工业落地-蚂蚁安全-柳星《我对安全与NLP的实践和思考》
柳星-我对安全与NLP的实践和思考
一、个人思考
通过对安全与NLP的实践和思考,有以下三点产出:
- 首先,产出一种通用解决方案和轮子,一把梭实现对各种安全场景的安全检测。通用解决方案给出一类安全问题的解决思路,打造轮子来具体解决这一类问题,而不是使用单个技术点去解决单个问题。具体来说,将安全与NLP结合,在各种安全场景中,将其安全数据统一视作文本数据,从NLP视角,统一进行文本预处理、特征化、预训练和模型训练。例如,在Webshell检测中,Webshell文件内容,在恶意软件检测中,API序列,都可以视作长文本数据,使用NLP技术进行分词、向量化、预训练等操作,同理,在Web安全中,SQl、XSS等URL类安全数据,在DNS安全中,DGA域名、DNS隧道等域名安全数据,同样可以视作短文本数据。因此,只要安全场景中安全数据可以看作文本数据,FXY:Security-Scenes-Feature-Engineering-Toolkit 中,内置多种通用特征化方法和多种通用深度学习模型,以支持多种安全场景的特征化和模型训练,达到流水线式作业。
- 其次,是对应用能力和底层能力的思考。之前写过一篇文章《应用型安全算法工程师的自我修养》,在我当时预期想法中,我理解的应用型,重点在于解决实际安全问题,不必苛求于对使用技术本身的理解深度,可以不具备研究型、轮子型的底层能力。映射到我自身,我做安全和算法,最初想法很好,安全和算法两者我都要做好,这里做好,仅仅指用好。之后,面试时暴露了问题,主管给出的建议是两者都要做好。这里做好,不单单指用好,还要知其所以然。举个例子,就是不仅要调包调参玩的6,还要掌握算法的底层原理,这就是底层能力。当时,懂,也不懂,似懂非懂,因为,说,永远是别人的,悟,才是自己的。在实现通用解决方案和轮子的过程中,遇到关于word2vec底层的非预期问题,才深刻体会到,底层能力对应用能力的重要性。过程中遇到的预期和非预期问题,下文会详述。现在我理解的应用型,重点还是在解决安全问题,以及对安全问题本身的理解,但应用型还需具备研究型、轮子型等上下游岗位的底层能力。安全算法是这样,其他细分安全领域也是一样,都需要底层能力,以发展技术深度。
- 最后,带来思考和认识的提升。从基于机器学习的XX检测,基于深度学习的XX检测,等各种单点检测,到基于NLP的通用安全检测,是一个由点到面的认知提升。从安全和算法都要做好,到安全和算法都要做好,其中蕴含着认知的提升。从之前写过一篇安全与NLP的文章《当安全遇上NLP》,到现在这篇文章。对一件事物的认识,在不同阶段应该是不一样的,甚至可能完全推翻自己之前的认识。我们能做的,是保持思考,重新认识过去的经历,提升对事物的认知和认知能力。这个提升认知的过程,类似boosting的残差逼近和强化学习的奖惩,是一个基于不知道不知道->知道不知道>知道知道->不知道知道的螺旋式迭代上升过程。
二、预期问题
2.1 分词粒度
首先是分词粒度,粒度这里主要考虑字符粒度和词粒度。在不同的安全场景中,安全数据不同,采用的分词粒度也可能不同:
- 恶意样本检测的动态API行为序列数据,需要进行单词粒度的划分。
- 域名安全检测中的域名数据,最好采用字符粒度划分。
- URL安全检测中的URL数据,使用字符和单词粒度划分都可以。
- XSS检测文中,是根据具体的XSS攻击模式,写成正则分词函数,对XSS数据进行划分,这是一种基于攻击模式的词粒度分词模式,但这种分词模式很难扩展到其他安全场景中。
FXY特征化类wordindex和word2vec中参数char_level实现了该功能。在其他安全场景中,可以根据此思路,写自定义的基于攻击模式的分词,但适用范围有限。我这里提供了两种通用词粒度分词模式,第一种是忽略特殊符号的简洁版分词模式,第二种是考虑全量特殊符号的完整版分词模式,这两种分词模式可以适用于各种安全场景中。FXY特征化类word2vec中参数punctuation的值‘concise’,‘all’和‘define’实现了两种通用分词和自定义安全分词功能。下文的实验部分,会测试不同安全场景中,使用字符粒度和词粒度,使用不同词粒度分词模式训练模型的性能对比。
2.2 语料库
关于预训练前字典的建立(语料库)。特征化类word2vec的预训练需求直接引发了字典建立的相关问题。在word2vec预训练前,需要考虑预训练数据的产生。基于深度学习的XSS检测文中,是通过建立一个基于黑样本数据的指定大小的字典,不在字典内的数据全部泛化为一个特定词,将泛化后的数据作为预训练的数据。这里我们将此思路扩充,增加使用全量数据建立任意大小的字典。具体到word2vec类中,参数one_class的True or False决定了预训练的数据来源是单类黑样本还是全量黑白样本,参数vocabulary_size的值决定了字典大小,如果为None,就不截断,为全量字典数据。下文的实验部分会测试是单类黑样本预训练word2vec好,还是全量数据预训练更占优势,是字典截断好,还是用全量字典来预训练好。
2.3 序列
关于序列的问题,具体地说,是长文本数据特征化需求。webshell检测等安全场景,引发了序列截断和填充的问题。短文本数据的特征化,可以保留所有原始信息。而在某些安全场景中的长文本数据,特征化比较棘手,保留全部原始信息不太现实,需要对其进行截断,截断的方式主要有字典截断、序列软截断、序列硬截断。
- 序列软截断是指对不在某个范围内(参数num_words控制范围大小)的数据,直接去除或填充为某值,长文本选择直接去除,缩短整体序列的长度,尽可能保留后续更多的原始信息。如果长本文数据非常非常长,那么就算有字典截断和序列软截断,截断后的序列也可能非常长,超出了模型和算力的承受范围;
- 序列硬截断(参数max_length控制)可以发挥实际作用,直接整整齐齐截断和填充序列,保留指定长度的序列数据。这里需要注意的是,为了兼容后文将说到的“预训练+微调”训练模式中的预训练矩阵,序列填充值默认为0。
2.4 词向量
词向量的问题,具体说,是词嵌入向量问题。词嵌入向量的产生有三种方式:
- 词序列索引+有嵌入层的深度学习模型
- word2vec预训练产生词嵌入向量+无嵌入层的深度学习模型
- word2vec预训练产生预训练矩阵+初始化参数为预训练矩阵的嵌入层的深度学习模型。
这里我把这三种方式简单叫做微调、预训练、预训练+微调,从特征工程角度,这三种方式是产生词嵌入向量的方法,从模型角度,也可以看作是模型训练的三种方法。第一种微调的方式实现起来比较简单,直接使用keras的文本处理类Tokenizer就可以分词,转换为词序列,得到词序列索引,输入到深度学习模型中即可。第二种预训练的方式,调个gensim库中word2vec类预训练,对于不在预训练字典中的数据,其词嵌入向量直接填充为0,第三种预训练+微调的方式,稍微复杂一点,简单来说就是前两种方式的组合,用第二种方式得到预训练矩阵,作为嵌入层的初始化权重矩阵参数,用第一种方式得到词序列索引,作为嵌入层的原始输入。下文的实验部分会测试并对比按这三种方式训练模型的性能,先说结论:预训练+微调>预训练>微调。
三、非预期问题
3.1 已知的库和函数不能满足我们的需求
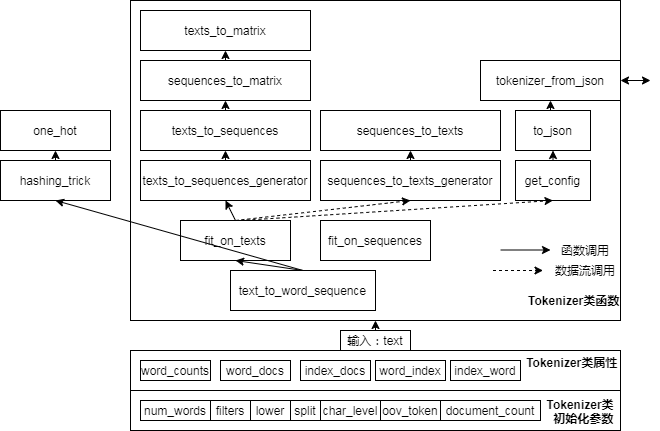
使用keras的文本处理类Tokenizer预处理文本数据,得到词序列索引,完全没有问题。但类Tokenizer毕竟是文本数据处理类,没有考虑到安全领域的需求。 + 类Tokenizer的单词分词默认会过滤所有的特殊符号,仅保留单词,而特殊符号在安全数据中是至关重要的,很多payload的构成都有着大量特殊符号,忽略特殊符号会流失部分原始信息。 + 首先阅读了keras的文本处理源码和序列处理源码,不仅搞懂了其结构和各函数的底层实现方式,还学到了一些trick和优质代码的特性。搞懂了其结构和各函数的底层实现方式,还学到了一些trick和优质代码的特性。下图为Tokenizer类的结构。借鉴并改写Tokenizer类,加入了多种分词模式,我们实现了wordindex类。
3.2 对word2vec的理解不到位
第二个非预期问题是,对word2vec的理解不到位,尤其是其底层原理和代码实现,导致会有一些疑惑,无法得到验证,这是潜在的问题。虽然可以直接调用gensim库中的word2vec类暂时解决问题,但我还是决定把word2vec深究深究,一方面可以答疑解惑,另一方面,就算不能调用别人的库,自己也可以造轮子自给自足。限于篇幅问题,不多讲word2vec的详细原理,原理是我们私下里花时间可以搞清楚的,不算是干货,对原理有兴趣的话,这里给大家推荐几篇优质文章,在github仓库Always-Learning中。
word2vec本质上是一个神经网络模型,具体来说此神经网络模型是一个输入层-嵌入层-输出层的三层结构,我们用到的词嵌入向量只是神经网络模型的副产物,是模型嵌入层的权重矩阵。以word2vec实现方式之一的skip-gram方法为例,此方法本质是通过中心词预测周围词。如果有一段话,要对这段话训练一个word2vec模型,那么很明显需要输入数据,还要是打标的数据。以这段话中的某个单词为中心词为例,在一定滑动窗口内的其他单词都默认和此单词相关,此单词和周围其他单词,一对多产生多个组合,默认是相关的,因此label为1,即是输入数据的y为1,而这些单词组合的one-hot编码是输入数据的x。那么很明显label全为1,全为positive sample,需要负采样来中和。这里的负采样不是简单地从滑动窗口外采样,而是按照词频的概率,取概率最小的一批样本来做负样本(这个概念下面马上要用到),因为和中心词毫不相关,自然label为0。
tensorflow中的nce_loss函数实现了负采样。