AI安全(5)Functionality-Preserving Black-Box Optimization of Adversarial Windows Malware 2021 TIFS
Functionality-Preserving Black-Box Optimization of Adversarial Windows Malware 2021 TIFS
keyword: 对抗样本;黑盒优化;
Abstract:
基于机器学习的Windows恶意软件检测器很容易受到攻击性示例的攻击,即使攻击者只获得对模型的黑盒查询访问权限。这些攻击的主要缺点是:查询效率低下,因为它们依赖于对输入恶意软件反复应用随机转换;它们可能还需要在优化过程的每次迭代中在沙盒中执行恶意软件,以确保其入侵功能得到保留。依赖于在恶意文件的末尾或在一些新创建的部分中注入良性内容(这些内容永远不会被执行)。我们的攻击被形式化为一个有约束的最小化问题,这也使得规避检测的概率和注入的有效负载的大小之间的权衡得到优化。对两种流行的静态Windows恶意软件检测器进行了实证研究,结果表明,即使只返回预测的标签,我们的黑盒攻击也可以通过很少的查询和较小的有效负载绕过它们。还评估了我们的攻击是否会转移到其他商业防病毒解决方案中,并意外地发现它们平均可以避开12个以上的商业防病毒引擎。讨论了我们的方法的局限性,以及它将来可能扩展到基于动态分析的目标恶意软件分类器。
一、Introduction
机器学习在计算机安全领域正变得越来越普遍。学术界和工业界都在投入时间、金钱和人力资源来应用这些统计技术来解决恶意软件检测的艰巨任务。特别是,Windows恶意软件仍然是一种威胁,因为每天都有成千上万的恶意程序被上传到VirusTotal[1]。现代方法使用机器学习来大规模检测此类威胁,利用许多不同的学习算法和特征集[1]–[7]。虽然这些技术已显示出很有前途的恶意软件检测能力,但它们最初的设计目的并不是为了处理攻击者可以操纵输入数据以逃避检测的非平稳、对抗性问题。
在过去的十年中,这一点在对抗式机器学习领域得到了广泛的证明[8],[9]。该研究领域研究了机器学习算法在训练或测试阶段受到攻击时的安全性问题。特别是,在基于学习的Windows恶意软件检测器的背景下,已经证明可以针对目标系统仔细优化对抗性恶意软件样本以绕过它[10]–[17]。其中许多攻击都在黑盒设置中进行了演示,在黑盒设置中,攻击者只能对目标模型进行查询访问[14]–[17]。这确实对作为云服务部署的此类系统的安全性提出了质疑,因为外部攻击者可以查询这些系统,然后根据目标系统提供的反馈优化其操作,直到实现规避。
然而,这些黑盒攻击在以下方面仍然不是非常有效:(i)所需查询的数量(reguired queries),(i)其优化过程的复杂性(complexity),以及(i)对输入样本执行的操作量(amount of manipulations),如下所述: 1. 首先查询效率 is hindered by the fact that 攻击通过反复迭代并非专门针对逃避检测的转换(如在文件结尾后注入随机字节)来优化恶意软件。优化过程在计算上可能要求很高,因为有些攻击需要在每次迭代时在沙盒中执行敌对恶意软件样本,以确保其入侵功能得到保留。这种验证步骤是由在特征空间中操纵数据(而不是考虑可实现的输入修改[18]的攻击所要求的或者考虑可能破坏恶意软件样本[14]的功能的输入变换[19]。 2. 虽然在沙盒中执行一次恶意软件样本可能不会显著减慢整个过程,但因为它需要在感染前的阶段恢复虚拟环境的状态。当优化过程的每次迭代后都必须重复此步骤时,问题就变得相关了。此外,许多恶意软件样本可以检测它们是否在虚拟环境中运行,并延迟执行以保持未被检测到:Malware dynamic analysis evasion techniques:A survey; 3. 所有这些攻击都通过显著操纵输入恶意软件的内容来实现规避,而不考虑额外的限制,例如,对生成的文件大小或注入的节数的限制。这可能导致攻击样本很容易被检测为异常,只需查看一些无关紧要的特征(trivial characteristics),如文件大小或节数。
在本文中,我们提出了一个新的黑盒攻击家族(Section 3) 可以有效地优化恶意软件样本。首先,我们的攻击是高效查询的,因为它们依赖于注入特定目标的内容以便于规避,即从良性样本中提取(而不是随机生成)。第二,它们在设计上保留了功能,因为它们利用了一组操作,这些操作仅通过利用用于在磁盘上存储程序的文件格式的模糊性将内容注入恶意程序,而不改变其执行跟踪。虽然在这项工作中,我们只关注在文件末尾(填充)或在一些新创建的节(节注入)中注入内容,但我们的方法足够通用,可以包含更广泛的功能保留操作。最后,我们的攻击更加隐蔽。特别地,它们被形式化为一个约束最小化问题,该问题不仅优化了规避检测的概率,而且通过一个特定的正则化项(via a specific regularization term.)来惩罚注入的敌方有效载荷的大小。
二、PROGRAMS AND MALWARE DETECTION
在本节中,我们首先讨论Windows可移植可执行文件(PE)格式,2它描述了程序如何存储在磁盘上,并向操作系统(OS)解释了如何在执行之前将其加载到内存中。然后,我们将介绍这项工作剩余部分中使用的两种流行的基于学习的Windows恶意软件检测器。
2.1 The Windows Portable Executable (PE) File Format
Windows PE格式由几个组件组成,如图1所示,如下所述。DOS标题(A)。它包含用于在DOS环境中加载可执行文件的元数据,以及DOS存根,如果在DOS环境中执行,则会打印“此程序无法在DOS模式下运行”。保留这两个组件是为了保持与旧版Microsoft操作系统的兼容性。从现代应用程序的角度来看,DOS头中唯一相关的部分是:(i)幻数MZ,文件的两字节长签名,以及(ii)偏移量0x3c处的四字节长整数,用作指向实际头的指针。如果这两个值中的一个由于某种原因被置乱,则认为程序已损坏,操作系统将不会执行该程序。
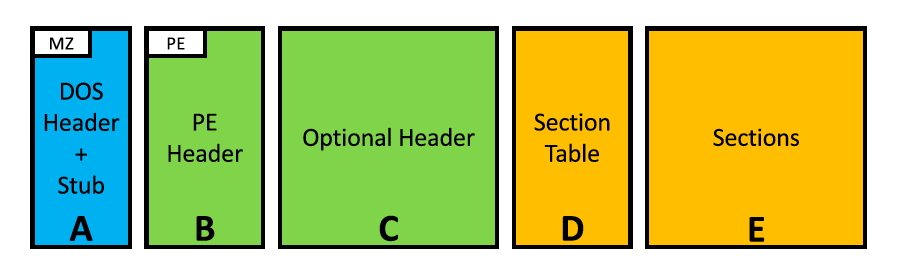
PE header(B)。它包含幻数PE以及其他文件特征,如目标体系结构、头大小和文件属性。
Optional Header(C)。它包含操作系统初始化加载程序所需的信息。它还包含指向有用结构的偏移量,如操作系统解析依赖关系所需的导入地址表(IAT)和导出表偏移量,后者指示在何处查找其他程序可以引用的函数。截
Section Table(D)。它是一个条目列表,指示程序的每个核心组件的特征,以及OS加载程序应该在文件中找到它们的位置。
Sections(E)节。这些连续的字节块承载着可执行文件的真实内容。要列出一些:。文本包含代码。数据包含全局变量和。rdata包含只读常量和计数。
可执行程序的结构可用于静态推断有关其行为的信息。事实上,大多数防病毒供应商应用静态分析来检测野外威胁,而不在受控环境中执行可疑程序。这种方法节省了时间和资源,因为防病毒程序不会在主机操作系统内执行可疑软件。静态分析是第一道防线,其性能对于抵御野外无数威胁至关重要。
2.2 Learning-Based Windows Malware Detection
- MalConv
- EMBER
三、BLACK-BOX OPTIMIZATION OF ADVERSARIAL WINDOWS MALWARE
在本节中,我们将介绍一种新的黑盒攻击框架,命名为GAMMA(Genetic adricative Machine learning Malware attack)。GAMMA可以有效地优化敌方恶意软件样本,同时只需要黑盒访问模型,即只查询目标模型并观察其输出,而不访问其内部结构和参数。我们的攻击依赖于一组保留功能的操作,这些操作利用用于在磁盘上存储程序的PE格式的模糊性将内容注入恶意程序,而不改变其执行跟踪。这使我们能够摆脱需要计算的验证步骤,以确保被操纵的恶意软件保留其预期功能。特别是,我们认为这里的内容操纵,特别是针对有利于逃避,即,从良性样本中提取,而不是随机产生。虽然这使得我们的攻击更加有效,但值得注意的是,我们的框架足够通用,可以包含许多其他不同的内容操作技术。最后,为了使我们的攻击更加隐蔽,我们将其形式化为一个约束优化问题,该问题不仅最小化了逃避检测的概率,而且通过一个特定的惩罚项最小化了注入内容的大小。
符号定义,我们用x 2 x表示 f0;:::;255g (恶意)输入程序,描述为任意长度的字节字符串。然后,我们定义了一组k个不同的保留功能的操作,这些操作可以作为向量s2 s应用于输入程序x [0;1]k
- Notation: \(x\) malicious;\(s\) (k 种 vector);(良性初始注入+遗传算法)


3.1 Functionality-Preserving Manipulations(保留功能的操作)
我们在这里讨论一组可以在我们的攻击框架中使用的保留功能的操作。在windowspe文件格式的上下文中,只有一些转换可以在不影响输入程序执行的情况下应用。我们将其分为结构性和行为性两类,详情如下。
- Structural结构化:这一系列操作只影响输入程序的结构,利用文件格式中的模糊性,而不改变其行为。
- Perturb Header Fields:扰动标题字段[13]–[15]。此技术包括更改节名称、中断校验和以及更改调试信息。
- Filling Slack Space:填充松弛空间[12]–[15],[23]。此技术操纵编译器插入的空闲空间,以保持文件内部的对齐。相应的空闲字节(图1中的E内)通常被设置为零,并且它们从不被可执行文件的代码引用。
- Padding:填充[11]、[12]、[23]。这种技术在文件末尾注入额外的字节(在图1中的E之后)。
- Manipulating DOS Header and Stub:操作DOS头和存根[10],[22]。这项技术修改了DOS头中一些现代程序不使用的字节。
- Extend the DOS Header: 扩展DOS标头[22]。这种技术通过在程序的实际头之前注入内容来扩展DOS头。
- Content shifting:内容转移[22]。这种技术通过向前移动内容,在节的开始之前创建额外的空间,并在中间注入对抗性内容。
- Import Function Injection:导入函数注入[13]–[15]。该技术通过向导入地址表添加适当的条目来注入导入函数,指定在加载过程中必须包括哪个库中的哪个函数(这影响图1中的C和E)。
- Section Injection:第[13]-[15]节。这种技术通过在节表中创建一个额外的条目将新的节注入到输入文件中(从而影响图1中的D和E)。每个节条目的长度为40字节,因此所有内容都必须按该长度进行移位,而不会影响头指定的文件和节对齐方式。
- Behavioral行为:这一系列的干扰可以改变程序的行为和执行痕迹,但仍然保留恶意软件程序的预期功能。例如,这些转换包含[24]中的二进制重写技术,如下所述。
- Packing:加壳[13]–[15]。软件加壳的原理是在原始程序外部添加一个保护层,以保护程序代码和数据不被恶意软件攻击者破解、篡改或复制。通过壳程序的加载和解码、原始程序的加密和解密、壳程序的动态反调试和反破解、以及代码混淆和虚拟机技术等手段,可以使程序更加安全和难以被攻击者破解。封隔器的作用是侵入性的,因为输入样本的整个结构都被修改了;
- [13] R. L. Castro, C. Schmitt, and G. D. Rodosek, “ARMED: How automaticmalware modifications can evade static detection?” in Proc. 5th Int.Conf. Inf. Manage. (ICIM), Mar. 2019, pp. 20–27.
- [14] R. L. Castro, C. Schmitt, and G. D. Rodosek, “Aimed: Evolving malwarewith genetic programming to evade detection,” in Proc. 18th Int. Conf.TrustCom, 2019, pp. 240–247.
- [15] H. S. Anderson, A. Kharkar, B. Filar, and P. Roth, “Evading machinelearning malware detection,” in Proc. BlackHat, 2017.
- Direct:直接[24]。这种方法重写代码的特定部分,比如用等价的指令替换汇编指令(例如,用相反的符号进行加法和减法)。
- 这种技术被称为“代码混淆”(code obfuscation)。它是一种常见的恶意软件攻击技术,攻击者使用代码混淆技术来隐藏恶意代码的真实意图,使其更难以被检测和分析。
- 在这种技术中,攻击者会通过重写代码的特定部分来进行代码混淆。例如,攻击者可以用等价的指令替换汇编指令,或者用相反的符号进行加法和减法等操作。这样一来,原本的代码逻辑就被混淆了,使得恶意代码更难以被理解和分析。
- 代码混淆技术可以有效地防止恶意代码被检测和分析,因为它使得恶意代码的行为更难以被预测和理解。然而,代码混淆也会使得恶意代码更难以被清除和修复,因为恶意代码的行为可能会受到混淆代码的影响,从而导致误报和误判。
- [24] M. Wenzl, G. Merzdovnik, J. Ullrich, and E. Weippl, “From hackto elaborate technique—A survey on binary rewriting,” ACM Comput.Surv., vol. 52, no. 3, pp. 1–37, Jul. 2019
- Minimal
Invasive[15],[24]。此技术将入口点设置为新的可执行部分,该部分跳回原始代码。
- 这种技术被称为“代码注入”(code injection)。它是一种恶意软件攻击技术,攻击者通过将恶意代码注入到受害者计算机中的合法进程中,来控制受害者计算机、窃取敏感信息或者执行其他恶意行为。
- 在这种技术中,攻击者会将恶意代码插入到被感染程序的可执行部分中,并将程序的入口点设置为恶意代码的起始位置,使程序在运行时首先执行恶意代码。然后,恶意代码会执行一些操作(如窃取信息、下载其他恶意代码等),最后将程序的控制权转回到原始代码中,以避免被检测到。
- 代码注入是一种常见的恶意软件攻击技术,攻击者可以使用多种方法来实现代码注入,如缓冲区溢出、API Hooking、DLL注入等。为了防止代码注入攻击,建议用户保持软件的更新和使用安全软件进行防护。
- Full
Translation:完整翻译[24]。这种方法将所有代码提升到更高的表示形式,例如LLVM,4,因为它简化了扰动的应用,然后将代码翻译回汇编语言。
- 这种技术被称为“语义混淆”(semantic obfuscation)。它是一种常见的恶意软件攻击技术,攻击者使用语义混淆技术来隐藏恶意代码的真实意图,使其更难以被检测和分析。
- 在这种技术中,攻击者会将所有代码提升到更高的表示形式,例如LLVM,因为这样可以简化扰动的应用。然后,攻击者会将代码翻译回汇编语言,但是这时的代码已经被语义混淆了,使得其更难以被理解和分析。
- 语义混淆技术可以有效地防止恶意代码被检测和分析,因为它使得恶意代码的行为更难以被预测和理解。然而,语义混淆也会使得恶意代码更难以被清除和修复,因为恶意代码的行为可能会受到混淆代码的影响,从而导致误报和误判。
- Dropper[30]。这种方法将代码存储为另一个二进制文件的资源,然后在运行时加载。
- 这种技术被称为“二进制文件注入”(binary file injection)。它是一种恶意软件攻击技术,攻击者使用二进制文件注入技术来隐藏恶意代码,使其更难以被检测和分析。
- 在这种技术中,攻击者会将恶意代码存储为另一个二进制文件的资源,然后在运行时加载。这样一来,恶意代码就被隐藏在另一个二进制文件的资源中,使得它更难以被检测和分析。
- 二进制文件注入技术可以有效地防止恶意代码被检测和分析,因为它使得恶意代码更难以被发现。然而,二进制文件注入也会使得恶意代码更难以被清除和修复,因为恶意代码可能会被存储在多个文件中,从而需要进行全面的扫描和清除。
- [30] F. Ceschin, M. Botacin, H. M. Gomes, L. Oliveira, and A. Grégio,“Shallow security: On the creation of adversarial variants to evademachine learning-based malware detectors,” in Proc. 3rd ReversingOffensive-Oriented Trends Symp., 2019, pp. 1–9.
- Padding and Section-Injection Attacks 填充和节注入攻击
虽然GAMMA可以通过在[33 ]中的开源实现支持大多数上述操作,但是我们只考虑在这项工作中的填充和分段注入攻击,因为它们提供了两个有代表性的示例,即在不需要操纵额外的头组件的情况下,在样本内注入内容(例如,节区表)。特别是,Padding将内容注入到可执行文件的未使用空间中,而不改变任何其他头组件。相反,Section infection不仅允许像其他技术一样注入自定义内容,而且还通过在节表中添加节条目来操纵可执行文件的结构。
四、实验
在本节中,我们根据经验评估了针对GBDT和MalConv恶意软件检测器的攻击的有效性。我们在一台装有Intel的工作站上进行了实验 至强 CPU E5-2670,具有48个CPU和128 GB RAM。MalConv的预训练版本呈现出略有不同的体系结构w.r.t。原始公式:1 MB的输入大小和256的填充值,以避免移动预处理部分。该网络使用PyTorch实现【25】。我们使用DEAP开发了GAMMA的遗传优化器【26】。我们使用10个元素的总体大小N测试了攻击,将查询预算T从10更改为510。如果优化器在一个局部最小值上停滞了5次以上的迭代,我们将停止该过程。我们使用正则化参数的值 2层10 ig9i=3。由于攻击特征空间S在攻击者可能添加的节数上是参数化的,因此我们随机提取了75个。如第III-a节所述,我们的goodware数据集中的rdata部分将用于向输入恶意软件添加内容,最大容量为2.5 MB。我们愿意将此数字设置为高值,因为优化器将发现较小的有效负载,这要归功于行为为“1”标准的惩罚术语所施加的稀疏性。我们实现并公开了用于计算这些攻击的库,名为secml恶意软件。5.
4.1 无攻击时的性能
为了在没有攻击的情况下评估这两种分类器的性能,我们收集了一组分类器;15000良性和15;000个恶意软件样本。恶意软件样本是从VirusTotal收集的,而goodware样本是通过从GitHub下载可执行程序收集的。结果如图3所示。为GBDT选择的阈值为0.8336,对应于0.039的假阳性率(FPR)和0.95的真阳性率(TPR)。MalConv使用的阈值为0.5,这导致FPR为0.035,TPR为0.69。图中的红点直接在曲线上显示这些值。这些结果与GBDT【6】的作者给出的描述相当,因为两种检测器的w.r.t得分略低。这篇论文中报道了这一点。不过,它们都可以作为我们分析的基线。
4.2 攻击评估
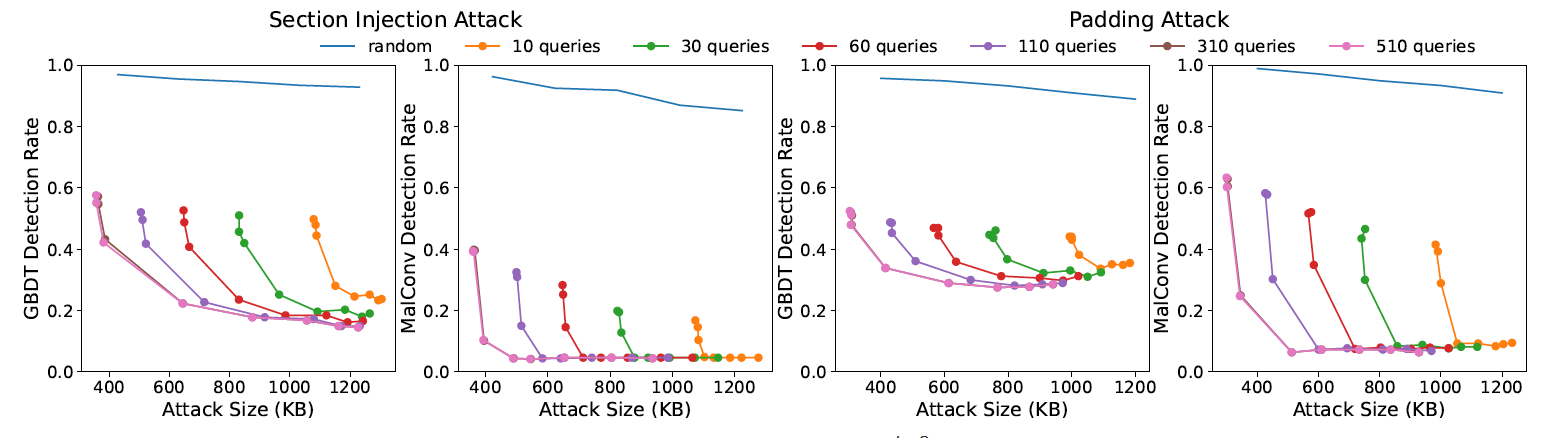
我们从收集的15K恶意软件中随机抽取500个用于对抗性攻击,其中包括5.3%的勒索软件、29%的下载软件、18%的病毒、7%的后门软件、29%的灰色软件、8%的蠕虫,以及其他百分比较低的家族。图4显示了检测率和对抗性有效载荷大小如何随查询数量和正则化参数的值而变化。曲线图中的每条曲线都是通过计算每个值的平均检测率和平均大小生成的 , 针对发送的不同查询数重复此操作。作为的值 由于在计算目标函数时,惩罚项可以忽略不计,因此该算法可以找到更多有效载荷较大的规避样本。另一方面,通过增加 由此产生的攻击特征向量变得稀疏,生成更小但更可检测的对抗性示例。在这种情况下,惩罚项会吞噬分类器计算的分数,这在优化过程中变得无关紧要。另一个重要影响是遗传优化器使用的总查询数:发送的越多,敌对示例的检测率和大小越好。直观地说,通过发送更多的查询,GAMMA可以同时探索更多隐藏和回避的解决方案,但在优化过程的早期阶段无法找到此类解决方案。为了证明我们的方法的有效性,我们报告了应用递增长度随机字节序列的结果。这个实验强调了轻微的下降趋势,但使用良性内容注入的优化攻击比随机干扰更有效。分段注入攻击比填充攻击更能降低GBDT的检测率。由于第一种技术还在节表中引入了节条目,因此与填充攻击修改的特性相比,对抗性有效载荷干扰的特性更多。
4.3 硬标签攻击
我们在表I中显示了聚合结果,重点比较了软标签和硬标签攻击的性能。每个条目表示每个检测器的平均检测率和平均对抗有效负载大小,给定一对用于计算指定攻击的查询/正则化参数。我们计算了4个不同的 在集合f10中 (2i+1)g4i=1。结果表明,在没有置信度得分的情况下,一旦发现一个规避有效载荷,则无论正则化参数的值如何,其大小都会在遗传算法的一次又一次迭代中得到优化 . 这是由我们为实验设置的结果造成的:我们使用一个无限值来丢弃每个检测到的敌对示例,因此所有剩余的示例仅用于优化大小,作为优化的约束本身。我们的方法在这种环境中的有效性是由注入的内容的性质引起的,它模仿良性类,图4证实了这一点,其中注入随机字节序列对目标没有影响。相反,查询的数量本身起到了调节器的作用,因为太少的查询会导致更大的对抗性有效载荷,而置信度较低,而大量的查询会导致分数较高的小有效载荷。

4.4 时间分析
从时间的角度来看,GAMMA的复杂性主要取决于查询探测器所花费的时间。表II显示了计算每个攻击和目标的单个查询所需的平均运行时间。令人惊讶的是,特征提取阶段和GBDT预测所花费的时间之和小于神经网络处理所有字节所需的时间。

4.5 加壳影响
由于这些分类器仅利用静态特征,因此我们有理由问自己,在不应用第三节中介绍的所有技术的情况下,加密程序内容是否足以逃避检测。打包是一种通过应用压缩、加密或编码算法来减少可执行文件大小的技术。由于打包器的作用完全改变了磁盘上的程序表示,恶意软件供应商广泛使用打包器向分析师隐藏其产品,增加了逆向工程分析的难度。在这种情况下,我们将一种著名的技术UPX7应用于1000个恶意软件和1000个goodware程序,并测试MalConv和GBDT的规避率。UPX封隔器的有效性如图5所示。这两个检测器在打包样本时都会给出恶意分数,通过查看打包好的goodware程序的方框图,这是很直观的。这两种检测器都增加了它们对恶意软件类别的得分,而打包恶意软件的均值和方差只有很小的变化。
从这些结果来看,我们认为,探测器将包装技术的应用视为一种恶意特征。这可能是由于训练集中有大量打包的恶意软件,而不是缺少打包的好软件。因此,基于此类数据训练的模型可能会有偏差,使他们错误地认为样本是恶意的,只是因为它是打包的。此外,如果使用一种技术打包足够的样本,学习算法应该能够捕获打包程序中打包程序本身留下的签名。例如,UPX打包器创建两个名为UPX0和UPX1的可执行部分,其中包含提取代码和原始压缩程序。我们认为,通过包装技术进行规避更可能由看不见的包装商实现,即恶意软件供应商自己开发的定制解决方案。
We believe that evasion through packing techniques should more likely to be achieved by unseen packers, i.e. custom solutions developed by malware vendors themselves.
4.6 Evaluation on Antivirus Programs (VirusTotal)
我们在此评估我们的攻击对商用探测器的影响。在这种情况下,我们无意逃避这些商业程序的检测,例如打包输入样本,而是评估这些方法是否可以检测到我们的攻击,因为我们的攻击只对输入恶意软件样本的内容进行了最小程度的修改。特别是,我们应用于恶意软件样本的操作仅涉及每个程序的语法结构,我们的目的是评估此类转换的应用是否会对其他防病毒程序构成威胁。我们预计,大多数商业解决方案不应受到此类攻击的影响。我们依赖VirusTotal检索到的响应,8这是许多威胁检测器的在线接口。该服务提供了一个API,可以通过从远程上传样本来查询系统。我们通过在向样本中注入对抗性负载之前和之后发送200个恶意软件样本来测试我们的攻击性能,该样本使用针对GBDT分类器的分段注入攻击进行了优化。我们还将我们的攻击与基线随机攻击进行比较,基线随机攻击只是向每个样本添加50 KB的随机负载。表三显示了VirusTotal上托管的防病毒程序平均有多少(总共70个)检测到提交的恶意软件样本。虽然随机攻击只会略微减少每个样本的检测数量,但分段注入攻击能够绕过平均每个样本12个以上的检测器。为了更好地评估我们的攻击对单个杀毒程序的影响,在表IV中,我们报告了2019年Gartner端点保护平台幻方图上出现的9种不同杀毒产品的检测率,9包括许多领先和有远见的产品,在执行随机和部分注入攻击之前和之后。在许多情况下,我们的节注入攻击能够大幅降低检测率(参见,例如,AV1、AV3、AV7和AV9),显著优于随机攻击(参见,例如,AV1和AV9)。原因可能是,其中一些防病毒程序已经使用基于静态机器学习的检测器,在保护终端客户端免受恶意软件攻击时实施了第一道防线,这也在他们的博客或网站上得到了证实,这使他们更容易受到我们的攻击。综上所述,我们的分析强调,这些商业产品可以通过转移攻击来规避,我们相信,通过对其进行优化攻击,它们的检测率可能会下降更多。
强化学习[15]
Anderson等人[15]提出了一种强化学习方法,以确定导致逃避的最佳操作顺序。为了测试代理的有效性,他们还测试了随机选取的操作的应用。他们用作基线的模型是我们在这项工作中分析的GBDT分类器的原始版本,使用较少的样本进行训练。为了训练学习代理的策略,他们通过为可使用的查询数量确定预算,让模型探索对抗性示例的空间。用于培训这些策略的查询平均数量约为1600[15]。作者没有报告对抗性恶意软件产生的文件大小:强化学习方法包含放大磁盘上表示的操作,但不清楚如何和多少。不同的是,我们的方法不需要培训阶段,因为它可以针对远程探测器进行部署。我们使用的转换在设计上是功能不变的,它们的应用程序不会改变程序的执行流。最后,通过在优化过程中插入正则化器,我们考虑了有多少内容被添加到输入恶意软件中。通过这种方法,可以控制插入噪声的数量,并且该算法可以找到不仅避开目标分类器,而且在大小上受到限制的对抗性示例。
随机算法和遗传算法[13],[14]
Castro等人[13],[14]应用随机算法和遗传算法来干扰输入恶意软件,并在沙箱中的优化过程的每次迭代中测试样本的功能。这些突变与Anderson等人提出的相同[15]。这些工作的作者表示,他们需要大约4分钟来创建敌对恶意软件,使用100个查询。尚未公布任何架构细节。我们不需要在沙箱中验证恶意软件,因为我们在变异过程中包含了领域知识。因此,我们的方法在同一时间跨度内执行1400个查询。他们也没有报告哪些是导致规避的最具影响力的突变:后者至关重要,我们正在处理统计算法中的潜在漏洞,与其他安全漏洞相比,这些漏洞的存在并不明显。
GAN[27]
Hu和Tan[17]开发了一个生成性对抗网络(GAN)[27],其目的是绕过目标分类器,打造对抗性恶意软件。网络会了解哪些API导入应该添加到原始样本中,但不会生成真正的恶意软件,因为这种攻击只在功能空间内运行。相反,由于每次都会生成真实的样本,因此我们创建了功能正常的恶意软件。针对Windows恶意软件检测器的黑匣子攻击的概述见表V,其中我们将上述技术与我们的方法进行了比较。
六、CONCLUSION AND FUTURE WORK
在本文中,我们提出了一个基于学习的Windows恶意软件检测器的新的黑盒攻击家族,它既能有效地进行查询,又能保持功能,克服了以往工作的局限性。我们的攻击依赖于在恶意文件末尾或在新创建的部分中注入良性内容(这些内容永远不会被执行),利用用于在磁盘上存储程序的文件格式的模糊性,而不改变其执行痕迹。所提出的攻击被形式化为一个有约束的最小化问题,该问题能够在规避检测的概率和注入的有效负载大小之间进行优化。我们对两个流行的基于学习的Windows恶意软件检测器进行了广泛的实证评估,结果表明,即使目标模型只输出预测的标签,我们的黑盒攻击也可以通过很少的查询和非常小的有效负载绕过它们。我们还表明,我们的攻击可以成功地转移到其他商业防病毒解决方案,发现他们可以逃避,平均而言,多达12个商业防病毒引擎提供的VirusTotal。尽管如此,我们相信直接针对这些探测器的优化攻击可能会更加有效。未来工作:未来工作的一个有趣途径是调查针对我们的攻击的适当对策的适用性,如第节所讨论的。六、 包括使用更健壮的特征表示(对基于字节或基于节的操作不敏感)和学习范式(通过对抗性再训练、特定攻击检测机制或使用领域知识约束)。另一个有希望的研究方向是将我们的攻击扩展到只在文件末尾或新创建的部分中注入内容的操作之外。我们坚信这是可以很容易实现的,因为我们的方法已经足够普遍,可以包含更广泛的功能保留操作,包括第节中讨论的操作。III-A级。将我们的工作扩展到处理也可以修改恶意软件程序动态执行的操作,例如在保留恶意意图的同时改变其控制流,无疑是一个挑战。然而,这无疑将为改进基于动态程序分析提取的特征的恶意软件检测器的评估和对抗性健壮性提供重要的一步。