模型部署(4)DaaS-Client
HOW 自动部署开源AI模型到生产环境?
一、背景介绍
AI的广泛应用是由AI在开源技术的进步推动的,利用功能强大的开源模型库,数据科学家们可以很容易的训练一个性能不错的模型。但是因为模型生产环境和开发环境的不同,涉及到不同角色人员:模型训练是数据科学家和数据分析师的工作,但是模型部署是开发和运维工程师的事情,导致模型上线部署却不是那么容易。
DaaS(Deployment-as-a-Service)是AutoDeployAI公司推出的基于Kubernetes的AI模型自动部署系统,提供一键式自动部署开源AI模型生成REST API,以方便在生产环境中调用。下面,我们主要演示在DaaS中如何部署经典机器学习模型,包括Scikit-learn、XGBoost、LightGBM、和PySpark ML Pipelines。关于深度学习模型的部署,会在下一章中介绍。
DMatrix 格式 在xgboost当中运行速度更快,性能更好。
二、部署准备
我们使用DaaS提供的Python客户端(DaaS-Client)来部署模型,对于XGBoost和LightGBM,我们同样使用它们的Python API来作模型训练。在训练和部署模型之前,我们需要完成以下操作。
- 安装Python DaaS-Client
1 | pip install --upgrade git+https://github.com/autodeployai/daas-client.git |
- 初始化DaasClient。使用DaaS系统的URL、账户、密码登陆系统,文本使用的DaaS演示系统安装在本地的Minikube上。完整Jupyter Notebook,请参考:deploy-sklearn-xgboost-lightgbm-pyspark.ipynb
1 | from daas_client import DaasClient |
- 创建项目。DaaS使用项目管理用户不同的分析任务,一个项目中可以包含用户的各种分析资产:模型、部署、程序脚本、数据、数据源等。项目创建成功后,设置为当前活动项目,发布的模型和创建的部署都会存储在该项目下。
create_project函数接受三个参数:- 项目名称:可以是任意有效的Linux文件目录名。
- 项目路由:使用在部署的REST
URL中来唯一表示当前项目,只能是小写英文字符(a-z),数字(0-9)和中横线
-,并且-不能在开头和结尾处。 - 项目说明(可选):可以是任意字符。
1 | project = '部署测试' |
- 初始化数据。我们使用流行的分类数据集
iris来训练不同的模型,并且把数据分割为训练数据集和测试数据集以方便后续使用。
1 | from sklearn import datasets |
- 模型部署流程。主要包含以下几步:
- 训练模型。使用模型库提供的API,在
iris数据集上训练模型。 - 发布模型。调用
publish函数发布模型到DaaS系统。 - 测试模型(可选)。调用
test函数获取测试API信息,可以使用任意的REST客户端程序测试模型在DaaS中是否工作正常,使用的是DaaS系统模型测试API。第一次执行test会比较慢,因为DaaS系统需要启动测试运行时环境。 - 部署模型。发布成功后,调用
deploy函数部署部署模型。可以使用任意的REST客户端程序测试模型部署,使用的是DaaS系统正式部署API。
- 训练模型。使用模型库提供的API,在
三、部署Scikit-learn模型
- 训练一个Scikit-learn分类模型:SVC
1 | from sklearn.svm import SVC |
- 发布Scikit-learn模型
1 | publish_resp = client.publish(model, |
test函数必须要指定前两个参数,第一个model是训练的模型对象,第二个是模型名称,其余是可选参数:
- mining_function:指定挖掘功能,可以指定为
regression(回归)、classification(分类)、和clustering(聚类)。 - X_test和y_test:指定测试训练集,发布时计算模型评估指标,比如针对分类模型,计算正确率(Accuracy),对于回归模型,计算可释方差(explained Variance)。
- data_test:
同样是指定测试训练集,但是该参数用在Spark模型上,非Spark模型通过
X_test和y_test指定。 - description:模型描述。
- params:记录模型参数设置。
publish_resp是一个字典类型的结果,记录了模型名称,和发布的模型版本。该模型是iris模型的第一个版本。
1 | {'model_name': 'iris', 'model_version': '1'} |
- 测试Scikit-learn模型
1 | test_resp = client.test(publish_resp['model_name'], |
test_resp是一个字典类型的结果,记录了测试REST
API信息。如下,其中access_token是访问令牌,一个长字符串,这里没有显示出来。endpoint_url指定测试REST
API地址,payload提供了测试当前模型需要输入的请求正文格式。
1 | { |
使用requests调用测试API,这里我们直接使用test_resp返回的测试payload,您也可以使用自定义的数据X,但是参数model_name和model_version必须使用上面输出的值。
1 | response = requests.post(test_resp['endpoint_url'], |
返回结果,不同于正式部署API,除了预测结果,测试API会同时返回标准控制台输出和标准错误输出内容,以方便用户碰到错误时,查看相关信息。
1 | # response.json() |
四、部署PySpark模型
训练一个PySpark分类模型:RandomForestClassifier。PySpark模型必须是一个PipelineModel,也就是说必须使用Pipeline来建立模型,哪怕只有一个Pipeline节点。
1 | from pyspark.sql import SparkSession |
发布PySpark模型
1 | publish_resp = client.publish(model, |
五、模型部署管理
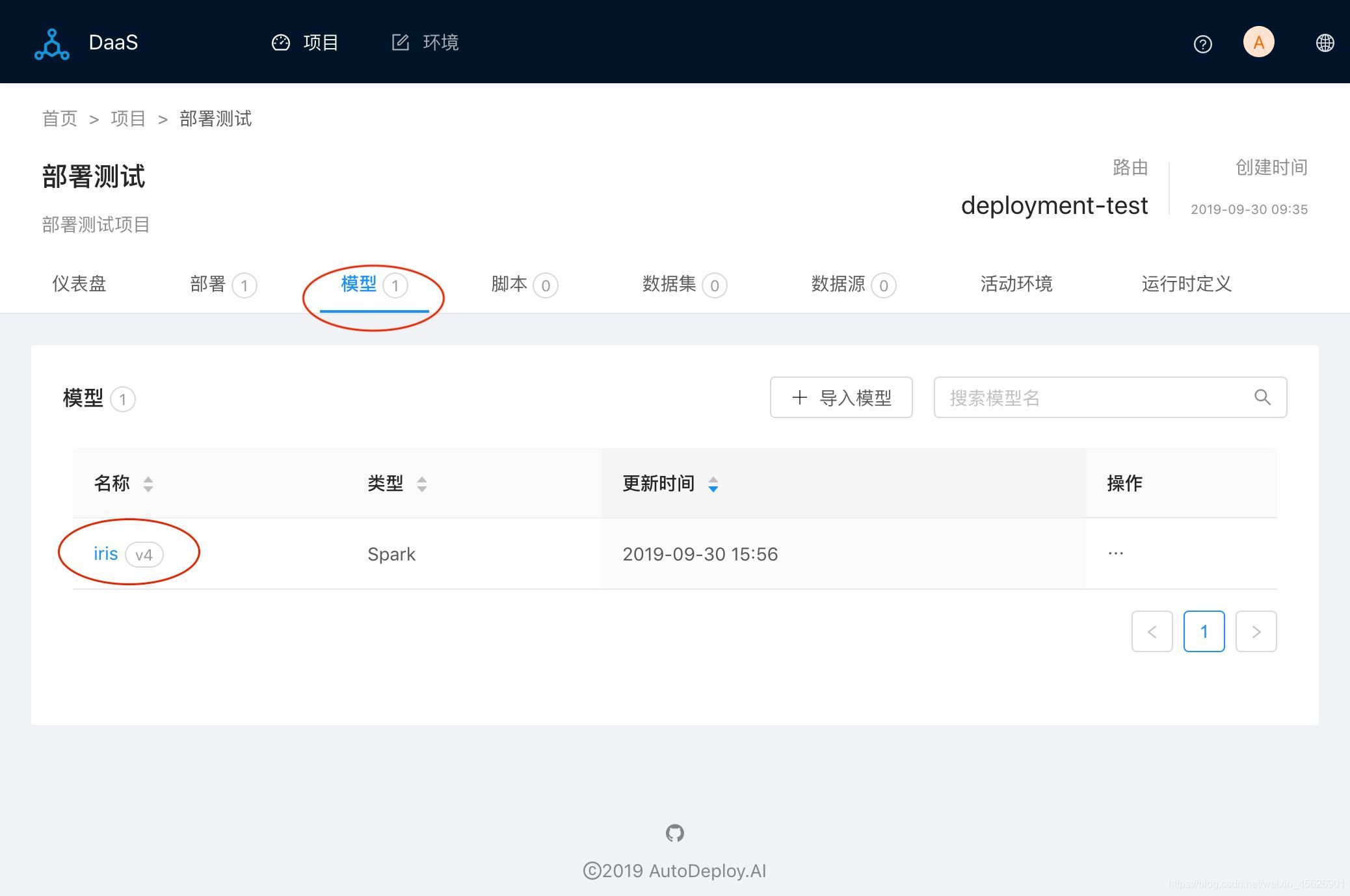
打开浏览器,登陆DaaS管理系统。进入项目部署测试,切换到模型标签页,有一个iris模型,最新版本是v4,类型是Spark即我们最后发布的模型。
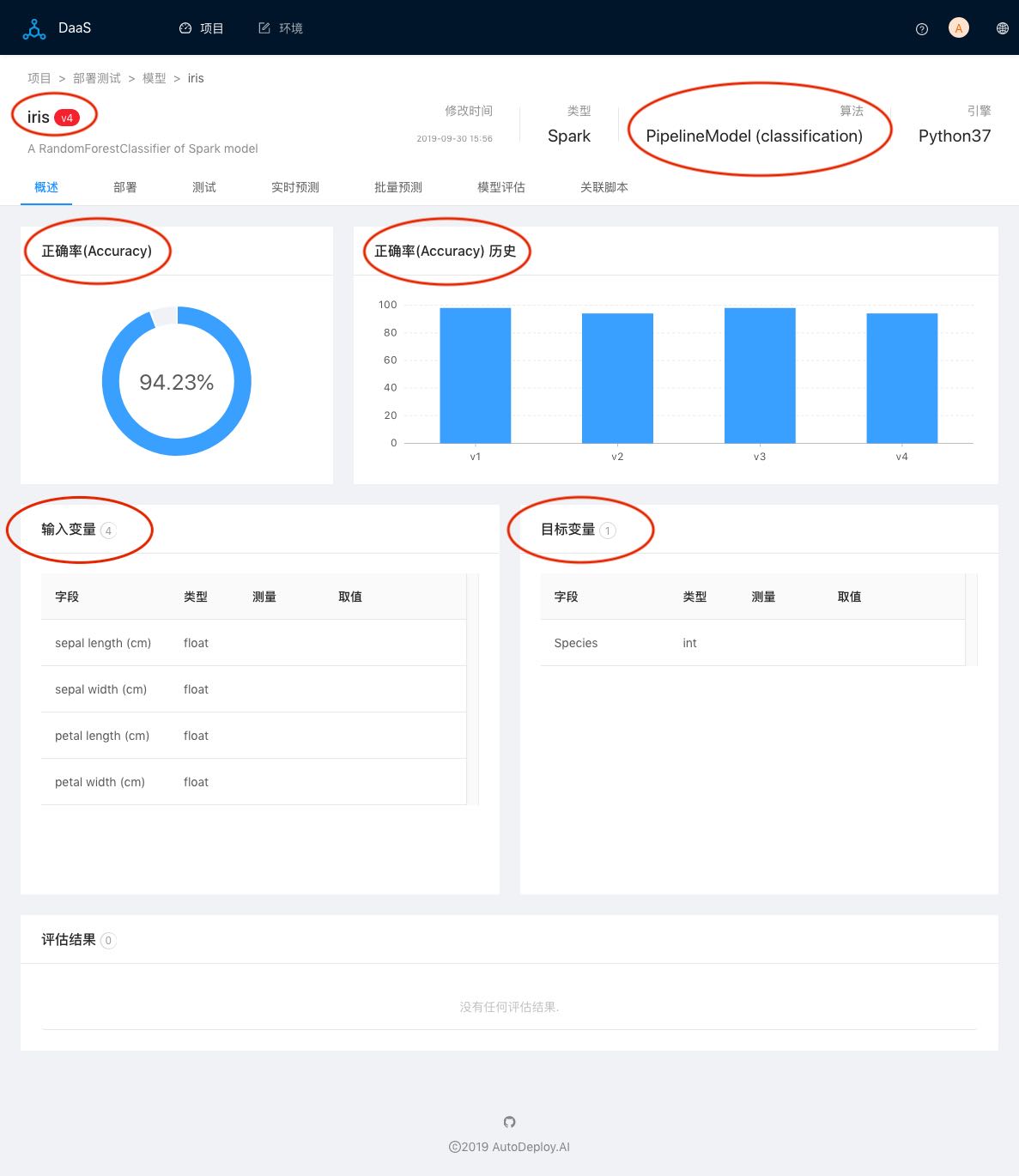
点击模型,进入模型主页(概述)。当前v4是一个Spark
Pipeline模型,正确率是94.23%,并且显示了iris不同版本正确率历史图。下面罗列了模型的输入和输出变量,以及评估结果,当前为空,因为还没有在DaaS中执行任何的模型评估任务。
点击v4,可以自由切换到其他版本。比如,切换到v1。

v1版本是一个Scikit-learn
SVM分类模型,正确率是98.00%。其他信息与v4类似。

切换到模型部署标签页,有一个我们刚才创建的部署iris-svc,鼠标移动到操作菜单,选择修改设置。可以看到,当前部署服务关联的是模型v1,就是我们刚才通过deploy函数部署的iris第一个版本Scikit-learn模型。选择最新的v4,点击命令保存并且重新部署,该部署就会切换到v4版本。
参考文献
- DaaS-Client、Sklearn、XGBoost、LightGBM、和PySpark_关注 AI/ML 模型上线、模型部署-程序员宅基地_
- DaaS-Client:https://github.com/autodeployai/daas-client
- 3万字长文 PySpark入门级学习教程,框架思维:https://zhuanlan.zhihu.com/p/395431025