Pytorch(8)模型构建-池化-线性-激活
[PyTorch 学习笔记] 池化层、线性层和激活函数层
一、池化层
池化的作用则体现在降采样:保留显著特征、降低特征维度,增大 kernel 的感受野。 另外一点值得注意:pooling 也可以提供一些旋转不变性。 池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度并在一定程度上避免过拟合的出现;一方面进行特征压缩,提取主要特征。
1.1 nn.MaxPool2d() 最大池化
1 | nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False) |
这个函数的功能是进行 2 维的最大池化,主要参数如下:
- kernel_size:池化核尺寸
- stride:步长,通常与 kernel_size 一致
- padding:填充宽度,主要是为了调整输出的特征图大小,一般把 padding 设置合适的值后,保持输入和输出的图像尺寸不变。
- dilation:池化间隔大小,默认为 1。常用于图像分割任务中,主要是为了提升感受野
- ceil_mode:默认为 False,尺寸向下取整。为 True 时,尺寸向上取整
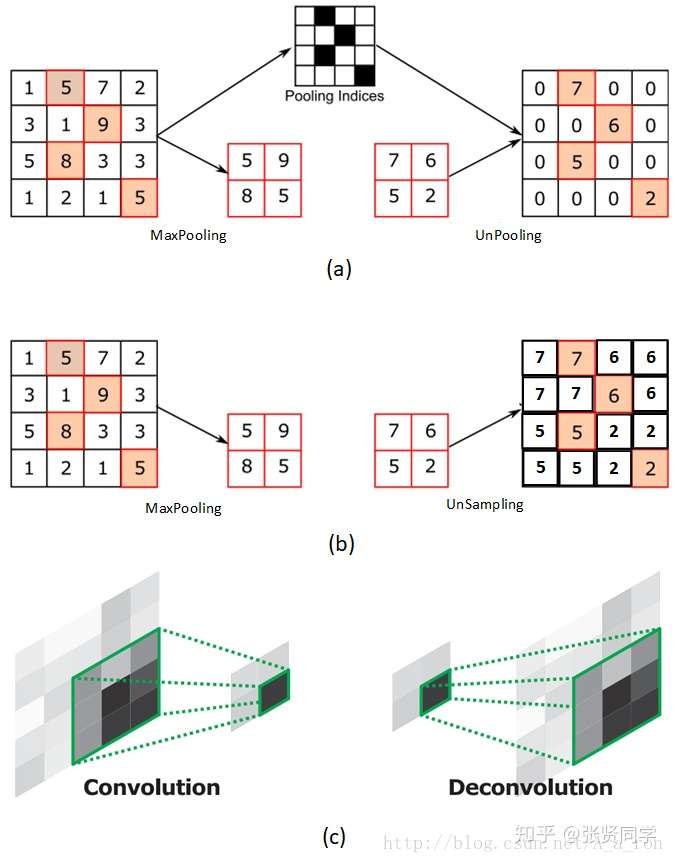
- return_indices:为 True 时,返回最大池化所使用的像素的索引,这些记录的索引通常在反最大池化时使用,把小的特征图反池化到大的特征图时,每一个像素放在哪个位置。
下图 (a) 表示反池化,(b) 表示上采样,(c) 表示反卷积。
1 | torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None) |
这个函数的功能是进行 2 维的平均池化,主要参数如下:
- kernel_size:池化核尺寸
- stride:步长,通常与 kernel_size 一致
- padding:填充宽度,主要是为了调整输出的特征图大小,一般把 padding 设置合适的值后,保持输入和输出的图像尺寸不变。
- dilation:池化间隔大小,默认为 1。常用于图像分割任务中,主要是为了提升感受野
- ceil_mode:默认为 False,尺寸向下取整。为 True 时,尺寸向上取整
- count_include_pad:在计算平均值时,是否把填充值考虑在内计算
- divisor_override:除法因子。在计算平均值时,分子是像素值的总和,分母默认是像素值的个数。如果设置了 divisor_override,把分母改为 divisor_override。
1 | img_tensor = torch.ones((1, 1, 4, 4)) |
1.3 nn.MaxUnpool2d() 最大值反池化
1 | nn.MaxUnpool2d(kernel_size, stride=None, padding=0) |
功能是对二维信号(图像)进行最大值反池化,主要参数如下:
- kernel_size:池化核尺寸
- stride:步长,通常与 kernel_size 一致
- padding:填充宽度
二、 线性层
线性层又称为全连接层,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换。
1 | inputs = torch.tensor([[1., 2, 3]]) |
输出为:
1 | tensor([[1., 2., 3.]]) torch.Size([1, 3]) |
三、激活函数层
假设第一个隐藏层为:,第二个隐藏层为:
,输出层为:
如果没有非线性变换,由于矩阵乘法的结合性,多个线性层的组合等价于一个线性层。激活函数对特征进行非线性变换,赋予了多层神经网络具有深度的意义。下面介绍一些激活函数层。
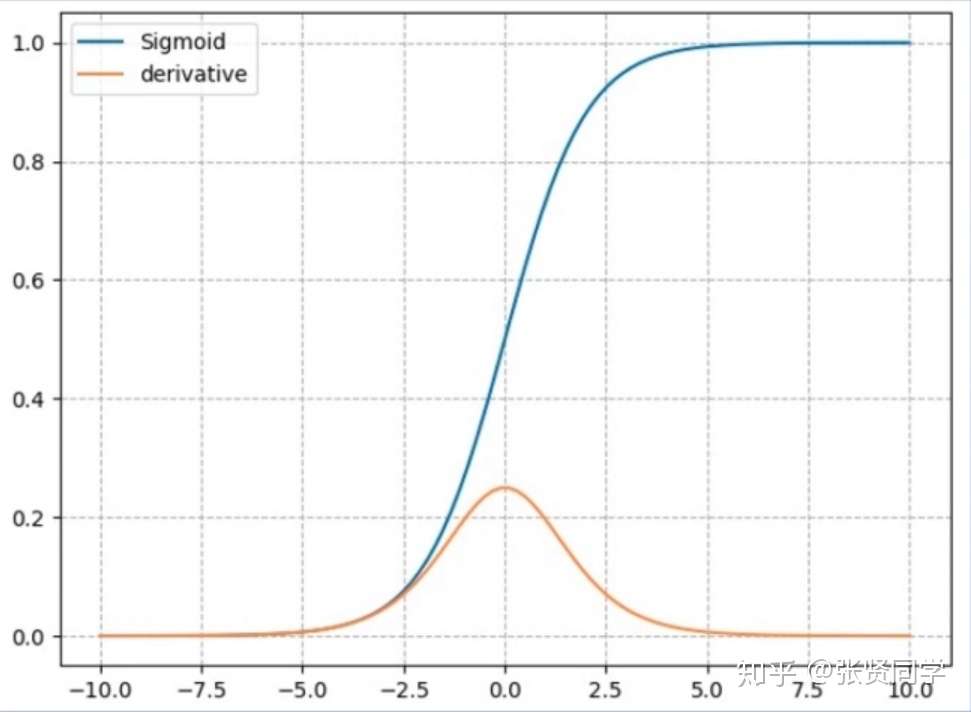
3.1 nn.Sigmoid
计算公式:
梯度公式:
特性:
- 输出值在(0,1),符合概率
- 导数范围是 [0, 0.25],容易导致梯度消失
- 输出为非 0 均值,破坏数据分布
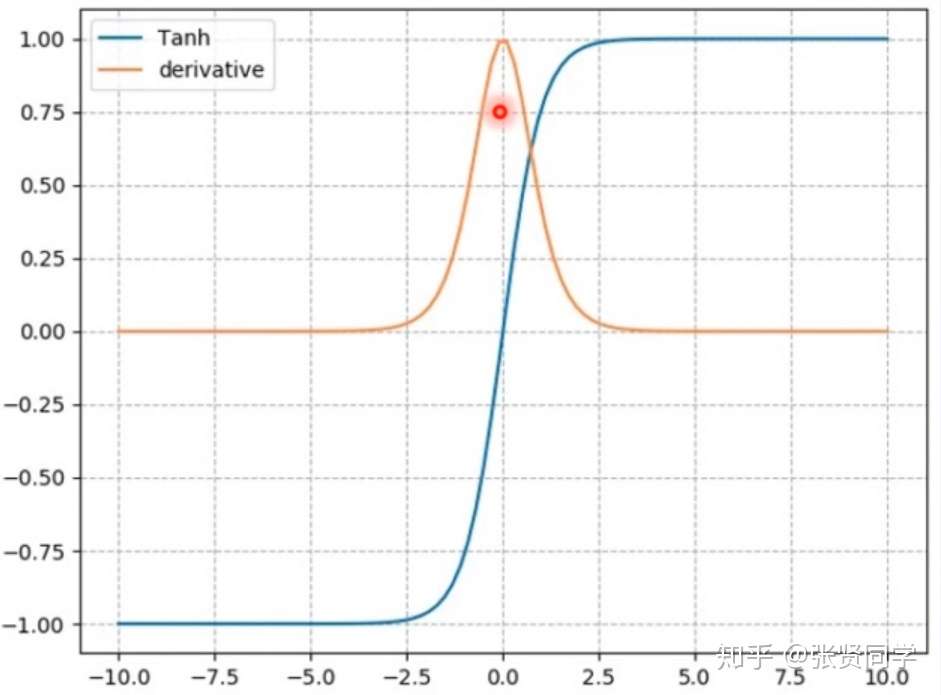
3.2 nn.tanh
计算公式:
梯度公式:
特性:
- 输出值在(-1, 1),数据符合 0 均值
- 导数范围是 (0,1),容易导致梯度消失
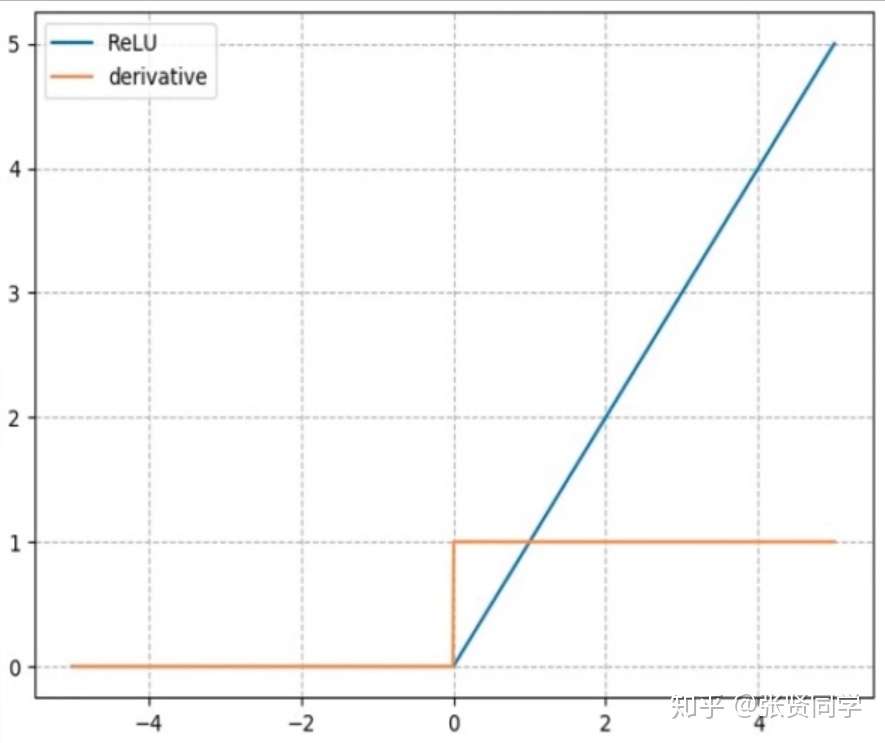
3.3 nn.ReLU(修正线性单元)
计算公式:
梯度公式:
特性:
- 输出值均为正数,负半轴的导数为 0,容易导致死神经元
- 导数是 1,缓解梯度消失,但容易引发梯度爆炸
针对 RuLU 会导致==死神经元==的缺点,出现了下面 3 种改进的激活函数。
nn.LeakyReLU
- 有一个参数
negative_slope:设置负半轴斜率
nn.PReLU
- 有一个参数
init:设置初始斜率,这个斜率是可学习的
nn.RReLU
R 是 random 的意思,负半轴每次斜率都是随机取 [lower, upper] 之间的一个数
- lower:均匀分布下限
- upper:均匀分布上限