深度学习-NLP(7)ELMO
ELMO-具有上下文语境的词嵌入
https://zhuanlan.zhihu.com/p/504527165
1.从静态词嵌入到动态词嵌入(具有语境的词嵌入)
词嵌入:将词用一个具有语义信息的多维向量来表示
静态词嵌入:多维稠密向量来表示,是一个固定的向量,不会根据语境的差异发生改变, 没办法结合语境给出正确的词向量,即一词多义的问题
动态词嵌入:根据不同的上下文语境调整词的语义,能较好的应对一词多义(polysemy)问题
如何做到动态词嵌入呢?NAACL 2018 best paper ELMO(Embeddings from Language Model)能给你一个较好的答案
2.ELMO:Deep Contextualized Word Representations
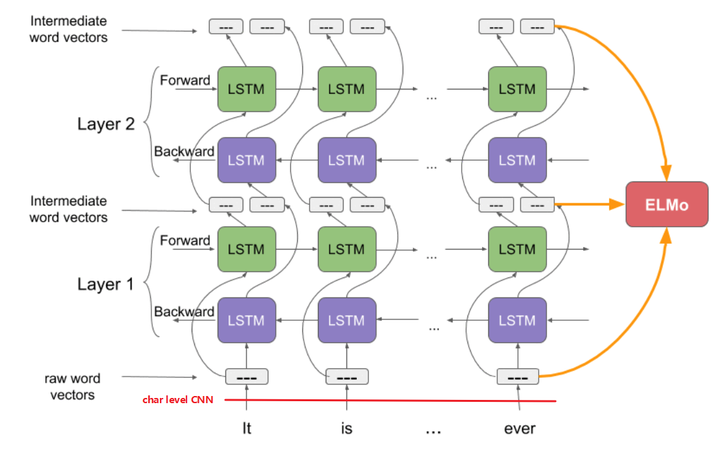
可以看到模型整体由 前向+后向LSTM 与 CNN 字符嵌入组成,详情见下图,还是非常直观的
- CNN字符嵌入: 输入一句话(多个word) 先由CNN字符嵌入进行编码 得到每个word的词向量,简单来说就是把一个词分解成字母,然后对字母进行卷积操作获得词向量;
- 将词向量按照顺序分别输入到前向 后向
LSTM中进行嵌入:其实就是基于已知的词预测下一个词,对词的编码采用LSTM架构(不熟悉LSTM的话就简单看成是一个编码器就行了)前向+后向分别是从前到后和从后到前,注意:前向和后向的LSTM之间并不连接,why?
假如连接了预测过程就相当于泄题了,这个地方比较抽象,让我再深入一下:
- 假如这里有一句话,由N个词组成
组成,LSTM具有较好的记忆能力,能够记忆已经给出序列的信息,前向LSTM从前向后扫的时候会不停的记忆已知的信息,每一时刻预测结果出来以后会将其信息存储起来,这样每次预测下一时刻信息的时候都会已知前面词的信息,比如:预测
时已知
;预测
时已知
.
- 相应的,后向LSTM也一样,只不过词的输入顺序反过来了,在这里是从
当t=N-1的时候,(就相当于前向LSTM的t=2时刻), 后向LSTM会存储着
的信息
- 对于前向LSTM来说,在t=3时刻,预测x_3,
后向LSTM存储着的
- 假如这里有一句话,由N个词组成
- 将CNN层的输出与多个LSTM层的输出拼接在一起 就得到一个词的表示了