关联规则(1)概述
一、关联规则概述
关联规则-策略挖掘中必不可少的算法。
1993年,Agrawal等人在首先提出关联规则概念,迄今已经差不多30年了,在各种算法层出不穷的今天,这算得上是老古董了,比很多人的年纪还大,往往是数据挖掘的入门算法,但深入研究的不多,尤其在风控领域,有着极其重要的应用潜力,是一个被低估的算法。
1.1 关联评价
关联规则有三个核心概念需要理解:支持度、置信度、提升度,下面用最经典的啤酒-尿不湿案例给大家举例说明这三个概念,假如以下是几名客户购买订单的商品列表:

(1)支持度
支持度 (Support):指某个商品组合出现的次数与总订单数之间的比例。
在这个例子中,我们可以看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8。

同样“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是 3/5=0.6

这样理解起来是不是非常简单了呢,大家可以动动手计算下 '尿不湿+啤酒'的支持度是多少?
(2)置信度
置信度 (Confidence):指的就是当你购买了商品 A,会有多大的概率购买商品 B,在包含A的子集中,B的支持度,也就是包含B的订单的比例。
置信度(牛奶→啤酒)= 3/4=0.75,代表购买了牛奶的订单中,还有多少订单购买了啤酒,如下面的表格所示。

置信度(啤酒→牛奶)= 3/4=0.75,代表如果你购买了啤酒,有多大的概率会购买牛奶?

置信度(啤酒→尿不湿)= 4/4=1.0,代表如果你购买了啤酒,有多大的概率会买尿不湿,下面的表格看出来是100%。

由上面的例子可以看出,置信度其实就是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多大。如果仅仅知道这两个概念,很多情况下还是不够用,需要用到提升度的概念。比如A出现的情况下B出现的概率为80%,那到底AB是不是有关系呢,不一定,人家B本来在大盘中的比例95%。你的A出现,反而减少了B出现的概率。
(3)提升度
提升度 (Lift):我们在做商品推荐或者风控策略的时候,重点考虑的是提升度,因为提升度代表的是A 的出现,对B的出现概率提升的程度。
提升度 (A→B) = 置信度 (A→B) / 支持度 (B)
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
提升度 (啤酒→尿不湿) =置信度 (啤酒→尿不湿) /支持度 (尿不湿) = 1.0/0.8 = 1.25,可见啤酒对尿不湿是有提升的,提升度为1.25,大于1。
可以简单理解为:在全集的情况下,尿不湿的概率为80%,而在包含啤酒这个子集中,尿不湿的概率为100%,因此,子集的限定,提高了尿不湿的概率,啤酒的出现,提高了尿不湿的概率。
(4)频繁项集
频繁项集(frequent itemset) :就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的的项集就是频繁项集,项集可以是单个商品,也可以是组合。
频繁集挖掘面临的最大难题就是项集的组合爆炸,如下图:

随着商品数量增多,这个网络的规模将变得特别庞大,我们不可能根据传统方法进行统计和计算,为了解决这个问题,Apriori算法提出了两个核心思想:
某个项集是频繁的,那么它的所有子集也是频繁的 {Milk, Bread, Coke} 是频繁的 → {Milk, Coke} 是频繁的
如果一个项集是非频繁项集,那么它的所有超集也是非频繁项集 {Battery} 是非频繁的 → {Milk, Battery} 也非平凡
如下图,如果我们已知B不频繁,那么可以说图中所有绿色的项集都不频繁,搜索时就要这些项避开,减少计算开销。

同理,如果下图所示,{A,B}这个项集是非频繁的,那虚线框后面的都不用计算了。
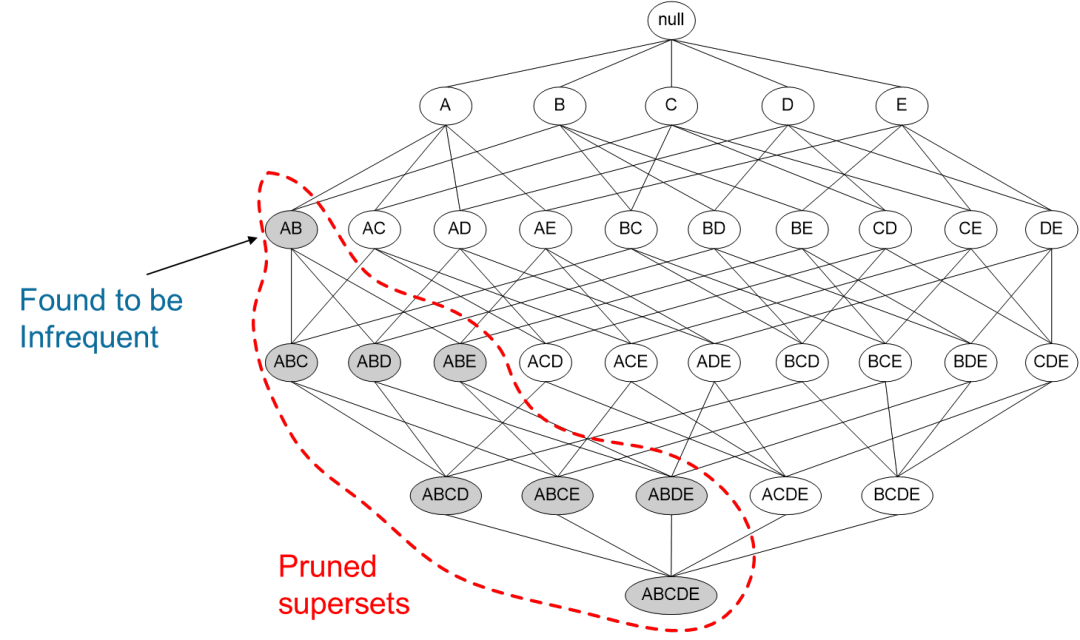
需要注意的是:
1)如果支持度和置信度阈值过高,虽然可以在一定程度上减少数据挖掘的时间,但是一些隐含在数据中的非频繁特征项容易被忽略掉,难以发现足够有用的规则;
2)如果支持度和置信度阈值过低,可能会导致大量冗余和无效的规则产生,导致较大计算量负荷。
1.2 应用场景
(1)电商行业
著名的“啤酒尿布”案例,通过分析历史用户的支付订单记录,挖掘出比如中年男人会同时购买啤酒和尿布两种商品,后续可以在商品陈列、打折促销组合、交叉营销发送优惠券等场景中应用。穿⾐搭配推荐穿⾐搭配是服饰鞋包
导购中⾮常重要的课题,基于搭配专家和达⼈⽣成的搭配组合数据,百万级别的商品的⽂本和图像数据,以及⽤户的⾏为数据。期待能从以上⾏为、⽂本和图像数据中挖掘穿⾐搭配模型,为⽤户提供个性化、优质的、专业的穿⾐搭配⽅案,预测给定商品的搭配商品集合。
(2)社会民生
- 互联⽹情绪指标和⽣猪价格的关联关系挖掘和预测
- ⽓象关联分析
- 交通事故成因分析
(3)金融行业
- 银⾏客户交叉销售分析
- 银⾏营销⽅案推荐
(4)文娱体育
- 影视演员组合
- 球员最优组合
(5)网络安全
- 自动化规则生成
1.3 常见算法
(1)算法
- 关联规则算法:典型如Apriori,PySpark中为FP-Growth;
关联规则算法是挖掘频繁项集的算法,1993年由Rakesh Agrawal 和Ramakrishnan Skrikant提出,并应用于IBM的业务场景。
- 序列模式算法:典型算法如Apriori-All,PySpark中为PrefixSpan;
与关联规则算法类似,不同点在于序列模式会考虑频繁项集中的时序先后关系
(2)优化
大部分的算法都是先频繁模式再关联规则流,算法的优化目的都是减少数据扫描的时间成本。
- 树基算法:FP-Growth, PrePost, CFP-Growth算法等,核心要义是把原始事务数据转换为树状数据结构,减少扫描事务的成本。
- 二进制向量算法:BitTableFI, IndexBitTableFI等,核心要义是把原始数据转换为二进制向量,用逻辑运算与矩阵运算来代替数据扫描,加快速度。
- 可靠采样流派:中心极限定理等,核心要义是通过采样来减少数据规模来加速。支持度就是频率,频率与其对应概率的差根据中心极限定理服从期望为0的正态分布。以此为理论基础,可以在频繁模式支持度误差可控的情况下,推导出合理的样本规模。
- 渐进采样流派:Progressive sampling,不推公式(当然有些算法用到了齐夫定理,但是鉴于Zipf定理是经验定理,不算很严谨),慢慢增加样本,然后选取几个代表性的项集,以其两个样本规模间的支持度变化量来决定采样是否足够。当变化足够小时,说明样本够了。
二、参考文献
- 目前流行的关联规则算法有哪些?
- 关联规则-策略挖掘中必不可少的算法
- 关联规则挖掘在实际中的应用有哪些? - 李小翰的回答 - 知乎 https://www.zhihu.com/question/62342815/answer/2616887115