线性模型(2)逻辑回归
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。Logistic 回归的本质是:假设数据服从这个Logistic分布,然后使用极大似然估计做参数的估计。
逻辑回归的思路是,先拟合决策边界(不局限于线性,还可以是多项式),再建立这个边界与分类的概率联系,从而得到了二分类情况下的概率。
一、逻辑回归 【深度学习的组成单元】
1.1 Logistic 分布 [位置参数、形状参数]
分布函数: 【Softmax函数、对数几率函数】 \[ F(x)=P(X \leq x)=\frac{1}{1+e^{-(x-\mu) / \gamma}} \]
密度函数: \[ f(x)=F^{\prime}(X \leq x)=\frac{e^{-(x-\mu) / \gamma}}{\gamma\left(1+e^{-(x-\mu) / \gamma}\right)^{2}} \]
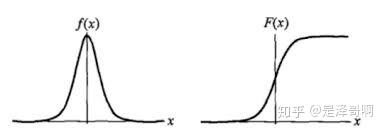
其中, \(\mu\) 表示位置参数, \(\gamma>0\) 为形状参数。
Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似, 但是 Logistic 分布的尾部更长, 所以我们可以使用 Logistic 分布来建模比正态分布具有更长尾部和更高波峰的数据分布。在深度学习中常用到的 Sigmoid 函数就是 Logistic 的分布函数在 \(\mu=0, \gamma=1\) 的特殊形式。
决策边界可以表示为 \(w_1 x_1+w_2 x_2+b=0\) ,假设某个样本点 \(h_w(x)=w_1 x_1+w_2 x_2+b>0\) 那么可以判断它的 类别为 1 , 这个过程其实是感知机。
1.2 Logistic 回归
Logistic 回归还需要加一层, 它要找到分类概率 \(P(Y=1)\) 与输入向量 \(x\) 的直接关系, 然后通过比较概率值来判断类 别。考虑到 \(w^T x+b\) 取值是连续的, 因此它不能拟合离散变量。可以考虑用它来拟合条件概率 \(p(Y=1 \mid x)\), 因 为概率的取值也是连续的。
最理想的是单位阶跃函数:
\[ p(y=1 \mid x)=\left\{\begin{array}{ll}0, & z<0 \\ 0.5, & z=0 \\ 1, & z>0\end{array}, \quad z=w^{T} x+b\right. \]
但是这个阶跃函数不可微, 对数几率函数是一个常用的替代函数: \[ y=\frac{1}{1+e^{-\left(w^T x+b\right)}} \]
\[ \ln \frac{y}{1-y}=w^{T} x+b \]
我们将 \(\mathrm{y}\) 视为 \(\mathrm{x}\) 为正例的概率, 则 1- \(\mathrm{y}\) 为 \(\mathrm{x}\) 为其反例的概率。两者的比值称为几率 (odds), 指该事件发生与不 发生的概率比值, 若事件发生的概率为 \(\mathrm{p}\) 。则对数几率: \[ \ln (o d d s)=\ln \frac{y}{1-y} \] 将 \(\mathrm{y}\) 视为类后验概率估计, 重写公式有: \[ \begin{aligned} & w^T x+b=\ln \frac{P(Y=1 \mid x)}{1-P(Y=1 \mid x)} \\ & P(Y=1 \mid x)=\frac{1}{1+e^{-\left(w^T x+b\right)}} \end{aligned} \]
也就是说,输出 Y=1 的对数几率是由输入 x 的线性函数表示的模型,这就是逻辑回归模型。当 \(w^T x+b\)的值越接近正无穷,\(P(Y=1 \mid x)\) 概率值也就越接近 1。因此逻辑回归的思路是,先拟合决策边界(不局限于线性,还可以是多项式),再建立这个边界与分类的概率联系,从而得到了二分类情况下的概率。
在这我们思考个问题,我们使用对数几率(sigmod)的意义在哪?通过上述推导我们可以看到 Logistic 回归实际上是使用线性回归模型的预测值逼近分类任务真实标记的对数几率,其优点有:【无假设分布?得到概率、易求解】
Sigmoid 函数到底起了什么作?
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线性)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
线性回归是在实数域范围内进行预测,而分类范围则需要在 [0,1],逻辑回归减少了预测范围;线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性。
无需实现假设数据分布:直接对分类的概率建模,从而避免了假设分布不准确带来的问题(区别于生成式模型);
不仅可预测出类别,还能得到该 预测的概率,这对一些利用概率辅助决策的任务很有用;
对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解。
1.3 代价函数
逻辑回归模型的数学形式确定后,剩下就是如何去求解模型中的参数。在统计学中,常常使用极大似然估计法来求解,即找到一组参数,使得在这组参数下,我们的数据的似然度(概率)最大。设: \[ \begin{aligned} & P(Y=1 \mid x)=p(x) \\ & P(Y=0 \mid x)=1-p(x) \end{aligned} \] 似然函数: \[ L(w)=\prod\left[p\left(x_i\right)\right]^{y_i}\left[1-p\left(x_i\right)\right]^{1-y_i} \] 为了更方便求解,我们对等式两边同取对数,写成对数似然函数: \[ \begin{aligned} L(w) & =\sum\left[y_i \ln p\left(x_i\right)+\left(1-y_i\right) \ln \left(1-p\left(x_i\right)\right)\right] \\ & =\sum\left[y_i \ln \frac{p\left(x_i\right)}{1-p\left(x_i\right)}+\ln \left(1-p\left(x_i\right)\right)\right] \\ & =\sum\left[y_i\left(w \cdot x_i\right)-\ln \left(1+e^{w \cdot x_i}\right)\right] \end{aligned} \] 逻辑回归模型中,我们最大化似然函数和最小化损失函数实际上是等价的。我们对预测结果的概率表示取似然函数,取似然函数就是将模型对样本的概率预测值累乘起来。得到如下的似然函数由于该式比较麻烦涉及连乘法,所以我们对其去对数操作得到对数似然函数。
\[ l(\theta)=\log L(\theta)=\sum_{i=1}^m\left(y^{(i)} \log h_\theta\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right)\right) \]
上述利用的是最大似然估计原理:极大似然估计就是就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大。
当似然函数求得最大值时,模型能够最大可能的满足当前的样本,求最大值使用梯度向上法,我们可以对似然函数加个负号,通过求等价问题的最小值来求原问题的最大值,这样我们就可以使用极大似然估计法。
令: \[ J(\theta)=-\frac{1}{m} l(\theta) \] 这样我们就能得到损失函数的最终形式 \[ J(\theta)=-\frac{1}{m} \sum_{i=1}^n\left(y^{(i)} \log h_\theta\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right)\right) \] 化简得: \[ =-\frac{1}{m} \sum_{i=1}^m\left[y^{(i)} \theta^T x^{(i)}-\log \left(1+e^{\theta^T x^{(i)}}\right)\right] \]
1.4 求解【 梯度下降 和 牛顿法 】
求解逻辑回归的方法有非常多,我们这里主要聊下梯度下降和牛顿法。优化的主要目标是找到一个方向,参数朝这个方向移动之后使得损失函数的值能够减小,这个方向往往由一阶偏导或者二阶偏导各种组合求得。逻辑回归的损失函数是:
\[ J(w)=-\frac{1}{n}\sum_{i=1}^n\left(y_i \ln p\left(x_i\right)+\left(1-y_i\right) \ln \left(1-p\left(x_i\right)\right)\right) \]
- 随机梯度下降
梯度下降是通过 J(w) 对 w 的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为: \[ \begin{gathered}g_i=\frac{\partial J(w)}{\partial w_i}=\left(p\left(x_i\right)-y_i\right) x_i \\ w_i^{k+1}=w_i^k-\alpha g_i\end{gathered} \]
其中 k 为迭代次数。每次更新参数后,可以通过比较梯度下降小于阈值或者到达最大迭代次数来停止迭代。
求导:
\[ \begin{aligned} & \frac{\partial}{\partial \theta_j} J(\theta)=\frac{\partial}{\partial \theta_j}\left(\frac{1}{m} \sum_{i=1}^m\left[\log \left(1+e^{\theta^T x^{(i)}}\right)-y^{(i)} \theta^T x^{(i)}\right]\right) \\ & =\frac{1}{m} \sum_{i=1}^m\left[\frac{\partial}{\partial \theta_j} \log \left(1+e^{\theta^T x^{(i)}}\right)-\frac{\partial}{\partial \theta_j}\left(y^{(i)} \theta^T x^{(i)}\right)\right] \\ & =\frac{1}{m} \sum_{i=1}^m\left(\frac{x_j^{(i)} e^{\theta^T x^{(i)}}}{1+e^{\theta^T x^{(i)}}}-y^{(i)} x_j^{(i)}\right) \\ & =\frac{1}{m} \sum_{i=1}^m\left(h_\theta\left(x^{(i)}\right)-y^{(i)}\right) x_j^{(i)} \\ & \end{aligned} \]
这就是交叉熵对参数的导数:
\[ \frac{\partial}{\partial \theta_j} J(\theta)=\frac{1}{m} \sum_{i=1}^m\left(h_\theta\left(x^{(i)}\right)-y^{(i)}\right) x_j^{(i)} \]
- 牛顿法
牛顿法的基本思路是, 在现有极小点估计值的附近对 \(f(x)\) 做二阶泰勒展开, 进而找到极小点的下一个估计值。假设 \(w^k\) 为当前的极小值估计值,那么有: \[ \varphi(w)=J\left(w^k\right)+J^{\prime}\left(w^k\right)\left(w-w^k\right)+\frac{1}{2} J^{\prime \prime}\left(w^k\right)\left(w-w^k\right)^2 \] 然后令 \(\varphi^{\prime}(w)=0\), 得到了 \(w^{k+1}=w^k-\frac{J^{\prime}\left(w^k\right)}{J^{\prime \prime}\left(w^k\right)}\) 。因此有迭代更新式: \[ w^{k+1}=w^k-\frac{J^{\prime}\left(w^k\right)}{J^{\prime \prime}\left(w^k\right)}=w^k-H_k^{-1} \cdot g_k \] 其中 \(H_k^{-1}\) 为海森矩阵: \[ H_{m n}=\frac{\partial^2 J(w)}{\partial w_m \partial w_n}=h_w\left(x^{(i)}\right)\left(1-p_w\left(x^{(i)}\right)\right) x_m^{(i)} x_n^{(i)} \] 此外, 这个方法需要目标函数是二阶连续可微的, 本文中的 \(J(w)\) 是符合要求的。
- 拟牛顿法
为了避免存储海塞矩阵的逆矩阵,通过拟合的方式找到一个近似的海塞矩阵,拟牛顿法的可行性在于严格的近似方法,只要不是差的特别远就能起到相应下调效果。
DFP、BFGS、L-BFGS:

LR-L1 的梯度下降方式?
OWL-QN:用L-BFCS求解L1正则化的LR
1.5 并行化 [对目标函数梯度计算的并行化 ???]
面试题解答8:逻辑斯蒂回归的并行化计算方法 - 舟晓南的文章 - 知乎 https://zhuanlan.zhihu.com/p/447482293
从逻辑回归的求解方法中我们可以看到,无论是随机梯度下降还是牛顿法,或者是没有提到的拟牛顿法,都是需要计算梯度的,因此逻辑回归的并行化最主要的就是对目标函数梯度计算的并行化。
我们看到目标函数的梯度向量计算中只需要进行向量间的点乘和相加,可以很容易将每个迭代过程拆分成相互独立的计算步骤,由不同的节点进行独立计算,然后归并计算结果。
- 梯度下降是通过 J(w) 对 w 的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为:
\[ \begin{gathered} g_i=\frac{\partial J(w)}{\partial w_i}=\left(p\left(x_i\right)-y_i\right) x_i \\ w_i^{k+1}=w_i^k-\alpha g_i \end{gathered} \] 其中 \(\mathrm{k}\) 为迭代次数。每次更新参数后, 可以通过比较 \(\left\|J\left(w^{k+1}\right)-J\left(w^k\right)\right\|\) 小于阈值或者到达最大迭代次数来 停止迭代。
二、模型的对比
2.1 线性回归
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
我们需要明确 Sigmoid 函数到底起了什么作用?
- 线性回归是在实数域范围内进行预测,而分类范围则需要在 [0,1],逻辑回归减少了预测范围;
- 线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性。
2.2 最大熵模型
逻辑回归和最大熵模型本质上没有区别,最大熵在解决二分类问题时就是逻辑回归,在解决多分类问题时就是多项逻辑回归。最大熵原理是概率模型学习的一个准则。其认为在学习概率模型时,熵最大的模型是最好的模型。也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
最大熵模型的学习(推导过程)
最大熵模型推导 - Eccc的文章 - 知乎 https://zhuanlan.zhihu.com/p/47988480
2.3 SVM
相同点:
- 都是分类算法,本质上都是在找最佳分类超平面;
- 都是监督学习算法;
- 都是判别式模型,判别模型不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对给定的一个数据进行分类;
- 都可以增加不同的正则项。
不同点:
- LR 是一个统计的方法,SVM 是一个几何的方法;
- SVM 的处理方法是只考虑 Support Vectors,也就是和分类最相关的少数点去学习分类器。而逻辑回归通过非线性映射减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重;
- 损失函数不同:LR 的损失函数是交叉熵,SVM 的损失函数是 HingeLoss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。对 HingeLoss 来说,其零区域对应的正是非支持向量的普通样本,从而所有的普通样本都不参与最终超平面的决定,这是支持向量机最大的优势所在,对训练样本数目的依赖大减少,而且提高了训练效率;
- LR 是参数模型,SVM 是非参数模型,参数模型的前提是假设数据服从某一分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。所以 LR 受数据分布影响,尤其是样本不均衡时影响很大,需要先做平衡,而 SVM 不直接依赖于分布;
- LR 可以产生概率,SVM 不能;
- LR 不依赖样本之间的距离,SVM 是基于距离的;
- LR 相对来说模型更简单好理解,特别是大规模线性分类时并行计算比较方便。而 SVM 的理解和优化相对来说复杂一些,SVM 转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
2.4 GBDT模型
先说说LR和GBDT的区别:
- LR是线性模型,可解释性强,很容易并行化,但学习能力有限,需要大量的人工特征工程;
- GBDT是非线性模型,具有天然的特征组合优势,特征表达能力强,但是树与树之间无法并行训练,而且树模型很容易过拟合;
当在高维稀疏特征的场景下,LR的效果一般会比GBDT好。
三、应用场景
- CTR预估/推荐系统的learning to rank/各种分类场景。
- 某搜索引擎厂的广告CTR预估基线版是LR。
- 某电商搜索排序/广告CTR预估基线版是LR。
- 某电商的购物搭配推荐用了大量LR。
- 某现在一天广告赚1000w+的新闻app排序基线是LR。
四、逻辑回归 Q&A
1、线性回归和逻辑的区别与联系?
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
| 算法 | 线性回归 | 逻辑回归 |
|---|---|---|
| 思想 | 线性回归假设特征和结果满足线性关系;每个特征的强弱可以由参数体现。高斯分布 | 逻辑回归是一个假设样本服从伯努利分布,利用极大似然估计和梯度下降求解的二分类模型,在分类、CTR预估领域有着广泛的应用。 |
| 模型假设 | 线性回归假设 \(y\) 的残差 \(\varepsilon\) 服从正态分布 \(N\left(\mu, \sigma^{2}\right)\) | 逻辑回归假设 \(y\) 服从伯努利分布 (Bernoulli) |
| 应用场景 | 回归问题 | 分类问题,【非线性问题】 |
| 目标函数【原因】 | \(J(\theta)=\frac{1}{2} \sum_{i=1}^n\left(\left(h_\theta\left(x^{(i)}\right)-y^{(i)}\right)\right)^2\) 【平方损失函数】 | \(J(\theta)=-\frac{1}{m} \sum_{i=1}^n\left(y^{(i)} \log h_\theta\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right)\right)\)【交叉熵损失函数】 |
| 参数估计 | 最小二乘法、梯度下降 | 梯度下降、牛顿法 |
| 并行化 | 无 | 对把目标函数梯度计算的并行 |
| 样本分布 | 高斯分布 | 伯努利分布 |
| 优势 | 对数几率:无假设分布?得到概率、易求解 |
2、线性回归为什么用平方损失函数?
中心极限定理 + 高斯分布 + 最大似然估计 推导出来的待优化的目标函数与平方损失函数是等价的。因此可以得出结论:线性回归误差平方损失极小化与极大似然估计等价。其实在概率模型中,目标函数的原函数(或对偶函数)极小化(或极大化)与极大似然估计等价,这是一个带有普遍性的结论。比如在最大熵模型中,有对偶函数极大化与极大似然估计等价的结论。
3、 为什么不用平方误差,用交叉熵损失【w 的初始化,导数值可能很小:梯度消失】
假设目标函数是 MSE,即: \[ \begin{gathered} L=\frac{(y-\hat{y})^2}{2} \\ \frac{\partial L}{\partial w}=(\hat{y}-y) \sigma^{\prime}(w \cdot x) x \end{gathered} \] 这里 Sigmoid 的导数项为: \[ \sigma^{\prime}(w \cdot x)=w \cdot x(1-w \cdot x) \] 根据 w 的初始化,导数值可能很小(想象一下 Sigmoid 函数在输入较大时的梯度)而导致收敛变慢,而训练途中也可能因为该值过小而提早终止训练(梯度消失)。
交叉熵的梯度如下,当模型输出概率偏离于真实概率时,梯度较大,加快训练速度,当拟合值接近于真实概率时训练速度变缓慢,没有 MSE 的问题。 \[ g^{\prime}=\sum_{i=1}^N x_i\left(y_i-p\left(x_i\right)\right) \]
- 为什么不用平方损失函数?
- 交叉熵损失函数原理?
4、 LR为什么适合离散特征【易于迭代、加快计算,简化模型和增加泛化能力】
我们在使用逻辑回归的时候很少会把数据直接丢给 LR 来训练,我们一般会对特征进行离散化处理,这样做的优势大致有以下几点:
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化;
- 特征离散化以后,起到了简化逻辑回归模型的作用,降低了模型过拟合的风险;
总的来说,特征离散化以后起到了易于迭代、加快计算,简化模型和增加泛化能力的作用。
5、LR推导(伯努利过程,极大似然,损失函数,梯度下降)有没有最优解?
6、LR可以用来处理非线性问题么?
引入kernel:
对特征先进行多项式转换:
7、LR为什么用sigmoid函数,这个函数有什么优点和缺点?为什么不用其他函数?
Sigmoid函数由那个指数族分布,加上二项分布导出来的。损失函数是由最大似然估计求出的。
逻辑回归认为函数其概率服从伯努利分布, 将其写成指数族分布的形式。因为指数族分布是给定某些统计量 下熵最大的分布,例如伯努利分布就是只有两个取值且给定期望值为 \(\mu\) 下的樀最大的分布。 也就是: \[ \begin{aligned} p(y ; \phi) & =\phi^y(1-\phi)^{1-y} \\ & =\exp (y \log \phi+(1-y) \log (1-\phi)) \\ & =\exp \left(\left(\log \left(\frac{\phi}{1-\phi}\right)\right) y+\log (1-\phi)\right) \end{aligned} \] 符合: \(\quad p(y ; \eta)=b(y) \exp \left(\eta^T T(y)-\alpha(\eta)\right)\) 其中: \(\quad \alpha(\eta)=-\log (1-\phi)\) 能够推导出sigmoid函数的形式。 \[ \eta=\log \left(\frac{\phi}{1-\phi}\right) \] \[ \phi=\frac{e^\eta}{1+e^\eta} \]
Sigmoid 函数到底起了什么作用?
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线性)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
线性回归是在实数域范围内进行预测,而分类范围则需要在 [0,1],逻辑回归减少了预测范围;线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性。
无需实现假设数据分布:直接对分类的概率建模,从而避免了假设分布不准确带来的问题(区别于生成式模型);
不仅可预测出类别,还能得到该 预测的概率,这对一些利用概率辅助决策的任务很有用;
对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解。
8、逻辑回归估计参数时的目标函数逻辑回归的值表示概率吗?(值越大可能性越高,但不能说是概率)
https://blog.csdn.net/zhaojc1995/article/details/114462504
不是概率,概率是可以做加减乘除计算的,但softmax只能比较大小,不能用于计算。
并不完全等同。在多分类中,softmax最终输出的数值,会和某个类别的样本数有关。因此它不能直接用作概率,但可以粗略的认为是与概率类似的东西。
9、手推逻辑回归目标函数,正类是1,反类是-1

10、scikit-learn源码LR的实现?
11、为什么LR需要归一化或者取对数,为什么LR把特征离散化后效果更好,为什么把特征组合之后还能提升?
为什么LR需要归一化或者取对数? 符合假设、利于分析、归一化也有利于梯度下降。
LR 特征离散化
12、Naive bayes,SVM和logistic regression的区别?
13、为什么LR可以用来做CTR预估?【场景】
简单应用 预测用户在未来某个时间段是否会购买某个品类,如果把会购买标记为1,不会购买标记为0,就转换为一个二分类问题。我们用到的特征包括用户在美团的浏览,购买等历史信息,见下表

其中提取的特征的时间跨度为30天,标签为2天。生成的训练数据大约在7000万量级(美团一个月有过行为的用户),我们人工把相似的小品类聚合起来,最后有18个较为典型的品类集合。如果用户在给定的时间内购买某一品类集合,就作为正例。哟了训练数据后,使用Spark版的LR算法对每个品类训练一个二分类模型,迭代次数设为100次的话模型训练需要40分钟左右,平均每个模型2分钟,测试集上的AUC也大多在0.8以上。训练好的模型会保存下来,用于预测在各个品类上的购买概率。预测的结果则会用于推荐等场景。
由于不同品类之间正负例分布不同,有些品类正负例分布很不均衡,我们还尝试了不同的采样方法,最终目标是提高下单率等线上指标。经过一些参数调优,品类偏好特征为推荐和排序带来了超过1%的下单率提升。
此外,由于LR模型的简单高效,易于实现,可以为后续模型优化提供一个不错的baseline,我们在排序等服务中也使用了LR模型。
14、了解其他的分类模型吗,问LR缺点,LR怎么推导(当时我真没准备好,写不出来)写LR目标函数,目标函数怎么求最优解(也不会)讲讲LR的梯度下降,梯度下降有哪几种,逻辑函数是啥?
由于该极大似然函数无法直接求解,我们一般通过对该函数进行梯度下降来不断逼急最优解。在这个地方其实会有个加分的项,考察你对其他优化方法的了解。因为就梯度下降本身来看的话就有随机梯度下降,批梯度下降,small batch 梯度下降三种方式,面试官可能会问这三种方式的优劣以及如何选择最合适的梯度下降方式。
(1)批梯度下降会获得全局最优解,缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且会有很多的冗余计算,导致的结果是当数据量大的时候,每个参数的更新都会很慢。 (2)随机梯度下降是以高方差频繁更新,优点是使得sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂。 (3) 小批量梯度下降结合了sgd和batch gd的优点,每次更新的时候使用n个样本。减少了参数更新的次数,可以达到更加稳定收敛结果,一般在深度学习当中我们采用这种方法。
| 梯度下降 | 批梯度下降 | 随机梯度下降 | 小批量梯度 |
|---|---|---|---|
| 样本 | 遍历所有的数据 | 1个样本 | 使用n个样本 |
| 解 | 全局最优解 | sgd会跳到新的和潜在更好的局部最优解 | 局部最优解 |
其实这里还有一个隐藏的更加深的加分项,看你了不了解诸如Adam,动量法等优化方法。因为上述方法其实还有两个致命的问题。
学习率?
(1)第一个是如何对模型选择合适的学习率。自始至终保持同样的学习率其实不太合适。因为一开始参数刚刚开始学习的时候,此时的参数和最优解隔的比较远,需要保持一个较大的学习率尽快逼近最优解。但是学习到后面的时候,参数和最优解已经隔的比较近了,你还保持最初的学习率,容易越过最优点,在最优点附近来回振荡,通俗一点说,就很容易学过头了,跑偏了。 (2)第二个是如何对参数选择合适的学习率。在实践中,对每个参数都保持的同样的学习率也是很不合理的。有些参数更新频繁,那么学习率可以适当小一点。有些参数更新缓慢,那么学习率就应该大一点。
15、LR 如何做回归预测?【回归任务】?????
logistic regression是这么假设的:数据服从概率为p的二项分布,并且 logit(p)是特征的线性组合。
二项分布的取值就是两个,0,1,所以如果不修改假设,直接就把logistic regression用于连续值的预测肯定是不合理的,因为没有哪个正常的连续取值的东西是服从二项分布的……
16、当在高维稀疏特征的场景下,LR的效果一般会比GBDT好?
高维稀疏特征 - 黄志超的文章 - 知乎 https://zhuanlan.zhihu.com/p/271055971
LR,gbdt,libfm这三种模型分别适合处理什么类型的特征,为了取得较好效果他们对特征有何要求? - 凯菜的回答 - 知乎 https://www.zhihu.com/question/35821566/answer/225291663
高维稀疏特征:向量表示了一个样本(或一个数据点)的特征向量 ,我们可以看到向量中存在着许多0,或者说0的数量>>其他值的数量。
- 产生的原因:数据特征的缺失;数据不恰当的处理(过多类别特征的one-hot)
高维稀疏特征对模型训练带来哪些影响呢?
- LR:低维的稠密特征映射到了高维空间,低维线性不可分就转到高维空间;LR的目标就是找到一个超平面对样本是的正负样本位于两侧,由于这个模型够简单,不会出现gbdt上过拟合的问题。
- GBDT:树模型是以列为单位切分样本集的,当稀疏时,每一列的特征就会存在大量的0,切分的意义不大,且特征过于细时,容易过拟合(如年龄每一岁占一列特征)
高维稀疏特征解决方案?
- embedding
- FM
17、SVM和logistic回归分别在什么情况下使用?
n是feature的数量 m是样本数;
1、如果n相对于m来说很大(n远大于m,n=10000,m=10-1000),则使用LR算法或者不带核函数的SVM(线性分类)
2、如果n很小,m的数量适中(n=1-1000,m=10-10000):使用带有核函数的SVM算法
3、如果n很小,m很大(n=1-1000,m=50000+):增加更多的feature然后使用LR算法或者不带核函数的SVM
18、 什么是广义线性模型?
线性回归和逻辑回归都是广义线性模型的一种特殊形式,介绍广义线性模型的一般求解步骤。 利用广义线性模型推导 出 多分类的Softmax Regression。
线性回归中我们假设:
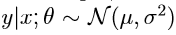
逻辑回归中我们假设:
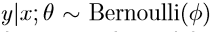
其实它们都只是 广义线性模型 (GLMs) 的特例。提前透露:有了广义线性模型下 我们只需要把 符合指数分布的一般模型 的参数 转换成它对应的广义线性模型参数,然后按照广义线性模型的求解步骤即可轻松求解问题。
指数分布族( The exponential family)
将拉格朗日乘数法应用于求解最大熵问题等同于求解对应的指数族分布问题。
结合定理1和定理2,可以看到指数族分布的联合分布的统计量充分完备统计量,再构造其无偏估计则为UMVUE。这也是指数族分布应用广泛的原因。
首先我们定义一下什么是指数分布族, 它有如下形式: \[ p(y ; \eta)=b(y) \exp \left(\eta^T T(y)-a(\eta)\right) \] 简单介绍下其中的参数 (看不懂没关系)
- \(\eta\) 是 自然参数 ( natural parameter)
- \(T(y)\) 是充分统计量 (sufficient statistic ) (一般情况下 \(T(y)=y\) )
- \(a(\eta)\) 是 log partition function \(\left(e^{-a(\eta)}\right.\) 充当正规化常量的角色, 保证 \(\sum p(y ; \eta)=1\) )
也就是所 \(\mathrm{T}, \mathrm{a}, \mathrm{b}\) 确定了一种分布, \(\eta\) 是 该分布的参数。 选择合适的 \(T, a, b\) 我们可以得到 高斯分布 和 Bernoulli 分布。
Bernoulli分布的指数分布族形式:
\[ p(y=1 ; \phi)=\phi ; p(y=0 ; \phi)=1-\phi \] \(=>\) \[ \begin{aligned} p(y ; \phi) &=\phi^{y}(1-\phi)^{1-y} \\ &=\exp (y \log \phi+(1-y) \log (1-\phi)) \\ &=\exp \left(\left(\log \left(\frac{\phi}{1-\phi}\right)\right) y+\log (1-\phi)\right) \end{aligned} \] 即: 在如下参数下广义线性模型是 Bernoulli 分布 \[ \begin{aligned} \eta=\log (\phi /(1-\phi)) \Rightarrow \phi=1 /\left(1+e^{-\eta}\right) \\ \\ T(y) &=y \\ a(\eta) &=-\log (1-\phi) \\ &=\log \left(1+e^{\eta}\right) \\ b(y) &=1 \end{aligned} \] ##### Gaussian 分布的指数分布族形式:
在线性回归中, \(\sigma\) 对于模型参数 \(\theta\) 的选择没有影响, 为了推导方便我们将其设为 1 : \[ \begin{aligned} p(y ; \mu) &=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{1}{2}(y-\mu)^{2}\right) \\ &=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{1}{2} y^{2}\right) \cdot \exp \left(\mu y-\frac{1}{2} \mu^{2}\right) \end{aligned} \] 得到 对应的参数: \[ \begin{aligned} \eta &=\mu \\ T(y) &=y \\ a(\eta) &=\mu^{2} / 2 \\ &=\eta^{2} / 2 \\ b(y) &=(1 / \sqrt{2 \pi}) \exp \left(-y^{2} / 2\right) \end{aligned} \]
19、LR的训练方
参考文献
逻辑回归:入门到精通:http://www.tianyancha.com/research/LR_intro.pdf
美团技术团队《Logistic Regression 模型简介》https://tech.meituan.com/intro_to_logistic_regression.html
SVM和logistic回归分别在什么情况下使用?https://www.zhihu.com/question/21704547
逻辑斯蒂回归能否解决非线性分类问题?https://www.zhihu.com/question/29385169
为什么LR可以用来做CTR预估?https://www.zhihu.com/question/23652394
评分卡基础—逻辑回归算法理解 - 求是汪在路上的文章 - 知乎 https://zhuanlan.zhihu.com/p/111260930
多分类:https://www.heywhale.com/mw/project/5ed755db946a0e002cb803f7
- LR推导(伯努利过程,极大似然,损失函数,梯度下降)有没有最优解?
- LR可以用来处理非线性问题么?(还是lr啊 只不过是加了核的lr 这里加核是显式地把特征映射到高维 然后再做lr)怎么做?可以像SVM那样么?为什么?
- 为什么LR需要归一化或者取对数,为什么LR把特征离散化后效果更好,为什么把特征组合之后还能提升,反正这些基本都是增强了特征的表达能力,或者说更容易线性可分吧
- 美团技术团队《Logistic Regression 模型简介》https://tech.meituan.com/intro_to_logistic_regression.html
- SVM和logistic回归分别在什么情况下使用?https://www.zhihu.com/question/21704547
- 逻辑斯蒂回归能否解决非线性分类问题?https://www.zhihu.com/question/29385169
- 为什么LR可以用来做CTR预估?https://www.zhihu.com/question/23652394
- 逻辑回归估计参数时的目标函数 (就是极大似然估计那部分),逻辑回归估计参数时的目标函数 (呵呵,第二次) 逻辑回归估计参数时的目标函数 如果加上一个先验的服从高斯分布的假设,会是什么样(天啦。我不知道,其实就是在后面乘一个东西,取log后就变成加一个东西,实际就变成一个正则项)
- 逻辑回归估计参数时的目标函数逻辑回归的值表示概率吗?(值越大可能性越高,但不能说是概率)
- 手推逻辑回归目标函数,正类是1,反类是-1,这里挖了个小坑,一般都是正例是1,反例是0的,他写的时候我就注意到这个坑了,然而写的太快又给忘了,衰,后来他提醒了一下,改了过来,就是极大似然函数的指数不一样,然后说我这里的面试就到这了。
- 看没看过scikit-learn源码LR的实现?(回头看了一下是调用的liblinear,囧)
- 为什么LR需要归一化或者取对数,为什么LR把特征离散化后效果更好,为什么把特征组合之后还能提升,反正这些基本都是增强了特征的表达能力,或者说更容易线性可分吧
- naive bayes和logistic regression的区别http://m.blog.csdn.net/blog/muye5/19409615
- LR为什么用sigmoid函数。这个函数有什么优点和缺点?为什么不用其他函数?sigmoid函数由那个指数族分布,加上二项分布导出来的。损失函数是由最大似然估计求出的。
- 了解其他的分类模型吗,问LR缺点,LR怎么推导(当时我真没准备好,写不出来)写LR目标函数,目标函数怎么求最优解(也不会)讲讲LR的梯度下降,梯度下降有哪几种,逻辑函数是啥