工业落地-Sophos《Learning from Context: Exploiting and Interpreting File Path Information for Better Malware Detection》
Learning from Context: Exploiting and Interpreting File Path Information for Better Malware Detection
- https://ai.sophos.com/presentations/learning-from-context-a-multi-view-deep-learning-architecture-for-malware-detection/
用于静态可移植可执行(PE)恶意软件检测的机器学习(ML)通常使用每个文件的数字特征向量表示作为训练期间一个或多个目标标签的输入。然而,可以从查看文件的上下文中收集到许多正交信息。在本文中,我们建议使用静态上下文信息源(PE文件的路径)作为分类器的辅助输入。虽然文件路径本身不是恶意或良性的,但它们确实为恶意/良性判断提供了有价值的上下文。与动态上下文信息不同,文件路径的可用开销很小,并且可以无缝集成到多视图静态ML检测器中,在非常高的吞吐量下产生更高的检测率,同时基础结构的更改也很小。在这里,我们提出了一种多视图神经网络,它从PE文件内容以及相应的文件路径中提取特征向量作为输入并输出检测分数。为了确保真实的评估,我们使用了大约1000万个样本的数据集—来自实际安全供应商网络的用户端点的文件和文件路径。然后,我们通过LIME建模进行可解释性分析,以确保我们的分类器已学习到合理的表示,并查看文件路径的哪些部分对分类器得分的变化贡献最大。我们发现,我们的模型学习了文件路径的有用方面以进行分类,同时还学习了测试供应商产品的客户的工件,例如,通过下载恶意软件样本目录,每个样本都命名为其哈希。我们从我们的测试数据集中删减了这些工件,并证明在10−3假阳性率(FPR),10时为33.1%−4 FPR,基于类似拓扑的单输入PE文件内容模型。
摘要
用于恶意软件检测的机器学习(ML)分类器通常在进行恶意/良性判断时使用每个文件内容的数字表示。然而,也可以从文件所在的上下文中收集相关信息,这些信息通常被忽略。 上下文信息的一个来源是文件在磁盘上的位置。例如,如果检测器可以清楚地利用有关其所在路径的信息,则伪装为已知良性文件(例如Windows系统DLL)的恶意文件更有可能显得可疑。了解文件路径信息还可以更容易地检测那些试图通过将自己放置在特定位置来逃避磁盘扫描的文件**。文件路径也可以使用,开销很小,并且可以无缝集成到多视图静态ML检测器中,在非常高的吞吐量和最小的基础结构更改下,可能产生更高的检测率。
在这项工作中,我们提出了一种 multi-view 深度神经网络结构,该结构将PE文件内容中的特征向量以及相应的文件路径作为输入并输出检测分数。我们对大约1000万个样本的商业规模数据集进行了评估,这些样本是来自实际安全供应商提供服务的用户端点的文件和文件路径。然后,我们通过LIME建模进行可解释性分析,以确保我们的分类器已学习到合理的表示,并检查文件路径如何在不同情况下改变分类器的分数。我们发现,与只对PE文件内容进行操作的模型相比,我们的模型学习了文件路径的有用方面,在0.001假阳性率(FPR)下,真阳性率提高了26.6%,在0.0001 FPR下,提高了64.6%。
keyword : 静态PE检测、文件路径、深度学习、多视图学习、模型解释
一、说明
商用便携式可执行(PE)恶意软件检测器由静态和动态分析引擎组成。静态检测通常首先用于标记可疑样本,它可以快速有效地检测大部分恶意软件。它涉及分析磁盘上的原始PE映像,可以非常快速地执行,但易受代码混淆技术的影响,例如压缩和多态/变形转换[1]。相比之下,动态检测需要在模拟器中运行PE,并在运行时分析行为[2]。当动态分析工作时,它不太容易受到代码混淆的影响,但与静态方法相比,它需要更大的计算容量和执行时间。此外,有些文件很难在仿真环境中执行,但仍然可以进行静态分析。因此,静态检测方法通常是端点恶意软件预防(在执行恶意软件之前阻止恶意软件)管道中最关键的部分。最近,由于采用了机器学习,静态检测方法的性能有所提高[3],其中高度表达的分类器(例如深层神经网络)适合于数百万个文件的标记数据集。训练这些分类器时,它们使用静态文件内容作为输入,但不使用辅助数据。然而,我们注意到,由于辅助数据(例如网络流量、系统调用等),动态分析工作得很好。在这项工作中,我们试图使用文件路径作为正交输入信息来增强静态ML检测器。文件路径是静态可用的,无需操作系统的任何附加工具。通过将文件路径作为辅助输入,我们希望能够将有关文件的信息与在特定位置看到此类文件的可能性的信息结合起来,并识别与已知恶意软件和良性文件相关的常见目录层次结构和命名模式。
静态检测:通用模块,快速有效地标记可疑样本;易受代码混淆技术(压缩和多态/变形转换)的影响。
[1] A. Moser, C. Kruegel, and E. Kirda, “Limits of static analysis for malware detection,” in Twenty-Third Annual Computer Security Applications Conference (ACSAC 2007). IEEE, 2007, pp. 421–430.
动态检测:分析模块,需要更大的计算容量和执行时间;有些文件很难在仿真环境中执行。
我们将分析重点放在三个模型上:
- 仅基线文件内容(PE)模型,仅将PE功能作为输入并输出恶意软件置信度得分。
- 另一个基准文件路径仅内容(FP)模型,仅将文件的文件路径作为输入,并输出恶意软件置信度得分。
- 我们提出的多视图PE文件内容+上下文文件路径(PE+FP)模型,该模型同时考虑PE文件内容特征和文件路径,并输出恶意软件置信度得分。
三个模型的示意图如图1所示。

我们对从一家大型反恶意软件供应商的遥测数据中收集的时间分割数据集进行分析,发现我们在文件内容和上下文文件路径上训练的分类器在ROC曲线上,尤其是在低误报率(FPR)区域,产生了统计上显著更好的结果。
本文的贡献如下:
- 我们从安全供应商的客户端点(而不是恶意软件/供应商标签聚合服务)获得一组真实、精心策划的文件和文件路径数据集。
- 我们证明,我们的多视图PE+FP恶意软件分类器在我们的数据集上的性能明显优于单独使用文件内容的模型。
- 我们将本地可解释模型不可知解释(LIME)[4]扩展到PE+FP模型,并使用它分析文件路径如何影响模型的恶意/良性决策。
[4] M. T. Ribeiro, S. Singh, and C. Guestrin, “Why should i trust you?: Explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2016, pp. 1135–1144.
本手稿的其余部分结构如下:第二节涵盖重要的背景概念和相关工作。第三节讨论数据集收集和模型制定。第四节将我们的新多视图方法与拓扑结构相似的纯内容基线模型进行了比较,并对我们的模型进行了可解释性分析。第五节结束。
二、背景和相关工作
在本节中,我们将描述机器学习如何普遍应用于静态PE检测,以及我们的方法如何通过提供上下文信息作为辅助输入而在高层意义上有所不同。然后,我们介绍了其他机器学习领域的相关工作。
2.1 静态ML恶意软件检测
机器学习已经应用于计算机安全领域多年了[5],但在商业规模上使用ML的静态PE模型的破坏性性能突破是一个较新的现象。商业模型通常依赖深度神经网络[6]或增强的决策树集合[7],并已扩展到其他静态文件类型,包括web内容[8]、[9]、office文档[10]和档案[10]。
大多数用于信息安全的静态ML(ML-Sec)分类器操作的是文件部分(例如,标题)上的学习嵌入[11],整个文件上的学习嵌入[12],或者最常见的是,操作的是设计用于总结每个文件内容的预设计数字特征向量[6]、[13]–[19]。预先构建的特征向量表示往往更具可伸缩性,可以快速从每个文件中提取内容,同时保留有用的信息。有很多方法可以构建特征向量,包括在滑动窗口上跟踪每字节统计信息【6】、【18】、字节直方图【7】、【18】、ngram直方图【13】、将字节视为图像中的像素值(文件内容的可视化)【13】、【18】、操作码和函数调用图统计信息【18】、符号统计信息【18】、哈希/数字元数据值【6】、【7】、【18】–例如。,入口点作为文件的一部分,或散列导入和导出,以及分隔标记的散列[10]、[19]。在实际应用中,从文件内容中提取的几种不同类型的特征向量通常连接在一起,以获得优异的性能。
2.2 Learning from Multiple Sources
使用深度神经网络进行静态ML恶意软件检测的相关研究已经检验了从多个信息源学习的方法,但这些方法与我们的方法有根本不同:Huang等人【20】和Rudd等人【21】对多个辅助损失函数使用多目标学习【22】,【23】,他们发现这些函数在主要恶意软件检测任务中的性能有所提高。这两项工作都在培训期间使用元数据作为辅助目标标签,为模型提供额外的信息,并在部署时使用单个输入来做出分类决策。我们的方法利用了多种输入类型/模式——一种是以类似于[6]的PE特征向量的形式描述恶意样本的内容,另一种是将原始字符串提供给一个字符嵌入层(类似于[8]),该层提供了有关该样本出现位置的信息。这种技术是一种多视图学习方法[24]。顾名思义,多视图学习的大多数应用都是在计算机视觉中进行的,在计算机视觉中,多个视图实际上是由来自不同输入摄像头/传感器的视图或来自同一摄像头/传感器在不同时间的不同视图组成的。在ML-Sec空间中,我们只能找到两种专门将自己称为多视图的方法:即[25],Narayanan等人将多内核学习依赖图应用于Android恶意软件分类,以及[26],Bai等人将多视图集合用于PE恶意软件检测。虽然这些方法在某些方面与我们的方法相似,但据我们所知,我们是第一个在商业规模上使用外部上下文反馈到深层神经网络并结合文件内容特征来执行恶意软件检测多视图建模的方法。
[25] A. Narayanan, M. Chandramohan, L. Chen, and Y. Liu, “A multi-view context-aware approach to android malware detection and malicious code localization,” Empirical Software Engineering, pp. 1–53, 2018.
[26] J. Bai and J. Wang, “Improving malware detection using multi-view ensemble learning,” Security and Communication Networks, vol. 9, no. 17, pp. 4227–4241, 2016.
三、实施细节
在本节中,我们将介绍我们的方法的实现细节,包括从客户端点获取PE文件和文件路径的数据收集过程、我们的特征化策略以及我们的多视图深度神经网络和比较基线的体系结构。
3.1 数据集
在我们的实验中,我们从一家著名反恶意软件供应商的遥测数据中收集了三个不同的数据集:一个训练集、一个验证集和一个测试集。培训集由9148143个样本组成,这些样本首次出现在2018年6月1日至11月15日之间,其中693272个样本被标记为恶意样本。验证集包括在2018年11月16日至12月1日期间观察到的2225094个不同样本,其中85041个被标记为恶意样本。最后,测试集在2019年1月1日至1月30日期间共有249783个样本,其中38767个被标记为恶意。这些文件的恶意/良性标签是使用类似于[6]、[8]的标准计算的,但结合其他专有信息可以生成更准确的标签。
3.2 特征工程
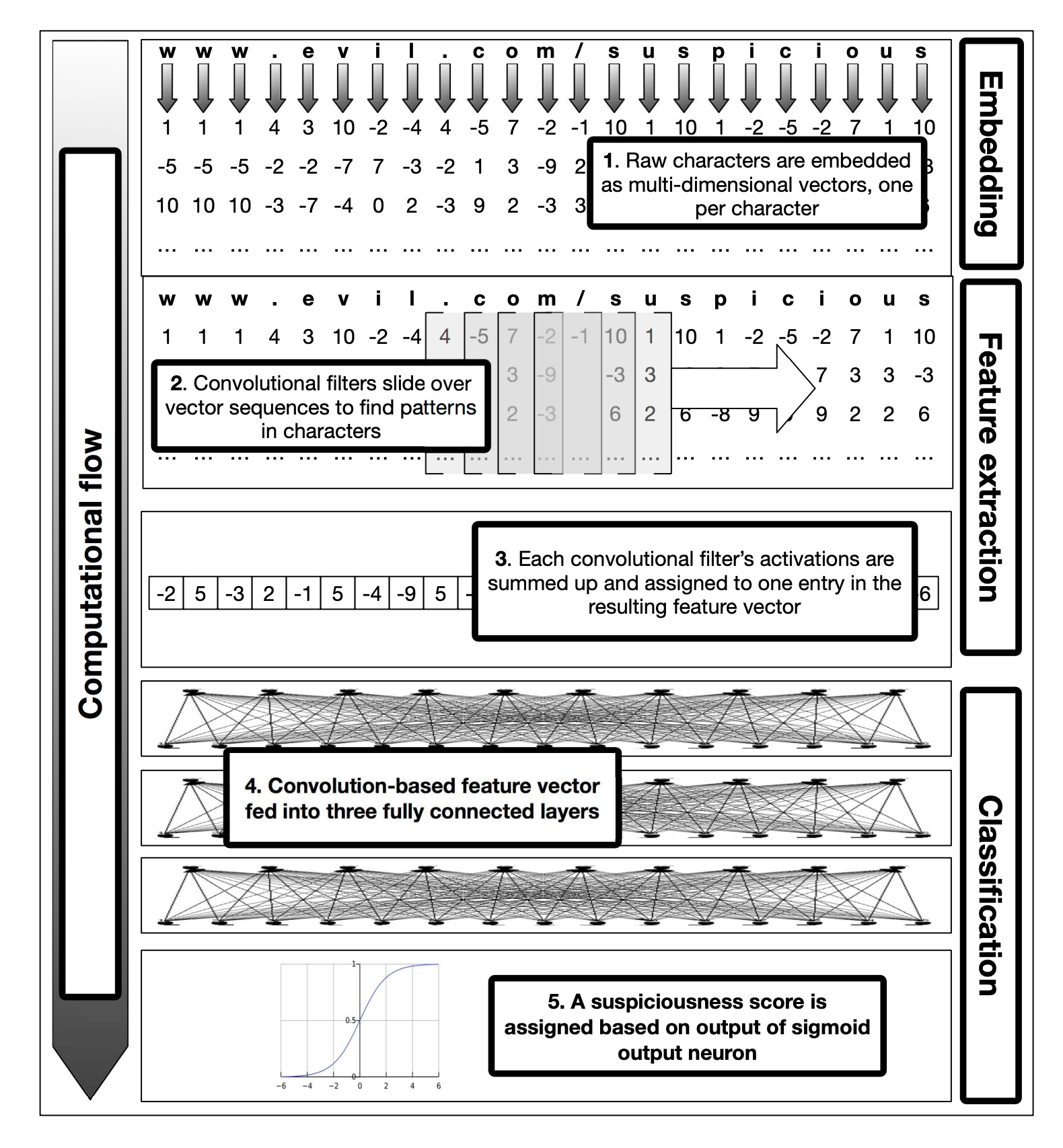
为了使用文件路径作为神经网络模型的输入,我们首先将可变长度字符串转换为固定长度的数字向量。我们使用类似于[8]的矢量化方案来实现这一点,方法是在每个字符上创建一个键控的查找表,该表用一个表示每个字符的数值(介于0和字符集大小之间)来表示。实际上,我们将此表实现为Python字典。在遥测和早期实验数据的指导下,我们将文件路径缩减到最后100个字符。短于100个字符的文件路径的功能用零填充。对于字符集,我们考虑整个Unicode字符集,但将词汇限制为150个最常见的字符。见附录??供进一步讨论。作为PE文件内容的特征,我们使用了由四种不同特征类型组成的浮点1024维特征向量,类似于[6]。总的来说,我们将每个样本表示为两个特征向量:1024维的PE内容特征向量和100维的上下文文件路径特征向量。
[8] J. Saxe and K. Berlin, “expose: A character-level convolutional neural network with embeddings for detecting malicious urls, file paths and registry keys,” arXiv preprint arXiv:1702.08568, 2017.
3.3 网络体系结构
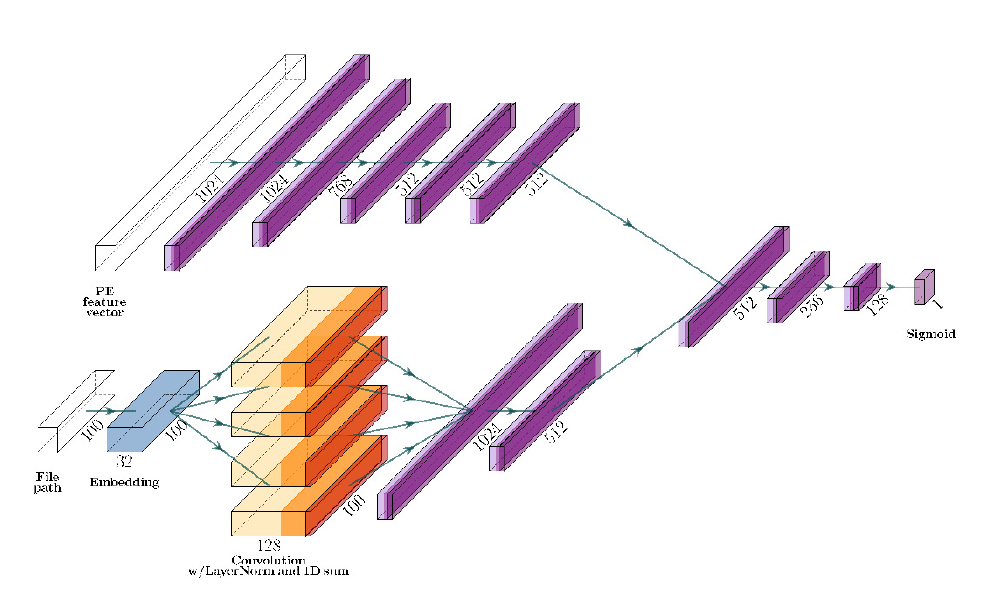
我们的多视图体系结构如图2所示。该模型有两个输入,1024个元素的PE内容特征向量xPE和100个元素的文件路径整数向量xFP,如第III-B节所述。每个不同的输入分别通过一系列具有各自参数θPE和θFP的层,用于PE特征和FP用于文件路径特征,并在训练期间联合优化。然后将这些层的输出连接(串联)并通过一系列最终隐藏层,即参数θO的联合输出路径。网络的最终输出由密集层和sigmoid激活组成。
- PE 特征:PE输入臂θPE使xPE通过一系列块,每个块由四层组成:一个完全连接的层,一个使用[27]中所述技术实现的层规范化层,一个丢失概率为0.05的丢失层,以及一个校正线性单元(ReLU)激活。其中五个块依次连接,密集层大小分别为1024、768、512、512和512个节点。
- 文件路径:
- 文件路径输入arm θFP 将 xFP(长度为100的向量)传递到嵌入层 ???
- 该嵌入层将文件路径的每个字符转换为32维向量,从而为整个文件路径生成100x32的嵌入张量。
- 然后将该嵌入馈入4个单独的卷积块,其中包含一个具有128个滤波器的1D卷积层、一个层归一化层和一个1D求和层,以将输出平坦化为向量。4个卷积块包含卷积层,卷积层的大小分别为2、3、4和5,用于处理2、3、4和5克的输入文件路径。
- 然后将这些卷积块的平坦输出串联起来,作为大小为1024和512个神经元的两个密集块的输入(与PE输入臂中的形式相同)。
- 输出层:PE arm和文件路径arm的完全连接块的输出随后被连接并传递到由θO参数化的联合输出路径。该路径由层大小为512、256和128的密集连接块(与PE输入arm中的形式相同)组成。然后将这些块的128D输出馈送至致密层,该致密层将输出投射至1D,然后进行sigmoid激活,以提供模型的最终输出。
仅PE模型只是PE+FP模型,但没有FP臂,输入xPE并拟合θPE和θO参数。类似地,FP模型是PE+FP模型,但没有3个授权的许可PE arm,采用输入xFP拟合θFP和θO参数。适当调整输出子网络的第一层,以匹配前一层的输出。我们使用二进制交叉熵损失函数拟合所有模型。给定标签为y的输入x的深度学习模型f(x;θ)的输出∈ {0,1},模型参数θ损失为:

通过优化器,我们求解ˆθ的最佳参数集,以最小化数据集上的组合损失:

其中M是数据集中的样本数,y(i)和x(i)分别是第i个训练样本的标签和特征向量。我们使用Keras框架构建和训练模型,使用Adam优化器和Keras的默认参数和1024个小批量。每个模型都经过15个阶段的训练,我们确定这些阶段足以使结果收敛。
4、实验分析

5、总结
我们已经证明,深度神经网络恶意软件检测器可以从合并来自文件路径的上下文信息中获益,即使这些信息本身不是恶意或良性的。将文件路径添加到我们的检测模型中不需要任何额外的端点检测,并且在整个相关FPR区域的总体ROC曲线中提供了统计上显著的改善。我们直接在客户端点分布上测量模型的性能这一事实表明,我们的多视图模型实际上可以部署到端点以检测恶意软件。我们在第IV-B节中进行的LIME分析表明,多视图模型能够提取暗示实际恶意/良性概念的上下文信息;不只是数据集的统计伪影,尽管正如我们所观察到的,它还可以学习这些伪影。除了端点部署之外,这项研究可以应用的另一个潜在领域是端点检测和响应(EDR)环境,在该环境中,我们的模型的输出可以用于根据事件的可疑程度对磁盘上的事件进行排序。有趣的是,石灰等技术在这方面也有应用。使用从LIME或类似方法得出的解释,可以创建分析工具,允许非恶意软件/取证专家的用户执行某种程度的威胁搜寻。如图4所示,重要性突出显示不仅对用户有用,而且是最近邻/相似性可视化方法的替代方法,该方法不会显示其他用户的潜在可识别信息(PII)。