国家的数量;
- 唯一IP地址的数量;
所有聚合都使用Apache Flink[8]在10分钟的窗口中以流式处理方式计算。请注意,时间窗口的大小可以根据用例进行参数化:
- 较小的时间窗口可以更快地进行检测,但可能会增加误报率;
- 较大的时间窗口可能会在异常检测中引入滞后,但可以降低误报率的风险;
图7:四个不同聚合时间序列的示例(请求计数、IP数量、用户代理数量、国家数量)

我们独立分析每个时间序列,并使用基于z-score的算法检测极高值。滚动窗口允许我们估计正常数据的分布,并基于该分布计算新值的z-score。如果z-score超过一定阈值,则宣布攻击开始,并触发流量分析。
该算法轻量级且可以轻松地以流式处理方式实现。该算法可能会遇到两个不同的问题:
- 误报:检测到攻击不是由Bot引起的,可能是因为z-score阈值过于敏感,或者因为由于某些特殊事件(突发新闻、限量销售等)导致流量增加。
- 漏报:错过本应该检测到的攻击。
关于漏报问题,可以收集示例时间序列并标记需要检测的攻击。这个带标签的数据集可以进一步用于更好地调整阈值。
关于误报问题,随后的规则生成步骤可以防止我们生成针对正常业务的规则。如果流量激增是由正常业务流量引起的,则Sliceline将不会发现攻击前后流量特征的任何差异,因此将不会生成任何规则。【有点意思,规则挖掘类似告警聚类,有降误报的能力】
优势
- 使用流量聚合和异常检测来检测分布式攻击的方法;
- 我们利用切片线来推断恶意签名并生成规则;
- 有效对抗频繁调整和修改/伪造指纹的机器人;
- 切片线可以应用于依赖规则引擎的其他安全用例;
3.3 案例分析:凭据填充攻击被Sliceline阻止
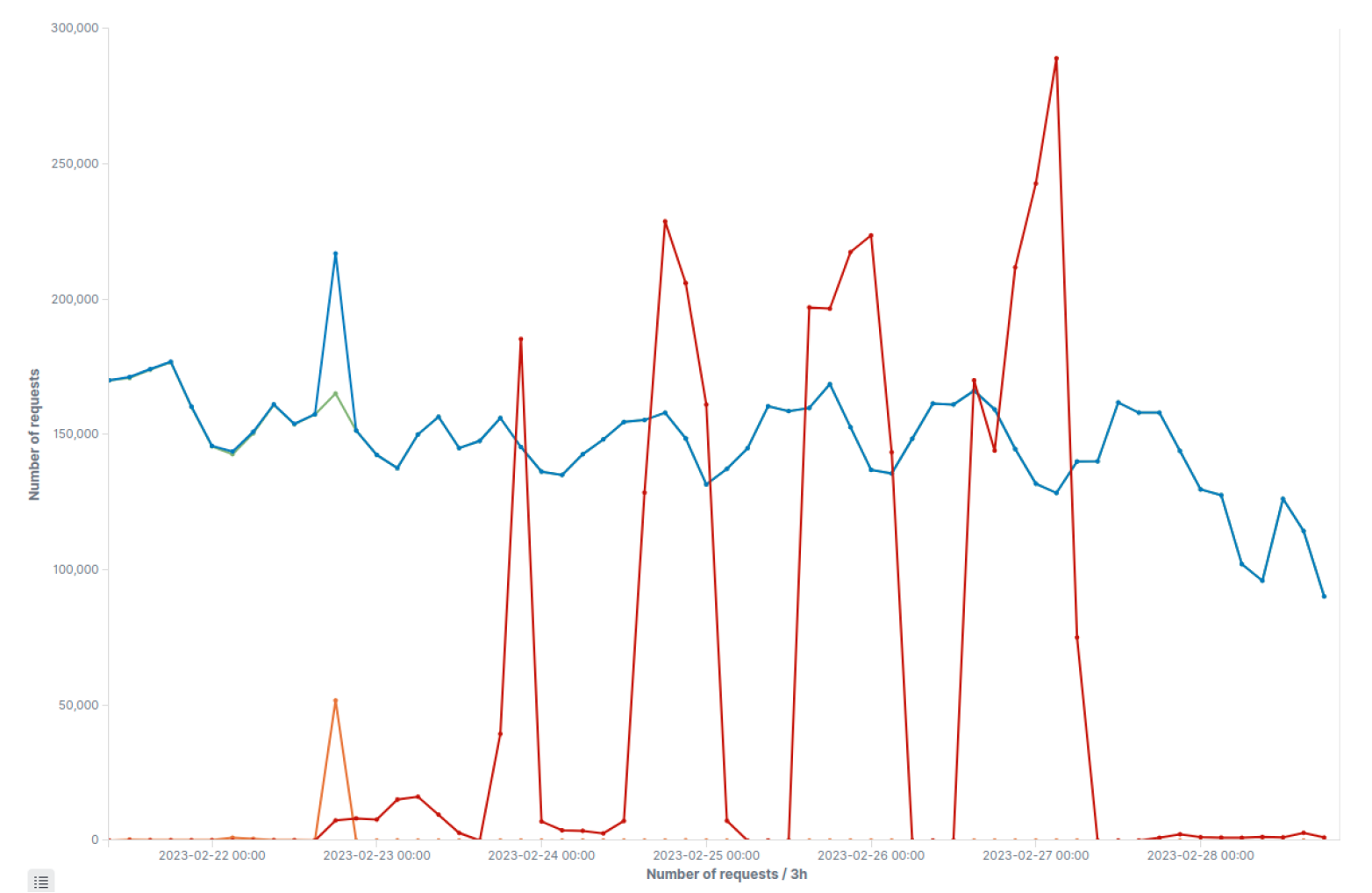
为了说明我们的方法,我们展示了一个使用我们的流式异常检测和Sliceline相结合的游戏平台攻击的具体例子。图8展示了4个不同的时间序列:
- 蓝色:被检测引擎分类为人类的HTTP登录流量(可能包含尚未检测到的Bot流量)。
- 橙色:在部署到检测引擎之前与Sliceline生成的规则匹配的流量(攻击的未检测子集)。
- 绿色:蓝色-橙色时间序列。在实施Sliceline生成的规则后被认为是人类流量。
- 红色:Sliceline生成的规则匹配并被阻止的HTTP登录流量。
首先:游戏平台的登录流量出现了一个小的峰值(蓝色线),被我们的异常检测算法捕捉到。然后,Sliceline被应用,并生成了一条规则,随后阻止了由红色线表示的所有流量,在一周内总计超过3百万个请求。
图8:与Slisline在游戏平台登录端点上的应用程序相关的时间序列
下面显示了相同的阻塞流量,但我们显示的不是请求号,而是不同IP的数量。超过18.7万个不同的IP被用来分发这次攻击。
图9:在游戏平台上进行凭证填充攻击时,IP地址的不同数量/3h
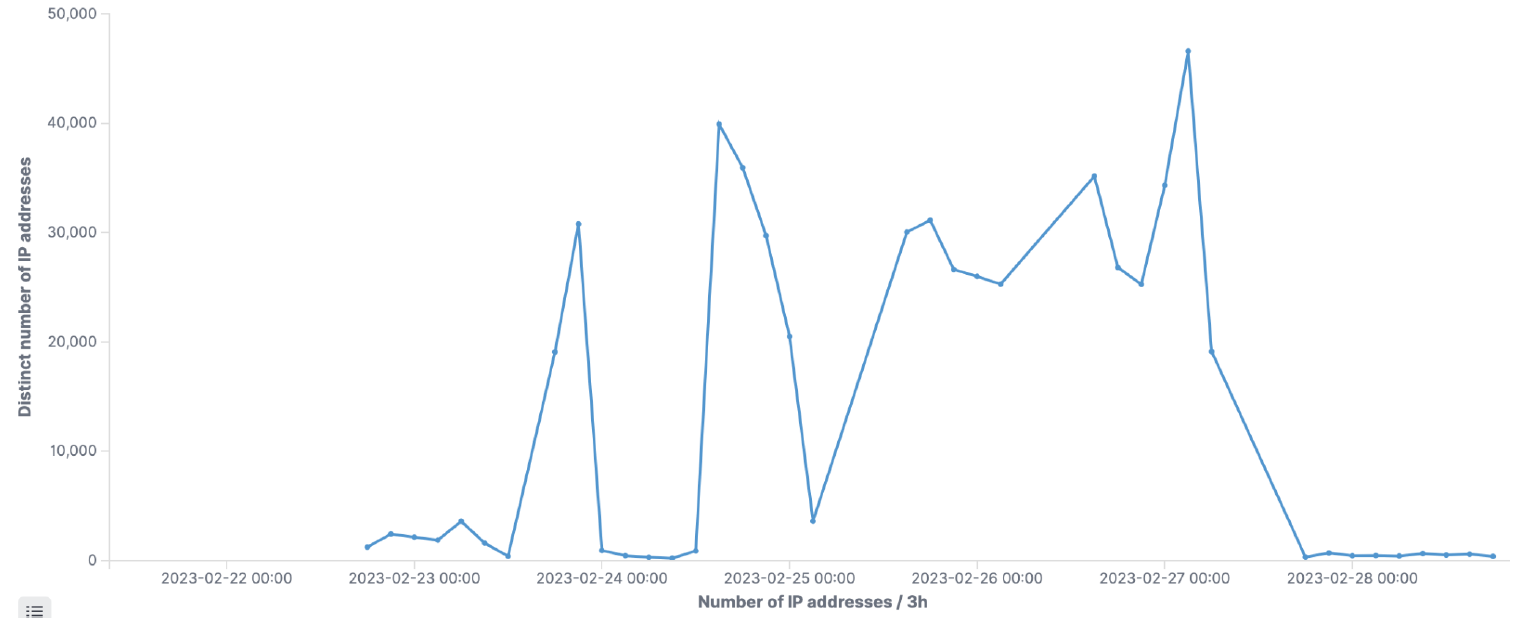
虽然我们利用Sliceline在不同的ML管道中生成规则,但我们结合基于流式处理的异常检测和Sliceline的方法能够保护登录终端,每个月跨多个客户阻止约220万次恶意登录尝试。
四、结论
为了绕过传统的Bot检测技术,如基于IP的速率限制和基于签名的阻止,Bot趋向于在数千个IP地址上分布其攻击,并频繁更改其指纹。我们提出了一种结合基于流式处理的异常检测和Sliceline的方法来检测分布式Bot攻击。
虽然Sliceline最初是作为一种ML模型调试算法提出的,但我们展示了如何使用它来生成与恶意Bot流量活动匹配的规则。这种方法使我们能够每月跨多个客户阻止约220万次恶意登录尝试。
我们实现并开源了Sliceline的优化Python版本。我们重写了部分代码,利用了矩阵乘法和稀疏矩阵,相比R实现,速度提升了1000倍。
在本文中,我们使用分布式Bot攻击检测问题展示了我们的方法。然而,我们的方法完全不依赖于规则引擎,可以应用于其他网络安全设置,只要能够定义正常和异常行为的组。
参考文献
[2] Jacob, Gregoire, Engin Kirda, Christopher Kruegel, and Giovanni Vigna. "PUBCRAWL: Protecting Users and Businesses from CRAWLers." In USENIX Security Symposium, pp. 507-522. 2012.
[3] Bursztein, Elie, et al. "Picasso: Lightweight device class fingerprinting for web clients." Proceedings of the 6th Workshop on Security and Privacy in Smartphones and Mobile Devices. 2016.
[4] Vastel, Antoine, et al. "FP-Crawlers: studying the resilience of browser fingerprinting to block crawlers." MADWeb'20-NDSS Workshop on Measurements, Attacks, and Defenses for the Web. 2020.
[5] Li, Xigao, et al. "Good bot, bad bot: Characterizing automated browsing activity." 2021 IEEE symposium on security and privacy (sp). IEEE, 2021.
[6] Sagadeeva, Svetlana, and Matthias Boehm. "Sliceline: Fast, linear-algebra-based slice finding for ml model debugging." Proceedings of the 2021 International Conference on Management of Data. 2021.
[7] https://github.com/DataDome/sliceline
相关链接
- https://datadome.co/datadome_events/black-hat-asia-2023-here-we-come/
- Leveraging Streaming-Based Outlier Detection and SliceLine to Stop Heavily Distributed Bot Attacks
- SliceLine: Fast, Linear-Algebra-based Slice Finding for ML Model Debugging
- War of the Bots: Learnings from Thwarting New Automated Attack Vectors