import torch import torch.nn as nn from common_tools import set_seed
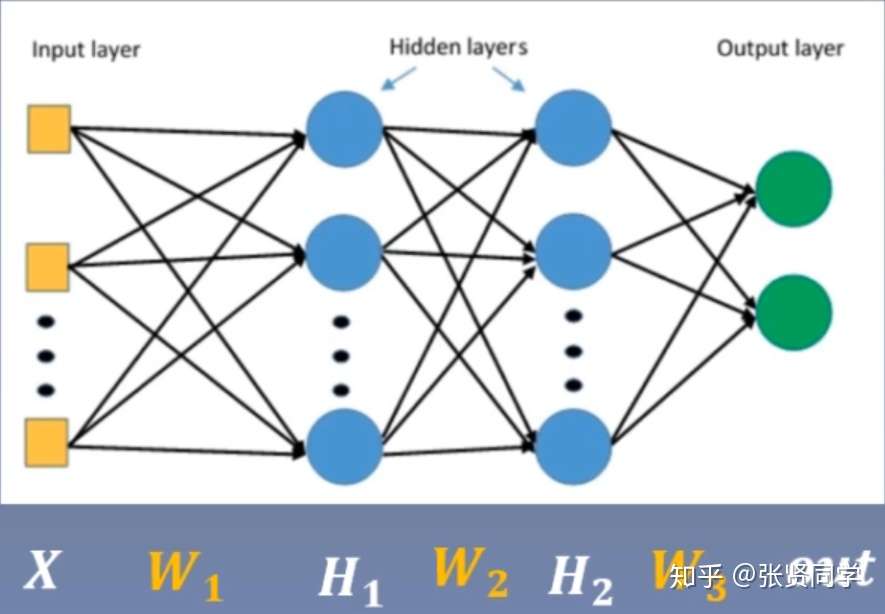
set_seed(1) # 设置随机种子 classMLP(nn.Module): def__init__(self, neural_num, layers): super(MLP, self).__init__() self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i inrange(layers)]) self.neural_num = neural_num
defforward(self, x): for (i, linear) inenumerate(self.linears): x = linear(x) return x defforward_new(self, x): for (i, linear) inenumerate(self.linears): x = linear(x) print("layer:{}, std:{}".format(i, x.std())) if torch.isnan(x.std()): print("output is nan in {} layers".format(i)) break return x definitialize(self): for m in self.modules(): # 判断这一层是否为线性层,如果为线性层则初始化权值 ifisinstance(m, nn.Linear): nn.init.normal_(m.weight.data) # normal: mean=0, std=1
:两个相互独立的随机变量的乘积的期望等于它们的期望的乘积
:一个随机变量的方差等于它的平方的期望减去期望的平方
:两个相互独立的随机变量之和的方差等于它们的方差的和
![[公式]](https://www.zhihu.com/equation?tex=D%28X+%5Ctimes+Y%29%3DE%5B%28XY%29%5E%7B2%7D%5D+-+%5BE%28XY%29%5D%5E%7B2%7D%3DD%28X%29+%5Ctimes+D%28Y%29+%2B+D%28X%29+%5Ctimes+%5BE%28Y%29%5D%5E%7B2%7D+%2B+D%28Y%29+%5Ctimes+%5BE%28X%29%5D%5E%7B2%7D)
,
,那么