Pytorch(4)DataLoader
[PyTorch 学习笔记] DataLoader 与 DataSet
人民币 二分类
实现 1 元人民币和 100 元人民币的图片二分类。前面讲过 PyTorch 的五大模块:数据、模型、损失函数、优化器和迭代训练。
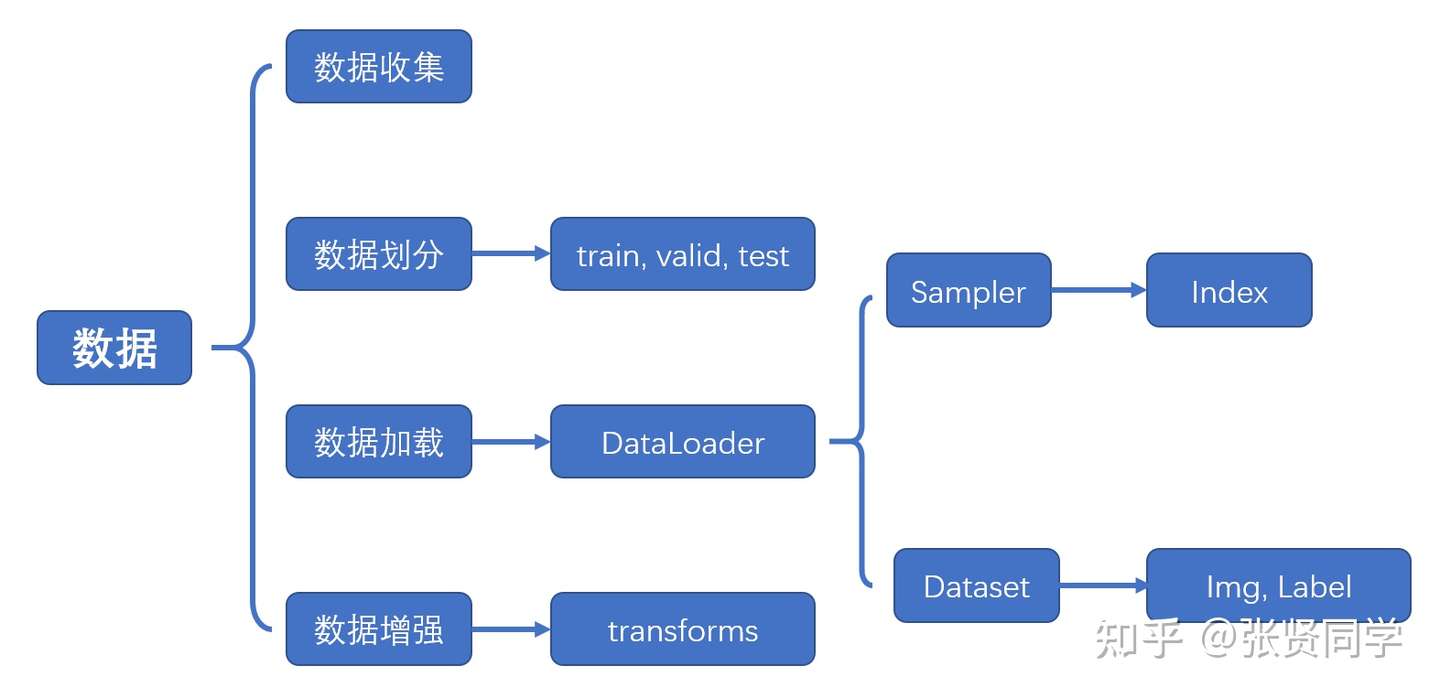
数据模块又可以细分为 4 个部分:
- 数据收集:样本和标签。
- 数据划分:训练集、验证集和测试集
- 数据读取:对应于 PyTorch 的 DataLoader。其中 DataLoader 包括 Sampler 和 DataSet。Sampler 的功能是生成索引, DataSet 是根据生成的索引读取样本以及标签。
- 数据预处理:对应于 PyTorch 的 transforms
一、DataLoader 与 DataSet
1.1 torch.utils.data.DataLoader()
1 | torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None) |
功能:构建可迭代的数据装载器
- dataset: Dataset 类,决定数据从哪里读取以及如何读取
- batchsize: 批大小
- num_works:num_works: 是否多进程读取数据
- sheuffle: 每个 epoch 是否乱序
- drop_last: 当样本数不能被 batchsize 整除时,是否舍弃最后一批数据
1.2 Epoch, Iteration, Batchsize
- Epoch: 所有训练样本都已经输入到模型中,称为一个 Epoch
- Iteration: 一批样本输入到模型中,称为一个 Iteration
- Batchsize: 批大小,决定一个 iteration 有多少样本,也决定了一个 Epoch 有多少个 Iteration
1.3 torch.utils.data.Dataset
功能:Dataset 是抽象类,所有自定义的 Dataset
都需要继承该类,并且重写__getitem()__方法和__len__()方法
。__getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。__len__()方法是返回所有样本的数量。
数据读取包含 3 个方面:
- 读取哪些数据:每个 Iteration 读取一个 Batchsize 大小的数据,每个 Iteration 应该读取哪些数据。
- 从哪里读取数据:如何找到硬盘中的数据,应该在哪里设置文件路径参数
- 如何读取数据:不同的文件需要使用不同的读取方法和库。
1 | class RMBDataset(Dataset): |
- 图片的路径和对应的标签:实现读取数据的
Dataset,编写一个
get_img_info()方法,读取每一个图片的路径和对应的标签,组成一个元组,再把所有的元组作为 list 存放到self.data_info变量中,这里需要注意的是标签需要映射到 0 开始的整数:rmb_label = {"1": 0, "100": 1}。 - 然后在
Dataset的初始化函数中调用get_img_info()方法。 - 索引:然后在
__getitem__()方法中根据index读取self.data_info中路径对应的数据,并在这里做 transform 操作,返回的是样本和标签。 - 长度:在
__len__()方法中返回self.data_info的长度,即为所有样本的数量。
在train_lenet.py中,分 5 步构建模型。
- 首先定义训练集、验证集、测试集的路径,定义训练集和测试集的
transforms。然后构建训练集和验证集的RMBDataset对象,把对应的路径和transforms传进去。再构建DataLoder,设置 batch_size,其中训练集设置shuffle=True,表示每个 Epoch 都打乱样本。
1 | # 构建MyDataset实例train_data = RMBDataset(data_dir=train_dir, transform=train_transform)valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform) |
- 第 2 步构建模型,这里采用经典的 Lenet 图片分类网络。
1 | net = LeNet(classes=2) |
- 第 3 步设置损失函数,这里使用交叉熵损失函数。
1 | criterion = nn.CrossEntropyLoss() |
- 第 4 步设置优化器。这里采用 SGD 优化器。
1 | optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器 |
第 5 步迭代训练模型,在每一个 epoch 里面,需要遍历 train_loader 取出数据,每次取得数据是一个 batchsize 大小。这里又分为 4 步。
前向传播
反向传播求导
使用
optimizer更新权重统计训练情况。每一个 epoch 完成时都需要使用
scheduler更新学习率,和计算验证集的准确率、loss。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
# 遍历 train_loader 取数据
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# 每个 epoch 计算验证集得准确率和loss
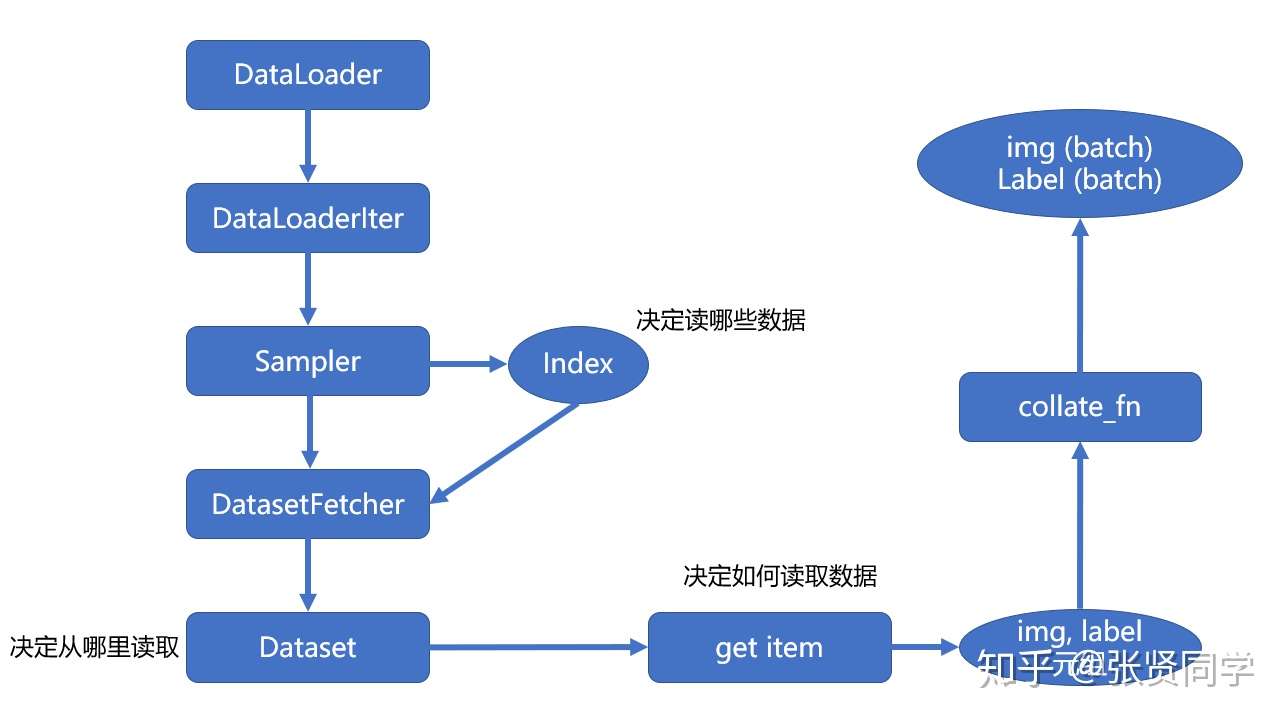
我们可以看到每个 iteration,我们是从train_loader中取出数据的。
1 | def __iter__(self): |
这里我们没有设置多进程,会执行_SingleProcessDataLoaderIter的方法。我们以_SingleProcessDataLoaderIter为例。在_SingleProcessDataLoaderIter里只有一个方法_next_data(),如下:
==1.4
_SingleProcessDataLoaderIter单进程==
1 | def _next_data(self): |
在该方法中,self._next_index()是获取一个 batchsize 大小的 index 列表,代码如下:
1 | def _next_index(self): |
其中调用的sample类的__iter__()方法返回
batch_size 大小的随机 index 列表。
1 | def __iter__(self): |
然后再返回看
dataloader的_next_data()方法,在第二行中调用了self._dataset_fetcher.fetch(index)获取数据。这里会调用_MapDatasetFetcher中的fetch()函数:
1 | def fetch(self, possibly_batched_index): |
这里调用了self.dataset[idx],这个函数会调用dataset.__getitem__()方法获取具体的数据,所以__getitem__()方法是我们必须实现的。我们拿到的data是一个
list,每个元素是一个 tuple,每个 tuple
包括样本和标签。所以最后要使用self.collate_fn(data)把
data 转换为两个 list,第一个 元素 是样本的 batch 形式,形状为
[16, 3, 32, 32] (16 是 batch size,[3, 32, 32]
是图片像素);第二个元素是标签的 batch 形式,形状为 [16]。
所以在代码中,我们使用inputs, labels = data来接收数据。
==PyTorch 单进程数据读取流程图==
==1.5 _MultiProcessingDataLoaderIter(self)多进程==
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader:https://www.cnblogs.com/rossiXYZ/p/15150504.html
总体逻辑如下:
- 主进程把需要获取的数据 index 放入index_queue。
- 子进程从 index_queue 之中读取 index,进行数据读取,然后把读取数据的index放入worker_result_queue。
- 主进程的 pin_memory_thread 会从 worker_result_queue 读取数据index,依据这个index进行读取数据,进行处理,把结果放入 data_queue。
