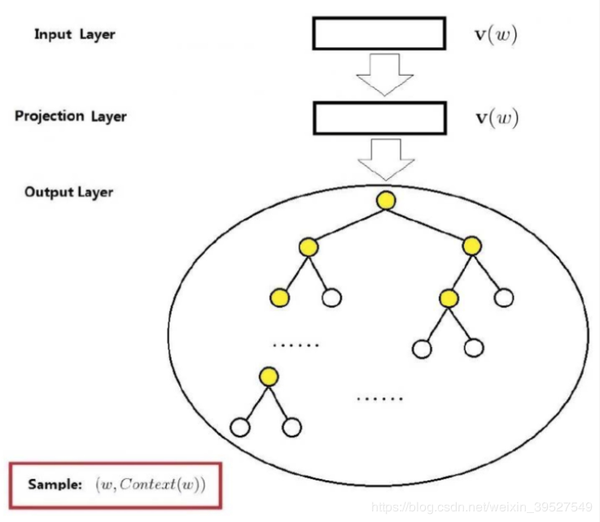
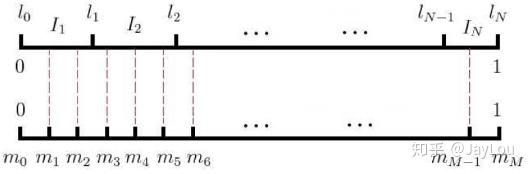
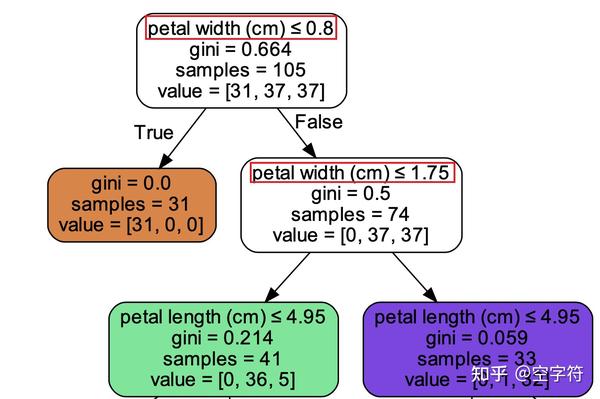
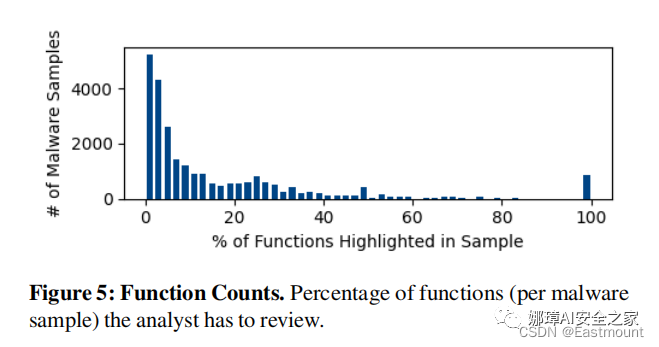
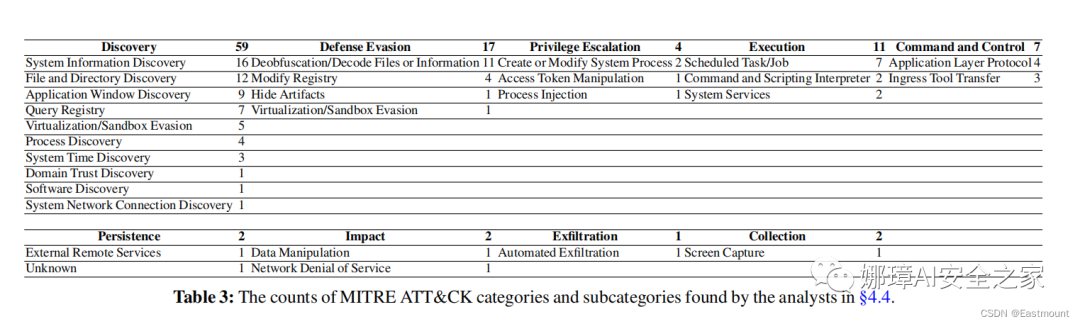
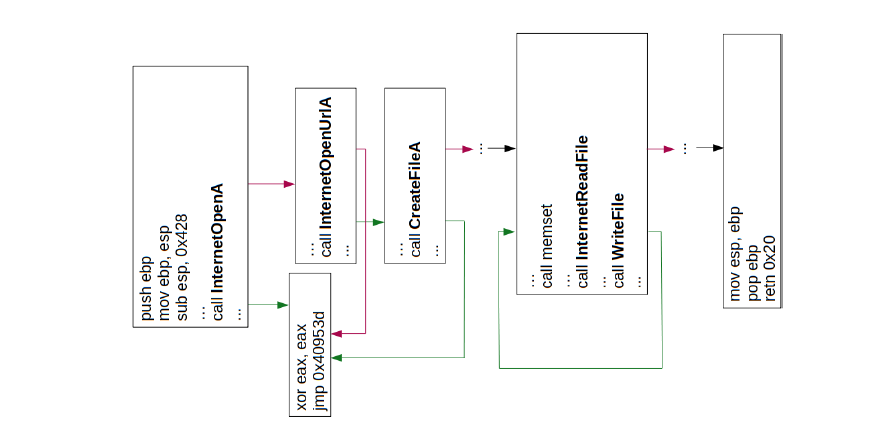
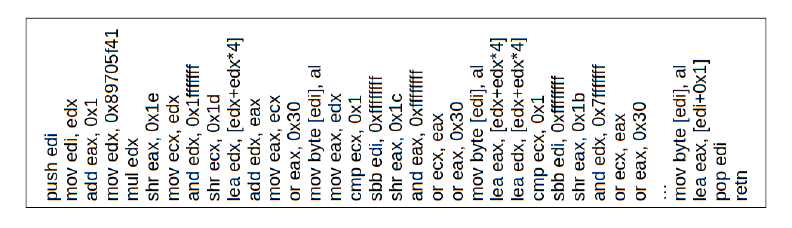
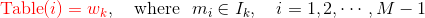2014 A Survey of Android Malware Characterisitics and Mitigation
Techniques
2014 Smartphone Malware and Its Propagation Modeling:A
Survey
2015 Android Security: A Survey of Issues, Malware Penetration,
and Defenses
2014 Evolution and Detection of Polymorphic and Metamorphic
Malwares: A Survey
2015 Kernel Malware Core Implementation: A Survey
2016 A Survey of Stealth Malware Attacks, Mitigation Measures,
and Steps Toward Autonomous Open World Solutions
2016 On the Security of Machine Learning in Malware C&C
Detection: A Survey
2017 Malware Methodologies and Its Future: A Survey
2017 A Survey on Malware Detection Using Data Mining
Techniques
2018 Malware Dynamic Analysis Evasion Techniques: A
Survey
2018 Android Malware Detection: A Survey
2018 A Survey on Metamorphic Malware Detection based on Hidden
Markov Model
2018 Machine Learning Aided Static Malware Analysis: A Survey and
Tutorial
2018 A survey on dynamic mobile malware detection
2018 A survey of malware behavior description and
analysis
2019 A Survey on Android Malware Detection Techniques Using
Machine Learning Algorithms
2019 Dynamic Malware Analysis in the Modern Era—A State of the
Art Survey
2019 Data-Driven Android Malware Intelligence: A Survey
2019 A survey of zero-day malware attacks and itsdetection
methodology
2019 A Survey on malware analysis and mitigation
techniques
2019 Survey of machine learning techniques for malware
analysis
2020 Deep Learning and Open Set Malware Classification: A
Survey
2020 A Comprehensive Survey on Machine Learning Techniques for
Android Malware Detection
2015 A Survey on Mining Program-Graph Features for Malware
Analysis
2020 Stochastic Modeling of IoT Botnet Spread: A Short Survey on
Mobile Malware Spread Modeling
2020 A survey of IoT malware and detection methods based on
static features
2020 A survey on practical adversarial examples for malware
classifiers
2020 A Survey of Machine Learning Methods and Challenges for
Windows Malware Classification
2020 A Survey on Malware Detection with Deep Learning
2020 An emerging threat Fileless malware: a survey and research
challenges
2021 Malware classification and composition analysis: A survey of
recent developments
2021 Adversarial EXEmples: A Survey and Experimental
Evaluation of Practical Attacks on Machine Learning for Windows Malware
Detection
2020 A Survey on Mobile Malware Detection Techniques
2021 Towards interpreting ML-based automated malware detection
models: a survey
2021 A Survey of Android Malware Detection with Deep Neural
Models
2021 A survey of malware detection in Android apps:
Recommendations and perspectives for future research
2021 A survey of android application and malware
hardening
2021 A survey on machine learning-based malware detection in
executable files
2021 The evolution of IoT Malwares, from 2008 to 2019: Survey,
taxonomy, process simulator and perspectives
2021 A Survey of Android Malware Static Detection Technology
Based on Machine Learning
2016 Empirical assessment of machine learning-based malware
detectors for Android Measuring the gap between in-the-lab and
in-the-wild validation scenarios
2016 When a Tree Falls: Using Diversity in Ensemble Classifiers
to Identify Evasion in Malware Detectors
2016 Automatically Evading Classifiers A Case Study on
PDF Malware Classifiers
2017 SecureDroid: Enhancing Security of Machine Learning-based
Detection against Adversarial Android Malware Attacks
2017 How to defend against adversarial attack
2017 Transcend: Detecting Concept Drift in Malware
Classification Models
2018 Automated poisoning attacks and defenses in malware
detection systems: An adversarial machine learning
approach
2018 Generic Black-Box End-to-End Attack Against State of
the Art API Call Based Malware Classifiers
2019 Yes, Machine Learning Can Be More Secure! A Case
Study on Android Malware Detection
2019 A cost analysis of machine learning using dynamic runtime
opcodes for malware detection
2019 TESSERACT: Eliminating Experimental Bias in Malware
Classification across Space and Time
2020 When Malware is Packin’ Heat; Limits of Machine Learning
Classifiers Based on Static Analysis Features
2020 Assessing and Improving Malware Detection Sustainability
through App Evolution Studies
2020 On Training Robust PDF Malware Classifiers
2020 Adversarial Deep Ensemble: Evasion Attacks and Defenses for
Malware Detection
2020 Intriguing Properties of Adversarial ML Attacks in the
Problem Space Fabio
2020 Query-Efficient Black-Box Attack Against Sequence-Based
Malware Classifiers
2020 Enhancing State-of-the-art Classifiers with API Semantics to
Detect Evolved Android Malware
2021 Lessons Learnt on Reproducibility in Machine Learning Based
Android Malware Detection
2016 Semantics-Based Online Malware Detection: Towards Efficient
Real-Time Protection Against Malware
2018 Understanding Linux Malware
2017 Droid-AntiRM: Taming Control Flow Anti-analysis to Support
Automated Dynamic Analysis of Android Malware
2017 Malton: Towards On-Device Non-Invasive Mobile Malware
Analysis for ART
2015 CopperDroid: Automatic Reconstruction of Android Malware
Behaviors
2018 EnMobile: Entity-based Characterization and Analysis of
Mobile
2015 Screening smartphone applications using malware family
signatures
2018 Toward a more dependable hybrid analysis of android malware
using aspect-oriented programming
2017 DroidNative: Automating and optimizing detection of Android
native code malware variants
2016 An HMM and structural entropy based detector for Android
malware: An empirical study
2020 Scalable and robust unsupervised android malware
fingerprinting using community-based network partitioning
2020 On the use of artificial malicious patterns for android
malware detection
2016 Andro-Dumpsys: Anti-malware system based on the similarity
of malware creator and malware centric information
2020 Bayesian Active Malware Analysis
2020 PermPair: Android Malware Detection Using Permission
Pairs
2014 Apposcopy: Semantics-Based Detection of Android Malware
through Static Analysis
2015 Profiling user-trigger dependence for Android malware
detection
2019 Identifying Android Malware Using Network-Based
Approaches
2016 Cypider: Building Community-Based Cyber-Defense
Infrastructure for Android Malware Detection
2014 Semantics-Aware Android Malware Classification Using
Weighted Contextual API Dependency Graphs
2017 MAMADROID: Detecting Android Malware by Building Markov
Chains of Behavioral Models
2014 Drebin: Effective and Explainable Detection of Android
Malware in Your Pocket
2018 Make Evasion Harder: An Intelligent Android Malware
Detection System
2018 Using Loops For Malware Classification Resilient to
Feature-unaware Perturbations
2016 Semantic Modelling of Android Malware for Effective Malware
Comprehension, Detection, and Classification
2018 Detecting Android Malware Leveraging Text Semantics of
Network Flows
2018 Improving Accuracy of Android Malware Detection with
Lightweight Contextual Awareness
2019 MalScan: Fast Market-Wide Mobile Malware Scanning by
Social-Network Centrality Analysis
2017 PIndroid: A novel Android malware detection system using
ensemble learning methods
2017 A pragmatic android malware detection procedure
2016 ICCDetector: ICC-Based Malware Detection on Android
2015 A Probabilistic Discriminative Model for Android Malware
Detection with Decompiled Source Code
2019 DroidCat: Effective Android Malware Detection and
Categorization via App-Level Profiling
2018 MADAM: Effective and Efficient Behavior-based Android
Malware Detection and Prevention
2020 Android Malware Detection via (Somewhat) Robust Irreversible
Feature Transformations
2018 Leveraging ontologies and machine-learning techniques for
malware analysis into Android permissions ecosystems
2018 Lightweight, Obfuscation-Resilient Detection and Family
Identification of Android Malware
2018 A multi-view context-aware approach to Android malware
detection and malicious code localization
2019 DroidFusion: A Novel Multilevel Classifier Fusion Approach
for Android Malware Detection
2020 DL-Droid: Deep learning based android malware detection
using real devices
2021 JOWMDroid: Android malware detection based on feature
weighting with joint optimization of weight-mapping and classifier
parameters
2020 Towards using unstructured user input request for malware
detection
2021 Toward s an interpretable deep learning model for mobile
malware detection and family identification
2020 AMalNet: A deep learning framework based on graph
convolutional networks for malware detection
2021 Disentangled Representation Learning in Heterogeneous
Information Network for Large-scale Android Malware Detection in the
COVID-19 Era and Beyond
2019 A Multimodal Deep Learning Method for Android Malware
Detection Using Various Features
2019 Android Fragmentation in Malware Detection
2019 An Image-inspired and CNN-based Android Malware Detection
Approach
2021 A Performance-Sensitive Malware Detection System Using Deep
Learning on Mobile Devices
2020 Byte-level malware classification based on markov images and
deep learning
2013 API Chaser: Anti-analysis Resistant Malware
Analyzer
2018 MalViz: An Interactive Visualization Tool for Tracing
Malware
2017 CloudEyes: Cloud-based malware detection with reversible
sketch for resource-constrained internet of things (IoT)
devices
2013 A fast malware detection algorithm based on
objective-oriented association mining
2013 PoMMaDe: Pushdown Model-checking for Malware
Detection
2014 Growing Grapes in Your Computer to Defend Against
Malware
2015 Hypervisor-based malware protection with
AccessMiner
2015 Probabilistic Inference on Integrity for Access Behavior
Based Malware Detection
2018 Probabilistic analysis of dynamic malware traces
2018 A malware detection method based on family behavior
graph
2018 Malware classification using self organising feature maps
and machine activity data
2019 Volatile memory analysis using the MinHash method for
efficient and secured detection of malware in private cloud
2020 A dynamic Windows malware detection and prediction method
based on contextual understanding of API call sequence
2013 Deriving common malware behavior through graph
clustering
2014 Enhancing the detection of metamorphic malware using call
graphs
2016 Minimal contrast frequent pattern mining for malware
detection
2019 Heterogeneous Graph Matching Networks for Unknown Malware
Detection
2021 Random CapsNet for est model for imbalanced malware type
classification task
2013 A Scalable Approach for Malware Detection through Bounded
Feature Space Behavior Modeling
2013 SigMal: A Static Signal Processing Based Malware
Triage
2014 Unsupervised Anomaly-Based Malware Detection Using Hardware
Features
2014 Control flow-based opcode behavior analysis for Malware
detection
2015 Employing Program Semantics for Malware Detection
2015 AMAL: High-fidelity, behavior-based automated malware
analysis and classification
2016 Optimized Invariant Representation of Network Traffic for
Detecting Unseen Malware Variants
2017 DYNAMINER: Leveraging Offline Infection Analytics for
On-the-Wire Malware Detection
2017 Security importance assessment for system objects and
malware detection
2018 From big data to knowledge: A spatiotemporal approach to
malware detection
2019 MalDAE: Detecting and explaining malware based on
correlation and fusion of static and dynamic characteristics
2019 Leveraging Compression-Based Graph Mining for Behavior-Based
Malware Detection
2020 Advanced Windows Methods on Malware Detection and
Classification
2020 Sub-curve HMM: A malware detection approach based on partial
analysis of API call sequences
2020 Multiclass malware classification via first- and
second-order texture statistics
2021 Catch them alive: A malware detection approach through
memory forensics, manifold learning and computer vision
2018 Auto-detection of sophisticated malware using lazy-binding
control flow graph and deep learning
2018 Malware identification using visualization images and deep
learning
2018 Classification of Malware by Using Structural Entropy on
Convolutional Neural Networks
2019 Classifying Malware Represented as Control Flow Graphs using
Deep Graph Convolutional Neural Network
2019 Neurlux: Dynamic Malware Analysis Without Feature
Engineering
2019 A feature-hybrid malware variants detection using CNN based
opcode embedding and BPNN based API embedding
2019 Effective analysis of malware detection in cloud
computing
2020 Recurrent neural network for detecting malware
2020 Dynamic Malware Analysis with Feature Engineering and
Feature Learning
2020 An improved two-hidden-layer extreme learning machine for
malware hunting
2020 HYDRA: A multimodal deep learning framework for malware
classification
2020 A novel method for malware detection on ML-based
visualization technique
2020 Image-Based malware classification using ensemble of CNN
architectures (IMCEC)