文本分类(1)搜狐文本情感分类
搜狐情感分析 × 推荐排序算法大赛 baseline
- 搜狐情感分析 × 推荐排序算法大赛 baseline
- 比赛官网:https://www.biendata.xyz/competition/sohu_2022/
赛题背景
在工业界,推荐算法和自然语言处理是结合非常紧密的两个技术环节。本次大赛我们推出创新赛制——NLP 和推荐算法双赛道:探究文本情感对推荐转化的影响。情感分析是NLP领域的经典任务,本次赛事在经典任务上再度加码,研究文本对指定对象的情感极性及色彩强度,难度升级,挑战加倍。同时拥有将算法成果研究落地实际场景的绝佳机会,接触在校园难以体验到的工业实践,体验与用户博弈的真实推荐场景。
比赛任务
比赛分为两部分:
- 第一部分:==面向实体对象的文本描述情感极性及色彩强度分析==。情感极性和强度分为五种情况:极正向、正向、中立、负向、极负向。选手需要针对给定的每一个实体对象,从文本描述的角度,分析出对该实体的情感极性和强度。
- 第二部分:利用给出的用户文章点击序列数据及用户相关特征,结合第一部分做出的情感分析模型,对给定的文章做出是否会形成点击转化的预测判别。用户点击序列中涉及的文章,及待预测的文章,我们都会给出其详细内容。
一、 任务1:面向实体对象的文本情感分类
2.1 数据加载
1 | train_file = 'data/Sohu2022_data/nlp_data/train.txt' |

2.2 文本长度统计
1 | train['text_len'].quantile([0.5,0.8,0.9,0.96]) |
大部分文本长度在562以内,在迭代过程中发现,输入到模型的文本越完整效果越好,所以可以尝试文档级的模型,比如ernie-doc或者xlnet等。

2.3 实体情感标签统计
1 | sns.countplot(sentiment_df.sentiment) |

可以看出中性情感占到了绝大部分,极端情感最少。因为数据量比较大,大家可以使用一些采样策略:
- 中立情感负采样 ,但是有过拟合风险
- 保证情感比例采样:加快模型迭代速度
- 对同一个样本的重复情感可以负采样,ent1和ent2:1 text|ent1+ent2
2.4 数据预处理
重复标签:同一样本的标签有多个,然后按照多个实体情感对样本进行复制,得到每个文本以及标签,处理代码如下:
1 | lst_col = 'sentiment' |
模型定义
1 | class LastHiddenModel(nn.Module): |
扩展思路:
- 长文本处理:模型输入/模型预测:TTA
- doc级文本模型:longformer
(xlnet) https://huggingface.co/hfl/chinese-xlnet-base
(longformer_zh) https://huggingface.co/ValkyriaLenneth/longformer_zh
(longformer-chinese-base-4096) https://huggingface.co/schen/longformer-chinese-base-4096
- 轻量级模型:LSTM、GRU/Transformer等网络 600 word 300
- 选择使用不同预训练模型进行微调,chinese-roberta-wwm/nezha/xlnet/ernie/ernie-gram,其中ernie或者ernie-gram效果可能会好些
- 预训练模型输出的利用:CLS/PoolerOut/LastHiddenState/+(Bi)LSTM/LastFourConcat/etc...
- 训练优化:对抗训练(FGM/PGD/AWP)/EMA/MultiDropout/Rdrop
- 文本分类上分微调技巧实战
- 改进1 Last 4 Layers Concatenating
- 改进2 模型层间差分学习率: 对不同的网络层数使用不同的学习率,这样可以防止过拟合,有利于加速学习。
- ==BERT长文本处理:《CogLTX: Applying BERT to Long
Texts》==
- https://github.com/Sleepychord/CogLTX
- 分类实例:https://github.com/Sleepychord/CogLTX/blob/main/run_20news.py
- COGLTX采用的策略是将每个子句从原句中移除判断其是否是必不可少的(t是一个阈值):
- XLNET分类模型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from transformers import XLNetModel
class MyXLNet(nn.Module):
def __init__(self, num_classes=35, alpha=0.5):
self.alpha = alpha
super(MyXLNet, self).__init__()
self.net = XLNetModel.from_pretrained(xlnet_cfg.xlnet_path).cuda()
for name, param in self.net.named_parameters():
if 'layer.11' in name or 'layer.10' in name or 'layer.9' in name or 'layer.8' in name or 'pooler.dense' in name:
param.requires_grad = True
else:
param.requires_grad = False
self.MLP = nn.Sequential(
nn.Linear(768, num_classes, bias=True),
).cuda()
def forward(self, x):
x = x.long()
x = self.net(x, output_all_encoded_layers=False).last_hidden_state
x = F.dropout(x, self.alpha, training=self.training)
x = torch.max(x, dim=1)[0]
x = self.MLP(x)
return torch.sigmoid(x)
- 长文本理解模型 ERNIE-Doc
- ERNIE-DOC,是一个基于Recurrence Transformers(Dai et al., 2019) 的文档级语言预训练模型。 本模型用了两种技术:回溯式feed机制和增强的循环机制,使模型具有更长的有效上下文长度,以获取整个文档的相关信息。
- https://github.com/PaddlePaddle/ERNIE
二、任务2:文章点击预测
第二部分:利用给出的用户文章点击序列数据及用户相关特征,结合第一部分做出的情感分析模型,对给定的文章做出是否会形成点击转化的预测判别。用户点击序列中涉及的文章,及待预测的文章,我们都会给出其详细内容。
2.1 数据加载
1 | train = pd.read_csv('data/Sohu2022_data/rec_data/train-dataset.csv') |

训练集中每条样本包含pvId,用户id,点击序列(序列中的每次点击都包含文章id和浏览时间),用户特征(包含但不限于操作系统、浏览器、设备、运营商、省份、城市等),待预测文章id和当前时间戳,以及用户的行为(1为有点击,0为未点击)。
smapleId:样本的唯一id
label:点击标签
pvId:将每次曝光给用户的展示结果列表称为一个Group(每个Group都有唯一的pvId)
suv:用户id
itemId:文章id
userSeq:点击序列
logTs:当前时间戳
operator:操作系统
browserType:浏览器
deviceType:设备
osType:运营商
province:省份
city:城市
2.2 数据分析
1 | def statics(data): |

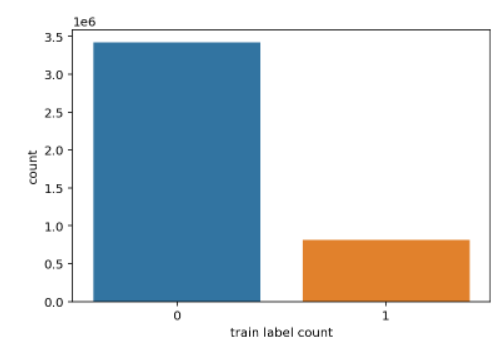
标签分布如下:
1 | sns.countplot(train.label) |
2.3 初步特征工程
- 情感特征
1 | amount_feas = ['prob_0', 'prob_1', 'prob_2', 'prob_3','prob_4' ] |
类别特征count特征:
1 | # count特征 |
用户特征:
1 | # count特征 |
物料特征:
1 | # pvId nunique特征 |
NN模型-DeepFM
基于deepctr实现DeepFM训练
1 | train_model_input = {name: train[name] for name in feature_names} |
树模型-Catboost
1 | train_model = CatBoostClassifier(iterations=15000, depth=5, learning_rate=0.05, loss_function='Logloss', logging_level='Verbose', eval_metric='AUC', task_type="GPU", devices='0:1') |
特征工程思路扩展
- 高阶特征:类别特征组合、高阶聚合特征,比例特征
- 点击序列统计特征:当前用户|全局: item 众数当做类别特征;统计量 count或者nunique
- 序列 Embedding特征:word2vec,tfidf(词袋)+SVD、graph embedding(deepwalk)
- 点击转化率特征:itemid、pvId,类别组合 ..(提分) Kfold