流量反作弊(2)阿里妈妈-“广告主套利”风控技术分享
阿里妈妈-“广告主套利”风控技术分享
一、背景介绍
1.1 套利的影响
由于平台的有效总曝光有限,当套利广告主占据了高质量位置后,真实点击率和成交率低于模型预期,平台产生的总点击、总成交就会相应减少,从而导致该资源位的收入降低。这里我们统一使用千次展现收益(Revenue Per Mile,以下简称:RPM)来代表地价。即套利会在一定程度上使对应位置的RPM降低。
由于现阶段ctr、cvr预估模型有在线更新机制,从长周期来看是具备自愈能力的。但模型的更新有一段时间延迟,在每个模型更新的空窗期内,广告主不会恰好都补单补量至模型的预期水平。最终就导致了模型不断被欺骗又修复的过程。如下图所示。

因此,在与排序模型的博弈中,广告主周期性地实现着套利。随着online模型更新的时效性提升,套利空间在不断被压缩。也导致广告主更加倾向于高频、低程度地进行操作,识别难度进一步增大。
1.2 困难与挑战
由于作弊手法千变万化、真实标签难以界定、作弊Ground-Truth未知,风控场景很难通过监督训练等手段获得通用解。具体到广告主套利上,我们还面临着一些其他的问题。
1.2.1 众包人工流量的识别
相比于以往的无效流量甄别,众包人工流量往往更加贴近平常用户的行为。难度远超以往的爬虫、机械性攻击。高并发的广告场景,对识别的精度和召回,要求都非常高。而且即使是刷手,也会产出正常的流量。
如何精细化区分刷手的每次行为以及是否是受雇佣的,是极具挑战的一个课题。
1.2.2 精度难评价
由于众包人工流量会有一定比例的成交,不符合0转化假设。高效评价流量识别模型的精度和召回,是很困难的。此外,套利广告主检测本身也需要找到合适的假设,没有客观高效的评价方式,难以指导模型迭代。
1.2.3 区分主动与被动
存在任务流量的广告主,不仅是主动套利的,还有一部分是被其他广告主雇佣的刷手误伤、或者受到人工攻击消耗的。如何无监督、高精度、高召回、鲁棒地挖掘广告主的主动性,也是我们需要重点关注的。
二、方案概览
在正式开始介绍方案之前,我们针对1.3节的问题,分别介绍一下思路。为了解决1.3中提到的3个问题,我们针对广告主套利开发了一套同样集感知、洞察、处置、评价于一体的检测框架,其架构图如下图所示。框架理念可以参考这篇文章:《阿里妈妈流量反作弊算法实践》。
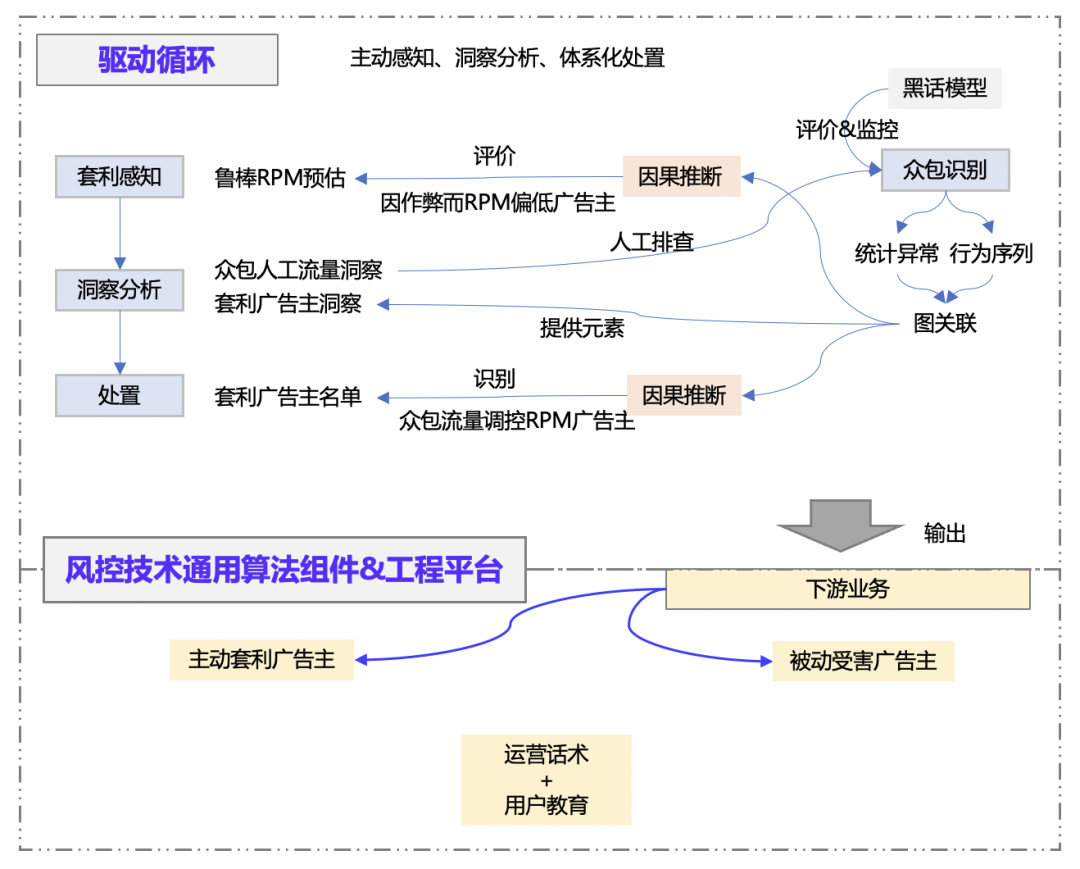
- 众包流量识别,分别由统计基线、行为序列、图关系3个模型一起召回,并使用黑话模型的产出评价标准,指导模型迭代;
- 感知部分,通过对RPM的鲁棒预估,计算广告主实际产生的RPM与平台预期的diff,从而召回RPM偏低的广告主;
- 通过洞察分析平台对列表中的实例进行分析,获取新模式认知的同时进行标注作为验证样本;
- 将认知抽象为策略或模型(当前为双模型因果推断),产出了套利广告主名单用于区分“主动”与“被动”,最后在下游中进行分类处置;
三、众包流量识别
在介绍感知、洞察、处置体系之前,我们首先对挖掘套利广告主的基础能力进行介绍——众包人工流量识别。该流量不满足0成交转化,模型的迭代和监控保障,也显然不能依赖低效的人工抽检。首先需要寻找一种可以批量校验、又和处置严格正交的评价方法。整体方案如下图所示。

3.1 黑话模型
考虑到直通车场景下,刷手需要高频地进行搜索,从而定位到自己的任务目标,不可能所有的内容都手敲。风控工程团队基于淘宝的搜索记录,对历史文本信息进行了系统地整合,使得黑话凝聚在标准化的文本库中。
3.1.1 特性
黑搜索的文本信息采集,受设备型号、手滑粘贴、误点搜索的影响,导致产出上并不稳定,所以没有直接用于召回。但同设备类型、应用、天维度同比是有意义的,可以作为精度和召回的评价指标。因此,我们构造了和众包流量构成强相关、但召回有限的黑话模型。
典型的黑话如下所示:
- "3️⃣看图👆拍苐一个,π下多少仮溃"
根据我们的分析显示,黑话具有以下特点:1)文字语序混乱;2)拼音、中、英文混输;3)表情、形近字替代;4)快速迭代、分析低效。这涉及到多种语义的还原,并且新的变种不断产生。基于文本出发的黑话模型开发非常困难。
3.1.2 用户维度、关键词与树
综合考虑各个方案的性价比后,我们尝试不完全依赖文本,而是从用户出发,2段式、半监督地召回黑话。
- 首先构造用户维度的处罚特征,无监督的召回候选人群集;
- 再以变换后的关键词为目标,天维度更新Cart回归树模型,选择额外80%召回的动态阈值,得到离线样本库;
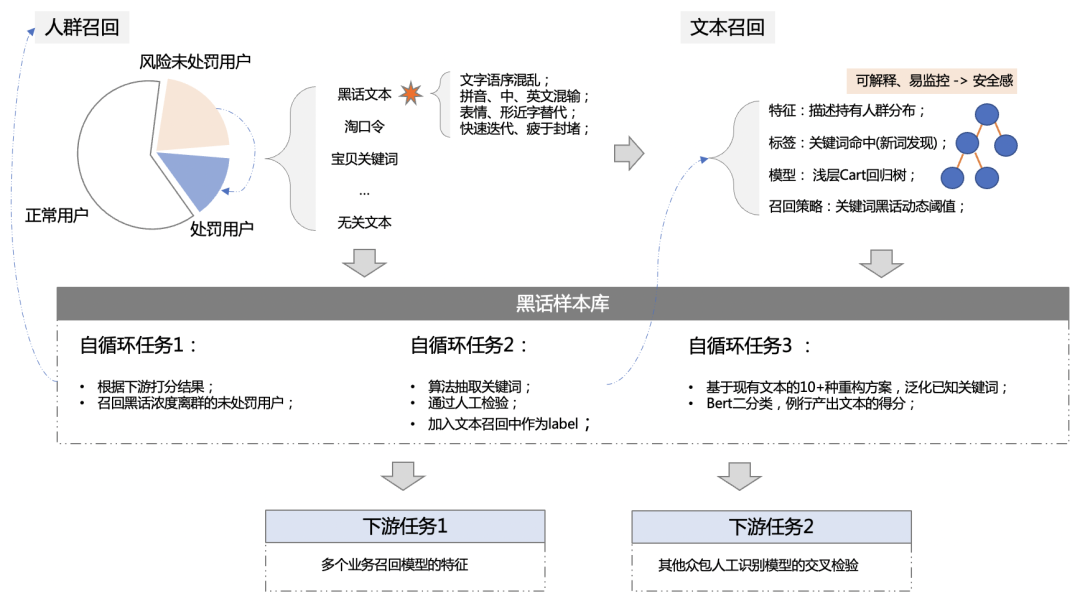
3.1.3 Bert提效
我们基于黑话样本库与大盘可信白样本,训练了基于Bert的2分类模型,用于对全量文本进行打分,从而减轻黑话样本库覆盖度不足的影响。使用召回人群多日黑话得分均值,来作为众包流量识别的精度指数,指导模型快速迭代,并持续以黑话精度作为模型的监控指标。
3.2 统计基线
众包人工流量虽然更难以识别,但是我们始终相信黑灰产用户是不可能完美隐藏的。我们从用户行为角度设计了一系列的异常检测方案。首先调研了黑灰产平台。发现用户需要通过一系列行为来完成任务的交付(考虑到攻防属性,暂不透出具体行为)。据此我们构造了本质、鲁棒性的统计特征,结合统计异常检测模型,产出了套利识别的基线。在《阿里妈妈流量反作弊算法实践》中介绍过,本质特征更有助于挖掘异常;如用“偏离对应人群的分布的程度”,代替“绝对数量”。
由于统计特征的粒度偏粗,导致我们并不能区分刷手当天的哪部分流量属于众包,哪部分属于正常流量。所以还需要更加精细化的识别能力建设。
3.3 行为序列
近期我们一直在尝试,使用更为细粒度的原始行为序列、良好的序列设计、以及合理的辅助任务,训练大规模无监督预训练模型。Zero-shot在下游进行应用,实现精细化地捕捉众包流量特点。当前行为序列研究的整体框架如下图所示。

3.3.1 序列信息
首先是通用的行为选择。为了更好地适用于大多数场景,我们只选择了搜索和点击两个行为,并辅以行为的属性与时间信息,共同组成行为序列。
为了方便刻画行为模式,我们使用下划线拼接行为和属性,构造类似于NLP中单词概念的行为元素,形式为:()()()_()。例如:clk_true_3_2 表示为 一次点击 & 是广告点击 & 商品属性为编号3 & 距离上一次行为时间间隔属于分箱编号2。
由于刷手需要接单大量的任务,产品类型、任务目的可能各不相同。通过合理的session划分,将不同的基础行为进行聚合,可以使信息更加凝聚。
结合搜索广告的特点,我们限制一个session必须以搜索开始,时间间隔在一定范围内都同属于一个session。
3.3.2 辅助任务设计
为了使模型学习到session排列的模式,我们使用Transformer结构 + Cut-paste任务,对序列整体进行表示。
Cut-paste算法是用于图像异常检测的一种辅助任务。通过对原始图片进行随机地局部剪裁,再随机粘贴至新的位置,原位置以黑色阴影覆盖(向量值均为0),从而获得大量的负样本,并以大量的数据增强产生正样本。然后通过原图与新图的二分类任务,促使模型学习到剪裁边缘的连续性。算法内容详见[1]。
类似地,根据刷手行为特点,对序列进行Cut-paste衍生,得到大量的样本用于二分类任务,从而得到完整序列表示。最终的预训练网络结构如下所示。

3.3.3 异常检测
根据序列表示的结果,我们得到了N维的Embedding向量:
- 将序列Embedding与COPOD模型结合,产出Embedding每个维度偏离分布的异常分(1);
- 固定基础行为的Embedding层权重,二次训练Seq2Seq模型,将重构误差产出异常分(2);
将2个方案计算的异常分结合,得到下游任务的打分。
3.4 图关联挖掘
截止目前,我们通过统计基线 + 行为序列对众包人工流量进行了识别。在阿里妈妈广告场景下,这些流量会在受害者/套利者维度上呈现出聚集。且因为模型的评估依赖于人工抽检,为了保证精度符合预期,显然单体识别模型的精度与召回都会受限。
因此我们增加了基于图关联的召回。以统计基线为基础节点,用行为序列结果剪枝,最终通过半监督的GAT网络对行为稀疏、但访问宝贝和基础节点重合度高的人工众包流量进行扩召回。

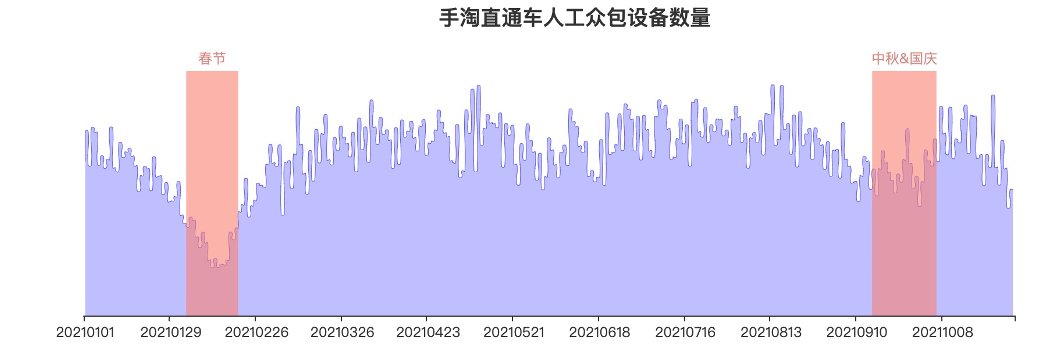
下图是2021年至今为止,最新挖掘的每日人工众包的设备数量趋势(具体数字已隐藏)。除大型节日外外,流量基本趋于稳定。相比于原始统计基线,组合模型可以精细定位到刷手与宝贝的对应关系,目前已额外新增30%的广告点击召回。
四、套利感知
为了建立内部自驱循环的异常检测框架,感知系统是必备的。在《阿里妈妈流量反作弊算法实践》文章中我们介绍过:感知重召回,其理念是召回一切认知之外的异常。从作弊的结果(果性)出发,才能召回受害者可感知的全部流量。
在广告主套利场景下,受害者是平台。但广告主的手法各不相同,从结果上看,未必会成功。虽然都需要处置,但在感知角度,我们更关注那些成功套利的案例。因此,我们从RPM低于平台预期的广告主的流量出发,召回套利成功流量的超集。
除了作为感知手段以外,估准RPM才能计算出该问题究竟为平台带来了多大影响。而且先找到一批RPM低于预期的广告主,才能用于最终,套利广告主名单的精度、召回评价。