恶意软件检测(11)T&-Blackhat 2022-Malware Classification With Machine Learning Enhanced by Windows Kernel Emulation
Malware Classification With Machine Learning Enhanced by Windows Kernel Emulation
论文:http://i.blackhat.com/USA-22/Thursday/US-22-Trizna-Malware-Classification-with-machine-learning.pdf
项目:https://github.com/dtrizna/quo.vadis
作者:Dmitrijs Trizna
我们提出了一种混合机器学习架构,该架构同时使用多个深度学习模型来分析Windows可移植可执行文件的上下文和行为特征,并根据元模型的决策生成最终预测。当代机器学习Windows恶意软件分类器中的检测启发式通常基于样本的静态属性,因为通过虚拟化进行的动态分析对于大量样本是具有挑战性的。为了克服这一限制,我们采用了一种Windows内核仿真,它允许以最小的时间和计算成本跨大型语料库获取行为模式。我们与一家安全供应商合作,收集了超过10万个类似于当代威胁场景的野生样本,其中包含执行时应用程序的原始PE文件和文件路径。获取的数据集至少比行为恶意软件分析相关工作中报告的数据集大十倍。训练数据集中的文件由专业威胁情报团队使用手动和自动逆向工程工具进行标记。我们通过在获得训练集三个月后收集样本外测试集来估计混合分类器的操作效用。我们报告了一种改进的检测率,高于当前最先进模型的能力,特别是在低误报要求下。此外,我们还发现了元模型在验证和测试集中识别恶意活动的能力,即使没有一个单独的模型表达足够的信心来将样本标记为恶意。我们得出结论,元模型可以从不同分析技术产生的表示组合中学习恶意样本的典型模式。此外,我们公开发布预先训练的模型和仿真报告的非命名数据集。
因此实现了与虚拟化相比的高分析速率。由于数据异构性,我们考虑使用多个单独的预训练模块和元模型的组合解决方案,而不是构建具有端到端可训练架构的单个特征向量。该架构允许通过仅重新训练元模型,以最小的努力扩展决策启发式的模块性。在本出版物的范围内,混合ML体系结构的评估依赖于三种不同的分析技术
缺乏出版物人工制品是任何研究中一个臭名昭著的缺陷,并导致了科学的再现性危机。因此,我们披露了源代码和预训练的PyTorch[19]和scikit learn[25]模型,并为我们的模型提供了类似scikit learn[20]的API,遵循机器学习对象广泛采用的接口。据我们所知,我们是安全研究社区中第一个发布基于(a)上下文、(b)静态和(c)PE文件动态属性的单一决策启发的模型。
模型训练三个月后,我们收集了一个样本外数据集。我们承认,与任何单独的方法能力相比,基于软件混合表示的恶意软件分类可以提高检测性能,降低针对恶意逻辑不断演变的误报率
仿真器不需要调动成熟的操作系统操作,因为它们允许以合理的速度获取大量遥测数据,而不需要虚拟化基础设施。因此,利用仿真器作为ML模型的遥测源进行动态恶意软件分析研究很有前景,但尚未普遍采用。据我们所知,Athiwaratkun和Stokes在2017年首次报告了系统调用收集的仿真器利用率[4]。他们的模型类似于自然语言处理(NLP)中使用的递归方案。Agrawal等人[2]进一步发展了这项工作,他们提出了一种类似的架构,用于在仿真器的帮助下获取的任意长API调用序列。Mandiant的数据科学团队通过基于仿真的动态分析进行了有前景的研究。具体而言,Li等人[16]提供了一个扩展摘要,报告了仿真器[18]在与我们的架构类似的混合分析中的使用情况
基于仿真的行为分析工作的稀疏性是由于它们的局限性。仿真是在模拟器运行的操作系统之上的抽象,不会与硬件发生直接交互。理论上,完美的仿真器可以欺骗任何系统调用背后的逻辑。尽管如此,像Windows N这样的内核并没有集成大量的功能,从而实现了难以置信的一对一复制。我们在第3.2节中报告了与相关的基于虚拟化的工作数据集的详细错误率和数据多样性比较。根据经验证据,我们认为现代Windows内核仿真在ML恶意软件检测器中具有巨大潜力。仿真报告生成丰富多样的遥测,绕过静态分析限制。它包含可执行文件调用的一系列内核API调用,并描述对文件或注册表项的操作以及尝试的网络通信。
例如,我们在训练和验证数据集报告中获取了2822个唯一的API调用。与相关工作数据集相比,这种行为的异构性明显更高-Athiwaratkun和Stokes[4]总共有114个独特的API调用,Kolosnjaji等人[14]报告了60个独特的API调用,Yen等人[33]有286个不同的API调用。Rosenberg等人[23]有314个单独的API调用。由于独特调用的数量与样本数量正相关,因此我们的数据集的较大容量可以部分地描述这种观察。然而,我们强调这是仿真技术效率的证据。仿真报告生成丰富多样的遥测数据,其质量相当于用于动态分析目的的沙箱。
三、数据集
本工作中提出的混合解决方案的功能基于输入数据,包括(a)适用于动态分析的武装PE文件和(b)上下文文件路径信息。获取上下文数据的必要性导致无法利用公共数据收集,因为对于每个数据样本,我们都需要拥有原始PE字节和文件路径数据。
据我们所知,所有已知数据集均未提供文件执行时具有文件路径值的PE样本的上下文信息。例如,Kyadige和Rudd等人[15]依赖专有的Sophos威胁情报源,不公开发布其数据集。上下文数据的私有性质是可以理解的,因为这种遥测将包含敏感组件,如个人计算机上的目录。
因此,我们与一家未公开的安全供应商合作,收集了大量数据集,其中包含原始PE文件和来自个人客户系统的样本文件路径,类似于最新的威胁场景。根据所有客户接受的隐私政策处理数据。因此,我们不会公开发布文件路径和原始PE数据集。敏感数据组件(如用户名或自定义环境变量)来自预处理阶段的遥测,在模型参数或仿真报告中没有相似之处。
3.1 数据集结构
我们分两次收集数据集。第一部分构成了我们分析的基础,包括98966个样本,329GB的原始PE字节。80%的语料库被用作固定的训练集,20%形成样本内验证集。我们使用这些数据对模型进行预训练,并研究我们的混合解决方案配置。
第二次数据集采集会议发生在三个月后,从27500个样本(约100GB的数据)形成了样本外测试集。该语料库用于评估混合模型的实际效用,并研究模型在进化的恶意景观上的行为。
数据集中的PE文件由专业威胁情报团队标记,利用恶意软件分析师操作的手动和自动逆向工程工具。数据集涵盖七个恶意软件家族和benignware,详细分布参数如表1所示。除“干净”外,所有标签均表示恶意文件。因此,我们收集了相对更多的“干净”样本,以平衡数据集中的恶意和良性标签。
由于大多数恶意软件被编译为x86二进制文件,因此我们关注32位(x86)图像,并有意跳过64位(x64)图像的集合,以保持数据集的同质性和标签平衡。此外,恶意软件作者更喜欢x86二进制文件,因为Microsoft向后兼容性允许在64位系统上执行32位二进制文件,但反之亦然。数据集由可执行文件(.exe)组成,我们有意省略库PE文件(.dll)。
3.2 样本评估
表1中表示的所有示例都是用Windows内核仿真器处理的。我们使用Mandiant根据MI T许可证发布并积极维护的Speakeasy[18]基于Python的仿真器。我们测试中使用的Speakeasy版本是1.5.9。它依赖于QEMU[6]CPU仿真框架。我们获得了108204个成功的仿真报告,每个报告的平均运行时间为12.23秒,仿真了来自训练和验证集的90857个样本,以及测试集中的17347个样本。
不幸的是,一些示例模拟是错误的,主要是由于写入汇编指令的无效内存读取。然而,模拟错误的另一个常见原因是调用了不受支持的API函数或反调试技术。图1显示了不同恶意软件系列的错误率。
据推测,模拟数据集的一个潜在缺点可能是,与沙箱中实时执行样本相比,其相对稀疏。然而,经验证据表明,我们的数据集比使用全Windows系统虚拟化执行类似数据采集的其他组报告的数据更为多样。例如,我们在训练和验证数据集报告中获得2822个唯一的API调用。与相关工作数据集相比,这种行为的异构性明显更高-Athiwaratkun和Stokes[4]总共有114个独特的API调用,Kolosnjaji等人[14]报告了60个独特的API调用,Yen等人[33]有286个不同的API调用。Rosenberg等人[23]有314个单独的API调用。这种观察部分可以通过我们数据集的更大容量来描述,因为唯一调用的数量与样本数量正相关。然而,我们强调这是仿真技术效率的证据。仿真报告生成丰富多样的遥测数据,其质量相当于用于动态分析目的的沙箱。
四、系统结构

图2显示了混合模型体系结构的总体概述𝜙, 它们被“融合”在一起,由元模型生成最终决策𝜓. 三种早期融合模型𝜙 是:
- file-path 1D convolutional neural network (CNN), 𝜙𝑓𝑝
- emulated API call sequence 1D CNN, 𝜙𝑎𝑝𝑖
- FFNN model processing Ember feature vector, 𝜙𝑒𝑚𝑏
每个子模型从输入数据获取的128维表示向量。此外,所有三个模型的输出连接在一起形成384维向量。因此,给定输入样本𝑥, 由原始PE(字节)及其文件路径(字符串)组成,早期融合过程统称为:

中间向量𝜙 (𝑥) 传递给元模型𝜓, 其产生最终预测:

所有早期融合网络都是单独预训练的,在第4.3节中详细定义了模型配置和训练过程。我们想强调,构建具有多个单独预训练组件的模块化系统而不是构建单个端到端可训练架构的决策是经过深思熟虑的。首先,Yang等人[32]表明,具有高概率的复合神经网络优于单个预训练组件的性能。
「 然而,主要原因是通过仅重新训练元模型,扩展具有互补模块的混合决策启发式的巨大潜力」。恶意活动分类问题依赖于原始PE字节以外的高度异构的信息源,这种体系结构保留了添加依赖于系统日志记录的启发式的能力。在本次发布之时,我们已经合并了文件路径信息,例如可以从Sysmon2遥测中获取。然而,可以进一步提取Sysmon数据或Speakeasy报告中的知识。
4.1 API 调用处理
Json_normalize:json to pandas
为了获取API调用序列的数值,我们根据可变词汇表大小选择最常见的调用𝑉 . 保留的API调用是标签编码的,不属于词汇表的调用将替换为专用标签。使用填充标签将最终序列截断或填充到固定长度𝑁.

表2显示了数据集多样性和各自模型性能背后的统计数据。尽管100个最常见的调用在一个数据集中包含95%以上的API调用,但实验表明该模型仍然受益于相对较大的词汇表大小值,因此我们选择𝑉 = 600用于我们的最终配置。这种现象可以通过每个样本的API调用分布来解释。具有数百个调用的冗长可执行文件会影响系统调用频率,而具有适度API序列的可执行文件则执行更独特的函数组合。
4.2 路径处理
路径预处理的第一部分包括路径规范化,因为文件路径语义的某些部分具有与通过深度学习模型进行的安全分析无关的可变性。如果使用通用命名约定(UNC)格式,则包括特定的驱动器号或网络位置,以及单个用户名。因此,在规范化过程中,我们为这些路径组件引入了通用占位符,如下所示:
[drive][user]\04-ca\8853.vbs [drive][user].tmp [net]2021.xlsm
此外,有必要分析Windows环境变量,使其类似于实际的文件路径,而不是用作变量名的环境别名。因此,我们构建了一个由大约30个环境变量组成的变量映射,这些变量表示系统上的特定路径,并在当代和传统Windows系统中使用。变量映射的一些示例如下所示:
r"%systemdrive%": r"[drive]", r"%systemroot%": r"[drive]", r"%userprofile%": r"[drive][user]"
分别使用100和150个最频繁的UTF-8字节。频率阈值以下的罕见字符将被丢弃,并由单个专用标签替换。
4.3 早期融合模型架构
如第3节所述,我们不能依赖于公开发布的恶意软件集合,因为该模型在执行时需要文件路径形式的上下文信息,而这些信息不是公开的。因此,与现有研究相比,为了保持评估模型性能的能力,我们只能依赖其他研究小组发布的带有预训练参数的恶意软件分类模型,并进一步评估我们数据集上的模型。不幸的是,没有任何混合或动态分析出版物[14、17、23、27、33]提供这样的伪影。
幸运的是,多个静态分析出版物伴随着代码库形式的工件[3,21,24]。例如,可以直接使用Ember LightGBM[12]模型,该模型是在Endgame3于2019年发布的Ember数据集[3]上预训练的。然而,我们不将该模型包括在我们的复合解决方案中,因为决策树模型不学习元模型可以使用的表示,只提供标量形式的最终预测。我们仍然依赖Ember特征提取方案[3],但使用Rudd等人[24]发布的FFNN,分别具有三个隐藏层或512、512和128个隐藏神经元,均使用ELU[9]非线性,具有层归一化[5]和丢失率[30]𝑝 = 0.05。我们在来自Ember训练集[3]的600k个特征向量和来自我们训练集的72k个样本上重新训练了200个周期的FFNN。
「 文件路径和API调用序列的分析可以被表述为相关的优化问题,即一维(1D)序列的分类 」。我们在受Kyadige和Rudd等人[15]影响的两种模型中使用了类似的神经结构,即嵌入层,具有用于表示提取的一维卷积神经网络(CNN)和完全连接的神经网络学习分类器功能。我们知道,有多种选择可以用交替结构(如递归神经网络(RNN)[8,10])来建模序列分类问题。然而,如API调用序列分类的相关工作所示,两种模型体系结构都报告了类似的性能[14,23],但表明1D CNN的计算要求明显降低[34]。
编码输入向量𝑥 定长𝑁 为嵌入层提供尺寸𝐻 词汇量𝑉 . 这些参数受到超参数优化的影响。通过验证集上的超参数优化获得的文件路径模型的最佳值为:输入向量𝑥𝑓𝑝 长𝑁 = 100,嵌入维数𝐻 = 64、词汇量𝑉 = 150.模拟API调用序列模型的相应值为:输入向量𝑥𝑒𝑚 长𝑁 = 150,嵌入尺寸𝐻 = 96和词汇量𝑉 = 600.文件路径模型的词汇表由最常见的UTF-8字节形成,对于API调用序列模型,选择最常见的系统调用。两个词汇表都有两个用于填充和稀有字符的标签。「 嵌入层的输出被传递到四个单独的1D 卷积层 」,内核大小为2、3、4和5个字符,输出通道的数量𝐶 = 128.带较低𝐶 价值模型表现不佳。例如𝐶 = 64文件路径的模块验证集F1分数低至0.962,而𝐶 ∈ {100,128,160}得分在0.966左右。
所有四个卷积层的输出连接到大小为 4×𝐶 并传递到具有四个隐藏层的FFNN,其中包含1024、512、256和128个神经元。FFNN的隐藏层使用整流线性单元(ReLU)[1]激活。最后一层使用S形激活。在ReLU激活之前,将批量归一化[11]应用于FFNN的隐藏层。此外,为了防止过度装配,使用 𝑝 = 0.5的速率。
使用二进制交叉熵损失函数拟合所有早期融合网络:

𝜙 (𝑥; 𝜃) 表示由深度学习模型给定参数近似的函数𝜃, 和𝑦 ∈ {0,1}是地面真相标签。使用Adam优化器[13]进行优化,学习率为0.001,批量大小为1024个样本。我们使用PyTorch[19]深度学习库构建了一维卷积网络、EMBER FFNN和训练例程。
4.4 元模型
早期融合模型的输出𝜙 (𝑥) 用于训练元模型𝜓. 评估了三种不同的架构类型,使用scikit学习库[20]实现了逻辑回归和FFNN,并基于xgboost[7]实现了梯度提升决策树分类器。
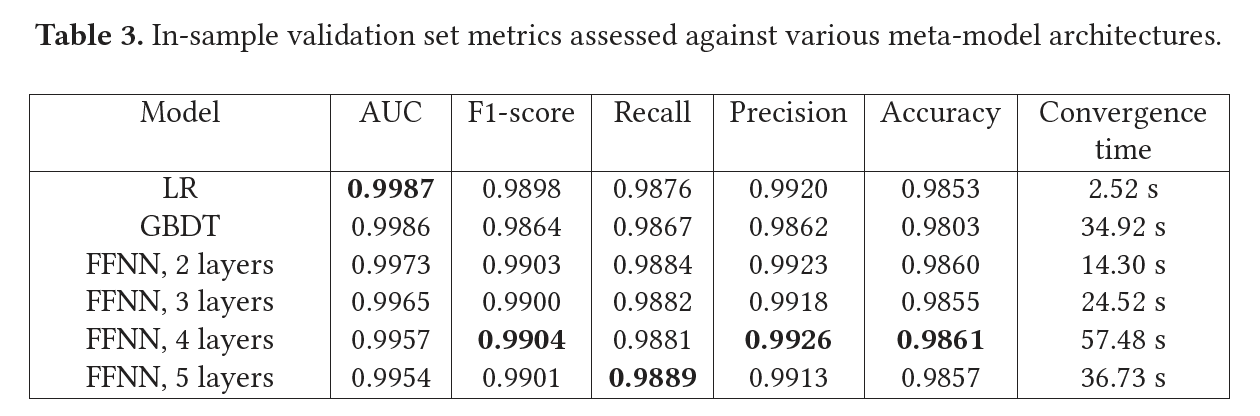
自元模型𝜓 执行相对复杂的非线性映射 [0,1]^384→ [0,1],基于表3中的性能指标,我们得出结论,融合的分类表面不平滑,并呈现了利用所有三种特征提取方法的表示进行最终决策的组合,而逻辑回归等简单模型无法学习。我们选择具有384、128、64和16个神经元的四层FFNN作为最终评估的元模型,因为它具有接近最佳的分数。
五、实验结果
实验表明,同时利用静态、动态和上下文信息的检测率明显高于单个模型的性能,特别是在低误报要求下。这种需求通常表达为安全行业中的机器学习解决方案。不符合低误报需求的解决方案通常不允许为人类分析师生成警报[22]。图3显示了样本外测试集给定固定假阳性率(FPR)的检测率(%)。
在100000个案例中,在FPR仅为100个错误分类的情况下设置警报阈值,Ember FFNN、filepath和仿真模型的个体模型检测率分别为56.86%、33.31%和33.89%。 然而,通过结合从所有三种处理技术中学习到的表示,混合解决方案可以从训练三个月后收集的测试集中的所有样本中正确分类86.28%。
令人惊讶的观察结果产生了文件路径和仿真模型。两种模型各自表现相对较差,尤其是与余烬FFNN相比。这一观察结果背后的一个潜在解释是由原始ember出版物[3]中的600k个特征向量组成的ember FFNN训练集。这种训练语料库比我们的100k样本更好地概括了“真实”恶意PE分布,反映了特定时间窗口中的威胁情况。
然而,在低误报要求下,仅文件路径和仿真模型的组合,忽略静态分析,优于在更广泛的数据集上训练的最先进的余烬特征提取方案,在10000个样本中的一个样本的FPR下,检测率为77.36%对55.86%。
此外,将这两种模型结合在一起会导致检测率高于单个模型的累积能力,从而更加突出了混合元模型相对于狭义解决方案的优势。例如,虽然单个文件路径和仿真模型在105个错误警报的FPR中仅检测到33.31%和10.24%的样本,但它们的组合产生了77.36%的检测率。
这一观察结果适用于从不同系统和不同时间框架收集的样本内验证和样本外测试集,使我们能够得出结论,这是具有元模型的混合检测启发式的一般属性,而不是特定数据集的伪影。对于文件路径、仿真和组合启发式,在105种情况下,给定一次错误分类的样本内验证集的值分别为34.46%、13.52%和97.25%
这一观察结果可以得出结论,元模型可以学习不同分析技术产生的恶意样本表示外组合的典型模式,例如组合特定的API调用序列和Trizna文件路径n-gram。这些表示中的每一个单独产生的证据都不足以将样本归类为恶意,因为它也发生在良性应用中。因此,只有当良性和恶意样本都被标记时,检测才会解除假阳性要求。然而,来自文件路径和API调用的表示的组合允许元模型在384维空间中构建决策边界以隔离此类情况,从而产生超过40%的检测率。
因此,我们看到,静态、动态和上下文数据的综合利用解决了独立方法的弱点,允许最小化FPR和假阴性率(FNR)。 表4中报告了所有集合的F1得分、精确度、召回率、精确度和AUC得分,元模型决策阈值为0.98,类似于FPR≈ 验证集为0.25%。虽然样本
内验证集的报告结果允许得出模型几乎没有过度拟合的结论,但我们仍然观察到样本外测试集F1和AUC得分下降了≈ 4.− 4.5%. 尽管恶意软件家族的比例相同,但检测分数仍会下降,我们认为这种现象的因果关系源自恶意逻辑的进化本质。
六、结论
我们已经证明,ML算法受益于混合分析,从而提高了性能,特别是在低误报要求下。我们确实报告了基于余烬特征向量[3]的当前最先进的恶意软件建模方案的异常性能,该方案报告的检测率明显高于单独的文件路径或仿真模型,如图3所示。然而,将余烬模型与文件路径或模拟或两种模型相结合,可以显著提高检测能力,在某些情况下,如低误报要求,几乎30%。
此外,我们报告说,混合解决方案可以检测恶意样本,即使没有一个单独的组件表示足够的信心来将输入分类为恶意。例如,对于100000个错误分类案例的FPR,单个文件路径和仿真模型仅检测到33.31%和10.24%的样本。它们的组合产生77.36%的检测率,如果两个模型一起使用但独立使用,则检测能力提高了40%以上。
我们得出结论,元模型可以从不同分析技术产生的表示组合中学习恶意样本的典型模式。此外,这一结论得到了数据集大小的支持,数据集大小明显大于行为恶意软件分析的相关工作。
我们认为,动态和语境分析的积极特征可以进一步扩展。虽然我们用API调用序列表示系统上的PE行为,但并非所有可执行功能都是通过API调用表示的。==额外的可见性源对于最小化模型决策启发式中的模糊性可能至关重要,我们认为扩展组合解决方案的模块性是一个有前途的研究方向。我们的分析中省略了大部分仿真遥测。==
我们公开发布了108204个样本的模拟报告,并期望在这方面进一步开展工作。文件系统和注册表修改、网络连接和内存分配可能为检测提供关键信息。我们解决方案的架构允许我们通过只重新训练元模型的参数,以最小的努力扩展决策启发式的模块性。
代码结构
data/
adversarial.emulated
emulation.dataset
path.dataset
pe.dataset
train_val_test_sets
evaluation/【评估】
img/【图片】
modules/【模型保存】
preprocessing/【数据预处理】
- arrary
utils/
models.py 【模型结构】【CompositeClassifier 类】
example.py 【代码样例】