NDSS20
UNICORN: Provenance-Based Detector for APTs
[AI安全论文]
06.NDSS20 UNICORN: Provenance-Based Detector for APTs
图片
原文作者:Xueyuan Han, Thomas Pasquier, Adam Bates, James Mickens and
Margo Seltzer 原文标题:UNICORN: Runtime Provenance-Based Detector for
Advanced Persistent Threats
原文链接:https://arxiv.org/pdf/2001.01525.pdf 发表会议:NDSS
2020参考文献:感谢两位老师
https://blog.csdn.net/Sc0fie1d/article/details/104868847
https://blog.csdn.net/xjxtx1985/article/details/106473928
摘要 本文提出的UNICORN是一种基于异常的APT检测器 ,可以有效利用数据Provenance进行分析 。通过广泛且快速的图分析,使用graph
sketching技术 ,UNICORN可以在长期运行的系统中分析Provenance
Graph,从而识别未知慢速攻击。其中,Provenance
graph提供了丰富的上下文和历史信息,实验证明了其先进性和较高准确率。
由于APT(Advanced Persistent
Threats)攻击具有缓慢可持续的攻击模式以及频繁使用0-day漏洞的高级特性使其很难被检测到。本文利用数据来源分析(provenance)提出了一种基于异常的APT检测方法,称为UNICORN。
从建模到检测,UNICORN专门针对APT的独有特性(low-and-slow、0-Days)设计。
UNICONRN利用高效的图分析方法结合溯源图丰富的上下文语义和历史信息,在没有预先设定攻击特征情况下识别隐蔽异常行为。
通过图概要(graph
sketching)技术,它有效概括了长时间系统运行来对抗长时间缓慢攻击。
UNICONRN使用一种新的建模方法来更好地捕捉长期行为规律,以提高其检测能力。
最后通过大量实验评估表明,本文提出的方法优于现有最先进的APT检测系统,并且在真实APT环境中有较高的检测精度。
一、引言 APT攻击现在变得越来越普遍。这种攻击的时间跨度长,且与传统攻击行为有着本质的区别。APT攻击者的目的是获取特定系统的访问控制,并且能够长期潜伏而不被发现。攻击者通常使用0-day漏洞来获取受害者系统的访问控制。
传统检测系统通常无法检测到APT攻击。
依赖恶意软件签名的检测器对利用新漏洞的攻击无效。
基于异常检测的系统通常分析一系列的系统调用或日志系统事件,其中大部分方法无法对长期行为进行建模。
由于基于异常检测的方法只能检测系统调用和事件的短序列很容易被绕过。
综上,当前针对APT攻击的检测方法很少能成功。攻击者一旦使用0-Day漏洞,防御者便无计可施;而基于系统调用和系统事件的检测方法,由于数据过于密集,这些方法难以对长时间的行为模式进行建模。因此,数据溯源(data
provenance)是一种检测APT更合适的数据。
最近的研究成果表明数据溯源是一个很好的APT检测数据源。数据溯源将系统执行表示成一个有向无环图(DAG),该图描述了系统主体(如进程)和对象(文件或sockets)之间的信息流。即使跨了很时间,在图中也把因果相关的事件关联到一起。因此,即使遭受APT攻击的系统与正常系统比较类似,但是溯源图中丰富的上下文语义信息中也可以很好地区分正常行为与恶意行为。
然而,基于数据溯源的实时APT检测依然具有挑战。
随着APT攻击的渗透的进行,数据溯源图的规模会不断增大。其中必要的上下文分析需要处理大量图中的元素,而图上的分析通常复杂度比较高。当前基于数据溯源的APT检测方法根据已有的攻击知识通过简单的边匹配实现APT检测,无法处理未知的APT攻击。基于溯源的异常检测系统主要是基于图模型的邻域搜索,利用动态或静态模型识别正常行为模式。理论上关联的上下文越丰富越好,但是实际中由于图分析的复杂性较高限制了其可行性。
Provenance
Graph的分析是相当耗费计算资源,因为APT是可持续攻击,图的规模也会越来越大
当前APT检测系统面临如下三种问题:
静态模型难以捕获长时间的系统行为;
low-and-slow
APT投毒攻击:由于APT高级可持续的特性可以在系统中潜伏很长时间,相关的行为会被认为是正常行为,这样的攻击会影响检测模型;
在主存内进行计算的方法,应对长期运行的攻击表现不佳。
基于此,本文提出了UNICORN,使用graph
sketching来建立一个增量更新、固定大小的纵向图数据结构。这种纵向性质允许进行广泛的图探索,使得UNICORN可以追踪隐蔽的入侵行为。而固定大小和增量更新可以避免在内存中来表示provenance
graph,因此UNICORN具有可扩展性,且计算和存储开销较低。UNICORN在训练过程中直接对系统的行为进行建模,但此后不会更新模型,从而防止模型的投毒攻击。
本文的主要贡献如下:
针对APT攻击特性提出一种基于Provenance的异常检测系统 。
引入一种新的基于概要的(sketch-based)、时间加权的(time-weighted)溯源编码 ,该编码非常紧凑且可处理长时间的溯源图。通过模拟和真实的APT攻击来评估UNICORN,证明其能高精度检测APT活动。
实现代码开源。
二、背景 2.1 系统调用追踪的挑战 系统调用抽象提供了一个简单的接口,用户级应用程序可以通过这个接口请求操作系统的服务 。作为调用系统服务的机制,系统调用接口通常也是攻击者入侵的入口点。因此,系统调用跟踪一直被认为是入侵检测的实际信息源。然而:
当前的攻击检测系统是对非结构化的系统调用的审记日志进行分析,但捕获的系统调用杂乱分散,传统基于异常检测的思路无法处理APT。因此需要将其关联成data
provenance,基于溯源的方法是将历史上下文数据都编码到因果关系图中。
数据溯源方法已经被应用到攻击调查中,已经有一些方法能够根据审计数据构建系统溯源图用以实现对系统执行过程的建模。然而这些方法依然存在一些局限:(1)
这种事后构建很难保证溯源图的正确性,由于系统调用问题存大量并发,溯源图的完整性与可靠性无法保证;(2)
容易被绕过;(3) 时空复杂度较高。
由于一些内核线程不使用系统调用,因此基于Syscall生成的Provenance是一些分散的图,而不是一张系统运行状况的完整图
2.2 全系统追踪溯源 全系统溯源运行在操作系统层面,捕获的是所有系统行为和它们之间的交互 。通过捕获信息流和因果关系,即使攻击者通过操作内核对象来隐藏自己的行踪也无济于事。
本文使用CamFlow,采用了Linux安全模块(Linux Security
Modules,LSM)框架来确保高效可靠的信息流记录。LSM可以消除race
condition。
CamFlow:溯源搜集系统 ,参考官网
https://camflow.org/。
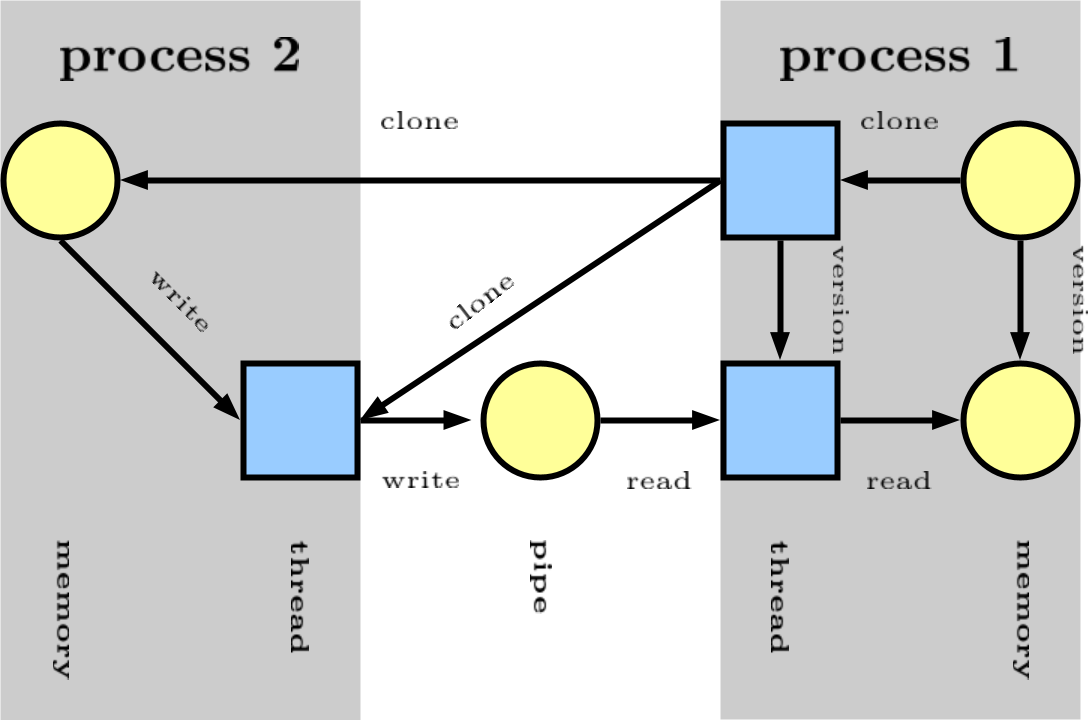
CamFlow
将系统的执行表示为有向无环图 。图中的顶点表示内核对象(例如线程、文件、套接字等)的状态,关系表示这些状态之间的信息流。
在上面的示例中process 1克隆process 2。
process 2写到一个pipe。
process 1同读pipe。创建版本是为了保证非周期性并代表信息的正确排序(有关详细信息,请参阅我们的CCS'18
论文 )。
2.3 问题描述 现有基于数据溯源的APT攻击检测方法主要存在如下缺陷:
预定义的边匹配规则过于敏感,很难检测到APT攻击中的0-Day漏洞;
溯源图的近邻约束导致其只能提供局部上下文信息(而非whole-system),然而这会影响相关异常检测精度;
系统行为模型难以检测APT:静态模型无法捕获长期运行的系统的行为;动态模型容易遭受中毒攻击;
溯源图的存储与计算都是在内存中,在执行长期检测上有局限性。
UNICORN可以解决如上问题,其本质是把APT检测问题看成大规模、带有属性的实时溯源图异常检测问题。在任何时间,从系统启动到其当前状态捕获的溯源图都将与已知正常行为的溯源图进行比较。如果有明显差别,那么就认为该系统正在遭受攻击。
对于APT检测来说,理想基于溯源的IDS应该如下:
充分利用溯源图的丰富上下文,以时间与空间有效的方法持续分析溯源图;
在不假设攻击行为的基础上,应考虑系统执行的整个持续时间;
只学习正常行为的变化,而不是学习攻击者指示的变化。
三、威胁模型 假设主机入侵检测有适当的场景:攻击者非法获得对系统的访问权限,并计划在不被检测的情况下驻留在系统中很长一段时间。攻击者可能分阶段执行攻击,在每个阶段还会使用大量的攻击技术 。UNICORN的目标是通过解决主机生成的溯源来实现在所有阶段对APT攻击进行检测。本文假设,我们假设在受到攻击之前,UNICORN在正常运行期间会完全观察主机系统,并且在此初始建模期间不会发生攻击。
数据收集框架的完整性是UNICORN正确性的核心,因此我们假定所使用的CamFlow中,LSM完整性是可信的。同时,本文假设内核、溯源数据和分析引擎的正确性,我们重点关注UNICORN的分析能力。
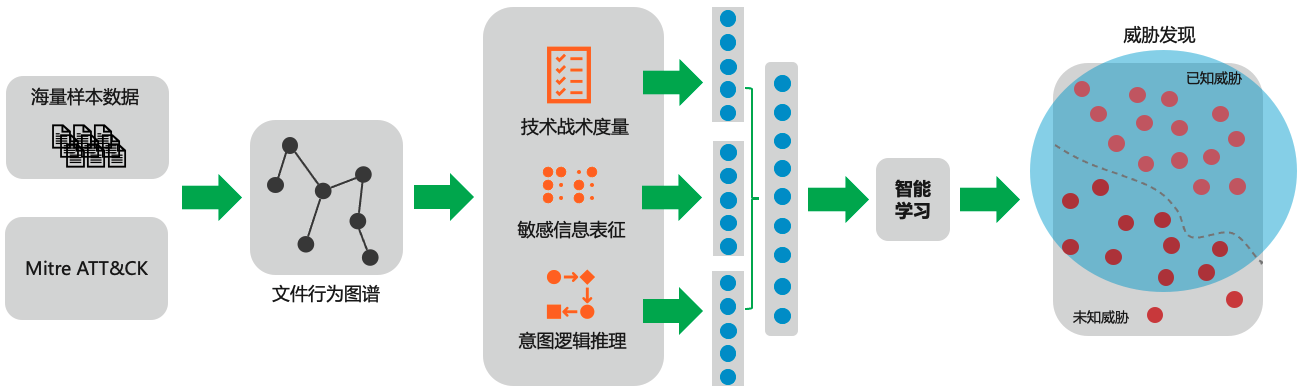
四、系统设计 独角兽是一个基于主机的入侵检测系统,能够同时检测在网络主机集合上的入侵。
以一个带标签的流式溯源图作为输入 。该图由CamFlow生成,每条边是带属性的。溯源系统构建一个具有偏序关系的DAG溯源图,能实现有效的流式计算和上下文分析。建立一个运行时的内存直方图 。UNICORN有效构建一个流式直方图,该直方图表示系统执行的历史,如果有新边产生则实时更新直方图的计数结果。通过迭代的探索大规模图的近邻关系,发现了在上下文环境中系统实体的因果关系。该工作是UNICORN的第一步,具体来说,直方图中每个元素描述了图中唯一的一个子结构 ,同时考虑了子结构中的顶点与边上的异构标签,以及这些边的时间顺序。APT攻击缓慢的渗透攻击目标系统,希望基于的异常检测方法最终忘记这一行为,把其当成正常的系统行为,但是APT攻击并不能破坏攻击成功的相关信息流依赖关系。定期计算固定大小的概要图(graph
sketch) 。在纯流式环境,当UNICORN对整个溯源进行汇总时,唯一直方图元素的数量可能会任意增长。这种动态变化导致两个直方图之间的相似计算变得非常有挑战,从而使得基于直方图相似计算的建模以及检测算法变的不可行。UNICORN采用相似度保存的hash技术把直方图转换成概要图。概要图可以增量维护,也意味着UNICORN并不需要将整个溯源图都保存在内存中。 另外,概要图保存了两个直方图之间的jaccard相似性,这在后续图聚类分析中特别有效。 将简略图聚类为模型 。UNICORN可以在没有攻击知识的前提下实现APT攻击检测。与传统的聚类方法不同,UNICORN利用它的流处理能力生成一个动态演化模型。该模型通过在其运行的各个阶段对系统活动进行聚类捕获单个执行中的行为改变,但是UNICORN无法在攻击者破坏系统时动态实时修改模型。因此,它更适合APT攻击这类长期运行的攻击。
4.1 溯源图 最近几年溯源图在攻击分析中越来越流行,并且本身固有的特别可以有效的用于APT检测。溯源图挖掘事件之间的因果关系,因果关系有助于对时间跨度较远的事件进行推理分析,因此有助于在检测APT相关攻击。
UNICORN根据两个系统执行的溯源图的相似性还判定两个系统的行为相似性。而且UNICORN总是考虑整个溯源来检测长期持续的攻击行为。当前已经有许多图相似度计算方法,然而这些算法大部分是NPC的,即使多项式时间复杂度的算法也无法满足整个溯源图快速增涨的需求。
4.2 构建Graph直方图 本文方法的目标是有效对溯源图进行比较分析,同时容忍正常执行中的微小变化。对于算法,我们有两个标准:
图表示应考虑长期的因果关系;
必须能够在实时流图数据 上实现该算法,以便能够在入侵发生时阻止入侵(不仅仅是检测到入侵)。
本文基于一维WL同构检验,采用了线性时间的、快速的Weisfeiler-Lehman(WL)子树图核算法。该算法的使用依赖于构造的顶点直方图的能力,需要直方图能捕捉每个顶点周围的结构信息。 通过迭代的标签传播来构造这些扩展的顶点标签 。
同构性的WL检验及其子树kernel变化,以其对多种图的判别能力而闻名,超越了许多最新的图学习算法(例如,图神经网络)。对Weisfeiler-Lehman(WL)子树图核的使用取决于我们构建顶点直方图的能力,捕获围绕每个顶点的图结构。我们根据增强顶点标签对顶点进行分类,标签描述了顶点的R-hop邻居。
为了简单说明,假设有一个完整静态图,重标记对所有的输入标签的聚合。对每个顶点都重复执行这个过程来实现对n跳邻居的描述。一旦为图中的每个顶点都构建了扩展标签,那么就可以基于此生成一个直方图,其中每个bucket表示一个标签。两个图的相似性比较是基于以下假设:两个图如果相似那么在相似的标签上会有相似的分布。
我们的目标是构建一个直方图,图中的每个元素对应一个唯一的顶点标签,用于捕获顶点的R-hop的in-coming邻居。
信息流的多样性与复杂性(Streaming Variant and
Complexity) 。算法1只有新顶点出现或是新边出现对其邻顶点有影响时才会执行。本文方法只需要为每条新边更新其目标顶点的邻域。UNICORN采用这种偏序关系来最小化计算代价。
直方图元素的概念漂移问题 。APT攻击场景需要模型必须能够处理长期运行行为分析能力,而系统行为的动态变化会导致溯源图的统计信息也随之变化,这种现象就叫概念漂移(concept
drift)。
UNICORN通过对直方图元素计数使用指数权重衰减来逐渐消除过时的数据(逐渐忘记机制),从而解决了系统行为中的此类变化。它分配的权重与数据的年龄成反比。
\[
H_h=\sum_t \mathbb{1}_{x_t=h}
\]
入侵检测场景中的适用性 。上述“逐渐忘记”的方法,使得UNICORN可以着眼于当前的系统执行动态,而且那些与先前的object/activity有关系的事件不会被忘记。
4.3 生成概要图(Graph Sketches) Graph直方图是描述系统执行的简单向量空间图统计量。然而,与传统的基于直方图的相似性分析不同,UNICORN会随着新边的到来不断更新直方图。另外,UNCORN会根据图特征的分布来计算相似性,而不是利用绝对统计值。
本文采用locality sensitive
hashing,也称作similarity-preserving data
sketching。UNICORN的部署采用了前人的研究成果HistoSketch,该方法是一种基于一致加权采样的方法,且时间得性是常数。
4.4 学习进化模型 在给定graph
sketch和相似性度量的情况下,聚类是检测离群点常用的数据挖掘手段。然而传统的聚类方法无法捕获系统不断发展的行为 。UNICORN利用其流处理的能力,创建了进化模型,可以捕获系统正常行为的变化。更重要的是,模型的建立是在训练阶段完成的,而不是在部署阶段,因为部署阶段训练模型可能会遭受中毒攻击。
UNICORN在训练期间创建一个时序sketches,然后使用著名的K-medods算法从单个服务器对该概要序列进行聚类,使用轮廓系数(silhouette
coefficient)确定最佳K值。
更新C中的每一列,即类中心 中心
K-means 模型: \(\min _{G, C} \sum_{i=1}^n
\sum_{j=1}^k g_{i j}\left\|x_i-c_j\right\|_2\) 算法流程:
固定C,更新 G
更新C中的每一列, 即类中心 \(c_j\) ,其通过计算第j类中样本的平均值得到
K-mediods:模型: \(\min _{G, C \subseteq X}
\sum_{i=1}^n \sum_{j=1}^k g_{i j}\left\|x_i-c_j\right\|_1 \quad\)
可以是曼哈顿距离或其它距离度量;由于类中心的更新规
则,该方法较之于K-means更鲁棒。 算法流程:
固定C,更新 G
更新C中的每一列,即类中心\(c_{j}\) ,对于第j类,中心\(c_{j}\) 需要通过遍历所有该类中的样本,取与该类所有样本距离和最小的样本为该中心。
对于每个训练实例,UNICORN创建一个模型,该模型捕获系统运行时执行状态的更新。直观地说,这类似于跟踪系统执行状态的自动机。 最终的模型由训练数据中所有种源图的多个子模型组成。
4.5 异常检测 在部署期间,异常检测遵循前面章节中描述的相同流模式。UNICORN周期性地创建graph
sketch,因为直方图从流式溯源图演变而来。给定一个概要图,UNICORN将该概要与建模期间学习的所有子模型进行比较,将其拟合到每个子模型中的一个聚类中。
UNICORN假设监视从系统启动开始,并跟踪每个子模型中的系统状态转换。要在任何子模型中为有效,概要必须适合当前状态或下一个状态;否则,被视为异常。因此,我们检测到两种形式的异常行为: