工业落地-STIX协议 《网络威胁情报协议》
网络威胁情报之 STIX 2.1
https://zhuanlan.zhihu.com/p/365563090
一、说明
STIX(Structured Threat Information Expression)是一种用于交换网络威胁情报(cyber threat intelligence,CTI)的语言和序列化格式。STIX的应用场景包括:协同威胁分析、自动化威胁情报交换、自动化威胁检测和响应等。
STIX对网络威胁情报的描述方法如下:
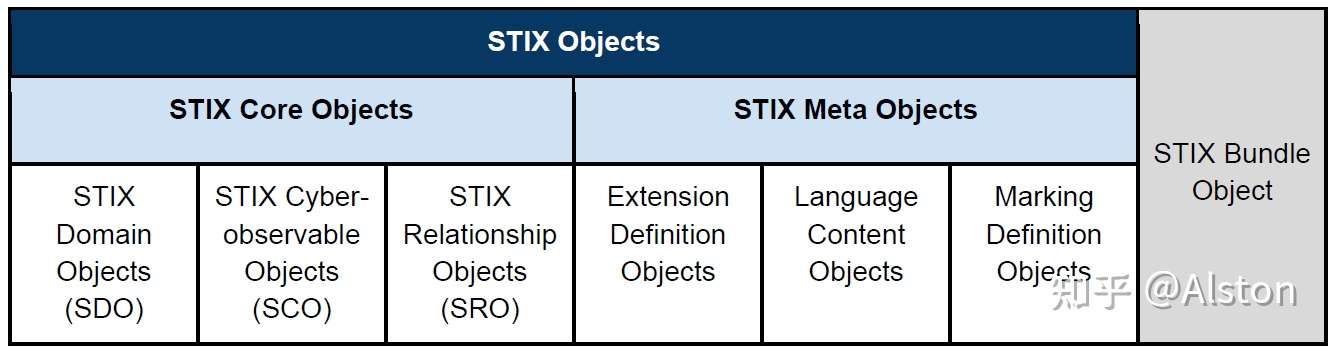
STIX Domain Objects(SDO):威胁情报主要的分类对象,包含了一些威胁的behaviors和construct,共有18种类型:Attack Pattern, Campaign, Course of Action, Grouping, Identity, Indicator, Infrastructure, Intrusion Set, Location, Malware, Malware Analysis, Note, Observed Data, Opinion, Report, Threat Actor, Tool, and Vulnerability.


STIX Cyber-observable Objects(SCO):威胁情报中具体的可观察对象,用于刻画基于主机或基于网络的信息。
- SCO会被多种SDO所使用,以提供上下文支持,如Observed Data SDO,表示在特定时间观察到的raw data;在STIX2.0中,SCO在SDO中出现时只会以Observed Data的形式出现,在STIX2.1则不限于此。
- SCO本身不包括who,when和why的信息,但是将SCO和SDO关联起来,可能会得到这些信息以及对威胁更高层面的理解。
- SCO可以捕获的对象包括文件、进程、IP之间的流量等。
STIX Relationship Objects(SRO):用于SDO之间、SCO之间、SDO和SCO之间的关系。SRO的大类包括以下两种:

generic SRO(Relationship):大多数关系所采用的类型,其relation_type字段包括:内置关系:如Indicator到Malware之间的关系,可以用indicates 表示,它描述了该Indicator可用于检测对应的恶意软件;自定义关系;
Sighting SRO:用于捕获实体在SDO中出现的案例,如sighting an indicator。没有明确指明连接哪两个object。之所以将其作为独立的SRO,是因为其具有一些独有的属性,如count。
除了SRO,STIX还用ID references来表示嵌入关系(embedded relationship)。当使用嵌入关系时,表示该属性时该对象的内置属性,从而不需要使用SRO表示,如create_by_ref。因此,SRO可以视为两个节点直接的边,而embedded relationship则可以视为属性(只不过其表示了二元关系)
- STIX Meta Objects:用于丰富或扩展STIX Core Objects
- STIX Bundle Object:用于打包STIX内容
STIX是一种基于图的模型,其中SDO和SCO定义了图的节点,而STIX relationships定义了边。
STIX Patterning language:STIX模式语言可以实现网络或终端的威胁检测。该语言目前使用STIX Indicator对象,来匹配时序的observable data。
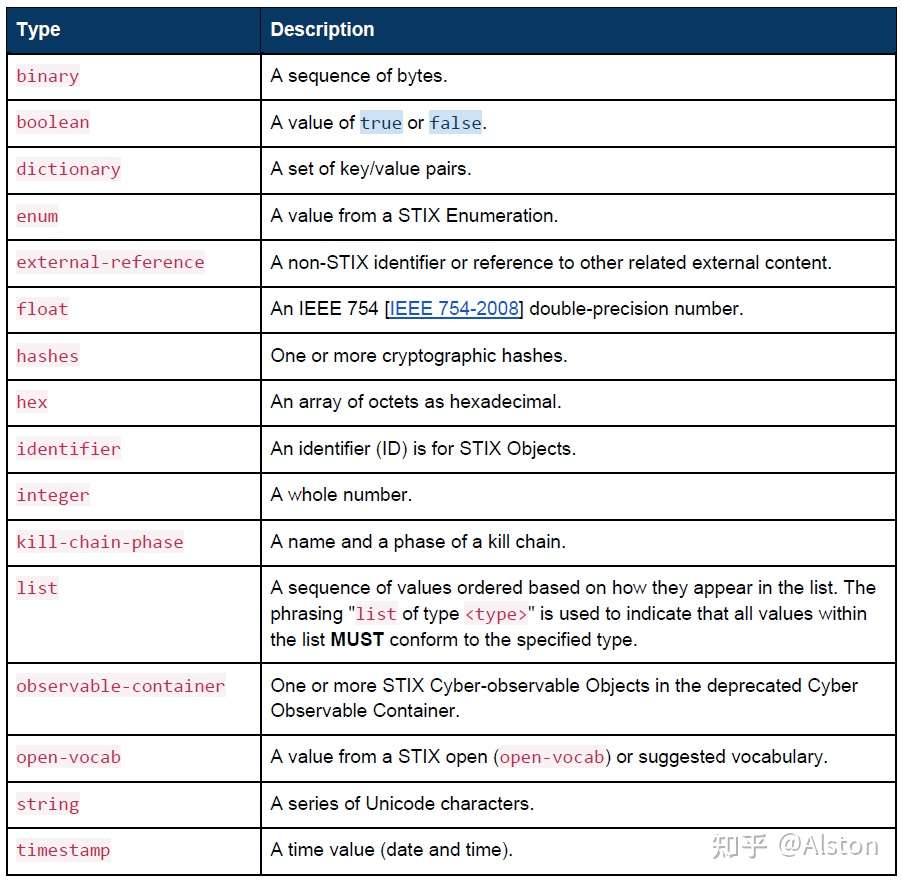
二、通用数据类型
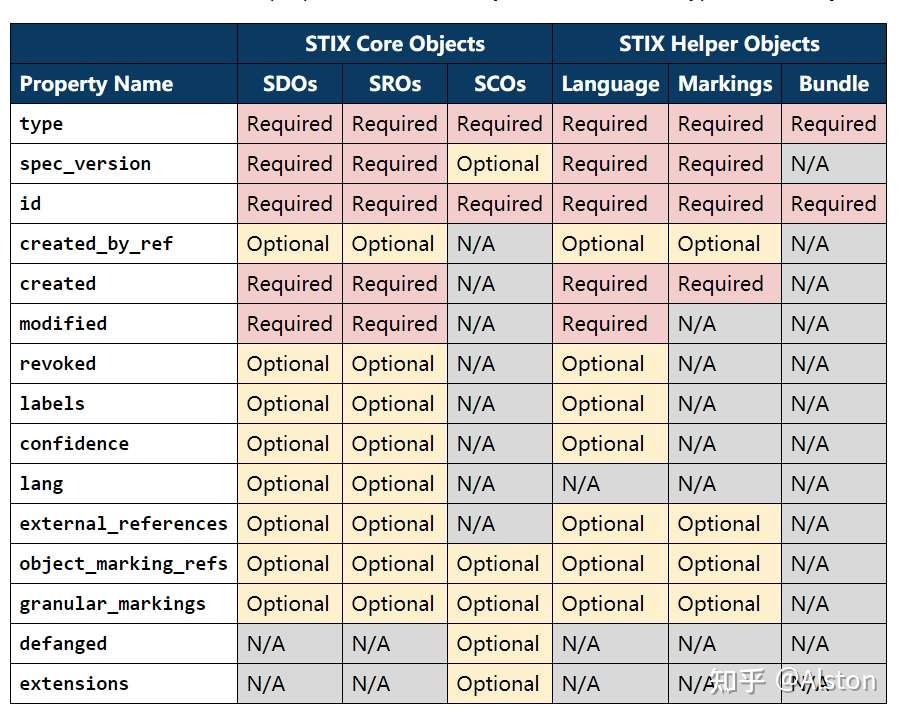
三、 STIX 通用概念
- STIX common properties
四、 STIX Domain Objects
每个SDO对应 交换网络威胁情报CTI中的唯一概念。使用SDO,SCO和SRO作为基本模块,用户可以方便的创建和共享CTI。
SDO:
- Property:通用属性、SDO转专用属性
- Relationship:embedded relationships、common relationships
一些相似的SDO可以被归为一个大类,如:
- Attack Pattern, Malware, and Tool可以被归为TTP,因为它们描述了攻击行为和资源
- Campaign, Intrusion Set, and Threat Actor 可以被描述为“攻击者发动攻击的原因,以及如何组织(why and how)”
4.1 Attack Pattern
TTP类型之一,它描述了攻击者试图破坏目标的方式,对应于TTP中的战术。可用于帮助对攻击进行分类,将特定的攻击概括为其遵循的模式,并提供有关如何进行攻击的详细信息。
如spear fishing就是一种攻击模式,而更具体的描述,如被特定攻击者实施的spear fishing也是一种攻击模式。
4.2 Campaign
表示某次具体的攻击活动。A Campaign is a grouping of adversarial behaviors that describes a set of malicious activities or attacks (sometimes called waves) that occur over a period of time against a specific set of targets. Campaigns usually have well defined objectives and may be part of an Intrusion Set.
战役是一组敌对行为,描述了针对特定目标集在一段时间内发生的一组恶意活动或攻击(有时称为WAVE)。活动通常有明确的目标,可能是入侵集的一部分。
4.3 Course of Action (响应的行为)
用于预防攻击或对攻击做出响应的行为,它回包含技术,自动化响应(补丁、重新配置防火墙),或高级别的动作(如员工培训或者策略制定)。
4.4 Grouping
Grouping表示分析和调查过程中产生的数据(待确认的线索数据);还可以用来声明其引用的STIX对象与正在进行的分析过程有关,如当一个安全分析人员正在跟其它人合作,分析一系列Campaigns和Indicators的时,Gouping会引用一系列其它SDO、SCO和SRO(Grouping就表示协作分析吧)。
除了embedded relationship和common relationship之外,没有明确定义Grouping对象和其它STIX对象之间的关系。
4.5 Identity
Identity可以代表特定的个人、组织或团伙;也可以代表一类个人、组织、系统或团伙。Identity SDO可以捕获基本标识信息,联系信息以及Identity所属的部门。 Identity在STIX中用于表示攻击目标,信息源,对象创建者和威胁参与者身份。
4.6 Incident
stub对象,待完善,没有专门定义的property和relationship。
4.7 Indicator
Indicator表示可用于检测可疑行为的模式。如用STIX Patterning Language来描述恶意域名集合(第九章)。
4.8 Infrastructure
TTP的类型之一,用于描述系统、软件服务等其它的物理或虚拟资源;如攻击者使用的C2服务器,防御者使用的设备和服务器,以及作为被攻击目标的数据库服务器等;
基于此我们可以将受保护网络中的设备纳入知识图谱,采用类似于这样的关系:

4.9 Intrusion Set
Intrusion set是由某个组织所使用的恶意行为和资源的集合。一个Intrusion Set可能会捕获多个Campaigns,他们共同指向一个Threat Actor。新捕获的活动可以被归因于某个Intrusion Set,而Actors可以在Intrusion之间跳转,甚至从属于多个Intrusion Set。
如在 apt1.json 中,整个报告被打包在bundle中,而Intrusion Set用来指示APT组织:
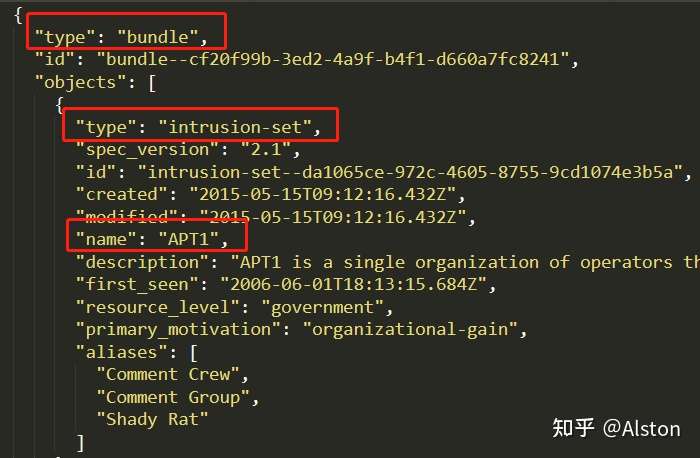
Intrusion Set和Campaigns对比:
如果 Campaigns 是在一段时间内针对一组特定目标进行的一组攻击,以实现某些目标,那么入侵集就是整个攻击包,可以在多个活动中长期使用,以实现潜在的多个目的.由Intrusion Set找出Threat Actors,nation state或者nation state中的某个APT组织,是一个溯源的过程。
4.10 Location
表示具体地点,可以与Identity或Intrusion Set相关联,表示其位置;与Malware或Attack Pattern相关联,表示其目标。
4.11 Malware
TTP类型之一,表示恶意软件或代码。
4.12 Malware Analysis
捕获了在恶意软件实例或恶意软件家族分析过程中,动态分析或静态分析的结果。
4.13 Note
其他对象中不存在的额外信息;例如,分析人员可以在一个Campaign对象中添加注释,以表明他在黑客论坛上看到了与该Campaign相关的帖子。同样,Note对象也没有定义与其他STIX Object之间的关系。
4.14 Observed Data
网络安全相关的可观察对象(raw information)集合,其引用对象为SCO,包含从analyst reports, sandboxes, and network and host-based detection tools等收集的信息。
必须包含objects或者object_refs属性,表示对SCO的引用:
Observed Data只有反向关系。此外,还会被Sighting SRO所指向:Sightings represent a relationship between some intelligence entity** that was seen** (e.g., an Indicator or Malware instance), where it was seen, and what evidence was actually seen. The evidence (or raw data) in that relationship is captured as Observed Data(Sighting中的证据就是Observed Data)。
4.15 Opinion
Opinion是对STIX对象中信息正确性的评估。
4.16 Report
威胁情报报告。
4.17 Threat Actor
攻击的个人、团体或组织;其与Intrusion Set不同,Threat Actor会同时支持或附属于不同的Intrusion Set、团体或组织。
4.18 Tool
Tool是威胁参与者可以用来执行攻击的合法软件。与Malware不同,Tool一般是合法软件,如Namp、VNC。
4.19 Vulnerability
漏洞。用于连接相关漏洞的外部描述(external_references),或还没有相关描述的0-day漏洞。
Q&A:
- Q1:embedded relationship和节点property有啥区别?property是节点属性,embedded relationship是带有二元关系的节点属性
- Q2:Observed Data和SCO有啥区别?Observed Data观察行为与观察对象的信息,而SCO是具体可观察实体的信息,二者是引用与被引用的关系
- Q3:Intrusion Set、Identity和Threat Actor的区别?Intrusion Set是最高层的实体,其包括Identity和Threat Actor,如APT1(高层APT组织)为Intrusion Set,其包含一些个人(Ugly Gorilla)或团体(SuperHard)的Threat Actor,而Identity是用真实名称描述的个人或组织(如Ugly Gorilla指向Wang Dong)。由此看来,Threat Actor也可以用真是名称描述(Communist Party of China),但是明显指示了其表示威胁主体,而Identity本身不显示其角色信息。
五、 STIX Relationship Objects
5.1 Relationship
Type Name: relationship
用于连接STIX中的SDO或SCO; STIX中的Relationship在每个SDO或SCO的定义中进行了描述, 用户还可以自定义关系。STIX中所有内置的Relationship详见文档Appendix B。注意, Relationship本身也是一个对象, 因此其也有自身的 Property 和 Relationships。
5.2 Sighting
Type Name: sighting
原文定义:目击(sighting)表示认为在CTI中看到了某些东西(例如指示器、恶意软件、工具、威胁因素等)。目击用于跟踪目标是谁和什么,如何实施攻击,以及跟踪攻击行为的趋势。
A Sighting denotes the belief that something in CTI (e.g., an indicator, malware, tool, threat actor, etc.) was seen. Sightings are used to track who and what are being targeted, how attacks are carried out, and to track trends in attack behavior.
Sighting 没有连接两个对象, 但却被定义为关系, 原因是:目击包括三部分的内容:• 发现的内容,如指示器、恶意软件、活动或其他SDO(sightingfef)•发现者和/或发现地点,表示为身份(whereightedefs)•系统和网络上实际看到的内容,表示为观察数据(SECUREDataefs)
Sighting is captured as a relationship because you cannot have a sighting unless you have something that has been sighted. Sighting does not make sense without the relationship to what was sighted
Sighting包括三部分的内容:
- What was sighted, such as the Indicator, Malware, Campaign, or other SDO (sighting_of_ref)
- Who sighted it and/or where it was sighted, represented as an Identity (where_sighted_refs)
- What was actually seen on systems and networks, represented as Observed Data (observed_data_refs)
Sighting和Observed Data的区别:
目击与观察到的数据不同,因为目击是一种情报断言(“我看到了这个威胁参与者”),而观察到的数据只是信息(“我看到了这个文件”)。当您通过包含来自目击的链接观测数据(Observedataefs)来组合它们时,您可以说“我看到了这个文件,这让我觉得我看到了这个威胁参与者”。
Sighting is distinct from Observed Data in that Sighting is an intelligence assertion ("I saw this threat actor") while Observed Data is simply information ("I saw this file"). When you combine them by including the linked Observed Data (observed_data_refs) from a Sighting, you can say "I saw this file, and that makes me think I saw this threat actor".