恶意加密流量(1)DataCon2020恶意加密流量检测
DataCon2020-恶意加密流量检测
- 思科AISec’16:《Identifying Encrypted Malware Traffic with Contextual Flow Data》:https://www.cnblogs.com/bonelee/p/9604530.html
一、流量处理的工具
zeek
joy
二、A Novel Malware Encrypted Traffic DetectionFramework Based On Ensemble Learning
zeek:https://docs.zeek.org/en/master/logs/index.html zeek-flowmeter:https://github.com/zeek-flowmeter/zeek-flowmeter zeek-tls-log-alternative:https://github.com/0xxon/zeek-tls-log-alternative
概述:
在我们的工作中,有一些定义。首先,将5元组定义为源IP、源端口、目标IP、目标端口和协议。其次,前向流是从客户端到服务器具有相同5元组的数据包集。反向词流与正向流相似,但与五元组相反。最后,流动是向前流动和向后流动的结合。由于我们从流量中提取的特征是异构的,我们不能简单地将它们合并并以常见的方式将它们装配到单个分类器中。我们将不同的特征匹配到相应的分类器中,并进行多数投票以获得最终结果。同时,我们考虑了flowlevel和host级别的行为。对不同级别的特性进行聚合和分析,以提高框架的TPR和较低的FPR。图1:。概述了我们的框架。我们将介绍每个特性以及相应的分类器、实现和性能。
2.1 数据包级
(1)长度分布
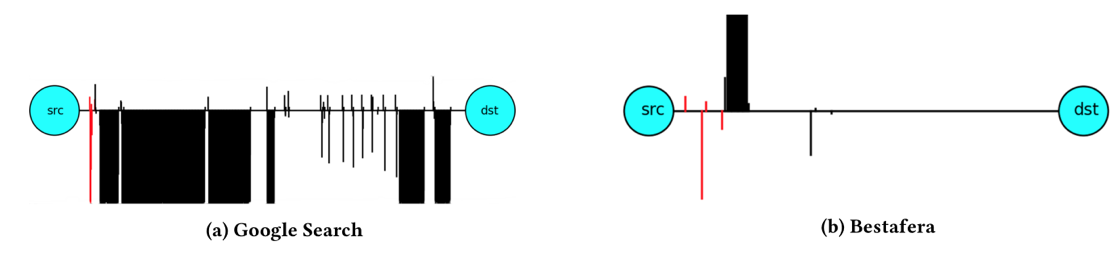
根据Cisco的研究【17】,恶意软件和普通软件在正向流和反向流中的数据包长度分布不同。 例如,当我们使用谷歌搜索时,客户端向服务器发送少量数据包,然后服务器返回大量数据包。然而,恶意软件的作用恰恰相反:恶意软件通常让客户端将数据传输到服务器,然后服务器定期返回调度命令。无论是否加密,数据包长度始终可见,因此它适合作为一种功能。我们将数据包长度和方向编码为一维独立特征。我们推测,感染恶意软件的客户端和服务器之间的一些控制消息的长度总是相似且频繁的,这具有很好的区分程度。我们考虑每个可能的数据包长度和方向元组。由于Internet上的最大传输单元(MTU)是1500字节,并且数据包的方向有两个发送或接收方向,因此我们的长度分布特征是3000维。为了提取这些特征,我们计算具有不同长度的所有数据包的数量,并进行规范化以确保概率分布。我们使用随机森林(RF)算法来处理这些特征。因为它能更好地处理高维特征,并且具有可解释性。
(2)长度序列
第二部分,在不使用序列信息的情况下,我们只使用了数据包长度的统计特征,这可能会在时间上丢失一些信息,因此我们提取了数据包长度序列。我们在每个客户端的双向上取前1000个数据包长度,并将其放入TextCNN算法中以提取局部序列关系。因为该算法运行速度快,精度高。文本数据的卷积神经网络TextCNN【22】是一种用于句子分类任务的有用的深度学习算法。在这种情况下,我们将每个数据包的长度视为一个单词,长度序列相当于一个句子。
(3)服务器IP
在我们的数据集中,服务器IP地址是一个重要的标识符。我们假设,在同一地区,如果客户端感染了相同的恶意软件,则可能会导致其访问相同的服务器IP地址。因此,我们还考虑了对服务器IP地址的访问。值1或0表示是否访问了特定的服务器IP地址(一个热编码)。我们使用朴素贝叶斯(NB)算法来处理这些特征。由于朴素贝叶斯算法是一种非参数算法,其本质是寻找特征和标签之间的关系。因此,它可以被视为一个黑名单。
(4)词频分类器
X509证书在Internet上广泛使用。它们用于验证实体之间的信任。证书颁发机构通常将X509证书链接在一起。如图2所示。[23],X509证书提供URL、组织、签名等信息。我们从培训集中每个客户端的TLS流中提取X509证书链,并获取证书中主题和颁发者中包含的单词。我们将所有单词组合在一起,并将客户的流量视为由这些单词组成的句子。与B部分类似,我们计算每个单词的数量并将其用作特征。0我们使用朴素贝叶斯(NB)算法来处理这些特征。如果测试集样本证书中的所有单词从未出现在训练集中,我们将直接推断它是恶意的。因为训练集包含最流行的域名。

==(5)TCP状态马尔可夫==
我们发现恶意流量和正常流量之间TCP连接状态的分布是不同的。表一说明了可能的TCP连接状态24:
我们按照流出现的时间对其进行排序,然后使用马尔可夫随机场转移矩阵(MRFTM)对该特征进行编码。MRFTM在建模连接状态序列时很有用。MRFTM[i,j]中的每个条目统计第i个和第j个状态之间的转换次数。最后,我们对MRFTM的行进行规范化,以确保适当的马尔可夫链。然后我们将其重塑为一维向量,也就是说,我们使用MRFTM的条目作为特征。我们使用随机森林(RF)算法来处理这些特征。
2.2 会话流级
(6)会话流量统计
在加密流量中,上述5种分类器在主机级使用不同的特征提取方法和分类方法。此外,为了进一步提高准确率,防止恶意软件由于缺乏领域知识而欺骗分类器,我们还提取了TLS握手中的明文信息。在这个分类器中,我们首先考虑流级特征。我们仅选择TLS流,并分析每个流。一旦推断流是恶意的,就会推断相应的客户端被感染。我们对TCP和TLS协议进行了深入分析,提取了1000多个维度的流级特征,包括以下部分:
- TCP连接状态特性:如F部分所述,我们对每个流的TCP连接状态进行一次热编码。
- 统计特征:我们还提取常规统计特征,表II显示了相关特征名称和描述。

长度马尔可夫特征:数据包长度序列的操作类似于F部分中的TCP连接状态序列。长度值被离散为大小相等的容器。长度数据马尔可夫链有10个箱子,每个箱子150字节。假设一个1500字节的MTU,任何观察到的大小大于1350字节的数据包都被放入同一个bin中。
TLS握手功能:我们发现客户端和服务器的TLS协议版本在恶意和良性TLS流之间有不同的分布,因此我们对客户端和服务器的TLS版本进行了一次热编码。此外,由于恶意软件可能使用旧的密码套件,我们在客户端和服务器上都对密码套件和扩展进行n-hot编码,即将所有密码套件和扩展扩展扩展为一维0向量,如果当前流使用某个密码套件或扩展,则相应的位置集值为1。
TLS证书特性:我们发现,在恶意流中,很大一部分叶证书是自签名的,或者自签名证书出现在证书链中。恶意软件喜欢利用的自签名证书的成本很低。因此,我们分析从服务器发送的证书:证书链是否包含自签名证书、叶证书是否过期、证书版本、证书有效期、公钥长度、是否发生警报。同时,考虑到之前的词频分类器,我们发现一些词无法区分恶意和良性,因此我们还将流词频添加到流特征中。
合并和适配:我们将上述功能合并到5元组(源IP、目标IP、源端口、目标端口和协议)中,并将其适配到随机林(RF)算法中。一旦流被推断为恶意,相应的客户端就会被推断为受到恶意影响。
在本节中,我们使用来自真实恶意软件的加密流量来评估我们的框架。首先,我们描述了数据集的格式。其次,我们分析了每个分类器的有效性以及集成后的有效性。然后,我们展示了我们的集成学习方法的优势。
数据表示:
如表三所示,列车数据包括3000台正常主机产生的正常流量和3000台恶意软件感染主机产生的恶意流量。我们的任务是检测测试数据中的客户端IP地址是否感染了恶意软件。

表V显示了每个分类器的得分。我们将每个分类器与投票结果进行比较,发现集成后的最终效果优于任何单个分类器的得分。我们的方法得分为86.6,TPR为95.0%,FPR为8.4%。流量统计分类器得分最高,其次是长度序列分类器和长度分布分类器。我们在每个分类器中使用默认参数。由于流级特征包含最丰富的信息,因此流统计分类器的性能最好,正如我们所期望的那样。我们可以推断,数据包长度是一个重要特征。事实上,在流量分类(非恶意流量检测)领域,有很多优秀的作品使用数据包长度进行分类,并取得了很好的效果[11][25]。目前,已有的一些基于机器学习的工作[8][9]与我们的流统计分类器或流合并分类器相似,也就是说,它们只使用流级特征或主机级特征。经过实验,我们的最终效果已经超过了每一个分类器。这表明我们的框架是有效和健壮的。此外,框架可以很容易地调整每个分类器的概率阈值,以提高TPR或降低FPR,以适应不同的场景。

三、知乎-s1mple
特征选择(Feature Selection),选取对于区分正常/恶意流量有明显作用的 Features。
- TLS客户端指纹信息
- 客户端支持的加密套件数组(Cipher suites),服务器端选择的加密套件。
- 支持的扩展(TLS extensions),若分别用向量表示客户端提供的密码套件列表和 TLS 扩展列表,可以从服务器发送的确认包中的信息确定两组向量的值。
- 客户端公钥长度(Client public key length),从密钥交换的数据包中,得到密钥的长度。
- Client version,the preferred TLS version for the client
- 是否非CA自签名,统计数据表示,恶意流量约70%出现非CA认证服务器且自签名的情况,非恶意流量约占0.1%。此项判断的依据是:未出现
CA: True字段(默认非 CA 机构)且signedCertificate中的issuer字段等于subject字段。
在进行TLS握手时,会进行如下几个步骤:
- Client Hello,客户端提供支持的加密套件数组(cipher suites);
- Server Hello,由服务器端选择一个加密套件,传回服务器端公钥,并进行认证和签名授权(Certificate + Signature);
- 客户端传回客户端公钥(Client Key Exchange),客户端确立连接;
- 服务器端确立连接,开始 HTTP 通信。

- 数据包元数据
- 数据包的大小,数据包的长度受 UDP、TCP 或者 ICMP 协议中数据包的有效载荷大小影响,如果数据包不属于以上协议,则被设置为 IP 数据包的大小。
- 到达时间序列
- 字节分布
- HTTP头部信息
- Content-Type,正常流量 HTTP 头部信息汇总值多为
image/*,而恶意流量为text/*、text/html、charset=UTF-8或者text/html;charset=UTF-8。 - User-Agent
- Accept-Language
- Server
- HTTP响应码
- Content-Type,正常流量 HTTP 头部信息汇总值多为
- DNS响应信息
- ==域名的长度==:正常流量的域名长度分布为均值为6或7的高斯分布(正态分布);而恶意流量的域名(FQDN全称域名)长度多为6(10)。
- ==数字字符及非字母数字(non-alphanumeric character)的字符占比==:正常流量的DNS响应中全称域名的数字字符的占比和非字母数字字符的占比要大。
- DNS解析出的IP数量:大多数恶意流量和正常流量只返回一个IP地址;其它情况,大部分正常流量返回2-8个IP地址,恶意流量返回4或者11个IP地址。
- TTL值:正常流量的TTL值一般为60、300、20、30;而恶意流量多为300,大约22%的DNS响应汇总TTL为100,而这在正常流量中很罕见。
- 域名是否收录在Alexa网站:恶意流量域名信息很少收录在Alexa top-1,000,000中,而正常流量域名多收录在其中。
- TLS客户端指纹信息
特征提取(Feature Extraction),从 pcap 文件中提取上述 Features,并转换为模型训练所需要的格式。我们选择的特征提取工具为 Zeek。特征提取我们采用的工具是 Zeek,它的前身是 Bro,一款网络安全监视(Network Security Monitoring)工具,它定义了自己的 DSL 语言,支持直接处理 pcap 文件生成各类日志文件,包括 dns、http、smtp 等:Zeek 网上有一些现成的脚本,我们采用的是 Zeek FlowMeter,它基于 OSI 七层协议的网络层和传输层,可以分析并生成一些 Packets 到达时间序列、Packet 字节大小和元数据等新特征。在使用时,我们需要在
local.zeek配置文件中加入@load flowmeter,这样 Zeek 在执行时会加载flowmeter.zeek并生成对应的flowmeter.log,下面列出了 FlowMeter 提取出的一些特征,包括上下行包总数、包负载均值方差等。其他详细的特征请见 zeek-flowmeter GitHub官方文档。除flowmeter.log之外我们还需要关注conn.log、ssl.log和X509.log。这几个日志共同字段uid是 Zeek 根据一次连接的源/目的 IP、源/目的端口四元组生成的唯一 ID。为了方便后续的处理,我们将这几个日志文件统一读入,使用uid字段连接后转成 csv 格式输出到文件。最终我们提取的特征如下:
模型训练(Model Training),选择合适的机器学习模型对三类 pcap 文件进行训练和预测。我们选择的 Python 机器学习库为 scikit-learn。
- Anomaly Detector:在 black
数据集中同时存在恶意流量和正常流量,没有明确的标注,无法直接用于训练分类器。而
white 数据集中都是正常流量,可以先用 white 数据集来训练一个 Anomaly
Detector 分类器。然后用这个分类器在 black
数据集中推理得到哪些是恶意流量。我们的模型选取的隔离森林
IsolationForest。 - Misuse Detector:假设这些由异常检测器识别的可疑流量是恶意流量,我们就有了恶意流量的标注。接下来我们用这些恶意流量 labels,结合 white 数据集中的正常流量 labels,来训练一个 Misuse Detector。我们选取了 XGBoost 基于树的模型,目标选取为多分类问题(分类数为2)。
- Anomaly Detector:在 black
数据集中同时存在恶意流量和正常流量,没有明确的标注,无法直接用于训练分类器。而
white 数据集中都是正常流量,可以先用 white 数据集来训练一个 Anomaly
Detector 分类器。然后用这个分类器在 black
数据集中推理得到哪些是恶意流量。我们的模型选取的隔离森林
四 、加密恶意流量检测方向(清华大学HawkEye战队)
清华大学HawkEye战队:https://datacon.qianxin.com/blog/archives/122
4.1 概述
我们所采用的检测方法的总体结构是让多个分别利用不同的异构特征训练而成的分类器进行多数投票 (Majority Voting) 的方式来获取最终的判定结果。
由于我们所采用的多种特征是异构数据, 且具有不同的组织特点,我们并没有直接采用将这些特征统一编码并输入到集成学习分类器中的常规方式,而是针对各个特征的特点分别构建对应的分类器,并利用他们的分类结果进行投票,最终取得多数票的分类结果被定为最终的分类结果。
参与投票的多个模型中部分使用了多维特征综合分析,另一部分使用经过分析后黑白样本区分较大的、置信度较高的单维特征对多维特征中的潜在的过拟合和判断错误进行消解。同时,我们考虑到了数据包级、流级、主机级多维度的行为建模,将不同层次的数据进行聚合分析,提升对于黑白样本建模的准确度。图1展 示了我们方案的整体流程。下面我们将分别介绍我们所采用的特征及对应的分类器、投票机制、 实现和性能以及展望和总结。
4.2 特征选取与子分类器
下面我们将详细介绍六个参与投票的子模型中的每一个模型所采用的特征及对应的分类器, 以及设计的动机和意义。

(1)包长分布特征(3000维)
不同的软件在通信数据的体量上具有不同的特点,我们认为功能或实现相似的软件会具有 相同的数据包体量分布特点,正如视频软件的下行流量通常远大于上行流量,而恶意键盘记录 器的上行流量总是远大于下行流量一样。
将每一个可能的报文长度和方向的二元组视为包长分布特征中的一个独立的维度。由 于以太网最小帧长为64 字节,而互联网的最大传输单元通常是 1500 字节,报文的方向只有收发两个方向,我们的包长分布特征是一个维数约 3000 的概率分布。
编码方式与分类器:
对该特征的提取,我们采用 以频率估计概率的方式,统计每个流量样本中的各个长度和方向的报文的数量,并除以报文总 数得到其概率分布。
由于包长分布的特征本质上是一个离散概率分布,最直接的分类器应该是基于度量的分类 算法,通过度量分布之间的相似性大小来判断其类别所属。我们采用了 Hellinger 距离的度量方式与kNN分类算法,Hellinger 距离是在概率分布空间对欧氏距离的模拟。由于kNN算法并不需要训练过程,而在分类过程中需要计算待分类的样例与已有样本集中的每个样例的相似性度量结果,因此其运行效率十分低下,于是我们也考虑了采用随机森林的分类器来利用这一特征的方式。
(2)证书主体与签发者黑白名单特征
我们认为决定一个软件是否是恶意软件不仅仅取决于其通信内容,也取决于其通信的对象, 而通信内容由于加密无法作为可辨识的特征,因此我们着重考虑了客户端流量样本中的通信对象。
在 TLS 建立连接的过程中,服务端发来的证书中的叶子证书的 Subject 字段表明了客户端的直接通信对象,而 Issuer 字段则表明了该证书的直属签发机构。
Subject 字段里的 common name 通常是一个域名,我们认为这将是一个很重要的标识信息,因为恶意软件与恶意域名关联的可 能性较大。图3中展示了恶意和正常证书中主体和签发者的情况,可以看出黑白样本有明显区别 并都存在着访问频次较高的项。

编码方式与分类器:
我们对训练集中的每个流量样本统计了其中的叶子证书所涉及到的不同 Subject 和 Issuer 的 数量,并记录每个流量样本与他们通信的频数。
X509证书在Internet上广泛使用。它们用于验证实体之间的信任。证书颁发机构通常将X509证书链接在一起。如图2所示。[23],X509证书提供URL、组织、签名等信息。我们从培训集中每个客户端的TLS流中提取X509证书链,并获取证书中主题和颁发者中包含的单词。我们将所有单词组合在一起,并将客户的流量视为由这些单词组成的句子。与B部分类似,我们计算每个单词的数量并将其用作特征。0我们使用朴素贝叶斯(NB)算法来处理这些特征。如果测试集样本证书中的所有单词从未出现在训练集中,我们将直接推断它是恶意的。因为训练集包含最流行的域名。

(3)通信 IP 地址黑白名单特征
除了证书中的 Subject 和 Issuer 信息外,服务端 IP 地址是另一个表示软件通信对象的标识 符。有少数流量样本中出现了缺少证书的情况,且我们认为同一地区遭受同类恶意软件感染很 可能会造成他们对相同的 IP 地址的访问,因此我们将流量样本中的远程 IP 地址的访问情况也 作为一个判断是否包含恶意流量的依据。
(4)流级荷载无关特征提取
对于黑样本的流标记问题存在一定问题,由于被感染的主机也可能会进行正常通信,而且 恶意软件也可能出现正常行为
我们首先考虑流级特征,由于 TCP 连接可以由流的四元组确定,所以恶意通信一般是指流 级别的,分析每条流的黑或白是十分合理的。我们综合考虑了已有相关工作 [1–3],以及对 TCP、 TLS/SSL 协议进行深入分析,共提取了超过 1000 维与荷载无关的流级特征,包含如下几部分:
- 元数据(Metadata):即单条流的基本统计数据,包含持续时间(duration)、总的流入(inbound)/流出(outbound)的字节数、数据包个数;
- 窗口序列统计特征:我们对出/入流量分别维护了包时间间隔和包长度的窗口,每个窗口提取统计特征,包含平均值、标准差、最大值、最小值;除此而外,我们发现仅仅关注一整个窗口的特征粒度不够细化,为了更加精细化的对流量行为进行捕获和建模,我们关注窗口中的每个数据包,并使用马尔科夫转移矩阵的方式捕获相邻包之间的关系。以构建包长窗口的马尔科夫矩阵为例,我们首先将包长均匀分成 15 个桶(bin),然后建立 15×15 的矩阵,每个元素表示从行转移到列所代表的的桶,最后对矩阵进行行的归一化处理,将其转化为概率形式;
- TLS/SSL 握手包特征:首先我们发现本赛题中客户端和服务器端都出现了多种不同的协议类型,而黑和白训练集中客户端和服务器不同版本的分布是不同的,因此协议版本可以 作为一个特征,我们将客户端和服务器端使用的 TLS 版本进行独热(one-hot)编码;同时 我们关注到 Hello 包中 GMT Unix Time 字段在黑/白训练集中的分布也有所不同,因此我 们将客户端和服务器端的 GMT Unix Time 的是否存在、是否使用随机时间编码为 0/1 的特征;此外,由于恶意软件和恶意服务器使用的加密套件和列表很有可能与正常的加密流量 有所区别, 我们将客户端与服务器端的加密套件(列表)和扩展列表进行独热编码,即将 所有可能的加密套件和扩展列出展成一维 0 向量,当前流使用的套件和扩展对应的位置赋 值为 1;
- TLS/SSL证书特征:服务器端证书对于区分正常和恶意流量有着重要的作用,如恶意通信的证书多采用自签名的方式。因此我们对服务器端证书进行了特征挖掘,主要选用如下的 0/1 特征: 是否自签名、是否过期、版本号、证书有效期、公钥长度;同时,我们考虑到之 前模型发现有些证书主体域名单一使用无法区分黑/白的情况,因此也嵌入到多维特征中, 使用独热编码对训练集常用证书主体域名进行独热编码。
(5)主机级荷载无关特征聚合 (流级统计信息)
单独的看每条流可能漏掉了流之间的关联行为即主机级别的行为,比如恶意软件在发出正常的访问谷歌流量后可能就要开始进行恶意传输。再比如,有少量正常流也会出现自 签名,如果我们单独看流,可能就会误判,但是如果我们基于主机提取特征发现同一 IP 下有多条流都是自签名,则我们就会有很大的信心认为这是恶意的。因此,我们将上一小节中流级别 的特征进行聚合,并以流为基本单位提取主机级别特征。
主机级特征聚合部分主要考虑了如下的特征:
- 总包个数,每条流的平均包个数,时间间隔、包长的均值,以及上一个小节中证书部分的相关特 征,即自签名流数量,过期流数量,有效期过长(比如 100年)的流数量及其均值。
- TLS 半连接 和无连接