特征工程(6)Auto工具
一、AutoEDA 工具
盘点Kaggle中常见的AutoEDA工具库: https://zhuanlan.zhihu.com/p/444405236
4.1 Pandas Profiling
Pandas Profiling是款比较成熟的工具,可以直接传入DataFrame即可完成分析过程,将结果展示为HTML格式,同时分析功能也比较强大。
- 功能:字段类型分析、变量分布分析、相关性分析、缺失值分析、重复行分析
- 耗时:较少

4.2 AutoViz
AutoViz是款美观的数据分析工具,在进行可视化的同时将结果保存为图片格式。
- 功能:相关性分析、数值变量箱线图、数值变量分布图
- 耗时:较多

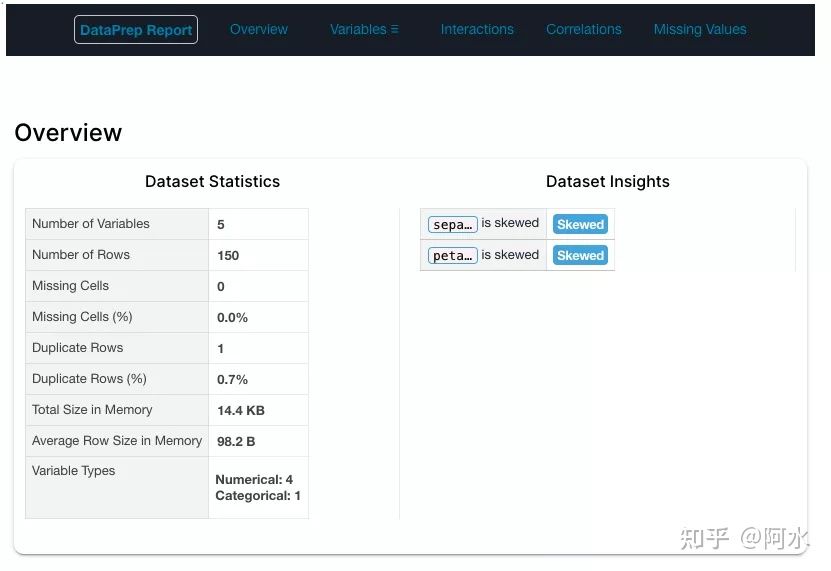
4.3 Dataprep
Dataprep是款比较灵活也比较强大的工具,也是笔者最喜欢的。它可以指定列进行分析,同时也可以在Notebook中进行交互式分析。
- 功能:字段类型分析、变量分布分析、相关性分析、缺失值分析、交互式分析。
- 耗时:较多
4.4 SweetViz
SweetViz是款强大的数据分析工具,可以很好的分析训练集和测试集,以及目标标签与特征之间的关系。
- 功能:数据集对比分析、字段类型分析、变量分布分析、目标变量分析
- 耗时:中等

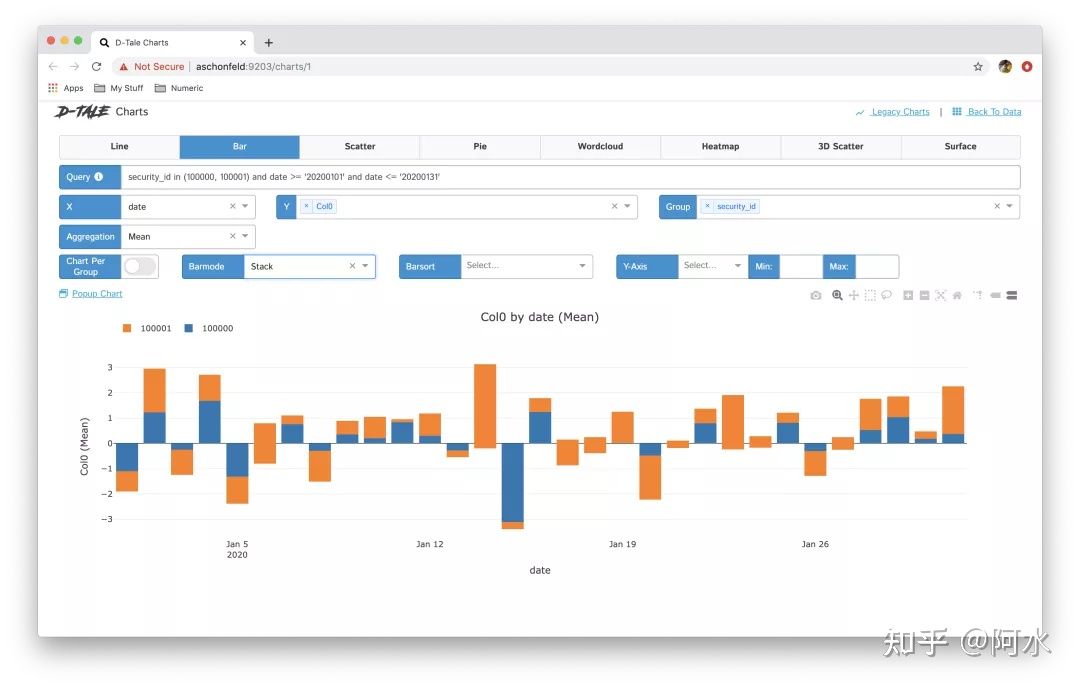
4.5 D-Tale
D-Tale是款功能最为强大的数据分析工具,对单变量的分析过程支持比较好。
- 功能:字段类型分析、变量分布分析、相关性分析、缺失值分析、交互式分析。
- 耗时:中等
二、警惕「特征工程」中的陷阱
- https://zhuanlan.zhihu.com/p/33651227
特征工程(Feature Engineering)是机器学习中的重要环节。在传统的项目中,百分之七十以上的时间都花在了预处理数据上(Data Preprocessing),其中特征工程消耗了很多时间。
一般来说, 特征工程涵盖的内容非常广泛, 包括从缺失值补全、特征选择、维度压缩, 到对输入数据的范围进行变 换 (Data Scaling) 等。举个简单的例子, 一个K-近邻算法的输入数据有两个特征 \(X_1, X_2\), 但 \(X_1\) 这个特征的 取值范围在 \([0,1]\) 而 \(X_2\) 的范围在 \([-1000,1000]\) 。不可避免的, K-近邻的结果取决于距离, 那么很容易被取值范 围大的特征, 也就是此处的 \(X_2\) 所“垄断”。在这种情况下, 把 \(X_1, X_2\) 的取值调整到可比较的范围上就成了必须。 常见的做法有归一化或者标准化, 此处不再赘述, 可以参考[1]。为了简化内容, 本文中的例子仅以归一化作为唯 一的特征工程。今天主要说的是: 特征工程中的面临的进退两难。
2.1 如何保证 训练集、测试集、预测数据 有相同的输入?
以刚才的例子为基础,我们把所有数据按照70:30的比例分为训练集和测试集,并打算使用K-近邻进行训练。那么一个令人困扰的问题是,对训练集的特征做归一化后,测试集的特征怎么办?这是一个非常关键的问题,因为训练集特征归一化后,测试集的特征范围可能就不同了,因此模型失效。一般有几种思路:
- 方法1:把训练集和测试集合在一起做归一化,这样特征范围就统一了。之后用训练集做训练,那测试集做测试。但很明显的,在训练模型时,不应该包括任何测试集的信息。这种做法会导致存在人为偏差的模型,不能用。
- 方法2:对训练集单独做归一化,之后对测试集单独做归一化。这种看法看似也可以,重点在于数据量以及数据的排列顺序。在数据量大且数据被充分打乱的前提下,这种做法是可行的。但换句话说,如果有这样的前提假设,那么方法1的结论也是可行的。
- 方法3:对训练集先做归一化,并保留其归一化参数(如最大、最小值),之后用训练集的归一化参数对测试集做处理。这种做法看似是可以的。但风险在于数据量有限的前提下,训练集的参数会导致测试集的结果异常,如产生极大或者极小的数值。
其实不难看出,从某种意义上说,三种做法是等价的。在数据量大且充分打乱的前提下,训练集和验证集有相同的分布假设,因此用任意一种其实差别不大。然而这样的假设过于乐观,且我们在真实情况下应该只有{训练集+1个测试数据},因此方法2是明显不行的。
方法1常常被认为是错误的操作,原因是在训练阶段引入了测试数据,这属于未知数据。即使仅仅引入了1个测试数据,如果取值非常极端,依然会导致输出范围有较大的波动。其次,如果对于每一个测试数据都需要用整个训练集来归一的话,那么运算开销会非常大。
那么似乎备选的只有方案3,即保留验证集上的归一化参数,并运用于测试集。这样的做法看似可以,但有不少风险:
- 不是每种特征工程都可以保存参数,很多特征工程是非常繁复的。
- 如果测试集数据和训练集数据有很大的差别,那么用测试集的参数会产生异常数据。
2.2 可能的解决方案
在模型评估阶段,如果我们假设拥有大量数据,且充分打乱其顺序。那么在划分训练集和测试集前,可以对整体数据进行统一的特征工程。不难看出,这和统计学的大数定理有异曲同工之妙。这种做法是最为高效的,需要的运算量最小。而将“测试数据”暴露给训练模型的风险也并不大,因为大数据量使得分布比较稳定,可以忽略。换个角度来看,当数据量非常大的时候,使用其他方法进行特征工程的开销会过大,不利于模型评估。因此,在模型评估阶段,如果符合以上假设,可以用这种方法(也就是上文的方法1)。但退一步说,如果满足这个条件,那么方法3也是等价的。
在预测阶段,每次假设我们只有1个测试点,那么最佳方案还是保存训练集上特征工程的参数或者模型,并直接用于未知数据的特征工程(也就是上文的方法3)。
但在预测阶段,一个一个数据的预测是非常昂贵的,我们一般会做“批处理”(batch operation)。换句话说,就是攒够一定量的预测数据后统一进行预测。在这种情况下,我们:
- 利用方法3,按照顺序对每个训练数据进行处理
- 利用方法1,风险在于(方法1)会影响训练数据且需要重新训模型
- 利用方法2,此时较为稳妥。在批的尺寸较大,且与训练数据分布相同(接近)时,效果应该与方法3一致,但效率可以得到提升
2.3 总结
这篇文章的重点是:“特征工程虽然重要,但极容易在使用中带来风险。”比如在训练时同时误用了测试数据进行特征工程,也叫做数据泄露(data leakage)。但数据泄露其实也是个伪命题,当数据量大且分布相同时,使用哪一种方法得到结果应该都近似等价,而更重要的是运行效率。分类讨论的话,方法1、2、3都有可能是适合的方法。
但我们依然希望能避免类似的风险,因此尽量避免不必要的特征工程,有以下建议:
- 选择对于特征学习能力强的模型,在数据量允许的情况下可以选择深度学习
- 避免不必要的特征工程,数据范围比较良好的情况下省略某些特征工程
- 优先选择对于特征工程要求低的模型,如xgboost等
三、业务角度看特征工程
前两天刷某知名社交软件的时候看到有人问特征工程现在还重要吗?觉得是个很有意思的事情。其实工业界能够支持的起大规模稀疏向量的场景大概并不是想象中的那么多,大多数场景面对极为稀疏的行为数据下都很难在ID层面得到很好的emb表达。在这个前提下,没有好的特征工程,其余的模型结构优化或者各种花里胡哨的模型结构都是纸上谈兵。真正被小场景捶打过的朋友,比如我,绝对会在一次又一次的生活毒打中明白,抛弃那些ppt上的高级多塔多注意力,直面特征工程的人生吧!
有竞赛经验的小伙伴都明白,一个强特能一飞冲天,一个灵机一动能直上top榜。但是,长久的可持续的特征工程决不能够靠简单的灵机一动来实现,特别是当手上有无数的芝麻大小的场景时,一个系统的特征工程思维就尤为重要了。本文将从以下几个方面来阐述特征工程中的方方面面。提前说明的是,一般的特征工程常用方法,例如one-hot,hash-encoding,分桶等等不会作为本文的重点,因为这是器的维度,文末有一篇非常全面的文章供参考,本文主要聚焦在术的维度,也就是怎么去思考和选用方法的层面。首先,我会给出一个特征工程树,这个属于一个主流版本,希望在屏蔽场景特殊性的情况下,给出一般场景的思考方法。接下来,我会介绍上文提到的特征树的细节,包括涉及到的具体特征例子。第三部分,则包括特征之间可能存在的相互作用和不同特征适合的模型类型。最后,我给出了一个具体场景的具体例子,并说明这个场景的一般性和特殊性,给出针对具体业务场景的特征工程思路。
此外,一个基础认知是,这里的特征是指输入模型的信息,包括偏置或者先验,这些特征的使用方式除了作为模型的输入,也可以通过其他的方式引入,例如样本工程或者损失函数,这个就不在本文讨论范围之内了。当然还是那句老话,个人的认知是有限的,欢迎有经验的小伙伴交流和指正。
3.1 基础特征树
不管是基于已有的模型迭代优化,又或者是从0到1构建一个场景的全部特征,都需要自己梳理一个完整的基础特征树。这是了解一个场景的开始。做这件事情我推荐的方法是先体验这个场景,然后分类列出所有可能影响你优化目标决策的因素以及优化目标的历史信息。
对于绝大多数业务来讲,基础的特征树都可以分为以下3大部分。
- 供给侧:对于大部分to c的互联网应用,供给侧都是item,可能是音乐,doc或者一条推送消息。
- 消费侧:有关用户的一切描述,其中比较特殊的是序列特征。
- 上下文:场景测的因素,包括特定的时刻,特定的展现形式等。
- 交叉特征:以上三个部分任意两部分或全部的交叉特征。