特征工程(5)特征融合
特征工程|数据清洗(预处理)、特征生成、特征拼接
这或许是全网最全机器学习模型融合方法总结!:https://zhuanlan.zhihu.com/p/511246278
特征工程的完整流程是:特征设计 -> 特征获取 -> 特征处理 -> 特征存储 -> 特征监控。前边介绍了那么多,相当于是对特征设计、特征获取、特征存储进行了说明,而特征工程中最重要的环节则是特征处理。特征处理中还包括:数据清洗、特征生成、特征拼接、特征处理、特征转换、特征选择。本篇主要介绍数据清洗、特征生成、特征拼接。
一、数据清洗
从特征工程角度讲,数据清洗是特征工程的前置阶段(但是也会贯穿整个数据应用过程),其本义是对数据进行重新的审查和校验,目的在于删除重复信息、纠正存在的错误数据,并保证数据的一致性。数据清洗是整个数据分析过程中不可缺少的一个环节,其结果质量直接关系到模型效果和最终结论。
一个特征处理的完整流程可以表示为:
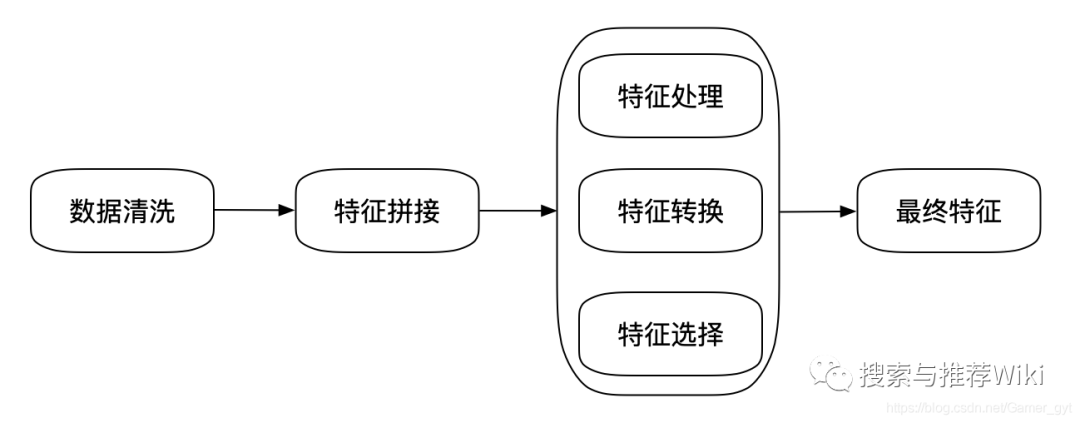
因此基础数据的准确性、完备性、一致性决定了后续特征数据的有效性。在我们日常使用的公开数据集中,很多都是已经被处理后的了,比如学术界中使用很广泛的MovieLens数据集,但是在真实的业务场景中,我们拿到的数据其实直接是没有办法使用的,可能包含了大量的缺失值,可能包含大量的噪音,也可能因为人工录入错误导致有异常点存在,对我们挖据出有效信息造成了一定的困扰,所以我们需要通过一些方法,尽量提高数据的质量。
初期数据清洗更多的是针对单条样本数据的清洗和检测,包括:
- 数据表示一致性处理
- 逻辑错误值处理
- 缺失值处理
- 非必要性数据剔除
在实际的业务场景中,数据是由系统收集或用户填写而来,有很大可能性在格式和内容上存在一些问题,同样类型的数据在不同的团队上报过程中产出的内容或格式会不一致,同样不同数据源采集而来的数据内容和格式也会不一致。
数据格式的一致性。比如时间信息(以2020年6月18日,11点11分12秒为例),有的用毫秒时间戳表示(1592449872000),有的用秒时间戳表示(1592449872),有的用带横线的时间表示(2020-06-18 11:11:12),有的则用不带横线的时间表示(20200618 11:11:12)。
数据类型的一致性。比如不同的数据表中,同样表示用户ID的字段,有的可能是string类型,有的是int类型。如果用string类型表示,如果用户id缺失的话,正常可以留空,但是不同团队,不同人对于缺失的id处理方式也会不一致,比如有的用None,有的用Null,有的则用0表示,可谓是千奇百怪。小编在日常工作中也会经常遇到这种情况,被折磨的体无完肤。
二、特征生成
对基础数据进行清理之后需要做的就是生成我们需要的特征,在特征设计部分提到特征主要分为四大维度,根据小编的经验特征又可以根据其值的属性划分为:
- 类别特征:即特征的属性值是一个有限的集合,比如用户性别、事物的类别、事物的ID编码类特征等
- 连续特征:即用户行为、类别、组合特征之类的统计值,比如用户观看的视频部数、某类别下事物的个数等
- 时间序列特征:即和时间相关的特征,比如用户来访时间、用户停留时长、当前时间等。
- 组合特征:即多种类别的组合特征,比如用户在某个类别下的行为统计特征、当天内事物被访问次数特征等
- 文本特征:即和文本相关的特征,比如评论数据、商品描述、新闻内容等。
- Embedding特征:即一些基础特征的高层次表示,比如用户ID编码的Embedding表示、事物ID编码的Embedding表示、用户访问事物序列的Embedding编码等。
三、特征融合
多模态特征融合三部曲: https://zhuanlan.zhihu.com/p/390668652
推荐系统(六)—— 特征融合 : https://zhuanlan.zhihu.com/p/459012483
3.1 特征处理
假设你有三种类型数据,或者说可以是三个不同维度的向量.
\[ x_1 \in \mathbb{R}^{n_1}, x_2 \in \mathbb{R}^{n_2}, x_3 \in \mathbb{R}^{n_3} \]
第一种融合手段就是在训练前进行的
- 三个向量直接concat,可能维度会比较高,再进行个PCA
- 自编码器结构:三个向量通过MLP映射成一个维度后相加,用还原回去;融合特征再用来做后续的模型设计和训练就好了。

3.2 模型结构
一种直接的思想就是分而治之,多分支网络;还有一种比较出名的在中间层进行融合的方法,多模态双线性矩阵分解池化方法(MFB),本质上就是对不同模态数据进行双线性融合,借助矩阵分解的思想,再对原始特征进行高维映射,然后element-wise相乘后再做pooling操作。


3.3 后处理
后处理其实也是分而治之的思想,多模态数据分别训练不同的模型,再将不同模型的预测输出进行融合,比如平均、加权,或者fix住原来的多个网络,后面再加一层进行微调。

3.4 特征融合是什么?和特征交叉有什么区别呢?
在上一篇文章(yu-lzn:推荐系统(五)—— 特征交叉)中,我们讨论了特征交叉,特征交叉也称为特征组合,旨在提高模型对非线性的建模能力,从而提高模型的性能。特征融合和特征交叉有相同的目的,都是为了提高模型的性能。特征融合是想更好地利用不同特性的特征。
随着信息时代的发展,在推荐系统中,多模态信息的融合也变得越来越重要。以淘宝购物为例,用户在决策是否购买物品时,会考虑物品的属性、物品图片的展示、其他用户的评论信息、甚至是观看物品的介绍视频等等。换句话说,这些多模态信息(文本、图片、视频)会影响用户的行为。所以如何利用这些多模态信息来建模,是提高推荐系统准确度的一个途径。那么如何去融合这些不同来源的信息便是一个关键的问题。