Pytorch(15)模型Finetune
[PyTorch 学习笔记] 模型 Finetune【微调】
迁移学习:把在 source domain 任务上的学习到的模型应用到 target domain 的任务。
Finetune 就是一种迁移学习的方法。比如做人脸识别,可以把 ImageNet 看作 source domain,人脸数据集看作 target domain。通常来说 source domain 要比 target domain 大得多。可以利用 ImageNet 训练好的网络应用到人脸识别中。
对于一个模型,通常可以分为前面的 feature extractor (卷积层)和后面的 classifier,在 Finetune 时,通常不改变 feature extractor 的权值,也就是冻结卷积层;并且改变最后一个全连接层的输出来适应目标任务,训练后面 classifier 的权值,这就是 Finetune。通常 target domain 的数据比较小,不足以训练全部参数,容易导致过拟合,因此不改变 feature extractor 的权值。
Finetune 步骤如下:
获取预训练模型的参数
使用
load_state_dict()把参数加载到模型中修改输出层
固定 feature extractor 的参数。这部分通常有 2 种做法:
- ==固定卷积层的预训练参数。可以设置
requires_grad=False或者lr=0==
- ==固定卷积层的预训练参数。可以设置
- 可以通过
params_group给 feature extractor ==设置一个较小的学习率==
- 可以通过
不使用 Finetune
第一次我们首先不使用 Finetune,而是从零开始训练模型,这时只需要修改全连接层即可:
1 | # 首先拿到 fc 层的输入个数 |
训练了 25 个 epoch 后的准确率为:70.59%。训练的 loss 曲线如下:
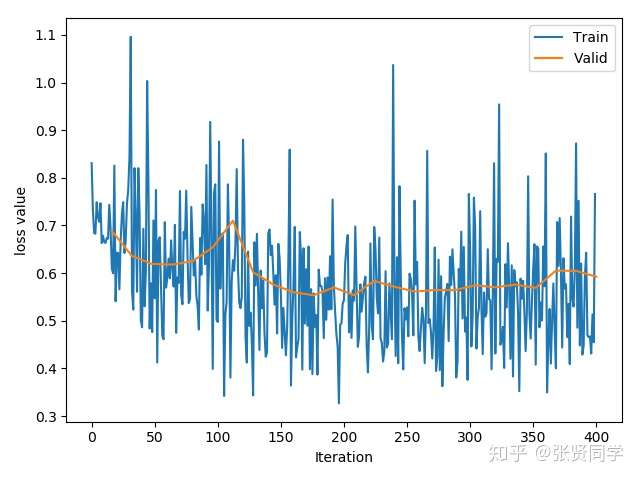
使用 Finetune, 不冻结卷积层
然后我们把下载的模型参数加载到模型中:
1 | path_pretrained_model = enviroments.resnet18_path |
训练了 25 个 epoch 后的准确率为:96.08%。训练的 loss 曲线如下:
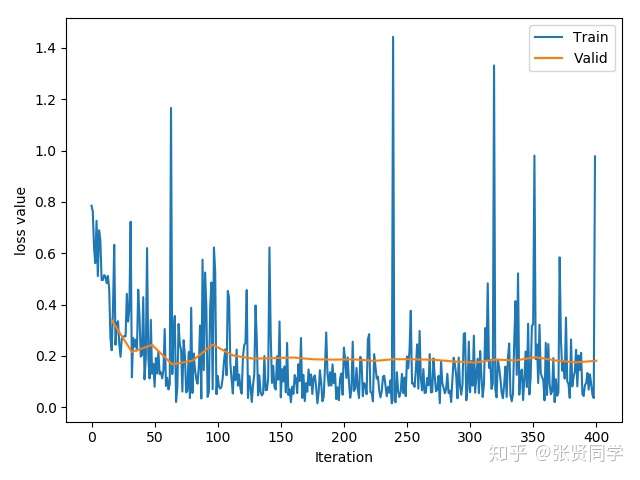
使用 Finetune、 冻结卷积层
设置requires_grad=False这里先冻结所有参数,然后再替换全连接层,相当于冻结了卷积层的参数:
1 | for param in resnet18_ft.parameters(): |
使用 Finetune、设置学习率为 0
这里把卷积层的学习率设置为 0,需要在优化器里设置不同的学习率。首先获取全连接层参数的地址,然后使用 filter 过滤不属于全连接层的参数,也就是保留卷积层的参数;接着设置优化器的分组学习率,传入一个 list,包含 2 个元素,每个元素是字典,对应 2 个参数组。其中卷积层的学习率设置为 全连接层的 0.1 倍。
1 | # 首先获取全连接层参数的地址 |
使用分组学习率、对卷积层使用较小的学习率
这里不冻结卷积层,而是对卷积层使用较小的学习率,对全连接层使用较大的学习率,需要在优化器里设置不同的学习率。首先获取全连接层参数的地址,然后使用 filter 过滤不属于全连接层的参数,也就是保留卷积层的参数;接着设置优化器的分组学习率,传入一个 list,包含 2 个元素,每个元素是字典,对应 2 个参数组。其中卷积层的学习率设置为 全连接层的 0.1 倍。
1 | # 首先获取全连接层参数的地址 |