风控算法(4)特征工程-变量加工实践经验
特征工程-风控变量加工实践经验
风控变量加工实践经验 - 求是汪在路上的文章 - 知乎 https://zhuanlan.zhihu.com/p/479784293
本文总结了风控变量开发过程中的一些实践经验。包括:
- 检查数据一致性,确保数据质量。
- 设计好整体架构,提高计算效率。
我们总在说,数据决定特征的上限,特征决定模型的上限。风控决策过程中依托大量变量,这些变量从开发到上线的研发流程如下:
- 风控模型同学先基于离线数据源使用Hive SQL挖掘一系列变量,经过建模筛选后将变量需求提给开发同学。
- 开发同学与模型同学一起核对数据源以及变量实现逻辑,将每个变量用Java代码实现。
- 在线灰度运行,与离线Hive T+1产出的变量以及模型分数做一致性比对,满足较高的一致性和稳定性后才最终发布。
一、线上线下底层数据一致
底层数据一致是最根本的要求,其内涵包括两点:
- 线上数据落快照,确保可回溯、不穿越。
- 线上数据经清洗到线下数据后确保一致。
1. 线上数据落快照,确保可回溯、不穿越。
数据资产非常宝贵,一些内部数据早点落快照积累,后期才能进行回溯。在这个过程中,数据穿越问题是最为常见的,其导致的结果是离线分析效果可能很棒,但真正上线后效果一塌糊涂。因此,在做特征变量时都要限制数据采集时间在回溯时点之前。
2. 线上数据经清洗到线下数据后确保一致。
线上数据一般是json这类的半结构化数据,为了离线分析时使用方便,我们通常将其解析为结构化的数据表。因此,在此转换过程中,有可能会出现字段取值错列、错误等情况,需要进行一致性检查。
二、离线变量加工注意事项
在平时业务实践中,我们习惯利用SQL来衍生特征变量,原因在于:
- SQL可分布式计算,对于海量数据处理上效率更高。
- SQL语法较为固定,容易阅读理解;而Python语法灵活,每个人写的代码风格差异很大,较难维护理解。
- SQL有大量内置函数(聚合函数、窗口函数等),可省去很多自定义函数的时间。
但是,在开发过程中需要注意以下几点:
1. 检查原始字段的取值类型。对于字符型变量,直接比较时容易出错,如下所示。例如,字符串类型的1000会比800小。因此,在聚合计算风控变量"最近N个月的最大借款金额"时就会出错。
1 | spark-sql> select '1000' > '800'; |
2. 检查原始字段的取值范围。避免想当然地认为,该变量什么含义就"应该"是什么取值,或者完全按照编码文档来写逻辑,一切以实际数据为准。包括但不限于:
- 确认字段正常不应该缺失的情况,确认是否实时数据落库过程中清洗所引起的。
- 从业务上检查字段含义对应的取值范围,确认脏数据该如何清洗。例如,对于日期类变量,其取值可能有如下格式:
1 | datetime.datetime.strptime(date, "%Y-%m-%d %H:%M:%S") |
3. 适当定义一些中间变量。其好处在于:
- 统一维护映射关系,便于维护修改变量口径;
- 提高计算效率,一次计算可复用,不必多次重复运算;
- 便于代码review,结构层次上更为清晰易懂。
中间变量适合需要利用多个字段来定义的场景,或者一个字段需要进行较为复杂的计算。例如:
1 | case when recall_date > due_date and repay_date = due_date then "已到期,正常还款" |
对于多人协作的项目,需要大家约定好中间变量口径,避免后续整理文档时出现类似的变量多种口径,引起IT同学混淆。
4. 适当制作一些中间表
其作用在于,采取最小可用数据范围原则,减少计算成本。例如:计算借据层面的字段"最近3个月内的借款次数",只需要用到借据表的信息,并不需要还款计划表的信息。
5. 确认每张表的主键,保证唯一
SQL中常见的聚合函数包括最大值(max)、最小值(min)、平均值(avg)、计数(count)、标准差(std)、累加(sum)。如果数据记录出现重复,虽然不会影响max、min这些操作,但是会影响其他聚合计算的值。因此,在做中间表的过程中需要明确主键,确保group by分组的时候是唯一的。
6. 优化SQL代码,提高运行效率。
例如,count(distinct case when 条件 then xxx else xxx end)操作需要消耗大量资源,可以考虑将when中的条件提前到表的where中,过滤减少数据量,但要注意影响范围,避免误伤到其他变量的计算。
同时,还可以将SQL代码做成工作流(workflow),某些任务可实现并行化运行。
三、实时变量上线比对验证
实时变量计算有时效性要求,比如500毫秒内计算出数据。因此,实时变量一般将由IT同学根据文档通过Java开发,在此过程中由于以下原因可能引起变量不一致。
- 离线变量开发口径逻辑,在文档整理过程中的表述歧义。
- 模型同学和IT同学沟通过程中的理解差异。
- Java代码编写过程中存在的Bug。
- 计算引擎不同所引起的精度差异。
- 脏数据引起的不一致。
为解决SQL离线变量到在线变量之间的翻译工作,目前有相关的实时SQL计算引擎技术,可参考下面这篇:
https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s/Rx43XfhgdwerQWLn1eI3Ww
线上线下变量确保一致是非常重要的。其能保证基于离线批量数据所建立的风控模型和策略规则,在上线后能按照预期的效果生效。如果不一致,将会导致风控系统不可控。例如,离线评估得到的模型分数阈值为低于600分则拒绝,但线上模型总是和离线有偏差,600这个阈值将拒绝更多的用户,导致通过率下降。
模型同学需要和IT同学协调来定位变量问题,整个工作流程图如下所示。可以看到这是一个闭环迭代的过程,如何加快迭代速度成为关键。
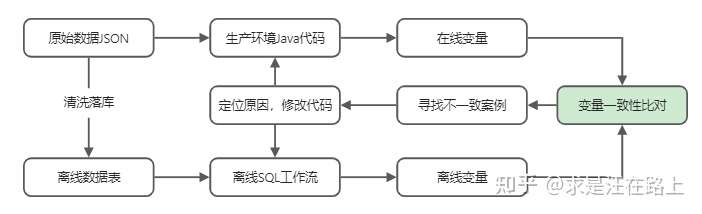
变量一致性比对的逻辑很直接,其依赖于测试数据来归纳排查,当两者出现不一致则必有问题。当然,变量的逻辑正确性和取值一致性是两回事,逻辑正确性需要业务知识来确认,取值一致性需要技术工具来解决。
为了尽可能提高比对效率,笔者有以下几点建议:
1)准备足量测试原始数据,以及离线变量取值结果。在开发过程中准备一批(如1000条)原始数据json,这批数据必须保证和解析到数据库中的表数据是完全一致的。这样可以确保IT同学在写Java的时候,就可自己测试来消除一部分bug,减少后续工作量。
2)提前准备好相关不一致案例,预约时间集中排查。定位问题是一个非常耗时的工作,因此和IT同学约定好大片段的时间,提前准备好一些案例来沟通。案例准备过程可以将变量划分类别,聚类治之可极大提高效率。
3)整理比对所需要的代码脚本,缩短数据准备时间。比对过程是迭代中完善的,必然需要多轮数据拉取、计算、整理的工作,把这个流程打通形成工作流可加快速度。
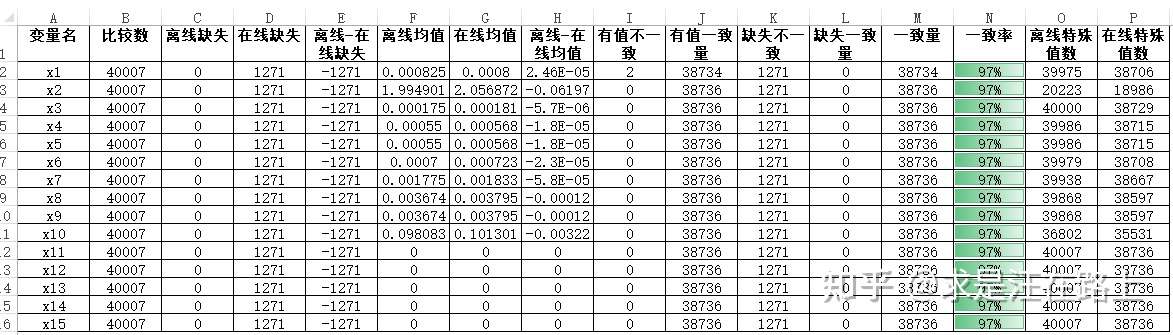
在取数得到线上线下数据集后,可根据附录代码计算得到以下比对报告,如图2所示。我们将比对结果分为以下4种情况:
- 有值且一致:有值并且满足精度一致要求
- 有值不一致:有值但不满足精度一致要求
- 缺失不一致:其中有一个为null
- 缺失且一致:两者取值都为null
对于情况1)和情况3)则需要查相应案例来定位原因。小细节往往能发现大问题,所以不要轻视。
附录A
1 | import pandas as pd |