账号安全(1)微信UFA-Unveiling Fake Accounts at the Time of Registration: An Unsupervised Approach
UFA-在注册环节识别虚假账户的无监督检测算法
2021 KDD 论文:Unveiling Fake Accounts at the Time of Registration: An Unsupervised Approach
- https://dl.acm.org/doi/10.1145/3447548.3467094
小伍哥聊风控:https://mp.weixin.qq.com/s/PE4OSByfngPEJOW8UWVkMw
引言
今天分享一篇腾讯的论文,是一篇非常偏工程化的文章,其中也有很多技术的创新,但是工程上的一些实践感觉还是非常有价值的, 其实在风控业务中,业务的抽象和提取方法,可能远大于算法本身,特别是图学习领域,一个垃圾的图,算法学的越准,错的越离谱。
一、概述
在线社交网络(OSN)充斥着虚假账户。现有的虚假账户检测方法要么需要手动标记的训练集,这既耗时又昂贵,要么依赖于OSN账户的丰富信息,例如内容和行为,这会导致检测虚假账户的显著延迟。在这项工作中,我们提出了UFA(揭开虚假账户的面纱)来在虚假账户以无监督的方式注册后立即检测它们。
首先,通过对真实世界注册数据集上的注册模式的测量研究,我们观察到虚假账户倾向于聚集在异常注册模式上,例如IP和电话号码。然后,我们设计了一种无监督学习算法来学习所有注册账户的权重及其特征,以揭示异常注册模式。
接下来,我们构建了一个注册图来捕捉注册帐户之间的相关性,并通过分析注册图结构,利用社区检测方法来检测虚假帐户。我们使用真实世界的微信数据集评估UFA。我们的结果表明,UFA在召回率为80%的情况下达到了94%的精度,而监督变体需要600K手动标签才能获得可比较的性能。此外,微信已经部署UFA来检测虚假账户一年多了。UFA检测到500𝐾 通过微信安全团队的手动验证,每天伪造账户的准确率平均为93%。
本文主要有四大贡献:
- 本文基于微信数据提出了大规模的度量学习的方法,并使用注册数据发现了虚假账号在异常注册模式的聚集趋势
- 本文基于微信注册数据,提出了非监督UFA模型用以识别虚假账户
- 系统性的评估了UFA和其他监督和非监督模型的效果
- UFA模型在微信已经部署超过一年,在线上取得了很好的效果
二、数据探索
2.1 IP地址分析
在论文使用的数据集中,总共有895,879个不同的IP地址。我们将使用同一IP地址注册的所有帐户组合在一起。因此,组的大小表示从一致的IP地址注册的帐户数量。图8a 显示了注册给定数量账户计数的IP地址数。

当给定的帐户数从0-5增加到5-10时,我们观察到IP地址数会有一个数量级的下降。这表明大多数IP地址注册了少量帐户(少于5个帐户),而少数IP地址注册了大量帐户。此外,假冒帐户更有可能使用相同的IP地址注册。
图8b显示了从IP地址注册的帐户中假冒帐户的比例,该IP地址注册了给定数量的帐户。我们观察到,当一个IP地址注册了少量帐户(例如10个)时,很难仅仅根据这些帐户共享IP地址的事实来判断这些帐户是否为假帐户。但是,当大量(例如100)帐户从同一IP地址注册时,这些帐户更有可能是伪造帐户。(量变引起质变)
2.2 手机号码分析
用户在注册微信账号时必须提供电话号码。由于我们只能访问电话号码的前 7 位数字(运营商加区号),因此我们将使用电话号码的前缀来研究假帐户和良性帐户之间的区别。

图 9a 显示了注册给定数量账户的电话号码前缀的数量,而图 9b 显示了从注册给定数量账户的电话号码前缀注册的账户中虚假账户的比例。与 IP 地址一样,我们观察到大多数电话前缀只具有少量注册帐户,而少数电话前缀具有大量注册帐户。更具体地说,如果一个电话前缀有超过 30 个注册帐户,这些帐户中的大部分可能是假帐户。
2.3 设备的device id(这里用的imei码)
图10a显示了注册给定数量帐户的设备(由IMEI标识)的数量,图10b显示了注册给定数量帐户的设备中注册的帐户中伪造帐户的比例。我们观察到相似的异常模式,也就是说,伪帐户可能是从相同的设备注册的。

2.4 注册时间
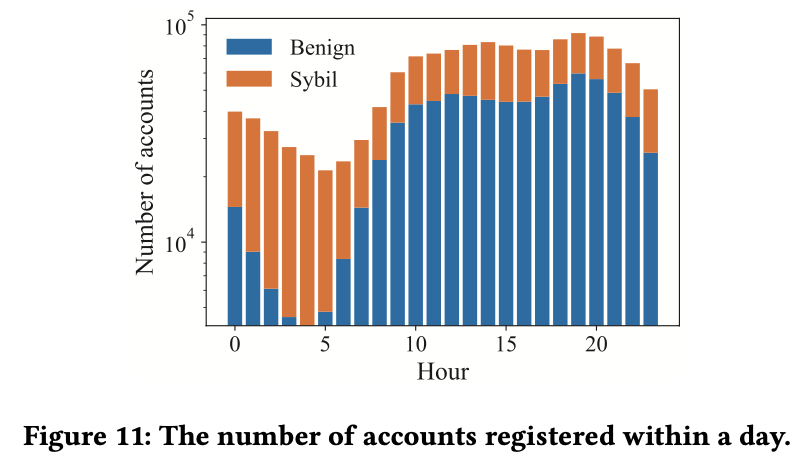
图11显示了在一天中注册的帐户的注册时间的分布。我们观察到大多数良性用户从早上八点开始注册帐户,到晚上24点左右停止注册,午夜时很少有用户活跃。然而,假账户的数量似乎一整天都没有变化。大多数在午夜注册的账户可能是假账户。
2.5 不一致的地理位置
IP地址和电话号码都可以映射到一个大概的地理位置。因此,我们可以分析每个注册的用户的两个地理位置是否相同(ip和电话号码可以查询到用户的归属地)。我们观察到65%的假帐户具有不同的基于IP的位置和基于电话号码的位置。一个可能的原因是攻击者利用云服务和从本地获取的电话号码注册假帐户。此外,用户还可以在注册帐户时在配置文件中指定其位置(例如国家)。我们发现96%的伪造账户指定的国家与基于IP的定位不一致。一个可能的原因是这些假账户的目的是攻击来自特定地点的良性账户。
2.6 微信和设备的版本
我们分析了微信版本和操作系统版本,发现大多数从过时的微信或/和操作系统版本注册的账户都是假账户。例如,从某个过时的Android版本注册的账户只有2K个,其中96.5%是假的。同样的现象也发生在iOS中。例如,我们发现从iOS 8(过期的DOS版本)注册的99%的帐户都是假帐户。一个可能的原因是,攻击者使用脚本自动注册假帐户,其中微信和操作系统版本尚未更新。
2.7 道德和隐私
微信在隐私政策中规定,用户注册帐户时将收集用户数据。此外,在提交微信服务器之前,所有注册属性都已匿名,以保护用户隐私。例如,电话号码的客户代码(即最后四位数字)将被删除。IP地址逐段散列,WiFi MAC和设备ID全部散列。特别是,我们有一个与WeChat合作的实习计划,因此我们可以访问存储在微信服务器上的上述数据。
三、相关研究
paper中的related部分其实就类似于我们平常做项目之前的一些解决方案的调研,传统的检测方法:这些方法可以分为基于特征的方法和基于结构的方法。
3.1 基于特征的方法
通常将虚假账户检测的建模转化为为一个二分类问题,并利用机器学习技术进行解决。具体来说,首先从每个账户的内容(如推特中的URL)、行为(如点击流和喜欢的行为记录)、注册信息(如IP地址和代理)中提取特征。然后,基于这些提取的特征和标记的训练集(由标记的假账户和标记的良性账户组成)训练监督分类器(如logistic回归),并使用训练的分类器检测假账户。
3.2 基于结构的方法
利用社交图的结构来检测假账户,并且通常基于这样一个观察结果,即如果一个账户与其他假账户相关联,该账户可能也是虚假的账户。这些基于扩展图的机器学习技术的方法,例如随机行走和信念传播,分析用户之间社交图的结构。
上述传统检测方法的主要局限性在于检测假账户时存在严重延迟,因为这些方法需要获取假账户生成的足够信息进行分析,例如,丰富的内容、行为,和/或社交图。因此,当检测到伪造帐户时,它们可能已经进行了各种恶意活动。
四、模型的原型设计
UFA旨在以无监督的方式在注册时检测出虚假账户。图1概述了UFA。它由四个关键部分组成,即特征提取、无监督的权重学习、注册图的构建和假账户检测。在特征提取方面,受注册模式测量研究的启发,我们提取了揭示虚假账户异常注册模式的特征。 在无监督的权重学习中,我们首先构建了一个注册-特征大图来捕捉注册账户和特征之间的关系。大图中的每个节点都代表一个注册账户或一个特征,注册节点和特征节点之间的每条边都表示该注册账户具有该特征。
4.1 整体框架
接下来,我们设计了一种统计方法来初始化大图中每个节点的权重。节点的权重量化了该节点的异常情况。我们的统计方法不需要标记的虚假账户或/和标记的良性账户,因此它是无监督的。这里,初始权重没有考虑特征之间和注册账户之间的关系。为了解决这个问题,我们采用了一种最先进的基于结构的方法,称为线性化信念传播[26],来传播注册-特征大图中节点的初始权重,并迭代更新每个节点的权重。每个注册账户的最终权重表示该账户被伪造的概率。
UFA主要包括了四个步骤:特征提取、无监督权重学习、注册图构造、虚假账户检测

在特征提取中,受之前的数据挖掘部分得到的分析结果的启发,我们提取了可以反应假账户异常注册模式的特征。在无监督权重学习中,我们首先构造一个注册特征-用户 的二部图来捕捉注册账户和特征之间的关系。二部图中的每个节点表示注册帐户或特征,注册节点和特征节点之间的每个边表示注册帐户具有该特征。我们初始化Bigraph中每个节点权重使用了基于统计的方法。节点的权重量化了节点的异常。我们的统计方法不需要标记假账户或/和标记良性账户,因此不是有监督的方法。在这里,初始权值不考虑特征和注册账户之间的关系。为了解决这个问题,我们采用了一种最先进的基于结构的方法,称为线性化置信传播(《Structure-based sybil detection in social networks via local rule-based propagation》),在注册特征bigraph中传播节点的初始权重,并迭代更新每个节点的权重。每个注册帐户的最终权重表示该帐户被伪造的可能性。
无监督权重学习无法学习注册帐户之间的相关性,因为注册特征-用户的bigraph中注册帐户之间没有边。因此,我们构建了一个图来直接捕获注册帐户之间的相关性。具体来说,我们将注册特征的bigraph映射到一个注册图中,其中每个节点都是注册帐户,如果两个注册帐户之间的相似度高于阈值,则在它们之间添加一条边(还是相似度构图的思路啊。。。)。两个注册帐户之间的相似性定义为两个帐户共享的特征权重之和。在构建的注册图中,假账户可能紧密连接,而真账户可能稀疏连接。最后,由于假账户在注册图中紧密连接,我们使用社区检测算法进行社群检测。如果社区中的节点的规模大于阈值,则我们将社区中的所有帐户视为假帐户。
4.2 特征提取
注册阶段的用户特征,当用户注册一个微信账号时,微信会收集该账号的多个注册属性。表1列出了具有代表性的注册属性。
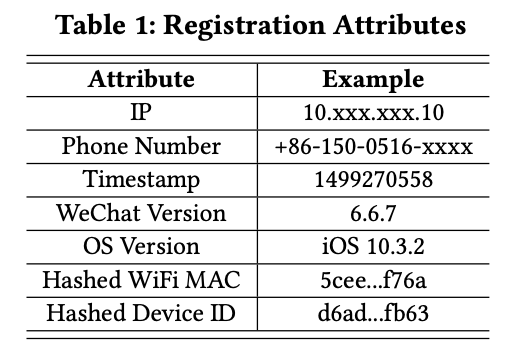
例如,电话号码是用户用来注册帐户的号码。每个电话号码只能用于注册一个帐户和作为帐户ID。WiFi MAC是手机用于注册帐户的WiFi路由器的MAC地址,DeviceID是用于注册帐户的手机的IMEI/Adsource。根据数据挖掘部分的分析结果,与良性账户相比,虚假账户倾向于具有异常值注册模式。特别是,假账户可能使用相同的IP,使用相同地区的相同电话号码,从相同的设备注册,在午夜活跃,使用罕见且过时的微信和操作系统版本。一个可能的原因是攻击者的资源有限(例如IP、电话号码和设备),只能使用脚本自动注册假帐户。
那么我们怎么做特征提取呢?我们提取了可以用来反映虚假帐户异常注册模式的特征。具体来说,我们将每个注册表的属性和属性值解析为一个字符串,格式为“%%FeaturePrefix%%.%%value%%”。表2中列出了所有特性前缀。
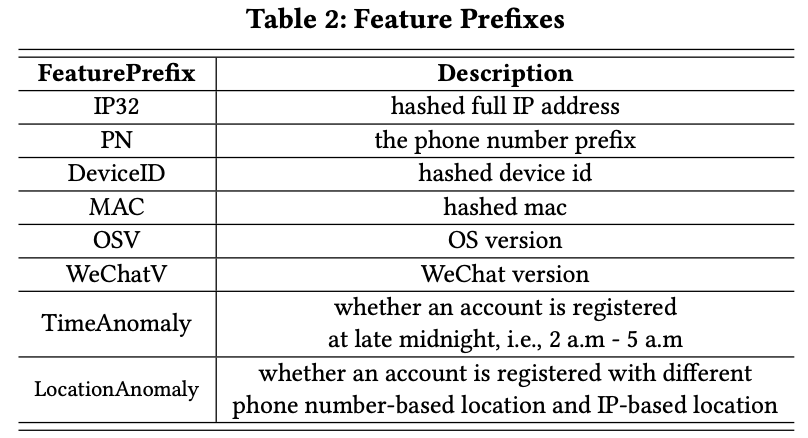
每个特征前缀只与一个属性相关,并表示该属性的预处理函数;并且每个值都是预处理后生成的结果。为了简单起见,我们只展示如何提取特征前缀为“TimeAbnormal”的特征,因为其他特征可以从其特征前缀和描述中轻松理解:
TimeAbnormal:根据我们的数据挖掘的结果,我们观察到在深夜注册的账户很可能是假账户,而良性账户主要在白天注册。因此,我们定义了一个特征Prefix TimeAbnormal,它使用时间戳特征。时间异常用于指示帐户的注册时间是否异常。也就是说,如果账户在白天注册,则时间异常值为假,如果账户在午夜晚些时候注册,则时间异常值为真,在我们的工作中,我们将午夜定义为凌晨2点到5点之间。

这里的意思是根据注册时间构建一个节点,这个节点的id为 timeanomaly true,如上图。
整体来看,特征提取的思路很简单,其实本质上就是通过将用户的属性转化为节点,从而将单个用户节点分裂为以用户节点为中心的用户-属性的k部图,不过文中用的描述是2部图,其实就是把所有的特征都定义为类型为“特征”的节点,问题不大。
在构图之前,对于特征论文中进行统一的string话处理,格式为 "%%FeaturePrefix%%_%%Value%%",假设我们现在手头有两个用户uid001和uid002,对于特征的处理和图的构建就像下图这样:
1 |
|
构图数据预处理过程:
1 |
|
4.3 无监督的权重学习
在无监督权重学习中,我们的目标是学习每个提取特征和每个注册帐户的权重。权重量化异常,范围在0到1之间。较高的权重表示异常的可能性较大。具体来说,我们首先构造一个图来捕获特征和注册帐户之间的关系,其中每个节点表示一个特征或一个注册帐户,两个节点之间的每条边表示注册帐户具有该特征。 我们设计了一种统计方法,以无监督的方式初始化构造图中每个节点的权重,并采用基于结构的方法在构造的图中传播节点的初始权重,并迭代更新每个节点的权重。每个注册节点的最终权重可被视为该注册帐户的伪造概率。
我们构造用户-特征的二部图来捕获注册帐户和提取特征之间的关系:

如上图所示。具体来说,我们用 (R,F,E)来表示这个图,其中R表示一组注册节点,就是注册用户的意思,F 表示一组特征节点,就是每个F节点都表示某个特征(当然这里的特征都是离散的,连续特征没法直接作为节点需要离散化之后才能作为节点),E,就表示edge了,(因为注册账户节点和特征节点之间都是 注册账户节点“拥有”特征节点 这么一个抽象的关系,所以edge的权重默认均为1.)注册节点和特征节点之间的边表示注册节点,即注册用户具有这个特征。
例如,在上图中, 节点连接了 如“IP32_10.xxx.xxx.10”、“PN_+861585321xxxx”、“OSV_Android 7.0”这三个特征节点,这意味着 注册时,使用IP地址“10.xxx.xxx.10”、电话号码“+861585321xxxx”和手机操作系统版本“Android 7.0”。
特征节点的权重的初始化策略,(这篇paper的思路是先通过无监督的方法给特征节点的权重进行初始化,然后通过信念传播的方式给注册账户节点进行权重的传播赋值)。我们设计了一种统计方法,为每个特征节点和每个注册帐户节点分配初始权重,这个过程无需手动打标虚假账户。我们的统计方法依赖于三个概念: 特征频率、特征比率和特征模式。
- 特征频率:特征频率表示某个特征有多少个注册账户有,比如有100个注册账户在注册的时候都使用了“IP32_10.xxx.xxx.10”,则“IP32_10.xxx.xxx.10”这个特征节点的特征频率为100;
- 特征比率:其实就是同类特征的占比啦。比如说我们的手机号这个特征下有10000个手机号,其中“PN_+861585321xxxx”有5000个,则“PN_+861585321xxxx”这个特征节点的特征比率为0.5.
- 特征模式:特征模式不是相对于某个特征节点的,而是对于某个特征下所有的特征节点的,还是举个例子,假设OSV前缀的,即手机系统版本这个特征下有Android 7.0,Android 8.0,Android 9.0,占比分别为0.25,0.25,0.5,则最终我们得到 OSV 这个特征的特征模式为 Android 9.0,其实就是某个特征下某个最大取值对应的特征节点的名字。
现在我们可以通过使用上述的特征频率,特征比率和特质模式来定义每个特征的权重。我们通过定义特征的权重来量化特征的异常。
为了描述清晰,这里还是强调一下,特征频率和特征比率都是针对于特征节点的,而特征模式是针对于某一类特征节点的群体的,以性别为例(因为性别特征就两个取值,比较好理解),性别有男女,则按照上述的思路,我们会有一个 “sex_男”和“sex_女”的这两种特征节点,“sex_男”和“sex_女”的特征频率假设分别60和40,则其特征比率分别为0.6和0.4,性别这个特征的特征模式为0.6.具体地说,是这么做的,首先,我们将所有的特质划分为两个组,一个pre-A,一个pre-B。我们以数据挖掘分析部分的一个case为例:

deviceid的共享情况,这个图解释一下,左边的直方图,横轴表示device id 共享的账户的数量,按照直方图的划分可以知道,每一个device id根据其共享的账户数量打上了标签,分别为“ 0~5”,“5~10”.。。。“>=30”,然后我们统计每一种标签下的device的数量,就是纵轴的取值了,可以看到,deviceid这种东西反映出来的趋势是 deviceid 一般情况下不太可能被多个账户共享,大部分的device 所共享的账户很少,极少部分的deivce id 存在大量账户共享的情况,所以我们把device id 这种特征分到 pre-B 组中去;像ip,phone 这些的反应出来的情况都是一样的,所以都放到pre-B中去了,显然,我们可以知道,放到pre-B中的特征都是不太容易产生高账户共享问题的字段。
原文提到了pre-A中的特征有一个是osv,即手机的版本号,比如android 7.0 ,ios xxx 这类的。pre-A中的特征就是比较容易产生大量账户共享的,比如手机版本,app的版本,时间上的异常等等(我以前对于这种容易产生大量账户共享的特征都是删除不拿来建图的,因为容易产生很稠密的图,坏处就是损失了一部分信息,这里给到的思路还可以。)而对于pre-B中的特征,例如phone number 手机号这种东西,一般不太容易被大量的账户共享,那么对于手机号这种特征,其特征节点,例如“861585321xxx” 这个号段,如果被大量账户共享,则我们认为这种情况很异常,因为手机号本上就趋向于被很少的账户共享或不被共享。文中的pre-A和pre-B的选择为:Pre_A={ , ℎ , , }andPre_B={ 32, , , }
我们这么来定义特征节点的权重,可以看到,上述的公式应该是很清晰了,对于pre-A中的特征,特征节点的节点权重为1-ratio(x),即这个特征节点共享的账户越多,越正常,节点权重越小;对于pre-B中的特征,特征节点的权重为ratio(x),即这个特征节点共享的账户越多,越不正常,节点权重越大。
然而,有一个严重的问题,上述定义的特征节点的权重,不能用于直接比较不同特征下的不同特征节点的节点权重,例如经过这样的计算,android7.0 这样的特征节点和“861585321xxx” 这样的特征节点没有可比性,比如手机系统版本和手机号这两个特征的特征分布,前者的特征比分布是比较集中的(大部分用户都是集中使用比较新的几个版本),而手机号的特征比分布则比较均匀(用户均匀的分配到不同的手机号段上),这个时候算出来的ratio肯定差别很大的。为了解决这个问题,对上图的公式进行优化和重新定义,使用了一种称为类别特征的“特征匹配”的技术(《Guansong Pang, Longbing Cao, and Ling Chen. 2016. Outlier Detection inComplex Categorical Data by Modeling the Feature Value Couplings.. InIJCAI.》),具体来说,是这么做的。
特征节点的节点权重wx的公式转化如下: \[ w_x=\frac{1}{2}(\operatorname{dev}(x)+\operatorname{base}(x)) \] where \[ \operatorname{dev}(x)= \begin{cases}1-\frac{\operatorname{ratio}(x)}{\text { ratio }(\text { mode }(\text { pre }(x)))} & \text { if } \operatorname{pre}(x) \in \text { Pre-A } \\ 1-\frac{1-\operatorname{Aatio}(x)}{\text { ratio }(\text { mode }(\text { pre }(x)))} & \text { if } \operatorname{pre}(x) \in \text { Pre-B}\end{cases} \] and \[ \operatorname{base}(x)= \begin{cases}1-\operatorname{ratio}(\operatorname{mode}(\operatorname{pre}(x))) & \text { if } \operatorname{pre}(x) \in \text { Pre-A } \\ \operatorname{ratio}(\operatorname{mode}(\operatorname{pre}(x))) & \text { if } \operatorname{pre}(x) \in \text { Pre-B }\end{cases} \] 本质上就是做了一个标准化的操作, 使得不同特征下的特征节点的权重统一到一个量纲下(对于离散特征的这种权重的处理在图中具有很好的推广作用, 有时间再看看文中提到的这几篇论文, 很不错) \(\operatorname{dev}(\mathrm{x})\) 考虑了特征节点的异常,base \((x)\) 考虑了特征的异常。因为 \(\operatorname{dev}(x)\) 的取值必然是0~1之间的, base (x)也必然是0~1之间的, 因此, 最终我们的特征节点权重w \((x)\) 也必然是0~1之间的。然后, 注册账户节点的初始化权重就是和这个注册账户节点连接的所有的特征节点的权重的平均值。 \[ w_r=\frac{\sum_{x \in \Gamma(r) w_x}}{|\Gamma(r)|} \] 初始化了权重之后, 使用线性的信念传播来进行特征节点和注册账户节点的权重的更新迭代, \[ \begin{split} p_u^{(t)}=w_u+2 \sum_{v \in \Gamma(u)}\left(p_v^{(t-1)}-0.5\right) \cdot\left(h_{v u}-0.5\right) \end{split} \]
文中提到了,作者做了10次的迭代来更新所有节点的权重。(信念传播还不太懂, 暂时可以先理解类似于用户自定义初始权重的个性化pagerank)
4.4 注册信息构图
我们构建了一个加权图来直接捕捉注册账户之间的关联性。构建的图是由注册-特征图而来的。具体来说, 对于注册特征图中的每一对注册节点 \(u, v \in \mathbb{R}\), 我们在 \(u\) 和 \(v\) 之间创建一条边 \((u, v)\) ,只要 \(u\) 和 \(v\) 的相似度大于阈值。特别是, 我们把 \(u\) 和 \(v\) 之间的相似性 \(\operatorname{sim}(u, v)\) 定义为 \(u\) 和 \(v\) 的共享特征的最终权重之和。这背后的直觉是,如果两个注册节点共享许多特征, 而且这些特征的最终权重很大(异常概率大),那么这两个注册 账户也有很大的相似性, 倾向于是假账户。如下图: \[ \operatorname{sim}(u, v)=\sum_{s \in \Gamma(u) \bigcap \Gamma(v)} p_s \] 此外,我们设置了边的权重\((𝑢,𝑣)\) 在新的图中成为相似性\(sim(𝑢,𝑣)\). 我们将构建的加权图称为注册图,因为图中的所有节点都是注册帐户。虚假账户更有可能以较大的边缘权重相互连接,良性账户更有可能通过较小的边缘权重稀疏连接。最终我们将注册账户节点-特征节点的异构图转化为了注册账户节点-注册账户节点的基于相似度的同构图。
4.5 社区发现
在注册图中,我们注意到虚假账户密集连接,而良性账户稀疏连接。为了检测欺诈账户,我们需要识别注册图中的密集子图。自然的选择是利用社区发现算法。我们首先采用社区检测方法,例如Louvain方法[2],将节点分为不同的社区(即密集子图)。其次,我们检测发现出来的社区中的所有注册帐户的数量,如果其大小超过了我们设定的阈值,则认为这个社群中所有的注册账户都是有问题的虚假账户。
- 我们首先采用社区检测方法将节点聚集到不同的社区(即密集子图)。
- 其次,我们预测社区中所有规模大于阈值的注册账户都是假账户。
五、模型评估
5.1 实验设置
- 数据集
我们从微信中获得了七个数据集。每个数据集都包括一天内的注册信息。表3显示了这些数据集的细节。这些标签是由微信安全团队提供的,他们手工验证了这些标签(大厂就是牛逼),并发现这些标签的准确率大于95%。

- 评价指标
我们使用三个指标,即准确率、召回率和 F-score 来评估性能。对于一个检测方法来说,精确率是其预测的假账户在测试集中为真实假账户的比例,召回率是测试集中真实假账户被该方法预测为假账户的比例,而F分数是精确率和召回率的调和平均值。比较的方法。我们将UFA与几种无监督的变体进行比较,包括UFA-naive、UFA-noLBP、UFA-noRG和超级视觉方法,包括Ianus[35]、XGBoost[6]和深度神经网络(DNN)。
5.2 实验结果
表4显示了ufa在七个数据集上的预测结果。

UFA可以在所有数据集中检测到约80%的假帐户,其精确度约为90%。一个关键原因是,通过无监督的权重学习和注册图构造,注册图中的假账户连接紧密,而良性账户连接稀疏。
例如,在第五天由构建出来的注册图中(从这里可以看出,腾讯构图的方式是构建天级别的图),平均而言,一个假帐户与22.32个其他假帐户存在连接,而与1个良性账户存在连接,而对于一个良性帐户而言,仅与2.04个其他良性账户相互连接。
然后,Louvain的方法可以很容易地检测到这些密集连接的假帐户。我们发现大约85%的假账户聚集在一起,剩下的15%的假账户是分散的,也就是说,他们与其他人没有共同的特征(这种就没办法了,毕竟ufa是完全从关联上出发去检测的)。因此,根据ufa的80%左右召回表现,证明了其在检测假账户方面的有效性。

相似阈值的影响
回顾一下,UFA预先定义了一对注册账户之间的相似度阈值,以确定两个注册账户之间是否添加了一条边。一个自然的问题是这个相似度阈值对UFA的检测性能有什么影响。图3a显示了UFA与1.0和1.5之间的相似度阈值的结果。我们观察到,当阈值增加时,精确度增加,召回率下降,而F-Score首先增加,然后下降。原因是较大的阈值使一对注册账户在我们的注册图中更难连接。当使用较高的阈值时,注册图中的连接节点更有可能是假账户,所以我们可以有更高的精度。同时,更少的假账户可以相互连接,因此召回率下降。我们还注意到,当相似度阈值在1.2左右时,F-Score达到最大值。因此,我们在实验中选择默认的相似度阈值为1.2。

我们观察到,当阈值增加时,精度增加,而F分数先增加后减少。原因是阈值越大,在注册图中连接一对注册帐户就越困难。当使用更高的阈值时,注册图中连接的节点更有可能是假帐户,因此我们可以获得更高的精确度。同时,可以相互连接的假帐户更少,从而减少了recall。我们还注意到,当相似性阈值在1左右时,F分数达到最大值。因此,我们在实验中选择了一个默认的相似性阈值为1.2。
社区规模的影响
UFA使用Louvain方法检测社区并预测社区中的注册帐户,这些帐户的大小大于预定义的阈值,即假帐户。我们研究了不同社区规模对UFA的检测性能的影响,结果如图3b所示。

我们观察到,随着社区规模的阈值变大,精确度和F分数先增加后降低。当阈值大于15时,所有三个指标都是稳定的。所以,我们在实验中选择了社区规模的默认阈值为15。
六、在微信场景的实际部署
UFA已经被微信部署了一年多,用于检测虚假账户。它是在Spark上用Python实现的,并被部署在微信的内部云计算平台YARD上。UFA以流程模式工作,其部署图如图6所示。具体来说,UFA系统有两个阶段:系统初始化和系统更新。
6.1 系统初始化
微信最初部署时,UFA收集一定数量的注册账号,提取特征,构建注册特征bigraph,学习特征权重和注册帐户,并构建注册图。微信在部署后第一周使用所有注册账号完成系统初始化。初始化后,我们拥有特征节点和注册帐户的权重。系统初始化中的所有步骤都在流式处理服务器上执行。

6.2 系统更新
系统初始化后,当WeChatserver收到新的注册帐户时,UFA先提取帐户特征,然后执行以下步骤。
- 在注册特征的Bigraph中创建新节点/边。UFA先为不在当前注册特征的bigraph中的特征创建新注册节点和新特征节点。然后,UFA在注册节点及其特征节点之间创建新边。此步骤在流数据服务器上运行。
- 在注册图中创建新节点/边。UFA在此步骤中检索与新注册帐户接近的现有注册帐户。具体而言,UFA寻找所有现有注册帐户与新注册帐户之间共享的注册节点。然后,UFA使用特征节点的当前权重计算新注册帐户和找到的注册帐户之间的相似性。接下来,在注册图中,如果两个帐户之间的相似性大于预定义阈值,UFA将为新注册帐户创建一个新节点,并在新注册帐户和找到的每个注册帐户之间创建一条边。此步骤在流式处理服务器上运行。
- 定期更新特征/注册节点的权重并检测假帐户。为了减轻计算负担,UFA更新特征/注册节点的权重,并每小时检测一次假帐户。权重更新和伪造帐户检测都定期在检测服务器上执行。具体来说,流式处理服务器上的UFA会每小时更新注册-特征节点bigraph和注册-注册节点的同构图,并将这些图保存到数据库中。然后,从数据库加载图,并运行无监督权重学习算法和社区检测算法来检测假帐户。接下来,UFA将更新的特征/注册节点的权重和检测到的假帐户从检测服务器传输到流处理服务器。检测到的假帐户存储在数据库中。流服务器使用更新的特征/注册节点权重进行下一次定期系统更新。
6.3 UFA在真实场景中的表现
微信所有检测到的假帐户,其中一些可能是良性帐户。如果良性帐号被封禁,微信安全团队会收到注册该帐号的用户的投诉。微信使用投诉数量来评估UFA的表现。
具体来说,微信安全团队有6名安全分析师来处理用户的投诉。总体而言,申请解锁账户在被封禁的账户中不到6%。此外,微信安全团队随机抽取了200个被UFA检测到的虚假账户,对UFA的性能进行评估,UFA的精度达到93%,与投诉测得的结果一致。
综上所述,UFA 平均每天检测 50 万个假账户,自 UFA部署以来总共检测到 1.8 亿个假账户(在 4 亿个注册账户中)。
Ianus 在现实世界中的部署限制,在 UFA 之前,微信已经部署了 Ianus [35] 大约六个月。Ianus 是一种监督式虚假账户检测方法,它也利用了账户的注册信息。然而,Ianus在部署一段时间后就暴露了它的弱点。
- 首先,手动标记非常耗时。微信安全团队有6名安全分析师,他们的职责是对注册账号进行标记,每个分析师每天可以标记大约1000个注册。人工标注,比如600K个虚假账户,大概需要100天左右,很费时间。很难获得准确的标注,毕竟人也会犯错。许多虚假帐户仅在检查其注册信息,类似于良性帐户。
- 而在一定数量的噪音标签下,Ianus的性能将下降。
- 除此之外,需要经常对Ianus进行retraining,以保持较高的检测性能。
图7显示了Ianus在连续14天的预测中的表现,不进行retraining。为了简单起见,我们只展示了分数,我们在精度和调用方面也有类似的观察结果。我们看到,Ianua的F-Score从第七天开始大幅下降。68%对55%。92%,在14天内。一个可能的原因是攻击者不断改变他们的注册模式以逃避Ianus的检测。因此,基于旧注册模式训练的Ianus不足以检测具有新注册模式的假帐户。为了保持较高的检测性能,需要经常使用新注册模式上的准确标签对Ianus进行重新训练。然而,正如我们上面提到的,它是耗时的,并且很难准确地标记注册帐户,所以靠谱的retraining需要的标签也不多。相比之下,UFA的分数相对稳定,表明UFA在实际部署中要比Ianus更好。
七、 总结
在本文中,我们开发了一种无监督的方法UFA来检测虚假账户,在他们被注册后立即检测。我们首先提取了揭示假账户异常注册模式的特征,其灵感来自于对微信中真实世界注册数据集的测量研究。然后,我们设计了一种无监督的权重学习算法来学习提取的特征和注册账户的权重。此外,我们构建了一个注册图来直接捕捉注册账户之间的关联性,如虚假账户是密集连接的,而良性账户是稀疏连接的。最后,我们采用了一种社区检测算法,通过分析注册图结构来检测虚假账户。我们使用微信的真实世界数据集对UFA进行了评估。我们的结果显示,UFA取得了94%的精度和80%的召回率。UFA已经被微信部署在检测虚假账户上一年多了,并且达到了93%的精度。