深度学习-GNN(7)【Nan】metapath2vec
Metapath2vec是Yuxiao Dong等于2017年提出的一种用于异构信息网络(Heterogeneous Information Network, HIN)的顶点嵌入方法。metapath2vec使用基于meta-path的random walks来构建每个顶点的异构邻域,然后用Skip-Gram模型来完成顶点的嵌入。在metapath2vec的基础上,作者还提出了metapath2vec++来同时实现异构网络中的结构和语义关联的建模。
深度学习-GNN(5)【Nan】GraphSAGE
GraphSAGE
GraphSAGE:我寻思GCN也没我牛逼 - 蝈蝈的文章 - 知乎 https://zhuanlan.zhihu.com/p/74242097
【Graph Neural Network】GraphSAGE: 算法原理,实现和应用 - 浅梦的文章 - 知乎 https://zhuanlan.zhihu.com/p/79637787
阿里开源的graphlearn:https://graph-learn.readthedocs.io/zh_CN/latest/
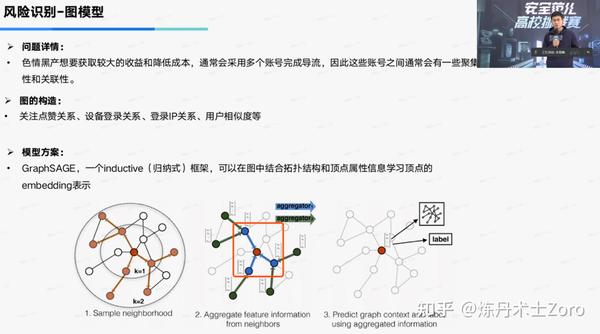
风控反欺诈(2)GraphSAGE算法在网络黑产挖掘中的思考.md
graphSAGE-pytorch:https://github.com/twjiang/graphSAGE-pytorch
众所周知,2017年ICLR出产的GCN现在是多么地热门,仿佛自己就是图神经网络的名片。然而,在GCN的风头中,很多人忽略了GCN本身的巨大局限——Transductive Learning——没法快速表示新节点,这限制了它在生产环境中应用。同年NIPS来了一篇使用Inductive Learning的GraphSAGE,解决了这个问题。今天,让我们来一起琢磨琢磨这个GraphSAGE是个什么玩意儿。
一、回顾GCN及其问题
对GCN不熟悉的盆友,可以看看我的上一篇文章: 蝈蝈:何时能懂你的心——图卷积神经网络(GCN)
- GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。
- GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。
- GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。
二、GraphSAGE
既然新增的节点,一定会改变原有节点的表示,那么我们干嘛一定要得到每个节点的一个固定的表示呢?我们何不直接学习一种节点的表示方法。这样不管graph怎么改变,都可以很容易地得到新的表示。
基本思想:
去学习一个节点的信息是怎么通过其邻居节点的特征聚合而来的。 学习到了这样的“聚合函数”,而我们本身就已知各个节点的特征和邻居关系,我们就可以很方便地得到一个新节点的表示了。
GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
深度学习-GNN(3)node2vec
Node2Vec
【Graph Embedding】node2vec:算法原理,实现和应用 - 浅梦的文章 - 知乎 https://zhuanlan.zhihu.com/p/56542707
DeepWalk的思路非常直接,就是结合随机游走和Skip-gram模型。尽管DeepWalk利用完全随机的游走,得到了相对小的游走时的时空复杂度,==但是这种游走的策略显然没有考虑到图中节点间的连接"强度",同时也无法很好的考虑到图中节点的结构等价性(structural equivalence)和同质性(homophily),生成的游走序列完全"听天由命"==。
Node2Vec[2]是一篇16年文章,它修改了DeepWalk中的游走策略,使其能够更灵活的捕捉图中节点的结构等价性和同质性。
2.1 Overview of the Model
二阶随机游走(二阶马尔科夫)


具体来说,如上图,我们可以说节点s1和节点u具有同质性,因为它们都属于图中同一个community/cluster;我们也会说节点u和节点s6具有结构等价性,因为它们在网络中扮演的角色十分类似,都是簇的中心。
Node2Vec的作者们宣称:
- 倘若随机游走倾向于BFS,那么生成的序列会更倾向于在起点的附近进行探索,这样能够更好的捕捉节点间的同质性;
- 若随机游走倾向于DFS,那么生成的序列会探索图中更大的区域,使得模型有机会捕捉到节点间的结构相似性。
以上陈述中,BFS能更好的捕捉同质性应该是比较直观的,毕竟它只会在起点附近震荡,也就意味着它能确保与起点近邻的节点均能习得近似的表达。但是DFS只是捕捉节点间结构等价性的必要条件而非充分条件。如果没有DFS,模型可能根本无法跳出起点的簇中,那么节点的结构等价性的捕捉也无从谈起。但是如果只是DFS,那么我们只能知道这两个距离很远的节点有某种依赖性,但我们无从得知这是怎样的依赖性,比如,它们都是簇的中心吗?还是它们都是各个簇的成员而已?
因此作者们提出了一个biased 2nd order random walk,其引入了两个额外的参数p和q,以在游走中控制和融合BFS与DFS。这个游走被称作二阶随机游走的原因是:游走的下一步不仅取决于当前的节点,也取决于当前节点的上一步的节点。这和二阶马科夫假设是类似的。

具体来说,上图为游走的一个例子。其中,节点v是当前节点,节点t是游走的上一步的节点,而我们现在要决定节点v的下一步x是哪一个节点。此时的游走概率由α决定,其公式为:

- 其中dtx指节点x与节点t之间的距离。有了α后,游走的(未经归一化的)转移概率可计算为\(π_{vx}=α_{pq}(t,x)⋅w_{vx}\),其中\(w_{vx}\)是节点v与节点x之间的权重。
- 直观来说,若p越大,越不容易返回上一步游走到的节点,这能鼓励模型游走的更远,若p越小,则更容易返回上一步节点,使得模型倾向于在起点周围进行探索;若q越大,游走会更倾向于在上一步节点t的周围进行探索,若q越小,游走会更倾向于探索距离上一步节点t更远的节点。在p和q之间trade off,可以控制随机游走的倾向性,从而达到更好的效果。特别的,当p=q=1时,Node2Vec等价于DeepWalk。
Node2Vec中提出的随机游走,若结合Alias Sampling策略,在额外引入O(2|E|)的时空复杂度后,也可以在O(1)内完成一步游走的采样,因此整个游走的复杂度是 \(O(lk|V|+2|E|)\)。基本上这就是Node2Vec这篇文章的核心了,后续同DeepWalk一样基于采样得到的序列训练Skip-gram模型即可。
2.2 Alias Sampling
4. Summary
DeepWalk和Node2Vec的思路都非常简单直接,也能取得可观的效果。它们与那些矩阵分解算法在同一时期被提出,但由于基于随机游走的算法有着更好的可扩展性,并且也能更好的泛化到新节点上,DeepWalk和Node2Vec远远比GraRep、HOPE这些模型流行的多。
但是,随着GCN的出现,无法共享参数的这些基于随机游走的模型也渐渐不再火热,如今的图机器学习领域已将重点放在了图神经网络的研究之中。
总体来说,DeepWalk和Node2Vec这类模型的优点有:
- 相比于矩阵分解模型来说,可扩展性更强
- 虽然本身不是inductive的,但也能很容易的在训练中加入新的节点
该类模型的局限性有:
- 随机游走的代价事实上是极大的
- Embedding lookup矩阵后直接跟损失函数,模型表达能力有限、节点间无参数共享
- 无法对k阶邻居进行区分,只能知道两两节点是否在同一个窗口中出现过,这样事实上丢失了图中部分拓扑信息,可能导致模型效果受限;
- 无法直接利用节点的特征
- Transductive

风控反欺诈(2)GraphSAGE算法在网络黑产挖掘中的思考
GraphSAGE图算法在网络黑产挖掘中的思考
Harry 高级研究员-DataFunTalk https://mp.weixin.qq.com/s/sZ7VQz26c5mrWAsnMKx8Hw
graphSAGE-pytorch:https://github.com/twjiang/graphSAGE-pytorch/tree/master/src
导读:虚拟网络中存在部分黑产用户,这部分用户通过违法犯罪等不正当的方式去谋取利益。作为恶意内容生产的源头,管控相关黑产用户可以保障各业务健康平稳运行。当前工业界与学术界的许多组织通常采用树形模型、社区划分等方式挖掘黑产用户,但树形模型、社区划分的方式存在一定短板,为了更好地挖掘黑产用户,我们通过图表征学习与聚类相结合的方式进行挖掘。本文将为大家介绍图算法在网络黑产挖掘中的思考与应用,主要介绍:
- 图算法设计的背景及目标
- 图算法GraphSAGE落地及优化
- 孤立点&异质性
- 总结思考
一、 图算法设计的背景
在虚拟网络中存在部分的黑产用户,这部分用户通过违法犯罪等不正当的方式去谋取利益,比如招嫖、色情宣传、赌博宣传的行为,更有甚者,如毒品、枪支贩卖等严重的犯罪行为。当前工业界与学术界的许多组织推出了基于图像文字等内容方面的API以及解决方案。而本次主题则是介绍基于账号层面上的解决方法,为什么需要在账号层面对网络黑产的账号进行挖掘呢?
原因主要有三:
- 恶意账号是网络黑产的源头,在账号层面对网络黑产的账号进行挖掘可以对黑产的源头进行精准地打击;
- 账号行为对抗门槛高,用户的行为习惯以及关系网络是很难在短期内作出改变的,而针对单一的黑产内容可以通过多种方式避免被现有的算法所感知,虽然黑产用户可能不懂算法,但其可以通过“接地气”的方式来干扰算法模型,譬如在图片上进行简单的涂抹,在敏感处打上马赛克,在图片处加上黑框,通过简单的对抗手段会对基于黑产内容的算法产生较大的影响;
- 可以防范于未然,通过账号层面的关联提前圈定可疑账号,在其进行违法犯罪行为之前对账号进行相应的处理以及管控。
具体通过什么方式挖掘黑产账号?
首先,简单介绍下在推荐场景中应用。比如广告推荐,通常上,广告商会给予平台方用户的用户标签,用户存在用户标签之后,平台方则会将相关类别的用户找出,然后将广告推送给对应的用户;另一种方式是广告方提供种子包给平台方,平台方会找到相似的用户,然后将广告推送给相关的用户,常见的应用场景有Facebook look like、Google similar audiences。
1.1 应用场景
在黑产场景中与推荐场景中的应用类似,主要分为两个任务场景:
- 找出目标恶意类别用户。比如需要找出散播招嫖信息的用户,则给定该类用户招嫖的标签,类似于一个用户定性的问题;
- 黑产种子用户扩散,即利用历史的黑产用户进行用户扩散以及用户召回,可以通过染色扩散以及相似用户检索等方式完成。
针对恶意用户定性的传统方法,通常采用树形模型,比如说XGboost、GBDT等。这类算法短板显而易见,其缺乏对用户之间的关联进行考虑;另外一种用户召回方式为用户社区划分(相似用户召回),其中比较常用的社区划分算法有FastUnfolding、Copra等。这类算法的缺陷也相当明显,其由于原本社区规模小,所以最终召回的人数也少。且会存在多个种子用户在同一个社区的情况,难以召回大量可疑用户。

通过图表征学习与聚类相结合的方式进行召回。通过图表征学习将图结构的节点属性以及结构特征映射到一个节点低维空间,由此产生一个节点特征,然后再去进行下游的任务,如用户定性即节点分类等。其中,图表征学习的关键点在于在进行低维的映射当中需要保留原始图的结构和节点属性信息。
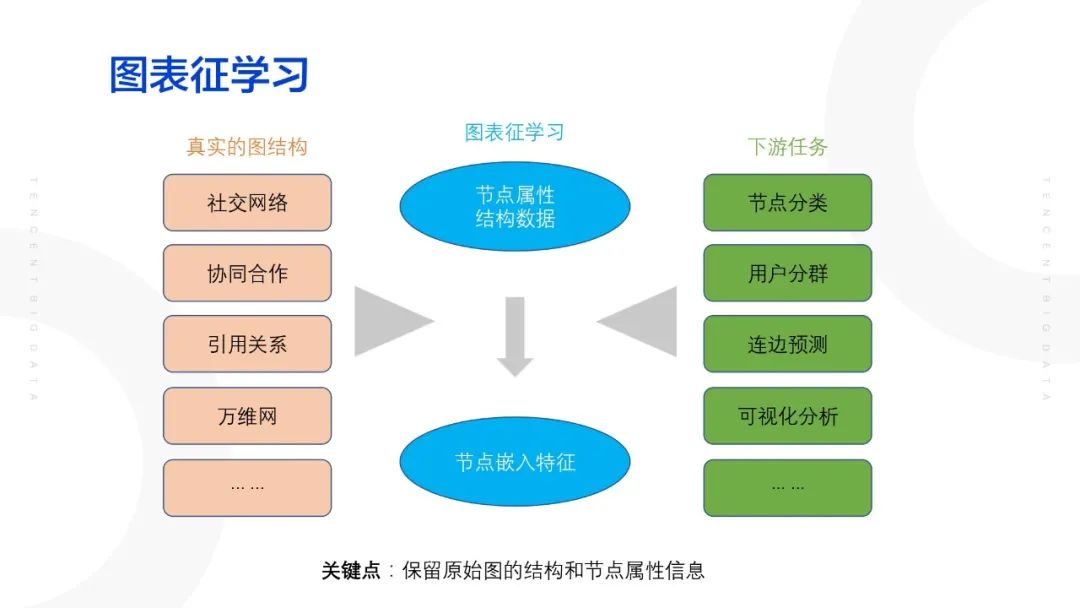
1.2 图算法设计
- 算法的覆盖率和精准度;
- 用户分群规模合理,保证分群的可用性;
- 支持增量特征,下游任务易用性。
由于业务场景更多为动态网络,当新增节点时,如果模型支持增量特征,则不需要重复训练模型,可以极大的减少开发的流程,节省机器学习的资源,缩短任务完成的时间。
二、图算法GraphSAGE落地及优化
2.1 GraphSAGE核心思想
GraphSAGE核心思想主要为两点:邻居抽样;特征聚合。
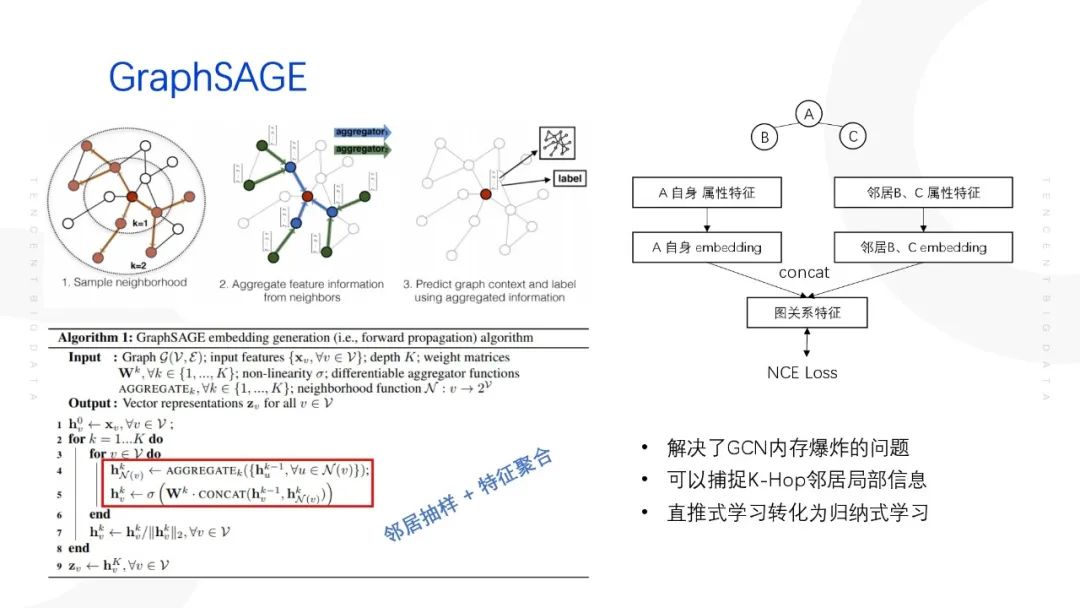
GraphSAGE的聚合过程实际是节点自身的属性特征和其抽样的邻居节点特征分别做一次线性变换,然后将两者concat在一起,再进行一次线性变换得到目标节点的embedding特征。最后利用得到的目标节点的embedding特征进行下游的任务,训练的方式的可以采用无监督的方式,如NCE Loss。
2.2 GraphSAGE的优点
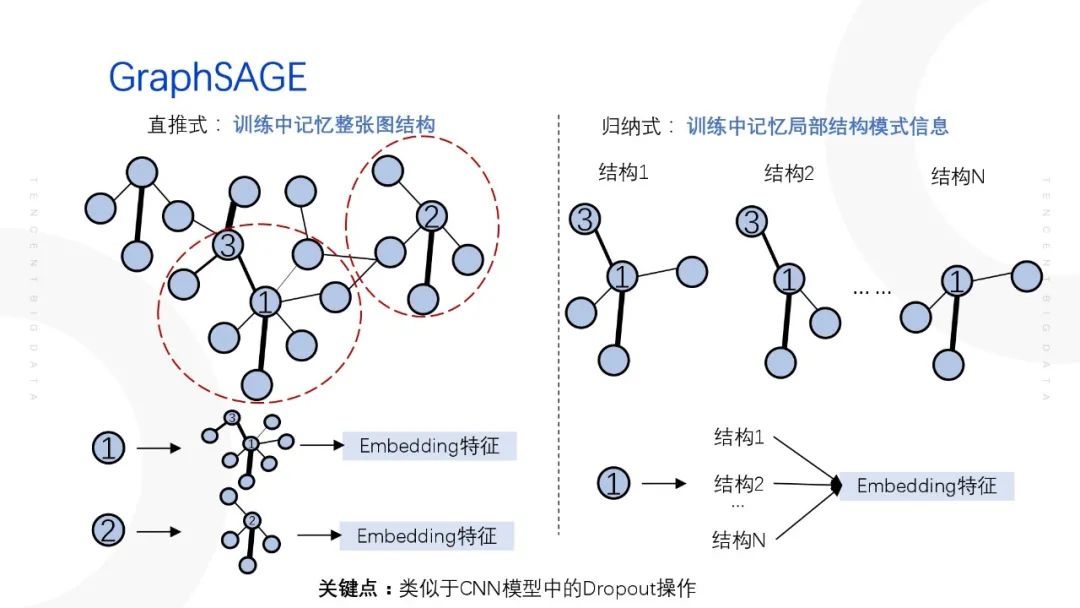
GraphSAGE通过邻居抽样的方式解决了GCN内存爆炸的问题,同时可以将==直推式学习转化为归纳式学习==,==避免了节点的embedding特征每一次都需要重新训练的情况,支持了增量特征==。为什么通过邻居随机抽样就可以使得直推式的模型变为支持增量特征的归纳式模型呢?
在原始的GraphSAGE模型(直推式模型)当中,节点标签皆仅对应一种局部结构、一种embedding特征。在GraphSAGE引入邻居随机抽样之后,节点标签则变为对应多种局部结构、多种embedding特征,这样可以防止模型在训练过程过拟合,增强模型的泛化能力,则可以支持增量特征。
2.3 GraphSAGE的缺点
- 原GraphSAGE无法处理加权图,仅能够邻居节点等权聚合;
- 抽样引入随机过程,推理过程中同一节点embedding特征不稳定;
- 抽样数目限制会导致部分局部信息丢失;
- GCN网络层太多容易引起训练中过度平滑问题。
2.4 GraphSAGE的优化
为解决上述GraphSAGE存在的缺点,对GraphSAGE进行优化。
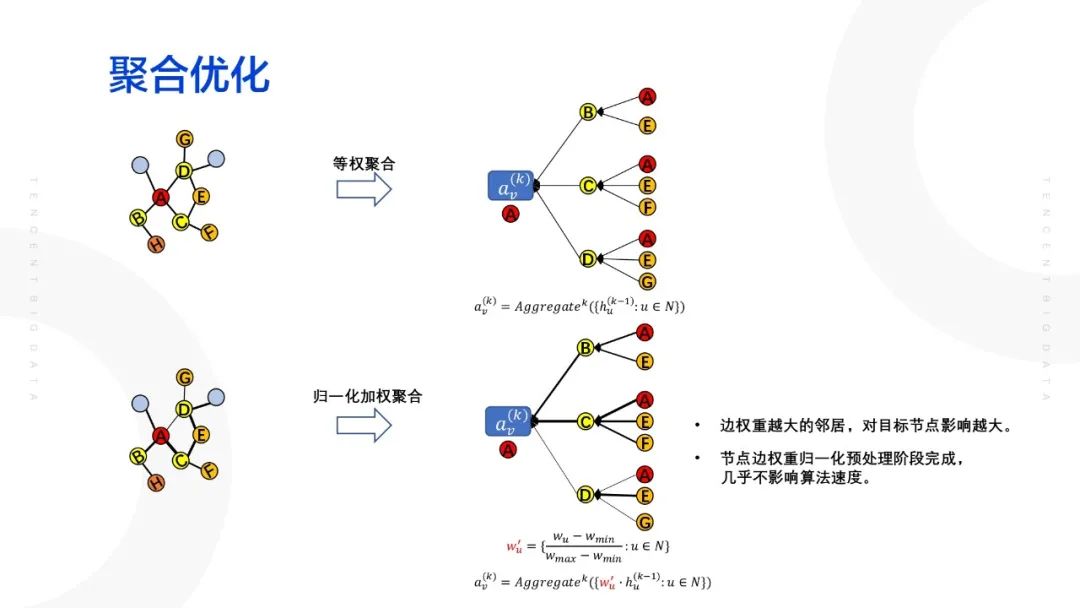
聚合优化:
解决等权聚合的问题。相对于直接将邻居节点进行聚合,将边权重进行归一化之后,点的邻居节点的特征进行点燃,最后再进行特征融合。这样做的好处主要有两点:边权重越大的邻居,对目标节点影响越大;节点边权重归一化在预处理阶段完成,几再与目标节乎不影响算法速度。
剪枝优化:
解决embedding特征不稳定的问题。在训练的过程希望通过引入随机过程防止模型出现过拟合的现象,但是在模型的推理过程式是想要去掉这样一个随机过程。直接对原始网络进行剪枝操作,仅保留每个节点权重最大的K条边,在模型进行推理的时候,会将目标节点所有的K个邻居节点的特征都聚合到目标节点上,聚合方式同样为加权的方式。这样做的好处主要有两个点:在网络结构不变的情况下,保证同节点embedding特征相同;在保证算法精度的前提下,大幅度降低图的稠密程度,降低内存开销。

==采样优化:==
解决局部信息丢失以及训练过平滑的问题。主要通过DGL的抽样方式代替原有的抽样方式,具体的做法为:提前将每一个节点的属性特征与它所有的邻居节点的属性特征的均值进行concat,这样可以使得每一个节点初始状态下已经包含了周围一些邻居节点的一些信息,通过这种方式,在采样相同节点的前提下,可以获得更多的局部信息。一般情况下,GCN模型采用两层网络模型,当增加至第三层的时候则将存在内存爆炸的问题;当增加至第四层时,则将出现过平滑的问题,将导致特征分布去重,这样则导致节点没有区分性。而采用DGL采样,通过采样两层GCN模型而实际上采样了三层,而且不会出现过平滑问题。
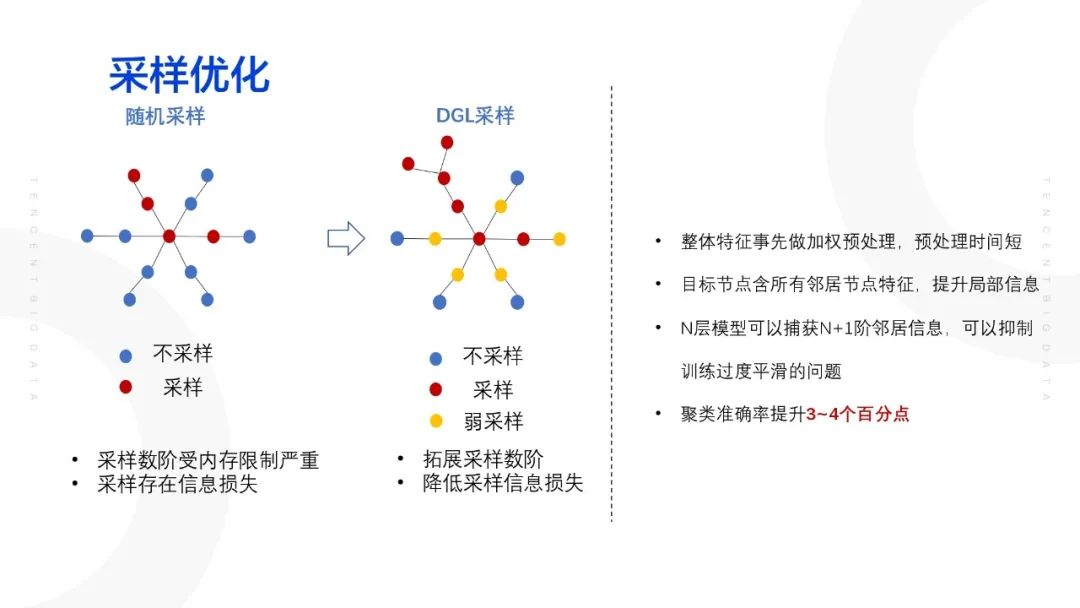
2.5 效果评估
效果评估的指标主要有两个:聚类(社区)准确率;召回恶意率。相对于原有的fastunfolding以及node2vec从聚类准确率、召回恶意率、平均社区规模、运行时间作一个横向对比:

三、孤立点&异质性
3.1 黑产挖掘场景中的孤立点的解决思路
黑产用户在被处理后,通常会快速地申请新的账号或使用备用账号,因为在对黑产的挖掘过程中就不可避免地会出现孤立点,类似在推荐算法中的冷启动问题。以node2vec算法为例,算法通常会通过游走去构造训练的节点段,那么如果孤立节点没有连边的话,节点是无法出现在训练集当中。 为了解决该问题,引入一个解决推荐系统冷启动的算法——EGES,将每一个节点的属性特征映射到一个embedding特征,然后将每一个属性的embedding特征置于注意力层进行处理,比如将N个随机特征通过注意力加权,可以获得最终的一个节点层面的embedding特征,新增的节点将不再依赖于关系网络以及用户的一些交互行为,新增的节点可以通过自身的属性特征就直接获得我们的embedding特征,不需要考虑用户关系从而解决孤立点的问题。

在具体落地过程中,提出了GraphSAGE-EGES算法,实际上是综合了两种算法的优势,GraphSAGE的节点本身的初始特征将其替换成了EGES增强之后的属性特征,通过此类方式,最终的算法框架如下图所示:

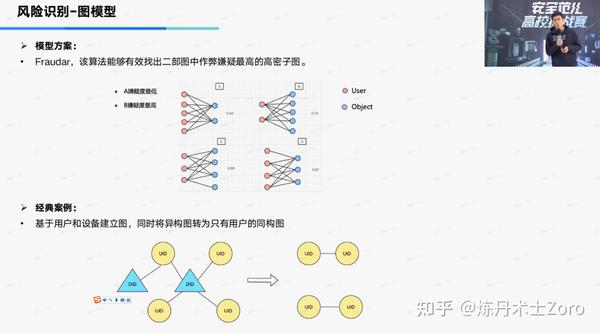
3.2 黑产网络中异质性的解决思路
在正常的网络结构当中,一个用户的一阶邻居基本上都是同一类的用户,比如说在学术引用当中,一篇数据挖掘的论文,引用其的论文也多是与数据挖掘相关的。这一类的网络称之为同质性网络。但在黑产的关系网络当中,图的异质性就非常高了,黑产用户不仅仅与黑产用户相关,其也可以与正常用户建立关系,这种特殊的网络结构就会存在一些弊端,以下图异质性网络为例,圈住的正常节点的一阶邻居节点一半为恶意账号,算法进行预测、聚类时,该节点很多概率会被判定为恶意账号。圈住的恶意节点的一阶邻居3个皆为正常账号,算法进行预测、聚类时,该节点则大概率被判定为正常节点,导致算法的精度下降。

为了解决上述问题,需要去考虑网络的结构是否合理。为了构建合理的网络结构,需要将恶意账号与正常账号之间存在的联系剔除掉,并将恶意账号之间的联系进行一定的增强。

当网络结构合理时,算法进行预测、聚类时会更加准确,因此引入图结构学习的概念,尝试用LDS算法解决这类问题。
LDS算法的思想:在训练GCN模型的参数的同时对网络的结构进行调整,在最初的时候给予一个网络结构(邻接矩阵),先固定GCN的模型,然后训练邻接矩阵,通过几轮迭代之后再固定邻接矩阵,再训练GCN模型,通过几轮迭代之后,可以得出一个合理的网络结构。
总的来说,这个算法实际上就是一个极大似然估计以及伯努利分布的问题。在LDS算法学习邻接矩阵的时候实际就是学习两个点的邻边是否应该存在,实际上为一个0-1分布。最终通过网络结构以及节点的标签去预估在当前数据标签的情况下,更应该得到什么样的一个网络结构,以上即为该算法的核心思想。
实际上,在许多业务场景当中会存在许多不合理的图结构,甚者在某些业务场景中不存在关系信息,这样的话,在最初达不到完整网络的情况时,通常会使用KNN的方式对网络进行初始化,然后再去学习一个更加合理的网络结构,最终达到一个更好节点预测、聚类的目的。
实际上,在许多业务场景当中会存在许多不合理的图结构,甚者在某些业务场景中不存在关系信息,这样的话,在最初达不到完整网络的情况时,通常会使用KNN的方式对网络进行初始化,然后再去学习一个更加合理的网络结构,最终达到一个更好节点预测、聚类的目的。
四、总结思考
下面分享几点在算法落地以及算法选择中的一些工作总结与思考:
- 针对图算法这块,特征工程和图的构建方式是非常重要的。如果图的结构不合理的话,即使算法模型再强大、特征工程处理得再好,算法训练出的结果也不是最终理想的效果;
- 多数业务场景的区分度是不一样的,不存在一个普适的算法可以解决所有业务场景存在的问题,如上述的FastUnfolding、node2vec在某些特定的业务场景下效果可以比GraphSAGE的效果更好,所以在面临具体问题的时候,需要结合场景作算法选择以及优化;
- 在工业界落地的算法通常比较直接、明了,这样的算法往往效果更好。
五、GraphSAGE应用
本例中的训练,评测和可视化的完整代码在下面的git仓库中
shenweichen/GraphNeuralNetworkgithub.com/shenweichen/GraphNeuralNetwor
这里我们使用引文网络数据集Cora进行测试,Cora数据集包含2708个顶点, 5429条边,每个顶点包含1433个特征,共有7个类别。
按照论文的设置,从每个类别中选取20个共140个顶点作为训练,500个顶点作为验证集合,1000个顶点作为测试集。 采样时第1层采样10个邻居,第2层采样25个邻居。
- 节点分类任务结果
通过多次运行准确率在0.80-0.82之间。
- 节点向量可视化

风控反欺诈(3)Fraudar:二部图反欺诈
Fraudar:二部图反欺诈
图异常检测系列文章:
可以说电商的发展,滋生并带火了一个由出资店铺、刷单中介、各级代理、刷手、空包物流组成的刷单产业。
一、黑产与反欺诈
关系网络与二部图
不同于对个体自身特征的分析,网络提供了对多个对象的关系之间另一种看问题的视角。把对象看做结点,把交互看成边,对象间的发生的各种关联自然会构成一张关系网络。从图论的角度出发,根据结点属性的不同可以把网络分为同构图和异构图。同构图是由同一种结点组成的关系网络,如家庭亲属关系、社交好友关系、论文间的引用关系等。历史上对于同构图的网络表示有很多研究,早在十九世纪就形成了几何拓扑学这一数学分支。在现代的同构关系研究中也逐步提出了基于网页链接的谷歌PageRank网页评级、基于结点关系紧密度的Louvian社区发现等重要算法。不过异构图在生活中的表现更为广泛,异构图是由不同属性的结点组成的关系网络,如由买方卖方以及中介组成的交易网络、由大V和其关注者组成的关注网络、由手机号。二部图(也叫二分图)是异构网络的一种,它由两类结点组成,并且同类结点之间通常没有关联。前述的刷单欺诈,即是以出资店铺和刷手这两类结点组成的交易关系二部图。

二部图下的欺诈
两类结点组成的欺诈场景还可以举出很多例子,如电商场景下用户对商户的薅羊毛、刷好评,如社交场景下水军账号的虚假关注、转发,又如消金场景下用户与商户勾结对平台的消费贷套现欺诈。 这些行为都会使两类结点之间出现异常的连接分布,从整体网络看来其呈现出了一张致密的双边连接子图,且该子图内的结点与图外结点联系相对较少。我们把这种大量的、同步的非正常关联行为模式称之为Lockstep,即在本不应出现聚集行为的二部图自然关系网络中,出现了双边聚集性行为。
只要能把欺诈行为总结成一种模式,自然可以将其分离出来。但是欺诈者往往会对自己做出某种伪装以使自己看起来有向好的一面,意图绕过风控系统。如在刷单欺诈场景下,为了尽量贴近真实用户的购买习惯,刷单平台会对刷手提出一系列要求,比如要求货比三家、要求最低浏览时长、要求滚动浏览高度及停留时间、要求对于正常热销商品做一定购买等,这些行为都会导致风控经验指标和模型特征的部分失效。在二部图交易网络中,对于正常热销商品的购买体现为刷手为自己增加了一些优异的边连接,使自己看起来更像一个正常的消费者结点。 我们需要一种能从这种复杂关系网络中对抗伪装、抽丝剥茧的提取出异常致密子图的算法。接下来对症下药引入Fraudar。Fraudar算法来源于2016年的KDD会议,并获得了当年的最佳论文奖。
二、Fraudar算法介绍- 无监督异常簇检测
FRAUDAR: Bounding Graph Fraud in the Face of Camouflagedl.acm.org/doi/pdf/10.1145/2939672.2939747
简单来说,Fraudar定义了一个可以表达结点平均可疑度的全局度量G(·),在逐步贪心移除可疑度最小结点的迭代过程中,使G(·)达到最大的留存结点组成了可疑度最高的致密子图。接下来我们稍微细化一下算法过程,以刷单交易场景为例(定义二部图结点集合S=[A,B],其中A、B分别代表消费者和店铺的结点集合),看Fraudar是如何从交易网络剥离出刷手和其出资店铺的。
网络水军、刷量刷单等行为在互联网中屡见不鲜,如何检测网络中的该类行为,即异常簇,是值得研究的问题。本文介绍一种图异常簇检测方案-FRAUDAR,该方法在具有14.7亿条边的Twitter社交网络中成功检测出了一系列刷量账户。
2.1 论文贡献
- 提出了一组满足公理的指标,且兼具多种优点。
- 提出了一个可证明的界限,即某个欺诈账户可以在图中有多少欺诈行为而不被抓获,即使是在伪装的情况下。接着通过新的优化改进了该界限,使其能够更好地区分真实数据中的欺诈行为和正常行为。
- 该算法在超大规模的Twitter网络中被证明了是有效的且能够在接近线性时间复杂度内完成任务。
2.2 欺诈行为的特点
网络中存在不少水军刷量刷单的现象,该类欺诈行为在社交网络中尤其显著,其中"刷量者"可称为follower,"刷单目标"可以称为followee。下图展示了Twitter中的“僵尸粉”购买服务案例:左图红色和蓝色颜色的柱子分别代表了正常用户和欺诈用户,用户所属的两个柱子中左柱子表示followee的数量,右柱子表示follower的数量;右图展示了某个刷量账号,其个人简介中表示“只要你follow他那么他就会follow你”。
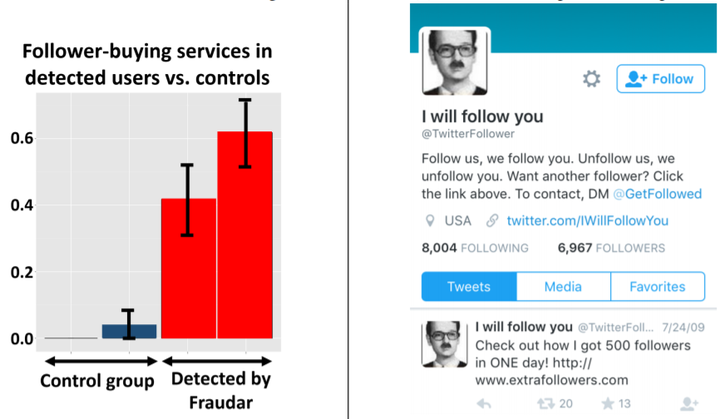
欺诈行为在网络的邻接矩阵视角下具有显著特征,某些“聪明”的刷量分子为了逃避检测往往会采取伪装(camouflage)来让自己看起来更像普通用户。下图从左到右分别展示了邻接矩阵中的随机伪装者、偏置伪装者和被劫持账户参与刷量行为。
2.3 FRAUDAR算法
FRAUDAR算法基于二部图表示,即网络中存在两种类型的节点Users和Objects。文中假设可能存在一个或多个User受到相关某个实体的控制,进而与Objects的某个子集交互而产生连边。算法所需的符号表示如下:

算法的目标是找到一个 \(S\), 并使得 \(S\) 构成子图的嫌疑指标 \(g(S)\) 最大。
子图内节点嫌疑度,即密集度指标 (density metrics) 可描述为: \(g(S)=\frac{f(S)}{|S|}\)
子图总嫌疑度 (total suspiciousness) 可描述为: \[ \begin{aligned} f(S) & =f_\nu(S)+f_{\varepsilon}(S) \\ & =\sum_{i \in S} a_i+\sum_{i, j \in S \wedge(i, j) \in \varepsilon} c_{i j}\end{aligned} \] 其中, \(a_i\) 和 \(c_{i j}\) 都是大于 0 的常数, \(a_i\) 即某个节点 \(i\) 的嫌疑度, 而 \(c_{i j}=\frac{1}{\log \left(d_j+c\right)}\) 可即边 \((i, j)\) 的嫌疑度, \(d_j\) 表示Object \(j\) 的度, \(c\) 是一个较小的常量。
由此,FRAUDAR算法可描述为如下过程:
- 将优先级最高的节点移出二部图
- 更新与移出节点相关的节点可疑度
- 反复执行步骤1和步骤2,直至所有节点都被移出
- 最后比较各轮迭代中节点的可疑度,找到最大可疑度对应的子图

算法中有如下两点值得注意:
1. 如何构造优先树
优先树本质上是一个小顶堆,其叶子节点为二部图中的Users或Objects,排序规则依赖于节点的嫌疑度。由此,根结点将记录全局嫌疑度最小的节点,将根节点从二部图中移出使得新子图中的节点具有最大的平均嫌疑度。
2. 如何更新可疑度
删除网络中的节点导致二部图结构被改变,因此每轮迭代后都需要在保持边可疑度不变的前提下,更新与被删除节点相关的节点可疑度,即相关节点减去被删节点的嫌疑度。
风控算法(3)阿里云-风险商品图算法识别
【阿里安全 × ICDM 2022】大规模电商图上的风险商品检测赛
比赛链接:Https://tianchi.aliyun.com/competition/entrance/531976/introduction
ICDM 2022: Risk Commodities Detection on Large-Scale E-Commence Graphs:https://github.com/EdisonLeeeee/ICDM2022_competition_3rd_place_solution
ICDM2022大规模电商图上的风险商品检测比赛(第六名):https://github.com/JaySaligia/SGHQS
ICDM 2022 : 大规模电商图上的风险商品检测 -- top1方案分享+代码:https://github.com/fmc123653/Competition/tree/main/ICDMCup2022-top1
ICDM2022_competition_3rd_place_solution:https://github.com/EdisonLeeeee/ICDM2022_competition_3rd_place_solution
【论文笔记】KGAT:融合知识图谱的 CKG 表示 + 图注意力机制的推荐系统:https://zhuanlan.zhihu.com/p/364002920
一、黑灰产VS风控系统
近年来,图计算尤其是图神经网络等技术获得了快速的发展以及广泛的应用。
在电商平台上的风险商品检测场景中,黑灰产和风控系统之间存在着激烈的对抗,黑灰产为了躲避平台管控,会蓄意掩饰风险信息,通过引入场景中存在的图数据,可以缓解因黑灰产对抗带来的检测效果下降。
在实际应用中,图算法的效果往往和图结构的质量紧密相关,由于风险商品检测场景中对抗的存在,恶意用户会通过伪造设备、伪造地址等方式,伪造较为“干净”的关联关系。 如何能够在这种存在着大量噪声的图结构数据中充分挖掘风险信息,是一个十分有挑战性的问题,另外该场景中还存在着黑白样本严重不均衡、图结构规模巨大且异构等多种挑战。

二、赛题背景
在电商平台上,商品是最主要的内容之一。风险商品检测旨在识别平台上存在的假货商品、违禁商品等,对维护平台内容信息健康、保护消费者权益起着至关重要的作用。
风险商品检测和其他风控领域一样,面临风险的对抗和变异,如对商品风险内容的刻意隐藏等,而使用平台广泛存在的各类图关系数据可以提供更多证据,提升黑灰产的攻击成本。
本次比赛提供了阿里巴巴平台来源于真实场景的风险商品检测数据,需要参赛者利用大规模的异构图结构以及比例不均衡的黑白样本,利用图算法,检测出风险商品。

三、结题思路
3.1 DeepFM模型
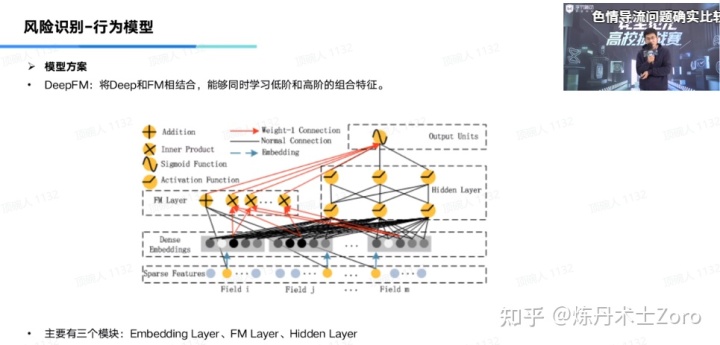
低阶和高阶特征选择
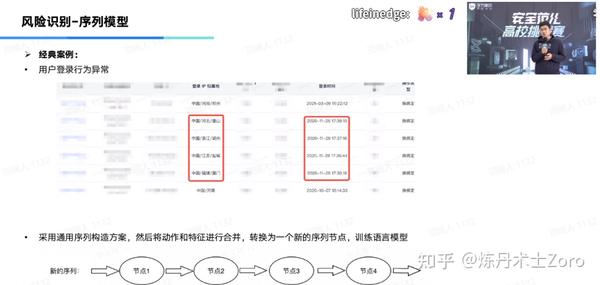
3.2 序列模型

3.3 图模型

工业落地-【draft】2021 BlackHat-Slips: A Machine-Learning Based, Free-Software, Network Intrusion Prevention System
Slips: A Machine-Learning Based, Free-Software, Network Intrusion Prevention System
2021 BlackHat Europe Arsenal, Slips: A Machine-Learning Based, Free-Software, Network Intrusion Prevention System [slides] [web]
开源项目:https://github.com/stratosphereips/StratosphereLinuxIPS
一、简介
Slips是一个自由软件行为Python入侵预防系统(IDS/IPS),它使用机器学习来检测网络流量中的恶意行为。
python-matplotlib画图
matplotlib画图
https://matplotlib.org/
https://zhuanlan.zhihu.com/p/109245779
简洁优雅的Matplotlib可视化 | 绘制论文曲线图:https://zhuanlan.zhihu.com/p/81336415
- 训练的loss可视化
1 | def plot_train_history(train_loss_history, val_loss_history, save_title): |
- 绘制三个折线子图
1 | import matplotlib.pyplot as plt |
理论基础(4)Dropout
为什么dropout 可以解决过拟合? 【共享隐藏单元的bagging集成模型】
集成取平均的作用: 整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
Dropout纯粹作为一种高效近似Bagging的方法。然而,有比这更进一步的Dropout观点。 Dropout不仅仅是训练一个Bagging的集成模型,并且是共享隐藏单元的集成模型。这意味着无论其他隐藏单元是否在模型中,每个隐藏单元必须都能够表现良好。