安全场景(2)恶意加密流量检测*
基于机器学习的恶意加密流量检测
[1] Anderson B, McGrew D. Identifying encrypted malware traffic with contextual flow data[C]//Proceedings of the 2016 ACM workshop on artificial intelligence and security. 2016: 35-46.

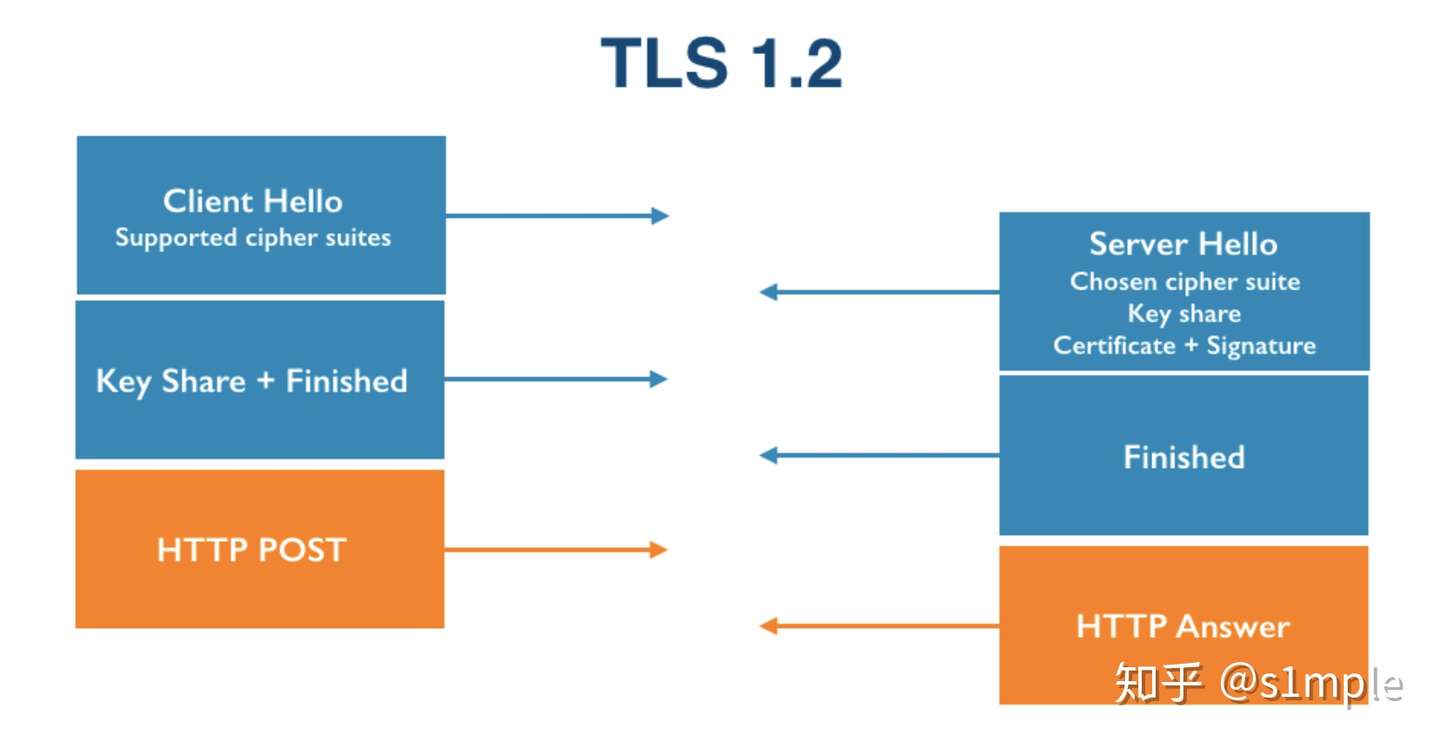
在进行TLS握手时,会进行如下几个步骤:
- Client Hello,客户端提供支持的加密套件数组(cipher suites);
- Server Hello,由服务器端选择一个加密套件,传回服务器端公钥,并进行认证和签名授权(Certificate + Signature);
- 客户端传回客户端公钥(Client Key Exchange),客户端确立连接;
- 服务器端确立连接,开始 HTTP 通信。
一、特征提取
1.1 可观察的数据元统计特征
- 传统流数据 (Flow Meta)
- 流入和流出的字节数和数据包数
- 源端口和目的端口
- 字节分布 (BD, Byte Distribution)
- 数据包有效负载中遇到的每个字节值的计数
- 提供了大量数据编码和数据填充的信息
- 字节分布概率 ≈ 字节分布计数 / 分组有效载荷的总字节数
- 特征表示:1×256维字节分布概率序列
- 分组长度和分组到达间隔时间的序列 (SPLT, Sequence of
Packets Length and Times)
- ==使用马尔可夫链模型建模==
1.2 未加密的TLS头部信息特征

TLS/SSL协议 过程
- 两层子协议:握手协议和记录协议
- 握手协议特点
- 加密明文但不加密握手过程
- 有多个版本但握手参数不变
- Client Hello
- 列出的密码套件列表(Cipher Suites)
- 密钥交换算法、加密算法
- 报文认证消息码(MAC)算法
- 支持的扩展列表(Extensions)
- 提供额外功能或设定
- 列出的密码套件列表(Cipher Suites)
- Server Hello:选定的密码套件和TLS扩展
- Certificate:服务器签发的证书信息
- Client Key Exchange:使用的密钥交换算法参数

1.3 上下文数据
- DNS上下文流
- 基于目标IP地址与TLS相关的DNS响应
- 域名长度
- DNS响应返回的IP地址数
- DNS TTL值
- 域名在Alexa榜的排名
- 补充了加密流中可能缺失的信息
- 基于目标IP地址与TLS相关的DNS响应
- HTTP上下文流
- 在TLS流5min窗口内的相同源IP地址的所有HTTP流
- 恶意软件可能利用HTTP的头部字段来发起恶意活动
- Content-Type、Server、Code
二、工业落地
然而,AI技术如没有得到有效运用,也无法在实战中检测到加密的威胁行为。例如无监督学习可以定位未知威胁,但精准度待提升;有监督学习精确度高,却无法覆盖未知威胁。
2.1 如何在实战中精准识别加密流量攻击?
深信服安全团队经过7000+用户实践发现,只有将无监督学习和有监督学习智能化结合,才能最大限度提升加密流量攻击的识别率。
2.2 有监督学习精准识别已知加密流量
有监督机器学习通过将已知、带标签的行为数据输入系统,学习分析数据行为,并根据数据标签来检测、识别特定的高级威胁。深信服NDR(全流量高级威胁检测系统)应用AI模型,基于有监督机器学习抓取所有上下行流量,提取1000+维度特征,同时增加了模型训练算法LightGBM学习特征的权重,对已知高级威胁的检测更为精准。传统的检测方式基于一个模型检测多个场景,不同场景的特征不尽相同,因此误报率很高。 深信服NDR基于AI模型有监督学习进行场景化建模,一个模型对应一个场景,根据场景特征进行针对性检测,模型检测精准率能够达到98%。
2.3 无监督学习提前发现未知加密流量
无监督的机器学习覆盖了聚类、神经网络等方法,不依赖任何标签值,通过自主学习,挖掘数据内在特征,实现自动化全面检测,更合理地利用资源,提升效率。
深信服NDR基于AI模型无监督学习方法,通过聚类学习、特征映射等智能分析技术建立设备加密流量动态行为基线,筛选出异常的、可疑的行为,同时结合行为聚合与关联分析,检测出未知威胁的早期迹象,最大程度地实现自动化检测,可以快速检测出如下异常,帮助网络安全团队主动预防威胁:
- 异常的网络设备JA3
- 异常的访问时间和访问频率
- 异常的上下行数据包比率
- 异常的证书签发机构
以常见的“服务器权限获取手法webshell加密通信”为例,攻击者通过渗透系统或网络安装webshell ,在应用服务器上执行敏感命令、窃取数据、植入病毒,危害极大。webshell具有很强的隐蔽性,传统的、基于单向数据流的流量检测方案,无法实时更新数据,难以有效检测webshell。
深信服NDR基于AI模型无监督学习的 孤立森林异常点检测算法,可以构建特征向量,精准检测“孤立离群”的webshell访问行为,具有更高检出率,更低误报率。除了webshell加密通信场景外,深信服NDR同样支持隧道检测、CS漏洞、加密挖矿、加密反弹shell等威胁检测,覆盖多种加密威胁场景。
三、算法比赛总结
恶意加密流量(1)DataCon2020-恶意加密流量检测.md
恶意加密流量(2)Datacon2021恶意加密流量检测.md
#### 流量处理的工具
#### zeek:https://github.com/zeek/zeek
Zeek Analysis Tools (ZAT):
#### joy:
2.1 数据包级
(1)长度分布
根据Cisco的研究【17】,恶意软件和普通软件在正向流和反向流中的数据包长度分布不同。 例如,当我们使用谷歌搜索时,客户端向服务器发送少量数据包,然后服务器返回大量数据包。然而,恶意软件的作用恰恰相反:恶意软件通常让客户端将数据传输到服务器,然后服务器定期返回调度命令。无论是否加密,数据包长度始终可见,因此它适合作为一种功能。我们将数据包长度和方向编码为一维独立特征。我们推测,感染恶意软件的客户端和服务器之间的一些控制消息的长度总是相似且频繁的,这具有很好的区分程度。我们考虑每个可能的数据包长度和方向元组。由于Internet上的最大传输单元(MTU)是1500字节,并且数据包的方向有两个发送或接收方向,因此我们的长度分布特征是3000维。为了提取这些特征,我们计算具有不同长度的所有数据包的数量,并进行规范化以确保概率分布。我们使用随机森林(RF)算法来处理这些特征。因为它能更好地处理高维特征,并且具有可解释性。
(2)长度序列
第二部分,在不使用序列信息的情况下,我们只使用了数据包长度的统计特征,这可能会在时间上丢失一些信息,因此我们提取了数据包长度序列。我们在每个客户端的双向上取前1000个数据包长度,并将其放入TextCNN算法中以提取局部序列关系。因为该算法运行速度快,精度高。文本数据的卷积神经网络TextCNN【22】是一种用于句子分类任务的有用的深度学习算法。在这种情况下,我们将每个数据包的长度视为一个单词,长度序列相当于一个句子。
(3)服务器IP
在我们的数据集中,服务器IP地址是一个重要的标识符。我们假设,在同一地区,如果客户端感染了相同的恶意软件,则可能会导致其访问相同的服务器IP地址。因此,我们还考虑了对服务器IP地址的访问。值1或0表示是否访问了特定的服务器IP地址(一个热编码)。我们使用朴素贝叶斯(NB)算法来处理这些特征。由于朴素贝叶斯算法是一种非参数算法,其本质是寻找特征和标签之间的关系。因此,它可以被视为一个黑名单。
(4)词频分类器
X509证书在Internet上广泛使用。它们用于验证实体之间的信任。证书颁发机构通常将X509证书链接在一起。如图2所示。[23],X509证书提供URL、组织、签名等信息。我们从培训集中每个客户端的TLS流中提取X509证书链,并获取证书中主题和颁发者中包含的单词。我们将所有单词组合在一起,并将客户的流量视为由这些单词组成的句子。与B部分类似,我们计算每个单词的数量并将其用作特征。0我们使用朴素贝叶斯(NB)算法来处理这些特征。如果测试集样本证书中的所有单词从未出现在训练集中,我们将直接推断它是恶意的。因为训练集包含最流行的域名。

==(5)TCP状态马尔可夫==
我们发现恶意流量和正常流量之间TCP连接状态的分布是不同的。表一说明了可能的TCP连接状态[24]。我们按照流出现的时间对其进行排序,然后使用马尔可夫随机场转移矩阵(MRFTM)对该特征进行编码。MRFTM在建模连接状态序列时很有用。MRFTM[i,j]中的每个条目统计第i个和第j个状态之间的转换次数。最后,我们对MRFTM的行进行规范化,以确保适当的马尔可夫链。然后我们将其重塑为一维向量,也就是说,我们使用MRFTM的条目作为特征。我们使用随机森林(RF)算法来处理这些特征。
2.2 会话流级
(6)会话流量统计
在加密流量中,上述5种分类器在主机级使用不同的特征提取方法和分类方法。此外,为了进一步提高准确率,防止恶意软件由于缺乏领域知识而欺骗分类器,我们还提取了TLS握手中的明文信息。在这个分类器中,我们首先考虑流级特征。我们仅选择TLS流,并分析每个流。一旦推断流是恶意的,就会推断相应的客户端被感染。我们对TCP和TLS协议进行了深入分析,提取了1000多个维度的流级特征,包括以下部分:
- TCP连接状态特性:如F部分所述,我们对每个流的TCP连接状态进行一次热编码。
- 统计特征:我们还提取常规统计特征,表II显示了相关特征名称和描述。

- 长度马尔可夫特征:数据包长度序列的操作类似于F部分中的TCP连接状态序列。长度值被离散为大小相等的容器。长度数据马尔可夫链有10个箱子,每个箱子150字节。假设一个1500字节的MTU,任何观察到的大小大于1350字节的数据包都被放入同一个bin中。
- TLS握手功能:我们发现客户端和服务器的TLS协议版本在恶意和良性TLS流之间有不同的分布,因此我们对客户端和服务器的TLS版本进行了一次热编码。此外,由于恶意软件可能使用旧的密码套件,我们在客户端和服务器上都对密码套件和扩展进行n-hot编码,即将所有密码套件和扩展扩展扩展为一维0向量,如果当前流使用某个密码套件或扩展,则相应的位置集值为1。
- TLS证书特性:我们发现,在恶意流中,很大一部分叶证书是自签名的,或者自签名证书出现在证书链中。恶意软件喜欢利用的自签名证书的成本很低。因此,我们分析从服务器发送的证书:证书链是否包含自签名证书、叶证书是否过期、证书版本、证书有效期、公钥长度、是否发生警报。同时,考虑到之前的词频分类器,我们发现一些词无法区分恶意和良性,因此我们还将流词频添加到流特征中。
2.3 主机级特征
(7)主机级荷载无关特征聚合 (流级统计信息)
单独的看每条流可能漏掉了流之间的关联行为即主机级别的行为,比如恶意软件在发出正常的访问谷歌流量后可能就要开始进行恶意传输。再比如,有少量正常流也会出现自 签名,如果我们单独看流,可能就会误判,但是如果我们基于主机提取特征发现同一 IP 下有多条流都是自签名,则我们就会有很大的信心认为这是恶意的。因此,我们将上一小节中流级别 的特征进行聚合,并以流为基本单位提取主机级别特征。
主机级特征聚合部分主要考虑了如下的特征:
- 总包个数,每条流的平均包个数,时间间隔、包长的均值,以及上一个小节中证书部分的相关特 征,即自签名流数量,过期流数量,有效期过长(比如 100年)的流数量及其均值。
- TLS 半连接 和无连接
2.4 上下文信息特征
(8)其他应用协议
HTTP头部信息
- Content-Type,正常流量 HTTP 头部信息汇总值多为
image/*,而恶意流量为text/*、text/html、charset=UTF-8或者text/html;charset=UTF-8。 - User-Agent
- Accept-Language
- Server
- HTTP响应码
DNS响应信息
- ==域名的长度==:正常流量的域名长度分布为均值为6或7的高斯分布(正态分布);而恶意流量的域名(FQDN全称域名)长度多为6(10)。
- ==数字字符及非字母数字(non-alphanumeric character)的字符占比==:正常流量的DNS响应中全称域名的数字字符的占比和非字母数字字符的占比要大。
- DNS解析出的IP数量:大多数恶意流量和正常流量只返回一个IP地址;其它情况,大部分正常流量返回2-8个IP地址,恶意流量返回4或者11个IP地址。
- TTL值:正常流量的TTL值一般为60、300、20、30;而恶意流量多为300,大约22%的DNS响应汇总TTL为100,而这在正常流量中很罕见。
- 域名是否收录在Alexa网站:恶意流量域名信息很少收录在Alexa top-1,000,000中,而正常流量域名多收录在其中。