深度学习(7)Seq2Seq
一、Seq2Seq
CS224n笔记[7]:整理了12小时,只为让你20分钟搞懂Seq2seq - 蝈蝈的文章 - 知乎 https://zhuanlan.zhihu.com/p/147310766
目录:
机器翻译
- 传统机器翻译,SMT
- 神经机器翻译,NMT
Seq2seq
- Seq2seq结构详解
- 为什么训练和预测时的Decoder不一样?
- Seq2seq的损失函数
- Decoding和Beam Search
总结
- NMT的优缺点
- 机器翻译的评价指标
1.1 seq2seq结构详解
![CS224n笔记[7]:整理了12小时,只为让你20分钟搞懂Seq2seq](https://lzy-picture.oss-cn-beijing.aliyuncs.com/img/202304182130235.png)
这张图,展示了在「训练时」,seq2seq内部的详细结构。
在Encoder端,我们将source文本的词序列先经过embedding层转化成向量,然后输入到一个RNN结构(可以是普通RNN,LSTM,GRU等等)中。另外,这里的RNN也可以是多层、双向的。经过了RNN的一系列计算,最终隐层的输入,就作为源文本整体的一个表示向量,称为「context vector」。
Decoder端的操作就稍微复杂一些了。首先,Decoder的输入是什么呢?Decoder的输入,训练和测试时是不一样的!
「在训练时,我们使用真实的目标文本,即“标准答案”作为输入」(注意第一步使用一个特殊的<start>字符,表示句子的开头)。每一步根据当前正确的输出词、上一步的隐状态来预测下一步的输出词。
下图则展示了在「预测时」,seq2seq的内部结构:
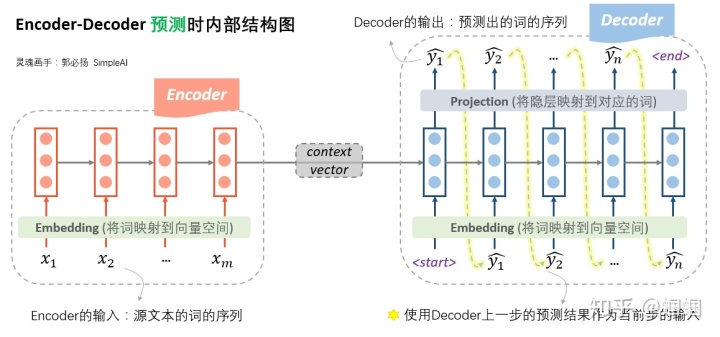
预测时,Encoder端没什么变化,在Decoder端,由于此时没有所谓的“真实输出”或“标准答案”了,所以只能「自产自销:每一步的预测结果,都送给下一步作为输入」,直至输出<end>就结束。如果你对我之前写的笔记很熟悉的话,会发现,「这时的Decoder就是一个语言模型」。由于这个语言模型是根据context
vector来进行文本的生成的,因此这种类型的语言模型,被称为“条件语言模型”:Conditional
LM。正因为如此,在训练过程中,我们可以使用一些预训练好的语言模型来对Decoder的参数进行初始化,从而加快迭代过程。
1.2 为什么训练和预测时的Decoder不一样?
很多人可能跟我一样,对此感到疑惑:为什么在训练的时候,不能直接使用这种语言模型的模式,使用上一步的预测来作为下一步的输入呢?

我们称这两种模式,根据标准答案来decode的方式为「teacher forcing」,而根据上一步的输出作为下一步输入的decode方式为「free running」。
其实,free running的模式真的不能在训练时使用吗?——当然是可以的!从理论上没有任何的问题,又不是不能跑。但是,在实践中人们发现,这样训练太南了。因为没有任何的引导,一开始会完全是瞎预测,正所谓“一步错,步步错”,而且越错越离谱,这样会导致训练时的累积损失太大(「误差爆炸」问题,exposure bias),训练起来就很费劲。这个时候,如果我们能够在每一步的预测时,让老师来指导一下,即提示一下上一个词的正确答案,decoder就可以快速步入正轨,训练过程也可以更快收敛。因此大家把这种方法称为teacher forcing。所以,这种操作的目的就是为了使得训练过程更容易。
所以,更好的办法,更常用的办法,是老师只给适量的引导,学生也积极学习。即我们设置一个概率p,每一步,以概率p靠自己上一步的输入来预测,以概率1-p根据老师的提示来预测,这种方法称为「计划采样」(scheduled sampling):
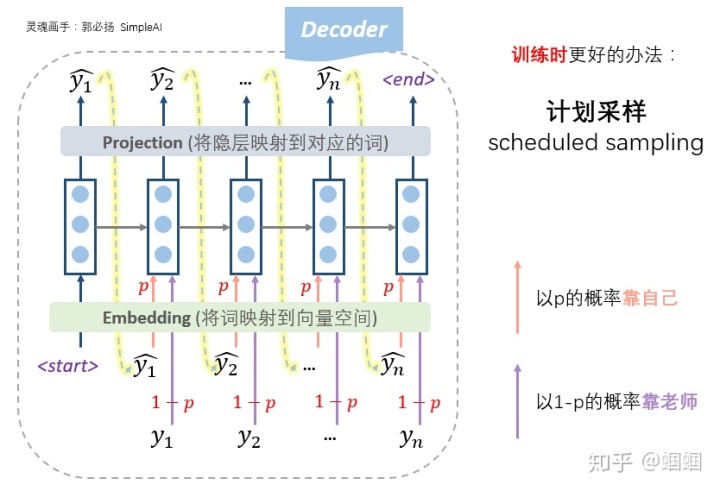
另外有一个小细节:在seq2seq的训练过程中,decoder即使遇到了<end>标识也不会结束,因为训练的时候并不是一个生成的过程
,我们需要等到“标准答案”都输入完才结束。
1.3 Seq2Seq的损失函数
在上面的图中,我们看到decoder的每一步产生隐状态后,会通过一个projection层映射到对应的词。那怎么去计算每一步的损失呢?实际上,这个projection层,通常是一个softmax神经网络层,假设词汇量是V,则会输出一个V维度的向量,每一维代表是某个词的概率。映射的过程就是把最大概率的那个词找出来作为预测出的词。
在计算损失的时候,我们使用交叉熵作为损失函数,所以我们要找出这个V维向量中,正确预测对应的词的那一维的概率大小,则这一步的损失就是它的负导数
,将每一步的损失求和,即得到总体的损失函数:
其中T代表Decoder有多少步,[EOS]代表‘end of sentence’这个特殊标记.
1.4 Decoding和Beam search
前面画的几个图展示的预测过程,其实就是最简单的decoding方式——「Greedy Decoding」,即每一步,都预测出概率最大的那个词,然后输入给下一步。
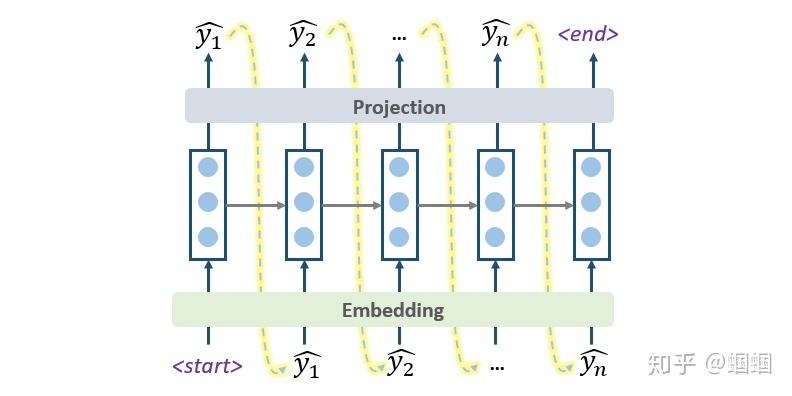
这种Greedy的方式,简单快速,但是既然叫“贪心”,肯定会有问题,那就是「每一步最优,不一定全局最优」,这种方式很可能“捡了芝麻,丢了西瓜”。
改进的方法,就是使用「Beam Search」方法:每一步,多选几个作为候选,最后综合考虑,选出最优的组合。
下面我们来具体看看Beam Search的操作步骤:
- 首先,我们需要设定一个候选集的大小beam size=k;
- 每一步的开始,我们从每个当前输入对应的所有可能输出,计算每一条路的“序列得分”;
- 保留“序列得分”最大的k个作为下一步的输入;
- 不断重复上述过程,直至结束,选择“序列得分”最大的那个序列作为最终结果。
这里的重点就在于这个“序列得分”的计算。
我们使用如下的score函数来定义「序列得分」:
这个score代表了当前到第t步的输出序列的一个综合得分,越高越好。其中类似于前面我们写的第t步的交叉熵损失的负数。所以这个score越到,就意味着到当前这一步为止,输出序列的累积损失越小。
再多描述不如一张图直观,我用下图描绘一个极简的案例(只有3个词的语料,k=2):

最后还有一个问题:由于会有多个分支,所以很有可能我们会遇到多个<end>标识,由于分支较多,如果等每一个分支都遇到<end>才停的话,可能耗时太久,因此一般我们会设定一些规则,比如已经走了T步,或者已经积累了N条已完成的句子,就终止beam
search过程。
在search结束之后,我们需要对已完成的N个序列做一个抉择,挑选出最好的那个,那不就是通过前面定义的score函数来比较吗?确实可以,但是如果直接使用score来挑选的话,会导致那些很短的句子更容易被选出。因为score函数的每一项都是负的,序列越长,score往往就越小。因此我们可以使用长度来对score函数进行细微的调整:对每个序列的得分,除以序列的长度。根据调整后的结果来选择best one。
Beam Search的使用,往往可以得到比Greedy Search更好的结果,道理很容易理解,高手下棋想三步,深思熟虑才能走得远。
1.5 NMT的优缺点
NMT相比于SMT,最大的优点当然就如前面所说的——简洁。我们不需要什么人工的特征工程,不需要各种复杂的前后组件,就是一个端到端的神经网络,整个结构一起进行优化。
另外,由于使用了深度学习的方法,我们可以引入很多语义特征,比如利用文本的相似度,利用文本内隐含的多层次特征,这些都是统计学方法没有的。
但是,没有什么东西是绝对好或绝对差的,NMT也有其不足。它的不足也是跟深度学习的黑箱本质息息相关。NMT的解释性差,难以调试,难以控制,我们谁也不敢保证遇到一个新的文本它会翻译出什么奇怪的玩意儿,所以NMT在重要场合使用是有明显风险的。
1.6 NMT的评价
机器翻译的效果如何评价呢?——「BLEU」指标。BLEU,全称是Bilingual Evaluation Understudy,它的主要思想是基于N-gram等特征来比较人工翻译和机器翻译结果的相似程度。