模型训练(2)梯度消失&爆炸
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。 梯度爆炸和梯度消失问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
一、反向传播推导到梯度消失and爆炸的原因
1.1 反向传播推导:
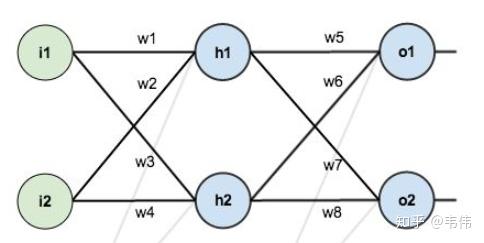
以上图为例开始推起来,先说明几点,i1,i2是输入节点,h1,h2为隐藏层节点,o1,o2为输出层节点,除了输入层,其他两层的节点结构为下图所示:

举例说明, \(N E T_{o 1}\) 为输出层的输入, 也就是隐藏层的输出经过线性变换后的值, \(O U T_{o 1}\) 为经过激活函数 sigmoid后的值; 同理 \(N E T_{h 1}\) 为隐藏层的输入, 也就是输入层经过线性变换后的值, \(O U T_{h 1}\) 为经过激活函数 sigmoid 的值。只有这两层有激活函数, 输入层没有。
定义一下sigmoid的函数: \[ \sigma(z)=\frac{1}{1+e^{-z}} \] 说一下sigmoid的求导: \[ \begin{aligned} \sigma^{\prime}(z) & =\left(\frac{1}{1+e^{-z}}\right)^{\prime} \\ & =\frac{e^{-z}}{\left(1+e^{-z}\right)^2} \\ & =\frac{1+e^{-z}-1}{\left(1+e^{-z}\right)^2} \\ & =\frac{\sigma(z)}{\left(1+e^{-z}\right)^2} \\ & =\sigma(z)(1-\sigma(z)) \end{aligned} \] 定义一下损失函数,这里的损失函数是均方误差函数,即: \[ \text { Loss }_{\text {total }}=\sum \frac{1}{2}(\text { target }- \text { output })^2 \] 具体到上图,就是: \[ \text { Loss }_{\text {total }}=\frac{1}{2}(\operatorname{target} 1-\text out_{o1} )^2+\frac{1}{2}(\operatorname{target} 2-\text out_{o2})^2 \] 到这里, 所有前提就交代清楚了,前向传播就不推了,默认大家都会, 下面推反向传播。
- 第一个反向传播(热身)
先来一个简单的热热身, 求一下损失函数对W5的偏导, 即: \[ \frac{\partial L o s s_{\text {total }}}{\partial w_5} \]

首先根据链式求导法则写出对W5求偏导的总公式, 再把图拿下来对照 (如上), 可以看出, 需要计算三部分的求 导【损失函数、激活函数、线性函数】, 下面就一步一步来:
第一步: \[ \frac{\partial \text { Loss }_{\text {total }}}{\partial o u t_{o 1}}=\frac{\partial \frac{1}{2}\left(\text { target }_1-o u t_{o 1}\right)^2+\frac{1}{2}\left(\text { target }_2-\text { out }_{o 2}\right)^2}{\partial o u t_{o 1}}=out _{o 1}- target _1 \] 第二步: \[ \frac{\partial o u t_{o 1}}{\partial \text { net }_{o 1}}=\frac{\partial \frac{1}{1+e^{-n e t_{o 1}}}}{\partial \text { net }_{o 1}}=\sigma\left(\right.net \left._{o 1}\right)\left(1-\sigma\left(\right.\right. net \left.\left._{o 1}\right)\right) \]
第三步: \[ \frac{\partial n e t_{o 1}}{\partial w_5}=\frac{\partial o u t_{h 1} w_5+\text { out }_{h 2} w_6}{\partial w_5}= out _{h_1} \] 综上三个步骤,得到总公式:
总公式: \[ \frac{\partial L_{o s s_{t o t a l}}}{\partial w_5}=\left(o u t_{o 1}-\right. target \left._1\right) \cdot\left(\sigma\left(\right.\right. net \left._{o 1}\right)\left(1-\sigma\left(\right.\right. net \left.\left.\left._{o 1}\right)\right)\right) \cdot out _{h_1} \]
- 第二个反向传播:
接下来,要求损失函数对\(w1\)的偏导,即: \[ \frac{\partial \operatorname{Loss}_{\text {total }}}{\partial w_1} \]
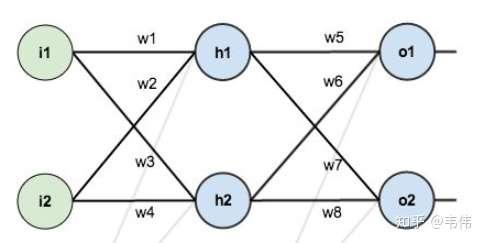
还是把图摆在这, 方便看, 先写出总公式, 对w1求导有个地方要注意, \(w 1\) 的影响不仅来自 01 还来自 02 , 从图上 可以一目了然, 所以总公式为: \[ \frac{\partial \text { Loss }_{\text {total }}}{\partial w_1}= l1 + l2 \]
\[ l1 = \frac{\partial \text { Loss }_{\text {total }}}{\partial o u t_{o 1}} \frac{\partial o u t_{o 1}}{\partial \text { net }_{o 1}} \frac{\partial n e t_{o 1}}{\partial \text { out }_{h 1}} \frac{\partial o u t_{h 1}}{\partial \text { net }_{h 1}} \frac{\partial \text { net }_{h 1}}{\partial w_1} \]
\[ l2 = \frac{\partial \text { Loss }_{\text {total }}}{\partial \text { out }_{o 2}} \frac{\text { out }_{o 2}}{\partial \text { net }_{o 2}} \frac{\partial \text { net }_{o 2}}{\partial \text { out }_{h 1}} \frac{\partial \text { out }_{h 1}}{\partial \text { net }_{h 1}} \frac{\partial n e t_{h 1}}{\partial w_1} \]
所以总共分为左右两个式子, 分别又对应 5 个步骤, 详细写一下左边, 右边同理:
第一步: \[ \frac{\partial \text { Loss }_{\text {total }}}{\partial o u t_{o 1}}=out _{o 1}- target _1 \]
第二步: \[ \frac{\partial o u t_{o 1}}{\partial \text { net }_{o 1}}=\sigma\left(n e t_{o 1}\right)\left(1-\sigma\left(n_{e 1} t_{o 1}\right)\right) \]
第三步: \[ \frac{\partial \text { net }_{o 1}}{\partial o u t_{h 1}}=\frac{\partial o u t_{h 1} w_5+\text { out }_{h 2} w_6}{\partial o u t_{h 1}}=w_5 \]
第四步: \[ \frac{\partial o u t_{h 1}}{\partial \text { net }_{h 1}}=\sigma\left(\right. net \left._{h 1}\right)\left(1-\sigma\left(\right.\right.net \left.\left._{h 1}\right)\right) \]
第二步: \[ \frac{\partial n e t_{h 1}}{\partial w_1}=\frac{\partial i_1 w_1+i_2 w_2}{\partial w_1}=i_1 \]
右边也是同理, 就不详细写了, 写一下总的公式: \[ \begin{aligned} & \frac{\partial \text { Loss }_{\text {total }}}{\partial w_1}=\left(\left(\text { out }_{o 1}-\text { target }_1\right) \cdot\left(\sigma\left(\text { net }_{o 1}\right)\left(1-\sigma\left(\text { net }_{o 1}\right)\right)\right) \cdot w_5 \cdot\left(\sigma\left(\text { net }_{h 1}\right)\left(1-\sigma\left(\text { net }_{h 1}\right)\right)\right) \cdot i_1\right) \\ & +\left(\left(\text { out }_{o 2}-\text { target }_2\right) \cdot\left(\sigma\left(\text { net }_{o 2}\right)\left(1-\sigma\left(\text { net }_{o 2}\right)\right)\right) \cdot w_7 \cdot\left(\sigma\left(\text { net }_{h 1}\right)\left(1-\sigma\left(\text { net }_{h 1}\right)\right)\right) \cdot i_1\right) \\ & \end{aligned} \] 这个公式只是对如此简单的一个网络结构的一个节点的偏导, 就这么复杂。。亲自推完才深深的意识到。。。
为了后面描述方便, 把上面的公式化简一下, out \({ }_{o 1}-\) target \(_1\) 记为 \(C_{o 1}, \sigma\left(\right.\) net \(\left._{o 1}\right)\left(1-\sigma\left(\right.\right.\) net \(\left.\left._{o 1}\right)\right)\) 记为 \(\sigma\left(n_e t_{o 1}\right)^{\prime}\) ,则: \[ \frac{\partial \text { Loss }_{t_{\text {otal }}}}{\partial w_1}=C_{o 1} \cdot \sigma\left(\text { net }_{o 1}\right)^{\prime} \cdot w_5 \cdot \sigma\left(\text { net }_{h 1}\right)^{\prime} \cdot i_1+C_{o 2} \cdot \sigma\left(\text { net }_{o 2}\right)^{\prime} \cdot w_7 \cdot \sigma\left(n e t_{h 1}\right)^{\prime} \cdot i_1 \]
1.2 梯度消失,爆炸产生原因
从上式其实已经能看出来, 求和操作其实不影响, 主要是是看乘法操作就可以说明问题, 可以看出, 损失函数对 w1的偏导, 与 \(C_{o 1}\), 权重w, sigmoid的导数有关, 明明还有输入i为什么不提? 因为如果是多层神经网络的中间 某层的某个节点,那么就没有输入什么事了。所以产生影响的就是刚刚提的三个因素。
再详细点描述,如图,多层神经网络:
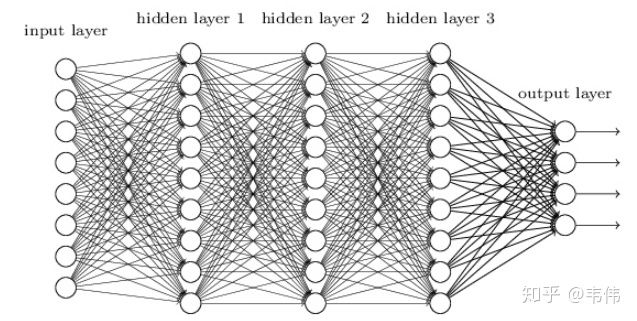
参考:PENG:神经网络训练中的梯度消失与梯度爆炸282 赞同 · 26 评论文章
假设 (假设每一层只有一个神经元且对于每一层 \(y_i=\sigma\left(z_i\right)=\sigma\left(w_i x_i+b_i\right)\), 其中 \(\sigma\) 为sigmoid函数), 如图:

则:
\[ \begin{aligned} & \frac{\partial C}{\partial b_1}=\frac{\partial C}{\partial y_4} \frac{\partial y_4}{\partial z_4} \frac{\partial z_4}{\partial x_4} \frac{\partial x_4}{\partial z_3} \frac{\partial z_3}{\partial x_3} \frac{\partial x_3}{\partial z_2} \frac{\partial z_2}{\partial x_2} \frac{\partial x_2}{\partial z_1} \frac{\partial z_1}{\partial b_1} \\ & =C_{y 4} \sigma^{\prime}\left(z_4\right) w_4 \sigma^{\prime}\left(z_3\right) w_3 \sigma^{\prime}\left(z_2\right) w_2 \sigma^{\prime}\left(z_1\right) \end{aligned} \]
看一下sigmoid函数的求导之后的样子:
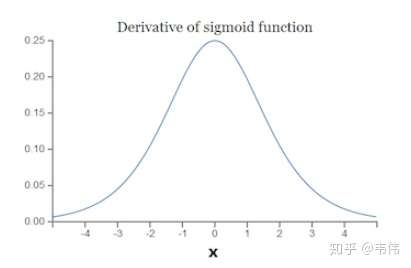
发现sigmoid函数求导后最大最大也只能是0.25。
再来看W,一般我们初始化权重参数W时,通常都小于1,用的最多的应该是0,1正态分布吧。
所以 \(\left|\sigma^{\prime}(z) w\right| \leq 0.25\), 多个小于1的数连乘之后, 那将会越来越小, 导致靠近输入层的层的权重的偏导几乎为 0 , 也就是说几乎不更新,这就是梯度消失的根本原因。
再来看看梯度爆炸的原因, 也就是说如果 \(\left|\sigma^{\prime}(z) w\right| \geq 1\) 时,连乘下来就会导致梯度过大, 导致梯度更新幅度特别 大, 可能会溢出, 导致模型无法收玫。sigmoid的函数是不可能大于1了, 上图看的很清楚, 那只能是w了, 这也 就是经常看到别人博客里的一句话, 初始权重过大, 一直不理解为啥。。现在明白了。
但梯度爆炸的情况一般不会发生, 对于sigmoid函数来说, \(\sigma(z)^{\prime}\) 的大小也与w有关, 因为 \(z=w x+b\), 除非该层的输入值 \(x\) 在一直一个比较小的范围内。
其实梯度爆炸和梯度消失问题都是因为网络太深, 网络权值更新不稳定造成的, 本质上是因为梯度反向传播中的连 乘效应。
所以,总结一下,为什么会发生梯度爆炸和消失:
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。
二、梯度消失、爆炸解决方案
2.1(预训练加微调):
提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。
Hinton在训练深度信念网络(Deep Belief Networks中,使用了这个方法,在各层预训练完成后,再利用BP算法对整个网络进行训练。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
2.2(梯度剪切、正则):
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
正则化是通过对网络权重做正则限制过拟合,仔细看正则项在损失函数的形式: \[ Loss =\left(y-W^T x\right)^2+\alpha\|W\|^2 \] 其中,\(\alpha\)是指正则项系数,因此,如果发生梯度爆炸,权值的范数就会变的非常大,通过正则化项,可以部分限制梯度爆炸的发生。
注:事实上,在深度神经网络中,往往是梯度消失出现的更多一些
2.3(改变激活函数):
首先说明一点,tanh激活函数不能有效的改善这个问题,先来看tanh的形式:
\[ \tanh (x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} \]
再来看tanh的导数图像:
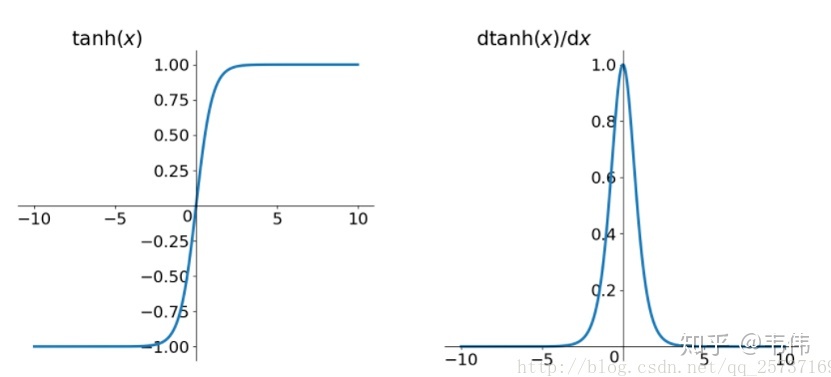
发现虽然比sigmoid的好一点,sigmoid的最大值小于0.25,tanh的最大值小于1,但仍是小于1的,所以并不能解决这个问题。
Relu:思想也很简单,如果激活函数的导数为1,那么就不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。先看一下relu的数学表达式: \[ \operatorname{Re} \operatorname{lu}(\mathrm{x})=\max (\mathrm{x}, 0)=\left\{\begin{array}{l}0, x<0 \\ x, x>0\end{array}\right\} \]
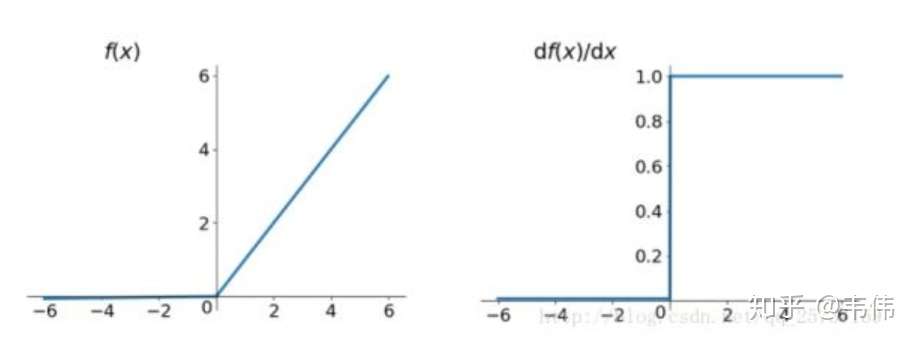
从上图中,我们可以很容易看出,relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
relu的主要贡献在于:
- 解决了梯度消失、爆炸的问题
- 计算方便,计算速度快
- 加速了网络的训练
同时也存在一些缺点:
- 由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
- 输出不是以0为中心的
leakrelu
leakrelu就是为了解决relu的0区间带来的影响, 其数学表达为: leakrelu \(=f(x)=\left\{\begin{array}{ll}x, & x>0 \\ x * k, & x \leq 0\end{array}\right.\) 其中k是leak 系数, 一般选择 0.1 或者 0.2 , 或者通过学习而来解决死神经元的问题。
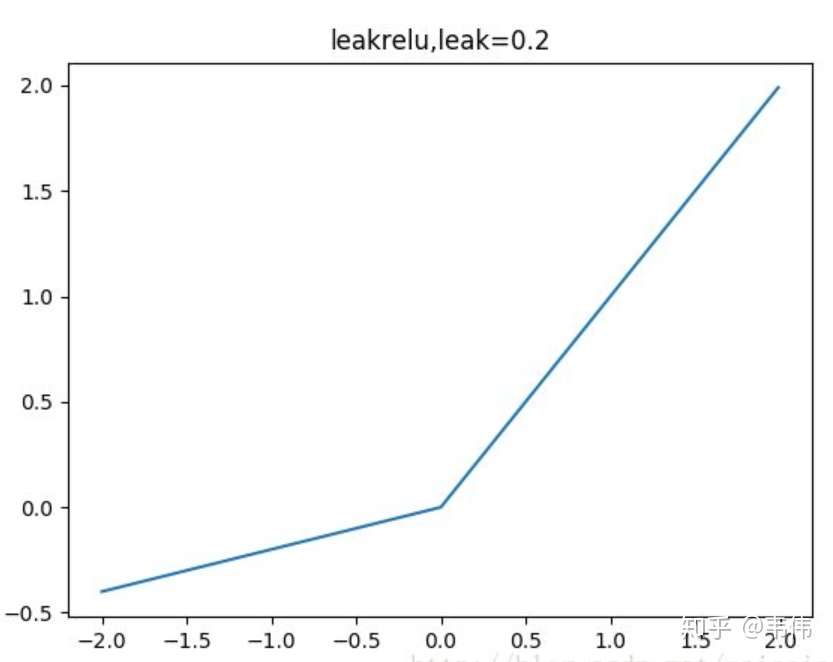
leakrelu解决了0区间带来的影响,而且包含了relu的所有优点
elu
elu激活函数也是为了解决relu的0区间带来的影响, 其数学表达为: \[ \left\{\begin{array}{cc} x, & \text { if } x>0 \\ \alpha\left(e^x-1\right), & \text { otherwise } \end{array}\right. \] 其函数及其导数数学形式为:
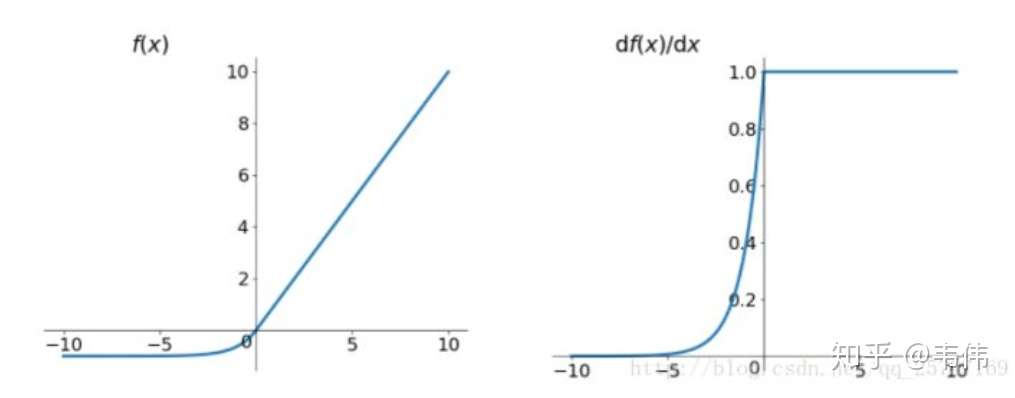
但是elu相对于leakrelu来说,计算要更耗时间一些,因为有e。
2.4(batchnorm):【梯度消失】
Batchnorm是深度学习发展以来提出的最重要的成果之一了, 目前已经被广泛的应用到了各大网络中, 具有加速网络收玫速度, 提升训练稳定性的效果, Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization, 简称 \(\mathrm{BN}\), 即批规范化, 通过规范化操作将输出信号x规范化到均值为 0 , 方差为 1 保证网络的稳定性。
具体的batchnorm原理非常复杂, 在这里不做详细展开, 此部分大概讲一下batchnorm解决梯度的问题上。具体来说就是反向传播中, 经过每一层的梯度会乘以该层的权重, 举个简单例子:正向传播中 \(f_3=f_2\left(w^T * x+b\right)\), 那么反向传播中, \(\frac{\partial f_2}{\partial x}=\frac{\partial f_2}{\partial f_1} w\), 反向传播式子中有 \(w\) 的存在, 所以 \(w\) 的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出做scale和shift的方法,通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布【假设原始是正态分布】强行拉回到接近均值为0方差为1的标准正太分布,即严重偏离的分布强制拉回比较标准的分布, 这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
2.5(残差结构):
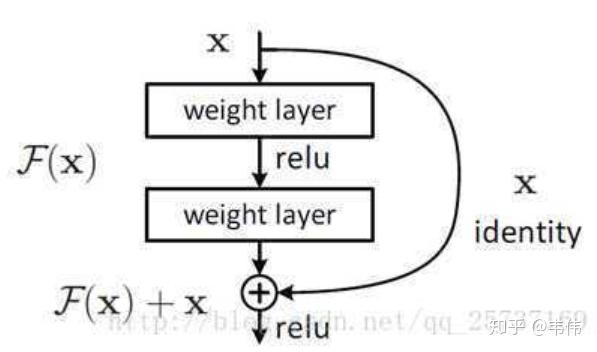
如图, 把输入加入到某层中, 这样求导时, 总会有个1在, 这样就不会梯度消失了。 \[ \frac{\partial \text { loss }}{\partial x_l}=\frac{\partial \text { loss }}{\partial x_L} \cdot \frac{\partial x_L}{\partial x_l}=\frac{\partial \text { loss }}{\partial x_L} \cdot\left(1+\frac{\partial}{\partial x_L} \sum_{i=l}^{L-1} F\left(x_i, W_i\right)\right) \] 式子的第一个因子 \(\frac{\partial l o s s}{\partial x_L}\) 表示的损失函数到达 \(\mathrm{L}\) 的梯度, 小括号中的 1 表明短路机制可以无损地传播梯度, 而另外一项残差梯度则需要经过带有weights的层, 梯度不是直接传递过来的。残差梯度不会那么巧全为- 1 , 而且就算其比较小, 有 1 的存在也不会导致梯度消失。所以残差学习会更容易。
注:上面的推导并不是严格的证,只为帮助理解
2.6(LSTM)
在介绍这个方案之前,有必要来推导一下RNN的反向传播,因为关于梯度消失的含义它跟DNN不一样!不一样!不一样!
先推导再来说,从这copy的:沉默中的思索:RNN梯度消失和爆炸的原因565 赞同
RNN结构如图:

假设我们的时间序列只有三段, \(S_0\) 为给定值, 神经元没有激活函数, 则RNN最简单的前向传播过程如下: \[ \begin{array}{ll} S_1=W_x X_1+W_s S_0+b_1 & O_1=W_o S_1+b_2 \\ S_2=W_x X_2+W_s S_1+b_1 & O_2=W_o S_2+b_2 \\ S_3=W_x X_3+W_s S_2+b_1 & O_3=W_o S_3+b_2 \end{array} \] 假设在 \(\mathrm{t}=3\) 时刻, 损失函数为 \(L_3=\frac{1}{2}\left(Y_3-O_3\right)^2\) 。
则对于一次训练任务的损失函数为 \(L=\sum_{t=0}^T L_t\), 即每一时刻损失值的累加。
使用随机梯度下降法训练 \(\mathrm{RNN}\) 其实就是对 \(W_x\) 、 \(W_s\) 、 \(W_o\) 以及 \(b_1 b_2\) 求偏导, 并不断调整它们以使L尽可能达 到最小的过程。
现在假设我们我们的时间序列只有三段, \(t 1, t 2, t 3\) 。我们只对 \(\mathrm{t}\) 时刻的 \(W_x 、 W_s 、 W_0\) 求偏导(其他时刻类似): \[ \begin{gathered} \frac{\partial L_3}{\partial W_0}=\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial W_o} \\ \frac{\partial L_3}{\partial W_x}=\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial W_x}+\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2} \frac{\partial S_2}{\partial W_x}+\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2} \frac{\partial S_2}{\partial S_1} \frac{\partial S_1}{\partial W_x} \\ \frac{\partial L_3}{\partial W_s}=\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial W_s}+\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2} \frac{\partial S_2}{\partial W_s}+\frac{\partial L_3}{\partial O_3} \frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2} \frac{\partial S_2}{\partial S_1} \frac{\partial S_1}{\partial W_s} \end{gathered} \] 可以看出对于 \(W_0\) 求偏导并没有长期依赖,但是对于 \(W_x 、 W_s\) 求偏导,会随着时间序列产生长期依赖。因为 \(S_t\) 随着时间序列向前传播, 而 \(S_t\) 又是 \(W_x 、 W_s\) 的函数。
根据上述求偏导的过程, 我们可以得出任意时刻对 \(W_x 、 W_s\) 求偏导的公式: \[ \frac{\partial L_t}{\partial W_x}=\sum_{k=0}^t \frac{\partial L_t}{\partial O_t} \frac{\partial O_t}{\partial S_t}\left(\prod_{j=k+1}^t \frac{\partial S_j}{\partial S_{j-1}}\right) \frac{\partial S_k}{\partial W_x} \] 任意时刻对 \(W_s\) 求偏导的公式同上。
如果加上激活函数, \(S_j=\tanh \left(W_x X_j+W_s S_{j-1}+b_1\right)\) ,则 \(\prod_{j=k+1}^t \frac{\partial S_j}{\partial S_{j-1}}=\prod_{j=k+1}^t \tanh W_s^{\prime}\) 激活函数tanh和它的 导数图像在上面已经说过了, 所以原因在这就不帻述了, 还是一样的, 激活函数导数小于 1 。
现在来解释一下,为什么说RNN和DNN的梯度消失问题含义不一样?
- 先来说DNN中的反向传播:在上文的DNN反向传播中,我推导了两个权重的梯度,第一个梯度是直接连接着输出层的梯度,求解起来并没有梯度消失或爆炸的问题,因为它没有连乘,只需要计算一步。第二个梯度出现了连乘,也就是说越靠近输入层的权重,梯度消失或爆炸的问题越严重,可能就会消失会爆炸。一句话总结一下,DNN中各个权重的梯度是独立的,该消失的就会消失,不会消失的就不会消失。
- 再来说RNN:RNN的特殊性在于,它的权重是共享的。抛开W_o不谈,因为它在某时刻的梯度不会出现问题(某时刻并不依赖于前面的时刻),但是W_s和W_x就不一样了,每一时刻都由前面所有时刻共同决定,是一个相加的过程,这样的话就有个问题,当距离长了,计算最前面的导数时,最前面的导数就会消失或爆炸,但当前时刻整体的梯度并不会消失,因为它是求和的过程,当下的梯度总会在,只是前面的梯度没了,但是更新时,由于权值共享,所以整体的梯度还是会更新,通常人们所说的梯度消失就是指的这个,指的是当下梯度更新时,用不到前面的信息了,因为距离长了,前面的梯度就会消失,也就是没有前面的信息了,但要知道,整体的梯度并不会消失,因为当下的梯度还在,并没有消失。
- 一句话概括:RNN的梯度不会消失,RNN的梯度消失指的是当下梯度用不到前面的梯度了,但DNN靠近输入的权重的梯度是真的会消失。
说完了RNN的反向传播及梯度消失的含义,终于该说为什么LSTM可以解决这个问题了,这里默认大家都懂LSTM的结构,对结构不做过多的描述。见第三节。【LSTM通过它的“门控装置”有效的缓解了这个问题,这也就是为什么我们现在都在使用LSTM而非普通RNN。】
三、缓解梯度消失&爆炸 Q&A
1、残差神经网络为什么可以缓解梯度消失?
残差单元可以以跳层连接的形式实现,即将单元的输入直接与单元输出加在一起,然后再激活。因此残差网络可以轻松地用主流的自动微分深度学习框架实现,直接使用BP算法更新参数损失对某低层输出的梯度,被分解为了两项。
(1)从前后向信息传播的角度来看
普通神经网络前向传播。前向传播将数据特征逐层抽象, 最终提取出完成任务所需要的特征/表示。 \[ a^{l_2}=F\left(a^{l_2-1}\right)=F\left(F\left(a^{l_2-2}\right)\right)=\ldots \] 普通神经网络反向传播。梯度涉及两层参数交叉相乘, 可能会在离输入近的网络中产生梯度消失的现象。 \[ \frac{\partial \epsilon}{\partial a^{l_1}}=\frac{\partial \epsilon}{\partial a^{l_2}} \frac{\partial a^{l_2}}{\partial a^{l_1}}=\frac{\partial \epsilon}{\partial a^{l_2}} \frac{\partial a^{l_2}}{\partial a^{l_2-1}} \ldots \frac{\partial a^{l_1+1}}{\partial a^{l_1}} \] 残差网络前向传播。输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以 解决网络退化问题。 \[ a^{l_2}=a^{l_2-1}+F\left(a^{l_2-1}\right)=\left(a^{l_2-2}+F\left(a^{l_2-2}\right)\right)+F\left(a^{l_2-1}\right)=\ldots=a^{l_1}+\sum_{i=l_1}^{l_2-1} F\left(a^i\right) \] 残差网络反向传播。 \(\frac{\partial \epsilon}{\partial a^{l_2}}\) 表明, 反向传播时, 错误信号可以不经过任何中间权重矩阵变换直接传播到低层, 一定 程度上可以缓解梯度弥散问题(即便中间层矩阵权重很小,梯度也基本不会消失)。 \[ \frac{\partial \epsilon}{\partial a^{l_1}}=\frac{\partial \epsilon}{\partial a^{l_2}}\left(1+\frac{\partial \sum_{i=l_1}^{l_2-1} F\left(a^i\right)}{a^{l_1}}\right) \] 所以可以认为残差连接使得信息前后向传播更加顺畅。
(2) 集成学习的角度
将残差网络展开,以一个三层的ResNet为例,可得到下面的树形结构: \[
\begin{array}{ll}
y_3=y_2+f_3\left(y_2\right)=
\left[y_1+f_2\left(y_1\right)\right]+f_3\left(y_1+f_2\left(y_1\right)\right)
\\
=\left[y_0+f_1\left(y_0\right)+f_2\left(y_0+f_1\left(y_0\right)\right)\right]+f_3\left(y_0+f_1\left(y_0\right)+f_2\left(y_0+f_1\left(y_0\right)\right)\right)
\end{array}
\] 
残差网络就可以被看作是一系列路径集合组装而成的一个集成模型,其中不同的路径包含了不同的网络层子集。
特点:
- 跳层连接;
- 例子:DCN(Deep Cross Network)、Transformer;
- 有效的缓解梯度消失问题的手段;
- 输入和输出维度一致,因为残差正向传播有相加的过程\(a^{l_2}=a^{l_2-1}+F\left(a^{l_2-1}\right)\);
参考文献
- 残差神经网络为什么可以缓解梯度消失? - 十三的文章 - 知乎 https://zhuanlan.zhihu.com/p/452867110
- 从反向传播推导到梯度消失and爆炸的原因及解决方案(从DNN到RNN,内附详细反向传播公式推导) - 韦伟的文章 - 知乎 https://zhuanlan.zhihu.com/p/76772734
- DoubleV:详解深度学习中的梯度消失、爆炸原因及其解决方法