恶意加密流量(2)Datacon2021恶意加密流量检测
Datacon2021 网络流量分析 Writeup
一、恶意流量分析
1.1 比赛题目
本题文件中提供了一段时间的失陷主机的通讯流量,参赛选手需审计该流量包,进行追踪溯源,找到真正的恶意服务器,最终获取key,此外本题还设有可以获得额外分数的彩蛋题目。
以主机端的网络流量为基础,通过流量审计和主动探测的方式,对攻击者进行追踪溯源和行为分析。
二、恶意攻击指令识别
1.2 比赛题目
本题中提供了一段时间的失陷主机的通讯流量和单个指令的流量样本的提供给参算选手,参赛选手需通过恶意软件通讯特征筛选出恶意流量,并通过提供的单一的下发指令流量作为样本,分析出通讯流量(http、dns、https)中下发的指令序列。
域前置技术:
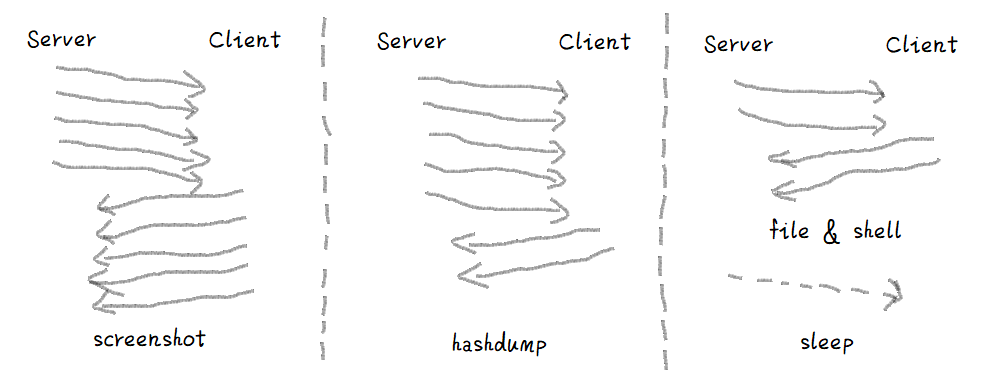
各命令对应的数据流也有不同的特征。比如,screen 命令会有来自服务端和客户端双向的大流量,hash命令有来自服务端的大流量和客户端的小流量,sleep 命令仅有get数据包,没有post数据包等,如图所示。
三、加密代理流量分析
3.1 比赛题目-阶段一 【流量审计】
本题中,管理员获取了内网中由数个不明用户构建的加密代理节点,这些软件使用的通信协议不完全一致,管理员只分别提取了一定数量的样本。参赛选手需要通过不同的加密代理特征,按照样本对目标流量进行分类。
概述:本题共有11个加密代理。对应11个类别,其中11个类别共包含带标签样本51个。无标签样本1000个,需要们通过分析51个带有标签样本,找到11个类别所对应的具体的特征,从而对1000个测试样本进行分类。
由于此题类别数目较少,只有圱圱个类别,且每个类别对应的带标签样本数目也很少,因此我们采取规则匹配的方法来实现分类。我们的实验框架如图所示。
首先通过分析不同的类别特征制定每个类别对应的规则,从1000个测试样本的pcap包里根据规则从提取相应的数据,继而基于这些数据进行匹配分类。最终对于极少数没有匹配结果的样本,采用人工审查的方式进行分类。值得注意的是,由于同一个样本可能满足多个类别的特点,所以不同类别的规则匹配顺序会对分类结果有一定影响。
3.1.1 加密代理特点分析
加密流量的特征一般包含协议特征、数据元统计特征。尤其应该注意TLS协议的流量特点。
对于恶意加密流量和良性加密流量的区别,cisco的研究表明【6】显示,对于TLS协议特征,在ClientHello数据包中,恶意软件提供于普通客户端完全不同的一组密码套件,此外,这些密码套件通常很脆弱或已经过时。相比之下,几乎所有良性应用程序都提供相同的密码套件。除此之外,恶意软件通常提供很少的扩展,而正常用户最多有9个拓展。此外客户端的公钥长度也存在很大的差异。在ServerHello和Certificate中,恶意软件查询的服务器会选择不常见的密码套件,因为优先提供的密码套件的大小受到限制。此外,证书的有效期和SAN条目数量也存在区别,而且恶意服务器发送自签名证书的比例也比普通服务器高一个数量级。
对于数据元统计特征,恶意流量于良性流量的特征差异主要表现在数据信息、数据包的大小、到达时间序列和字节分布等。
3.1.2 特征分析与规则制定
基于上述加密代理的特点, 我们分析 51 个带标签的样本, 并着重关注了 TLS 特征。我们对协议信息、TLS 应用数据、TLS 握手信息、数据信息、数据 包大小等特征进行了分析, 找到了有效区分的方法。
其中有三个类别有明显的区别, 只关注协议信息即可区分开来
- 类别 0 对应的 pcap 包所有的通信流量只包含 UDP 协议, 而在 11 个类别中, 只有类别 0 具有此特点。
- 类别 6 中, 发现只有类别 6 的流量中同时出现了 TCP 和 UDP 协议, 此外, 只有类别 6 中出现了 OCSP 协议。
- 类别 8 中, 我们发现了 WireGuard 协议, WireGuard 是一种 VPN 协议, 它的大量出现使得类别 8 的特 征变得明显。通过以上方法, 我们可以通过协议信息将类别 0、类别 6、类别 8 区分出来。
剩下的 8 类需要我们做进一步区分, 我们发现类别 4、类别 5、类别 7、类别9 的通信流量中只包含 TCP 协议, 类别 1、类别 2、类别 3、类别 10 的通信流量 由 TCP+TLS 协议组成。
到了此时, 我们的进度开始变得缓慢, 因为剩下的 8 类 没有很明显的区分特征。但是在我们的不觖努力下, 我们逐渐有了突破, 我们 发现:
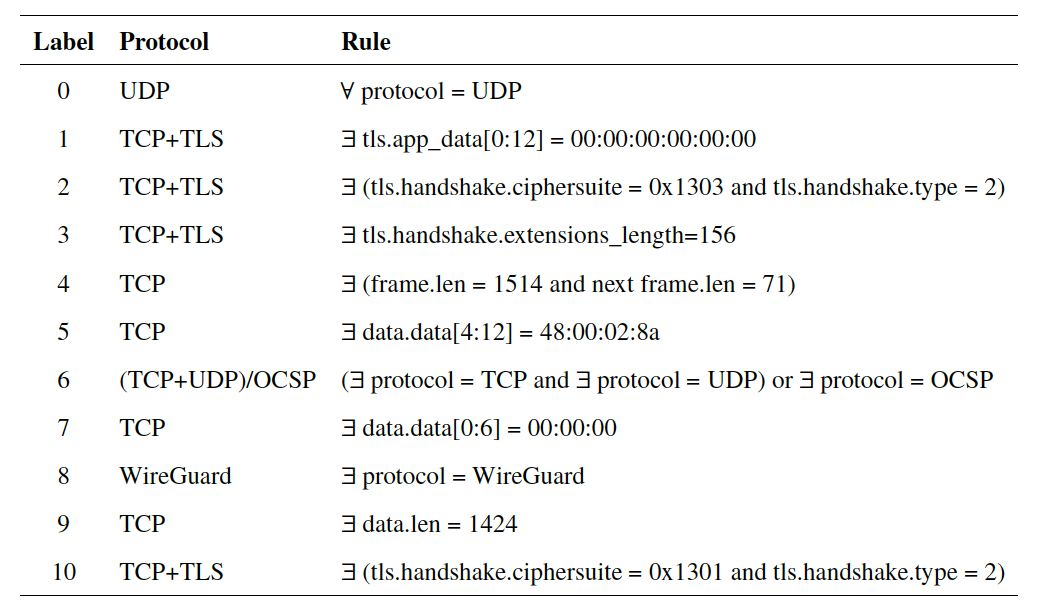
- 在类别 1 中, 存在 tls.app_data 字段的前 12 位为 00:00:00:00:00:00 的流量, 如图3.2所示;
- 在类别 7 中, 存在 data.data 字段的前 6 位为 00:00:00 的 流量;
- 在类别 5 中, 存在 data.data 字段的第 5 位到第 12 位为 \(48: 00: 02: 8 \mathrm{a}\) 的 流量, 如图3.3所示;
- 在类别 3 中, 存在 tls.handshake.extensions_length 字段值 为 156 的流量; 在类别 10 中, 存在 tls.handshake.ciphersuite 值为 \(0 \times 1301\) 并且 tls.handshake.type 值为 2 的流量;
- 在类别 2 中, 存在 tls.handshake.ciphersuite 值为 0x1303 并且 tls.handshake.type 值为 2 的流量;
- 在类别 4 中, 存在 frame.len 值为 1514 和 71 的流量, 值得注意的是, 当出现 frame.len 为 1514 时, 通常下一 条流量的 frame.len 为 71 ;
- 在类别 9 中, 存在 data.len 的值为 1424 的流量。 综上所述, 我们可以通过以上方法将 11 个类别区分出来, 文字描述略显繁 杂, 表3.1展示了我们制定的匹配规则。
3.2 比赛题目-阶段二
同一代理协议、少量样本标签
身份不明的用户或恶意软件可能使用未授权的加密代理进行通信,访问恶意网站或正常网站。确认这些行为的详细信息有利于对可疑用户行为和恶意软件进行分析,但截获的加密流量无法进行破解。
本题中,管理员使用机器自动产生了恶意软件与多个恶意网站(或正常网站)通信产生的,经过加密代理的流量。根据已知的信息,管理员提取了一部分可以确定类别的样本信息。参赛选手需要利用管理员生成的样本,标记每个流量包可能访问站点的标签。
3.2.1 概述
题目主要考察加密流量识别能力,需要选手根据提供的已知类别样本,识别测试数据可能可能访问何种恶意站点。经过对题目和数据的初步分析,我们发现所 提供加密流量数据均由同一加密代理软件产生,且数据包中并未观测到特殊应用层协议可供分析。因此,我们确定了从统计特征和行为特征两个角度角度对加密流量样本进行审计分析,深入挖掘标识访问不同恶意通信流量的有效特征,从而实现对恶意流量的自动化分类的基本思路。
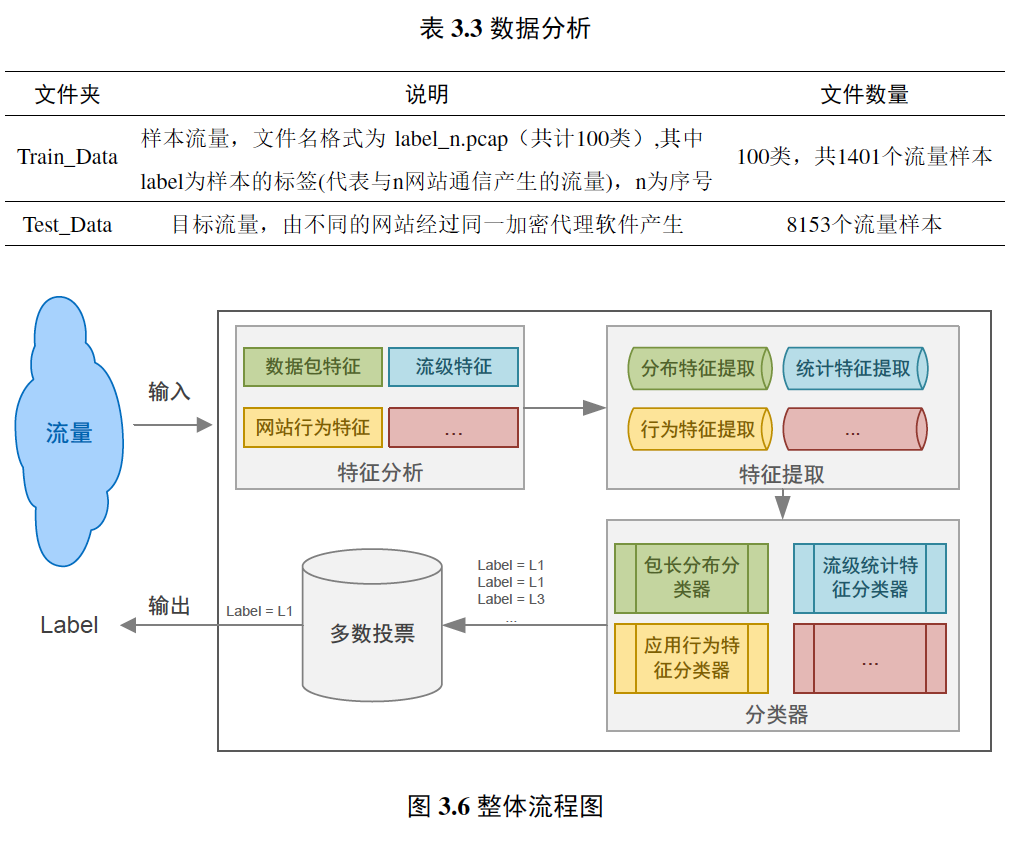
图3.6展示了我们方案的整体流程。具体来讲,我们分别提取训练样本的多维统计特征及标识行为特征的包长序列特征,分别构建分类器,基于投票机制结合多维分类结果来获得最终判定结果,从而避免异构数据混淆和权重问题带来的误分类情况。接下来我们将分别介绍我们所采用的特征及对应的分类器、实现和性能以及展望和总结。
3.2.2 结题思路
数据分析:拿到数据后我们首先对提供的训练样本和测试样本进行初步分整理分析;train_data文件夹中,
共包含1401个流量样本,除第85类只有2个样本,29、52、94只有6个样本,平均每个家族都有13-15个样本。下面我们将详细介绍六个参与投票的子模型中的每一个模型所采用的特征及对应的分类器,以及设计的动机和意义。
(1)数据包特征
由于网络中不同的服务商提供的服务不同,导致数据流中的==数据分组大小==存在一定的差异,如流媒体的数据分组较小以提高播放流畅度而文件下载通常是以最大的负载进行传输[7]。由于数据分组大小与网络服务有关且不受加密技术的影响,因此可以根据数据分组的分布对加密流量进行识别。
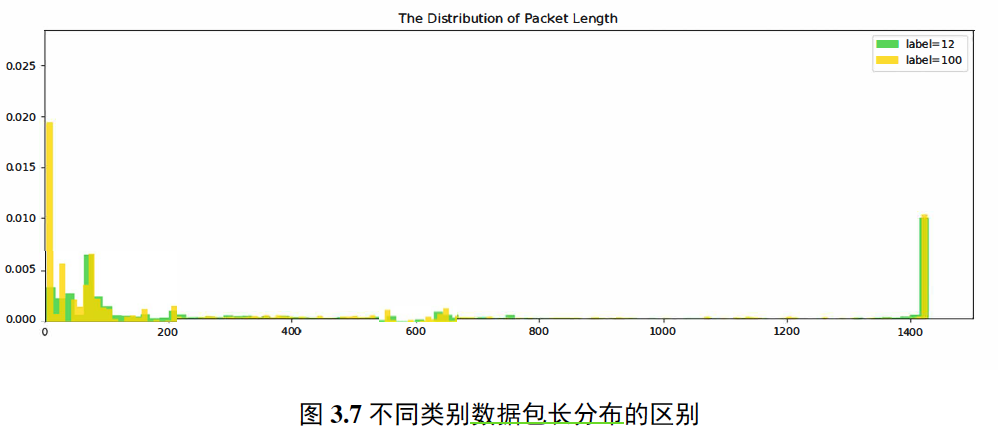
我们根据方向的不同,首先针对每个pacp文件分别提取前向包有效负载长度序列和后向有效负载长度序列。然后每个序列分别提取方差、均值、四分位值、众数、平均数、最大值等特征从而描述分布特点。
由于包长分布的特征本质上是一个离散概率分布,特征值之间的差值可以很好的描述不同分布之间的差异,因此我们选择基于欧拉距离度量的KNN分类算法。KNN通过测量不同特征值之间的距离来讲待检测样本分类到训练样本之中,因此并不适用于特征维度过高的数据,我们所提取的圱圲维特征可以较好地应用于此。
(2) 流级特征
根据五元组(源IP、目的IP、源端口,目的端口,协议)划分得到的会话数据能够最大程度的保留客户端和服务端之间的通信特征信息,因此成为了流量分析领域常用的分析对象[8].通信双方的 会话级别的统计特征能够很好的反映不同类型应用的属性。
- 恶意通信往往具有持续时间短、传输速率快、出入站比例大等特点;
- 正常流量则往往具有持续时间长、包长分布均匀、数据包到达间隔稳定、出入站比例较小等特点。
本题中提供的加密流量只是对数据包的载荷进行加密,对流的特征属性的影响较小,因此可以根据流量的属性如间隔时间,报文大小,流持续时间等提取相应的流量特征,根据流量特征准确的识别出访问不同网站的加密流量的类别。如图所示,为题目提供训练样本中不同类别的加密流量在流级统计特征上的分布差异。

提取方式:
我们利用SplitCap工具按照(源IP、目的IP、源端口, 目的端口, 协议)五元组将提供的训练和测试数据分别拆分成单独的会话, 并过滤掉末完成三次握手的会话。我们认为末完成三次握手的会话可能是由于抓包或是题目设定原因出现了截断, 而这种不完整的会话若何混合在其他完整的会话中一同提取统计特征, 将会使特征变得混淆而不可用。因此我们从全部切分得到的46,667个会 话文件中过滤后得到可用于特征提取和模型训练的 22,211 条完整会话。
SplitCap划分pcap文件:将pcap拆分为较小pcap的文件。
在确定并获得训练数据后, 我们直接实现了从原始报文数据中的流量特征提取, 没有依赖tshark等第三方工具。具体来讲, 我们基于 python和dpkt库,直接将pcap文件作为二进制流读取并依据协议解析每个字段, 从而计算80+维的会 话统计特征。具体使用特征如表3.4所示:

dpkt:
scapy:
joy:
特征提取后, 我们选择XGBoost作为流级特征的分类算法。XGBoost (eXtreme Gradient Boosting)是基于Boosting框架的一个算法工具包 (包括工程实现), 在 并行计算效率、缺失值处理、预测性能上都非常强大。同时基于树的方法可以 直接对特征重要性进行评分, 这对于后续挑选重要特征、降低特征维度、删除冗余特征十分方便,同时还可以对max_depth参数进行限制防止特征过于细化和线性相关带来的过拟合风险。
(3) 网站行为特征
由于本题数据说明提到所有样本均由同一加密代理生成,差异在于访问了不同的目标网站。而恶意网站由于其目的和功能的不同,在通信过程中往往存在特定的通信模式和规律,通过分析比较有效负载长度序列的异同,可有效定位不同类别的访问流量【9】
与流级特征中提取的包长统计特征不同,该部分重点关注的是序列特征,通过数据包长度的时序性交错变化来反映不同网站的应用和业务特征。在加密代理不变且网站业务功能稳定的情况下,利用基于包长序列的网站应用行为特征进行加密网站流量分类具备相当的稳定性和精确度。
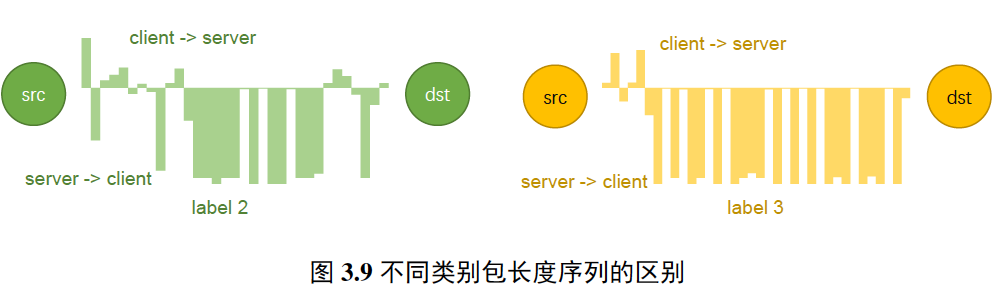

为证明该特征的有效性, 我们先将序列长度窗口设定为 11 , 在 1401 个训练样本中获得了1396个样本所包含的独特包长序列, 并基于匹配的强规则确定4734个样本的标签。此次提交获得了55.18分, 即提交内容获得了94%左右的 正确率,从根本上证明该特征的有效性。
在获得以上的验证结果后,我们开始思考如何将以上的匹配规则“软化” 成机器学习可以处理的形式。我们希望能够兼顾包长序列在莫以类别的出现频 率和 “特异程度”, 结合以往课程和信息检索相关知识,
我们想到了 TF-IDF(term frequency-inverse document frequency) 技术。即将包长序列视为 \(i\) tem, 拼接后形成 对应该类别的 “文档”, 随后基于tf-idf思想, 计算每个item的出现频率tf和特异性程度idf, 两者结合后用来代表该类别的特征向量。在本题提供的数据中, 我们共得到了1306维的特征, 也就是说1396的训练样本和8109的测试样本, 共出 现不同的包长序列1306个。
在获得特征向量后, 我们依然选择了在前面就已经取得良好表现的梯度提升树算法一XGBoost作为该部分的子分类器。主要是考虑到该部分特征向量维 度较高, 且容易出现过拟合的问题。因此, 我们在设定树模型的超参数时, 集中 调整了如max_depth、colsample_bytree、subsample以及eta、lambda、alpha等 控制数据采样和正则化程度的超参数。
3.2.3 结果验证与评估
我们基于 python的sklearn和dpkt库实现了相应的机器学习模型和特征提取。 由于所提供数据包规模不大, dpkt并为遇到内存爆炸无法打开的情况, sklearn中 所包含的KNN模型和XGBoost模型则均采用之前多次试验得到的较好的超参数设置。而且在流级特征分类时, 我们基于XGBoost树模型特有的特征重要度评分功能, 进行了一定程度的特征选择, 最终得到了纬度较低且精确度较高的模型作为最终使用的判定模型。
给予我们的多级别特征提取和分类器投票结果, 提交多次后发现并末达到理想的分数。因此后期我们又基于KNN算法和tf-idf特征进行进一步分类, 将多 个模型判定结果均相同的 2270 个测试样本提取出来补充相对较少的训练样本集 重新训练各部分子分类器, 最终达到了87分的结果。