深度学习-NLP(1)词嵌入
nlp:word2vec/glove/fastText/elmo/GPT/bert
本文以QA形式对自然语言处理中的词向量进行总结:包含word2vec/glove/fastText/elmo/bert。
- https://zhuanlan.zhihu.com/p/56382372
- Bert之后,RoBERTa、XLNET、ALBERT、ELECTRA改进对比 - 虹膜小马甲的文章 - 知乎 https://zhuanlan.zhihu.com/p/486532878
一、文本表示和各词向量间的对比
1、文本表示和各词向量间的对比
- 词袋模型:one-hot、tf-idf、textrank等;
- 主题模型:LSA(SVD)、pLSA、LDA;
- 基于词向量的固定表征:word2vec、fastText、glove
- 基于词向量的动态表征:elmo、GPT、bert
2、怎么从语言模型理解词向量?怎么理解分布式假设?
上面给出的4个类型也是nlp领域最为常用的文本表示了,文本是由每个单词构成的,而谈起词向量,one-hot是可认为是最为简单的词向量,但存在维度灾难和语义鸿沟等问题;通过构建共现矩阵并利用SVD求解构建词向量,则计算复杂度高;而早期词向量的研究通常来源于语言模型,比如NNLM和RNNLM,其主要目的是语言模型,而词向量只是一个副产物。
所谓==分布式假设,用一句话可以表达:相同上下文语境的词有似含义==。而由此引申出了word2vec、fastText,在此类词向量中,虽然其本质仍然是语言模型,但是它的目标并不是语言模型本身,而是词向量,其所作的一系列优化,都是为了更快更好的得到词向量。glove则是基于全局语料库、并结合上下文语境构建词向量,结合了LSA和word2vec的优点。
3、传统的词向量有什么问题?怎么解决?各种词向量的特点是什么?
上述方法得到的词向量是固定表征的,无法解==决一词多义==等问题,如“川普”。为此引入基于语言模型的动态表征方法:elmo、GPT、bert。

各种词向量的特点:
One-hot 表示 :维度灾难、语义鸿沟;
分布式表示 (distributed representation) :
- 矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大;
- 基于NNLM/RNNLM的词向量:词向量为副产物,存在效率不高等问题;
- word2vec、fastText:优化效率高,但是基于局部语料;
- glove:基于全局预料,结合了LSA和word2vec的优点;
- elmo、GPT、bert:动态特征;
4、word2vec和NNLM对比有什么区别?(word2vec vs NNLM)
1)其本质都可以看作是语言模型;
2)词向量只不过NNLM一个产物,word2vec虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
- 与NNLM相比,词向量直接sum,不再拼接,并舍弃隐层;
- 考虑到sofmax归一化需要遍历整个词汇表,采用hierarchical softmax 和negative sampling进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling更为直接,实质上对每一个样本中每一个词都进行负例采样;
5、word2vec和fastText对比有什么区别?(word2vec vs fastText)
- 都可以无监督学习词向量, fastText训练词向量时会考虑subword;
- fastText还可以进行==有监督学习==进行文本分类,其主要特点:
- 结构与CBOW类似,但学习目标是人工标注的分类结果;
- 采用hierarchical softmax对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
- 引入N-gram,考虑词序特征;
- 引入subword来处理长词,处理未登陆词问题;
6、glove和word2vec、 LSA对比有什么区别?(word2vec vs glove vs LSA)
glove vs LSA
LSA(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高;
glove可看作是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化;
==word2vec vs glove==
word2vec是局部语料库训练的,其特征提取是基于滑窗的;而glove的滑窗是为了构建co-occurance matrix,是基于全局语料的,可见glove需要事先统计共现概率;因此,word2vec可以进行在线学习,glove则需要统计固定语料信息。
word2vec是无监督学习,同样由于不需要人工标注;glove通常被认为是无监督学习,但实际上glove还是有label的,即共现次数
。
word2vec损失函数实质上是带权重的交叉熵,权重固定;glove的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,==glove可以被看作是更换了目标函数和权重函数的全局word2vec==。
7、 elmo、GPT、bert三者之间有什么区别?(elmo vs GPT vs bert)
之前介绍词向量均是静态的词向量,无法解决一次多义等问题。下面介绍三种elmo、GPT、bert词向量,它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
- 特征提取器:elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的==Transformer==可采用多层,并行计算能力强。
- 单/双向语言模型:GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,采用了完整句子。
二、深入解剖word2vec
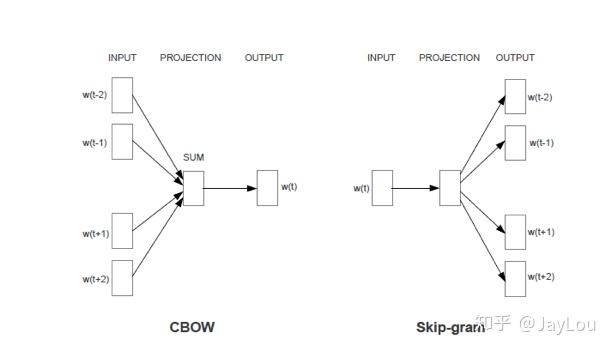
1、word2vec的两种模型分别是什么?
word2Vec 有两种模型:CBOW 和 Skip-Gram:
- CBOW 在已知
context(w)的情况下,预测w;在CBOW中,投射层将词向量直接相加而不是拼接起来,并舍弃了隐层,这些牺牲都是为了减少计算量。 - Skip-Gram在已知
w的情况下预测context(w);
2、word2vec的两种优化方法是什么?它们的目标函数怎样确定的?训练过程又是怎样的?
不经过优化的CBOW和Skip-gram中 ,在每个样本中每个词的训练过程都要遍历整个词汇表,也就是都需要经过softmax归一化,计算误差向量和梯度以更新两个词向量矩阵(这两个词向量矩阵实际上就是最终的词向量,可认为初始化不一样),当语料库规模变大、词汇表增长时,训练变得不切实际。为了解决这个问题,word2vec支持两种优化方法:hierarchical softmax 和negative sampling。此部分仅做关键介绍,数学推导请仔细阅读《word2vec 中的数学原理详解》。
- hierarchical softmax
hierarchical softmax 使用一颗二叉树表示词汇表中的单词,每个单词都作为二叉树的叶子节点。对于一个大小为V的词汇表,其对应的二叉树包含V-1非叶子节点。假如每个非叶子节点向左转标记为1,向右转标记为0,那么每个单词都具有唯一的从根节点到达该叶子节点的由{0 1}组成的代号(实际上为哈夫曼编码,为哈夫曼树,是带权路径长度最短的树,哈夫曼树保证了词频高的单词的路径短,词频相对低的单词的路径长,这种编码方式很大程度减少了计算量)。
- negative sampling(拒绝采样)
negative sampling是一种不同于hierarchical softmax的优化策略,相比于hierarchical softmax,negative sampling的想法更直接——为每个训练实例都提供负例。
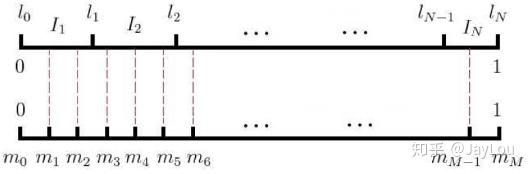
负采样算法实际上就是一个带权采样过程,负例的选择机制是和单词词频联系起来的。具体做法是以
N+1 个点对区间 [0,1]
做非等距切分,并引入的一个在区间 [0,1] 上的 M
等距切分,其中 M >> N。源码中取 M =
10^8。然后对两个切分做投影,得到映射关系:采样时,每次生成一个 [1, M-1]
之间的整数 i,则 Table(i)
就对应一个样本;当采样到正例时,跳过(拒绝采样)。

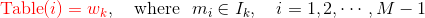
三、深入解剖Glove详解
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具。
1、GloVe构建过程是怎样的?
(1)根据语料库构建一个共现矩阵,矩阵中的每一个元素
代表单词
和上下文单词
在特定大小的上下文窗口内共同出现的次数。
共现矩阵:统计文本中两两词组之间共同出现的次数
(2)构建词向量(Word Vector)和共现矩阵之间的近似关系,其目标函数为:
这个loss function的基本形式就是最简单的mean square
loss,只不过在此基础上加了一个权重函数 :
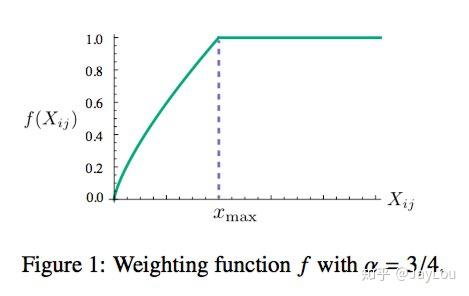
根据实验发现
的值对结果的影响并不是很大,原作者采用了
。而
时的结果要比
时要更好。下面是
时
的函数图象,可以看出对于较小的
,权值也较小。这个函数图像如下所示:
- 实质上还是监督学习:虽然glove不需要人工标注为无监督学习,但实质还是有label就是
- 向量
和
为学习参数,本质上与监督学习的训练方法一样,采用了AdaGrad的梯度下降算法,对矩阵
中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
- 最终学习得到的是两个词向量是
,因为
作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。