深度学习-GNN(1)图嵌入
图神经网络:从入门到放弃:https://www.zhihu.com/column/c_1322582255018184704
图卷积:从GCN到GAT、GraphSAGE

一、图卷积:从GCN到GAT、GraphSAGE
前言
图模型总体上可以分为两大类:一是random-walk游走类模型,另一类就是GCN、GAT等卷积模型了。
下面就自己学习卷积图模型过程的一些模型GCN、GAT、GraphSAGE 及疑问总结一下,欢迎交流学习。
1.1 为什么出现GCN来处理图结构?
在图像领域,CNN被拿来自动提取图像特征的结构,但是CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵,虽然图结构不整齐(不同点具有不同数目neighbors),但是不是可以用同样的方法去抽取图的的特征呢?
于是就出现了两种方式来提取图的特征。一是空间域卷积(spatial domain),二是频域卷积(spectral domain)。第一种方式由于每个顶点提取出来的neighbors不同,处理上比较麻烦,同时它的效果没有频域卷积效果好,没有做深究。因此,现在比较流行、工程上应用较多的为频域卷积。
1.2 GCN的计算原理
GCN的卷积核心公式:
分别是第l层、第l+1的节点,D为度矩阵,A为邻接矩阵,如下图。
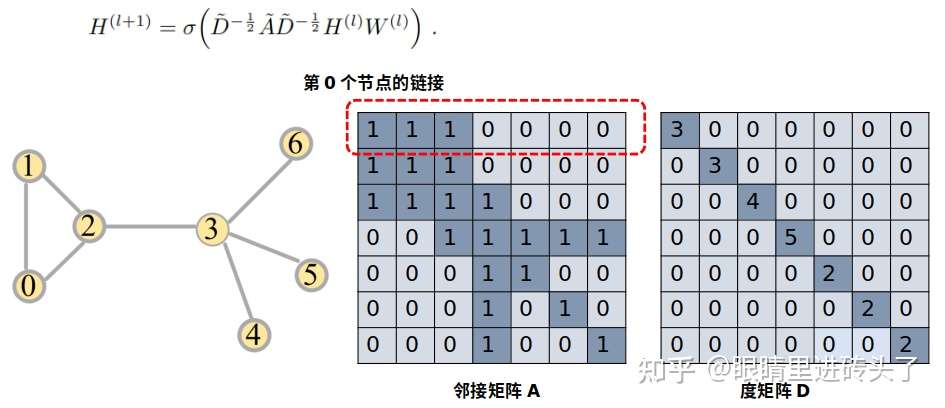
GCN计算方式上很好理解,本质上跟CNN卷积过程一样,是一个加权求和的过程,就是将邻居点通过度矩阵及其邻接矩阵,计算出各边的权重,然后加权求和。
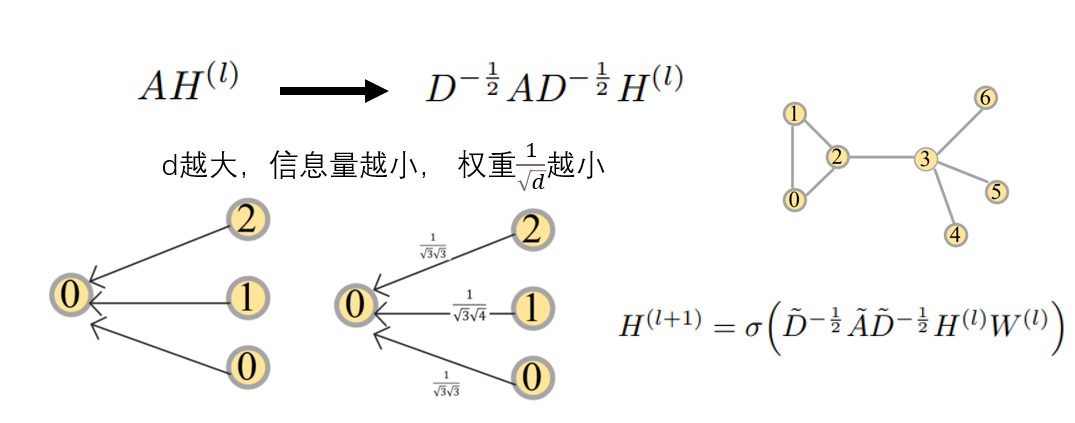
D负责提供权值的矩阵,邻接A矩阵控制应该融合哪些点, H表示上一层的embedding参数。
结合上面两张图,动手算一算 ,能很清楚的看到,这个加权求和的卷积过程是怎么做的。
GCN 小结一下:
GCN首次提出了卷积的方式融合图结构特征,提供一个全新的视角。
主要缺点:
- 问题1:融合时边权值是固定的,不够灵活。
- 问题2:可扩展性差,因为它是全图卷积融合,全图做梯度更新,当图比较大时,这样的方式就太慢了,不合适。
- 问题3:层数加深时,结果会极容易平滑,每个点的特征结果都十分相似。
GAT就来解决问题1的,GraphSAGE就来解决这个问题2的,DeepGCN等一系列文章就来讨论问题3的。基本上,GCN提出之后,后续就是各路神仙打架了,都是针对GCN的各个不同点进行讨论改进了。
1.3 带attention的图注意网络GAT
attention这么流行,看完GCN就容易想到,GCN每次做卷积时,边上的权重每次融合都是固定的,那能不能灵活一点,加个attention,让模型自己去学,那GAT就来干这个事了。
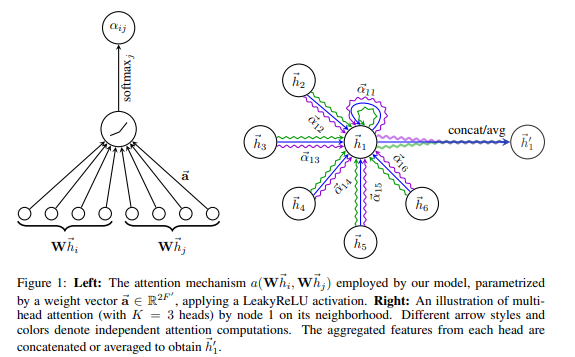
结合下面这两各公式,看看这个attention是怎么定义的。
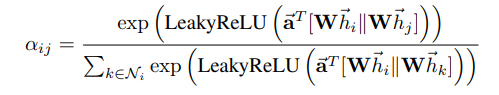
表示第i个点与第j个点之间的attention系数,是node
feature,其他a、W的为模型参数。
就是通过计算
,在经过Normalize处理一下得到。
得到各条边的 之后,第i个点的融合attention过后的node
feature可以表示下面这个公式,实质上还是一个加权的feature求和过程,只是每次融合中的权重系数是随模型训练学习的,最后在经过一个非线性的激活函数去做对应的任务。
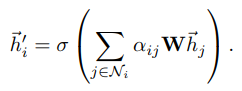
在这个基础上,文中还提到了,为了使attention机制更具扩展性,定义multi-head attention机制(K代表K个attention head),去做attention权重的计算,然后concat起来,得到node feature。
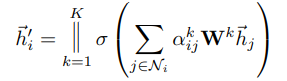
当在网络最后一层时,concat输出的维度就node feature太大,不太合理,就改用累加再平均,然后输出,做具体任务。
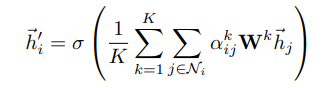
以上就是第一个图中右边示意的结构了。
GAT 小结一下:
GAT中的attention机制还是很直观的,通过给每条边加了一个模型可学习的系数
,进行带attention系数的node
feature融合,使得在做卷积融合feature的过程,能够根据任务调整模型参数,变得自适应使得效果更好。
今年还出了一篇专门讨论GAT的工作的,讨论attention到底学到了的是什么,感兴趣的可以去看看How Attentive are Graph Attention Networks?
1.4 可扩展的图网络Graph-SAGE
前面说到,GCN中做卷积融合是全图的,梯度是基于全图更新,若是图比较大,每个点邻居节点也较多,这样的融合效率必然是很低的。于是GraphSAGE出现了。
在提GraphSAGE前,先解释下transductive learning、inductive learning的概念,这也是GraphSAGE与其他图模型的区别。
- transductive是说要预测的数据在训练时模型也能看到。进一步解释一下,就是说训练前,构建的图结构已经是固定的,你要预测的点或边关系结构都应该已经在这个图里了,训练跟预测时的图结构都是一样的。
- inductive是说要预测的数据在训练时模型不用看到,也就是我们平常做算法模型的样子,训练预测时的数据是分开的,也就是上面说的可以图结构不是固定的,加入新的节点。
GraphSAGE就是inductive的模式,GraphSAGE提出随机采子图的方式去采样,通过子图更新node embedding, 这样采出的子图结构本身就是变化,从而让模型学到的是一种采样及聚合的参数的方式,有效解决了unseen nodes问题,同时避免了训练中需要把整个图的node embedding一起更新的窘境,有效的增加了扩展性。
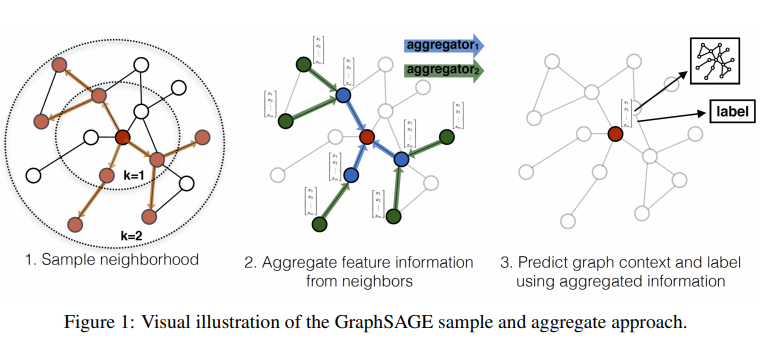
具体的思想就是分三步:
- 采子图:训练过程中,对于每一个节点采用切子图的方法,随机sample出部分的邻居点,作为聚合的feature点。如上图最左边,对于中心点,采两度,同时sample出部分邻居节点组成训练中的子图。
- 聚合:采出子图后,做feature聚合。这里与GCN的方式是一致的,从最外层往里聚合,从而聚合得到中心点的node embedding。聚合这里可操作的地方很多,比如你可以修改聚合函数(一般是用的mean、sum,pooling等),或增加边权值都是可以的。
- 任务预测: 得到node embedding后,就可以接下游任务了,比如做node classification,node embedding后接一个linear层+softmax做分类即可。
具体到代码实现思路上,也是与上述思路高度一致。

也是针对每一个node采出子图,然后进行聚合,最后得到node embedding。
举例:假设中心点为v,采点v的K度子图
- 采出中心点v的K层子图中邻居点u,然后一层层聚合,聚合得到邻居节点node
feature
- 中心点与它的邻居点通过concat方式聚合,
,在经过一个非线性函数处理。
- 最后再Normalize归一化处理一下,得到最后的node embedding
- 以上述这种方式,从最外层往里聚合,一直聚合到最初的中心点v,点v的node embedding 就更新完成了。
GraphSAGE小结一下:
GraphSAGE主要解决了两个问题:
- 解决了预测中unseen nodes的问题,原来的GCN训练时,需要看到所有nodes的图数据。
- 解决了图规模较大,全图进行梯度更新,内存消耗大,计算慢的问题
以上两点都是通过一个方式解决的,也就是采子图的方式,由于采取的子图是局部图且是随机的,从而大大增加模型的可扩展性,但这也有一个问题可以思考一下,这个随机采子图的方式是合理的吗?这种方式会不会损失掉部分这个图的node信息,欢迎交流学习。
对以上感兴趣的还可以看看Cluster-GCN,它通过图聚类的方式去划分子图分区,从而,进一步提高了计算效率。