Pytorch(3)Autograd 与逻辑回归
[PyTorch 学习笔记] Autograd 与逻辑回归
自动求导 (autograd)
在深度学习中,权值的更新是依赖于梯度的计算,因此梯度的计算是至关重要的。在
PyTorch
中,只需要搭建好前向计算图,然后利用torch.autograd自动求导得到所有张量的梯度。
torch.autograd.backward():自动求取梯度
1 | torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None) |
- tensors: 用于求导的张量,如 loss
- retain_graph: 保存计算图。PyTorch 采用动态图机制,默认每次反向传播之后都会释放计算图。这里设置为 True 可以不释放计算图。
- create_graph: 创建导数计算图,用于高阶求导
- grad_tensors: 多梯度权重。当有多个 loss 混合需要计算梯度时,设置每个 loss 的权重。
==逻辑回归 (Logistic Regression)==
逻辑回归是线性的二分类模型。模型表达式 ,其中
。
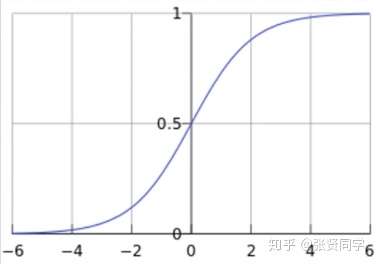
称为 sigmoid 函数,也被称为 Logistic
函数。函数曲线如下:(横坐标是
,而
,纵坐标是
)
分类原则如下:class 。当
时,类别为 0;当
时,类别为 1。
其中 就是原来的线性回归的模型。从横坐标来看,当
时,类别为 0;当
时,类别为
1,直接使用线性回归也可以进行分类。逻辑回归是在线性回归的基础上加入了一个
sigmoid 函数,这是为了更好地描述置信度,把输入映射到 (0,1)
区间中,符合概率取值。
逻辑回归也被称为对数几率回归 ,几率的表达式为:
,
表示正类别的概率,
表示另一个类别的概率。根据对数几率回归可以推导出逻辑回归表达式:
==PyTorch 实现逻辑回归==

PyTorch 构建模型需要 5 大步骤:
- 数据:包括数据读取,数据清洗,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强。
- 模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层。
- 损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。
- 优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。
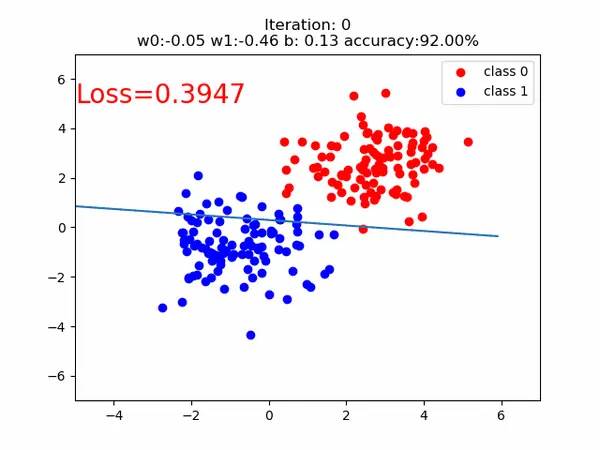
- 迭代训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。
1 | import torch |
训练的分类直线的可视化如下: