AI安全(1)Adversarial Attacks and Defenses in Deep Learning: From a Perspective of Cybersecurity
Adversarial Attacks and Defenses in Deep Learning: From a Perspective of Cybersecurity
- https://dl.acm.org/doi/10.1145/3547330
摘要
深度神经网络的卓越性能推动了深度学习在广泛领域的应用。然而,对抗性样本带来的潜在风险阻碍了深度学习的大规模部署。在这些场景中,人眼无法察觉的对抗性扰动会显著降低模型的最终性能。已经发表了许多关于对抗性攻击及其在深度学习领域的对策的论文。大多数论文都集中在逃避攻击上,即在测试时发现对抗性示例,而不是在训练数据中插入中毒数据的中毒攻击。此外,由于没有标准的评估方法,很难评估对抗性攻击的真实威胁或深度学习模型的稳健性。因此,在本文中,我们回顾了迄今为止的文献。此外,我们试图为系统地理解对抗性攻击提供第一个分析框架。该框架是从网络安全的角度构建的,为对抗性攻击和防御提供生命周期。
说明
机器学习技术已被应用于广泛的场景,并取得了广泛的成功,尤其是在深度学习方面,它正迅速成为各种任务中的关键工具。然而,在许多情况下,机器学习或深度学习模型的失败可能会导致严重的安全问题。例如,在自动驾驶汽车中,无法识别交通标志可能会导致严重事故[1]。因此,在大规模部署之前,训练一个准确稳定的模型至关重要。不幸的是,近年来,许多研究揭示了模型安全中一个令人失望的现象,即深度学习模型可能容易受到对抗性示例的影响,即被对手恶意干扰的样本。以这种方式被篡改的模型很有可能会产生错误的预测,尽管它们可能在良性样本中显示出很高的准确性[2-5]。对抗性攻击可以被广泛定义为一类攻击,其目的是通过将对抗性示例插入训练阶段(称为中毒攻击[6-8])或推理阶段(称称为逃避攻击[2,3])来欺骗机器学习模型。无论哪种攻击都会显著降低深度学习模型的鲁棒性,并引发模型安全问题。此外,最近在现实世界中发现了深受这种模型安全问题困扰的深度学习解决方案的漏洞,这引发了人们对深度学习技术的信任程度的担忧
由于在深度学习技术的实际应用中,隐私和安全的潜在威胁多种多样,越来越多的组织,如ISO、IEEE和NIST,正在参与人工智能标准化的过程。对一些国家来说,这项工作被认为类似于一些国家的新基础设施建设[9]。ISO提出了一个关于人工智能系统生命周期的项目,该项目将技术的生命周期分为八个阶段,包括初始化、设计和开发、检查和验证、部署、运行监控、持续验证、重新评估和放弃[10]。本周期中没有进一步解决的是对抗性攻击如何阻碍深度学习模型的商业部署。因此,评估模型安全威胁是人工智能项目生命周期中的一个关键组成部分。此外,考虑到可能的对抗性攻击和防御的分散性、独立性和多样性,如何分析模型的安全威胁也应该标准化。迫切需要的是一个风险图,以帮助准确确定项目生命周期每个阶段的多种类型的风险。更严重的是,攻击的防御仍处于早期阶段,因此对更复杂的分析技术提出了更高的要求。
近年来,一些与对抗性机器学习相关的调查已经发表。Chakraborty等人[11]描述了安全相关环境中对抗性示例的灾难性后果,并回顾了一些强有力的对策。然而,他们的结论表明,它们都不能成为应对所有挑战的灵丹妙药。Hu等人[12]首先介绍了基于人工智能的系统的生命周期,用于分析每个阶段的安全威胁和研究进展。对抗性攻击分为训练和推理阶段。Serban等人[13]和Machado等人[14]分别回顾了在对象识别和图像分类中关于对抗性机器学习的现有工作,并总结了存在对抗性示例的原因。Serban等人[13]还描述了对抗性示例在不同模型之间的可转移性。与参考文献[14]提供设计防御的相关指导类似,Zhang等人[15]还从防御者的角度对相关工作进行了全面调查,并总结了深度神经网络对抗性示例起源的假设。还有一些关于对抗性机器学习在特定领域的应用的调查,如推荐系统[16]、网络安全领域[17]和医疗系统[18]。
[17]
先前已经观察到,在网络安全背景下,高级持续威胁(APT)通常是高度有组织的,成功的可能性极高[19]。以Stuxnet为例,这是最著名的APT攻击之一。它于2009年发射,摧毁了伊朗的核武器计划[19]。APT的工作流程系统地考虑了安全问题,这使得APT相关技术既能获得出色的成功率,即绕过这些防御,又能以高度有效的方式评估系统的安全性。受APT工作流程的启发,我们将此系统分析工具应用于网络安全问题,作为分析对抗性攻击威胁的潜在方法。APT主要由多种类型的现有底层网络空间攻击(如SQL注入和恶意软件)组成。不同类型的底层攻击的组合策略及其五阶段工作流程意味着,与单一攻击相比,APT的成功率极高。然而,有趣的是,根据现有的对抗性攻击策略,可以将其巧妙地划分为这五个阶段。基于这一观察,我们发现在评估对抗性攻击的威胁时,类似于APT的工作流程是有效的。因此,这构成了我们分析和对策框架的基础。尽管一些综述论文总结了模型安全方面的工作,但攻击方法或防御通常仍分为依赖类和分段类。这意味着不同方法之间的关系尚未明确确定。在这篇文章中,我们从APT的角度系统地对现有的对抗性攻击和防御进行了全面系统的回顾。我们的贡献如下:
- 我们提供了一个新颖的网络安全视角来研究深度学习的安全问题。我们首次提出将APT概念纳入深度学习中对抗性攻击和防御的分析中。其结果是为模型安全性提供了一个标准的类似APT的分析框架。与之前部分关注机制[13,20]、威胁模型[21]或情景[22]的调查不同,我们的工作可以为理解和研究这个问题提供全局和系统层面的视角。具体而言,先前的研究倾向于在小组中讨论具有类似策略的方法。分别研究了不同策略的对抗性攻击,忽略了不同攻击群之间的关系。相反,我们的工作将对抗性攻击视为一个全球系统,每一组具有相似策略的攻击都只是这个全球系统的一部分。与网络安全类似,考虑不同群体之间的关系有助于进一步提高攻击的有效性;
- 基于类似APT的分析框架,我们对现有的对抗性攻击方法进行了系统的审查。根据APT的逻辑,对抗性攻击可以明确地分为五个阶段。在每个阶段,都确定了共同的基本组成部分和短期目标,这有助于以深入的顺序提高攻击性能;
- 我们还回顾了在类似APT的分析框架内对对抗性攻击的防御。同样,防御分为五个阶段,提供自上而下的顺序来消除对抗性例子的威胁。可以识别不同阶段的防御方法之间的关系,从而激发一种可能的策略,将多种防御结合起来,为深度学习模型提供更高的鲁棒性
- 我们分别从数据和模型的角度总结了对抗性示例存在的假设,并全面介绍了对抗性机器学习中常用的数据集
我们希望这项工作能激励其他研究人员在系统层面上看待模型的安全风险(甚至隐私威胁),并在全球范围内评估这些风险。如果可以建立一个标准,那么各种财产,例如健壮性,就可以在更短的时间内更准确地访问。因此,用户对深度学习模型的信心将会增强。
二、相关研究
深度学习是指建立在深度神经网络(DNN)上的一组机器学习算法,已广泛应用于预测和分类等任务[21]。DNN是一种数学模型,包括具有大量计算神经元和非线性激活函数的多层。典型的深度学习系统的工作流程包括两个阶段:训练阶段和推理阶段。两个阶段的详细流程如下所示,如图1所示:

图1:深度学习系统的一般工作流程。在训练阶段,基于训练数据迭代更新参数θ。得到最佳参数θ后 , 在推理阶段,输入将被输入到经过训练的模型中,这将为决策提供相应的输出
在训练阶段,DNN的参数通过迭代前馈和反向传播不断更新。反向传播中的梯度下降方向是通过优化损失函数来引导的,该函数量化了预测标签和地面实况标签之间的误差。具体地,给定输入空间X和标签空间Y,最优参数θ 期望DNN f的损失函数L最小化训练数据集(X,Y)上的损失函数。因此,在训练过程中要找到最佳θ 可以定义为:
\[ \theta^{\star}=\underset{\theta}{\arg \min } \sum_{x_i \in \mathcal{X}, y_i \in \mathcal{Y}} \mathcal{L}\left(f_\theta\left(x_i\right), y_i\right) \]
其中fθ是要训练的DNN模型;xi∈X是从训练数据集中采样的数据实例,yi和fθ(xi)分别表示相应的地面真实标签和预测标签。
在推理阶段,训练的模型f 具有固定最优参数的θ 被应用来提供关于未被包括在训练数据集中的看不见的输入的决策。给定看不见的输入xj,可以通过单个前馈过程来计算相应的模型决策yj(即xj的预测标签):yj=f θ(xj)。值得注意的是,一次成功的对抗性攻击通常会在推理阶段导致被操纵的预测yõ,这可能与xj的正确标签相去甚远。
2.2 针对DNN的威胁模型
为了对这些攻击进行分类,我们通过引入模型攻击的关键组件来指定针对DNN的威胁模型。威胁被分解为三个维度:对手的目标、对手的特异性和对手的知识。这三个维度可以帮助我们识别潜在的风险,并了解对抗性攻击环境中的攻击行为。在图2中,我们概述了对抗性攻击中的威胁模型。

2.2.1 攻击目标
- 中毒攻击。在中毒攻击中,攻击者可以访问和修改训练数据集,以影响最终训练的模型[23-26]。攻击者在训练数据中注入假样本以生成有缺陷的模型的方式可以被视为“中毒”。中毒攻击通常会导致准确性下降[25]或对给定测试样本的错误分类[26]。•躲避攻击。
- 在规避攻击中,对手的目标是攻击训练有素且固定的DNN,而没有任何权限修改目标模型的参数[13,18,23]。通过这种方式,攻击者不再需要训练数据集的可访问性。相反,攻击者生成目标模型无法识别的欺骗性测试样本,以逃避最终检测[27,28]。
2.2.2 对抗性特异性
对抗性特异性的差异取决于攻击者是否能够在推理阶段为给定的对抗性样本预先定义特定的欺诈预测。
- 非目标攻击。在无目标攻击中,对手的唯一目的是欺骗目标模型生成错误预测,而不关心选择哪个标签作为最终输出[29-32]。
- 有针对性的攻击。在有针对性的攻击中,对于给定的样本,攻击者不仅希望目标模型做出错误的预测,而且还旨在诱导模型提供特定的错误预测[33-36]。一般来说,有针对性的攻击不会像无针对性的那样成功。
2.2.3 敌人的知识
- 白盒攻击。在白盒设置中,对手能够访问目标模型的细节,包括结构信息、梯度和所有可能的参数[30,34,37]。因此,对手可以通过利用手头的所有信息来精心制作对抗性样本。
- 黑匣子攻击。在黑盒设置中,攻击者在不了解目标模型的情况下实施攻击。攻击者可以通过与目标模型交互来获取一些信息[36,38,39]。这是通过将输入查询样本输入到模型中并分析相应的输出来完成的。
2.3 对抗性攻击
2.3.1 逃逸攻击
Szegedy等人[2]首先在对抗性攻击中引入了对抗性示例的概念,它可以在推理阶段以高成功率误导目标模型。他们提出了一种通过等式(1)搜索具有目标标签的最小失真对抗性示例的方法:
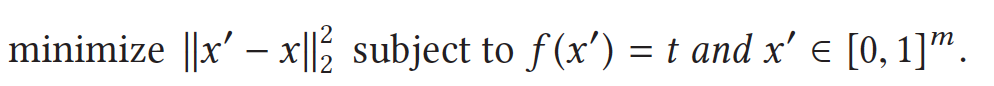
通过这个方程,他们可以找到最接近的x 通过最小化与良性样本x的距离 x − x 22,并且将被f(x)的条件错误地分类为目标标签t ) = 时间。这个问题可以导致方程(2)中的目标,该目标可以通过L-BFGS算法来解决:

2.3.2 投毒攻击
与推理攻击中发生的规避攻击不同,中毒攻击旨在通过污染训练数据来降低模型的准确性。攻击者需要一些权限来操纵训练数据,例如数据注入和数据修改[11]。因此,发起中毒攻击的目标可以分为两类:可用性违规和完整性违规。前者旨在降低受害者模型的置信度或准确性,破坏整个系统,而后者试图在不影响其他正常样本的情况下,通过引入后门,在某些特定样本上误导受害者模型[11]。具体而言,针对仅涉及训练样本的神经网络的中毒实例可以通过以下两种策略来制作:双层优化和特征碰撞[23]。
- 双层优化:修改数据的经典数据中毒可以形式化为双层优化问题[23]。然而,对于非凸神经网络,双层优化问题是棘手的。Mu~noz-Gonz´alez等人[24]提出了“反向梯度下降”来近似内部问题的解,然后对外部损失进行梯度下降,尽管这在计算上仍然很昂贵。为了加快中毒样品的生产,Yang等人[25]引入GAN来产生毒素。MetaPoison等人[26]也被提出作为一阶方法,使用集成策略近似解决生产毒药的双层优化。
- 特征冲突:基于双层优化的方法通常对迁移学习和端到端训练都有效,而特征冲突策略可以用于在有针对性的错误分类设置中设计针对迁移学习的有效攻击。例如,Shafahi等人[40]开发了一种方法,在特征空间中生成与目标样本相似的中毒样本,同时在输入空间中接近原始良性样本。这两类方法只需要操作训练的权限,而不需要标签,并且训练数据的语义将保持不变。这些带有干净标签的中毒样本将更难被检测到。
此外,除了仅操纵训练数据的中毒攻击外,另一种类型的中毒攻击是后门攻击,它需要在推理阶段向输入插入触发器的额外能力[23]。
后门攻击:后门攻击中的对手通常可以修改训练样本的标签[41]。这些带有后门触发器的错误标记数据将被注入到训练数据集中。因此,基于该数据集的训练模型将被迫为新样本(使用触发器)分配所需的目标标签。大多数后门攻击都需要在制作毒药的过程中给训练样本贴上错误的标签,而这些毒药更有可能被防御者识别出来。因此,还提出了一些干净标签后门攻击[42],并使用参考文献[40]中提出的特征碰撞策略来制作后门样本。
2.4 Advanced Persistent Threats
高级持久性威胁(APT)是一系列新定义的攻击过程,其中攻击是长时间连续的,例如数年。分析APT的工作流程构成了我们对抗性攻击和防御分析框架的基础。