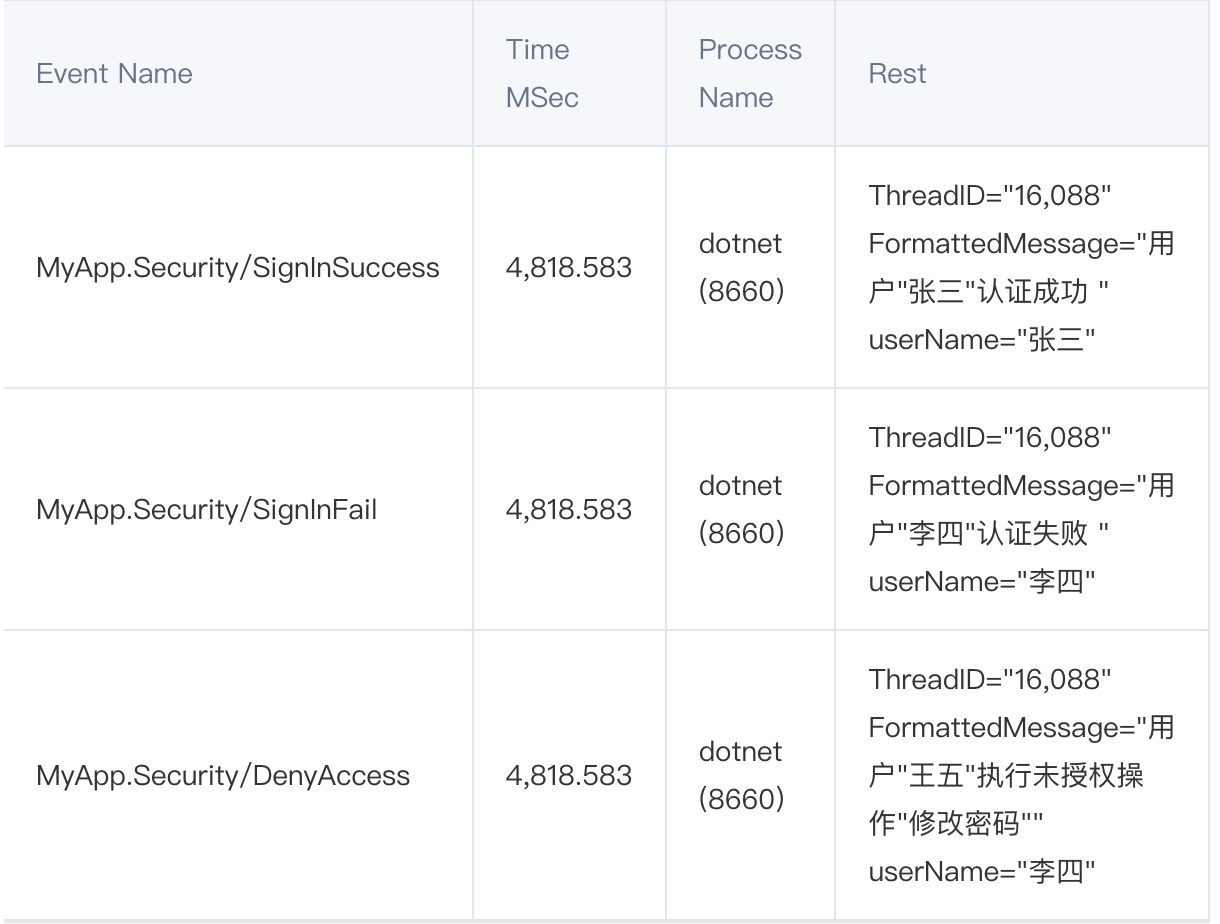
python-正则表达式
Python3爬虫笔记 -- 正则表达式
https://blog.csdn.net/Sc0fie1d/article/details/102724298?spm=1001.2014.3001.5502
https://blog.csdn.net/Sc0fie1d/article/details/102724298?spm=1001.2014.3001.5502
本文提出了一种实时重构企业主机上攻击场景的方法和系统。为了满足问题的可伸缩性和实时需求,我们开发了一个平台中立的、基于主存的、审计日志数据的依赖图抽象方法。然后,我们提出了高效的、基于标签的攻击检测和重建技术,包括源识别和影响分析。我们还开发了一些方法,通过构建紧凑的攻击步骤的可视化图来揭示攻击的大局。我们的系统参与了由DARPA组织的红色团队评估,并能够成功地检测并重建了红色团队对运行Windows、FreeBSD和Linux的主机的攻击细节
我们正在目睹由熟练的对手进行的有针对性的网络攻击(“企业高级和持续威胁(APTs))[1]的迅速升级。通过将社会工程技术(例如,鱼叉式网络钓鱼)与先进的开发技术相结合,这些对手通常会绕过广泛部署的软件保护系统,如ASLR、DEP和沙箱。因此,企业越来越依赖于二线防御,例如,入侵检测系统(IDS)、安全信息和事件管理(SIEM)工具、身份和访问管理工具,以及应用程序防火墙。虽然这些工具通常很有用,但它们通常会生成大量的信息,这使得安全分析师很难区分真正重要的攻击——众所周知的“大海捞针”——从背景噪音。此外,分析人员缺乏“连接这些点”的工具,即,将跨越多个应用程序或主机并在长时间扩展的攻击活动的碎片拼凑起来。相反,需要大量的手工努力和专业知识来整理由多个安全工具发出的众多警报。因此,许多攻击活动被错过了数周甚至数月的[7,40]。
为了有效地控制高级攻击活动,分析人员需要新一代的工具,不仅帮助检测,而且还生成一个总结攻击的因果链的紧凑总结。这样的摘要将使分析人员能够快速确定是否存在重大入侵,了解攻击者最初是如何违反安全规则的,并确定攻击的影响。
将导致攻击的事件的因果链拼接在一起的问题首先在反向跟踪器[25,26]中进行了探索。随后的研究[31,37]提高了由反向跟踪器构建的依赖链的精度。然而,这些工作在一个纯粹的法医环境中运行,因此不处理实时进行分析的挑战。相比之下,本文提出了侦探(SLEUTH),一个系统,该系统可以实时提醒分析师一个正在进行的活动,并在攻击后的几秒钟或几分钟内为他们提供一个紧凑的、直观的活动摘要。这将使在对受害者企业造成巨大损害之前及时作出反应。实时攻击检测和场景重构提出以下几点:
下面,我们将简要介绍侦探调查,并总结我们的贡献。侦探假设攻击最初来自企业外部。例如,对手可以通过外部提供的恶意输入劫持web浏览器、插入受感染的u盘或向企业内运行的网络服务器提供零日攻击来启动攻击。我们假设对手在侦探开始监视系统之前并没有在主机上植入持续的恶意软件。我们还假设操作系统内核和审计系统是值得信赖的
图1提供了我们的方法的概述。侦探是操作系统中立的,目前支持微软的Windows、Linux和FreeBSD。来自这些操作系统的审计数据被处理成平台中立的图形表示,其中顶点表示主题(进程)和对象(文件、套接字),边表示审计事件(例如,读、写、执行和连接等操作)。该图可作为攻击检测、因果关系分析和场景重建的基础。

本文的第一个贡献是针对高效事件存储依赖图表示的开发和紧凑的事件存储和分析(第2节)的挑战。主存表示上的图形算法可以比磁盘上的表示快几个数量级,这是实现实时分析能力的一个重要因素。在我们的实验中,我们能够在14秒内处理来自FreeBSD系统的79小时的审计数据,主存使用量为84MB。这种性能表示的分析速率比生成数据的速率快2万倍。
本文的第二个主要贡献是开发了一种基于标签的方法,用以识别最有可能参与攻击的主题、对象和事件。标签使我们能够确定分析的优先级和重点,从而解决上面提到的第二个挑战。标签编码对数据(即对象)以及过程(主题)的可信度和敏感性进行评估。此评估是基于来自审计日志的数据来源。从这个意义上说,从审计数据中衍生出的标签类似于粗粒度信息流标签。我们的分析也可以很自然地支持更细粒度的标记,例如,细粒度的污染标记[42,58],如果它们可用的话。在第3节中更详细地描述了标签,以及它们在攻击检测中的应用。
本文的第三个贡献是开发了利用标签进行根源识别和影响分析的新算法(第5节)。从图1中所示的攻击检测组件产生的警报开始。我们的反向分析算法遵循图中的依赖关系来识别攻击的来源。从源代码开始,我们使用前向搜索对对手的行动进行全面的影响分析。我们提出了几个标准,以生成一个紧凑的图。我们还给出了一些转换,进一步简化了这个图,并生成了一个图,以一种简洁和语义上有意义的方式直观地捕获攻击,例如,图中的图。 4.实验表明,我们基于标记的方法是非常有效的:例如,侦探可以分析3850万个事件,并生成一个只有130个事件的攻击场景图,代表事件量减少了5个数量级。
本文的第四个贡献,旨在解决上面提到的最后两个挑战,是一个用于标记初始化和传播的可定制策略框架(第4节)。我们的框架提供了合理的默认值,但是可以覆盖它们以适应特定于操作系统或应用程序的行为。这使我们能够调整检测和分析技术,以避免在良性应用程序表现出类似攻击行为的情况下出现误报。(参见第6.6节了解的尾部。)策略还使分析人员能够测试攻击的“备选假设”,方法是重新对认为为可信或敏感的内容进行分类,并重新运行分析。如果分析人员怀疑某些行为是攻击的结果,他们还可以使用策略捕获这些行为,并重新运行分析以发现其原因和影响。由于我们处理和分析审计数据的速度比它生成的速度快数万倍,因此可以有效地、并行地、实时地测试alternate假设。
本文的最后贡献是一个实验评估(第6节),主要基于由DARPA组织的一个红色团队评估,作为其透明计算项目的一部分。在这项评估中,在Windows、FreeBSD和Linux主机上进行了类似现代apt的攻击活动。在这项评估中,侦探能够:
我们的评估并不是为了表明我们发现了最复杂的对手;相反,我们的观点是,给定几种未知的可能性,我们系统的优先级结果可以实时到位,没有任何人类的帮助。因此,它确实填补了今天存在的一个空白,即法医分析似乎主要是手动启动的。
为了支持快速检测和实时分析,我们将依赖关系存储在图形数据结构中。存储此图的一个可能的选择是图形数据库。然而,诸如Neo4J[4]或Titan[6]等流行数据库的性能[39]在许多图形算法中都是有限的,除非主内存足够大,可以容纳大部分数据。此外,一般图数据库的内存使用太高,适合我们的问题。即使是毒刺[16]和NetworkX[5],两个为主存性能而优化的图形数据库,每个图边[39]分别使用约250字节和3KB。在企业网络上报告的审计事件的数量每天很容易达到数十亿到数百亿亿美元之间,这将需要几tb范围内的主内存。相比之下,我们提出了一个更有效的空间依赖图设计,每条边只使用大约10个字节。在一个实验中,我们能够在329mb的主存中存储38m个事件。
Subjects:
Objects:
事件:subjects和objects之间或者两个subjects之间带标签的边,用read 、connect、 execveread、connect、execveread、connect、execve来表示。 事件存储在subjects中,从而消除了subject-event的指针、事件标识符(event id)的需求。他们的表示采用可变长编码,在通常情况下可以采用4 bytes,当需要时可以扩展到8、12或者16 bytes。
我们使用标签来描述objects和subjects的可信度和敏感度。对可信度和敏感度的评估基于以下三个因素:
一个默认的策略被用从从input到output传播标签:为output分配input的可信度标签中的最低值,以及机密性标签的最大值(也就是说,入口点的行为是危险的,出口点的行为也被标注为危险;入口点的数据是机密的,出口点的数据也被标注为是机密的)。这是一种保守的策略,该策略可能会导致一些良性事件被错误地识别为恶意事件(over-tainting),但绝不会漏掉攻击。
标签在SLEUTH中扮演了核心角色。它为攻击检测提供了重要的上下文信息,每个事件都在这些标记组成的上下文中进行解释,以确定其导致攻击的可能性。此外,标签对我们的前向和回溯分析的速度也很有用。最后,标签为消除大量与攻击无关的审计数据也起到了关键作用。
如下定义可信度标签(trustworthiness tags,t-tags),可信度依次降低:
良性可信标签(Benign authentic tag):为数据和代码分配该标签,其来源(source)为良性且可靠性可被验证的
良性标签(Benign tag):为数据和代码分配该标签,其来源为良性,但是来源可靠性未被充分验证
未知标签(Unknown tag):为数据和代码分配该标签,但是其来源未知
策略(policy)定义了那些来源是良性的,哪些来源验证时充分的;策略的最简单情况是白名单。如果对于某个源,没有策略应用在它上面,那么这个源则被打上未知标签。如下定义机密性标签(confidentiality tags,c-tags),机密性依次降低:
我们设计的一个重要方面是分离代码和数据的t-tag。具体而言,即一个subject给定两个t-tag,一个表示其代码可信度(code trustworthiness,code t-tag),另一个表示其数据可信度(data trustworthiness,data t-tag)。这样的设计可以削减重建场景的规模,加快取证分析的速度。而机密性标签仅仅与数据相关联。
已经存在的objects和subjects使用标签初始化策略分配初始标签。在系统执行过程中还会产生新的objects和subjects,它们由标签传播策略分配标签。最后,基于行为的检测策略来检测攻击。
检测方法不应该要求知晓特定应用的一些细节,因为这需要有关应用程序的专家知识,而在动态环境中,应用程序可能会频繁更新。
我们不把着眼点放在变化的应用行为上,而是着眼于攻击者的高级别目标,比如后门插入和信息窃取。具体而言,我们结合了攻击者的动机和手段的推理,注意到我们提出的标签就是用来捕获攻击者的手段:如果一段数据或代码有未 知 标 签 未知标签未知标签,那么它就是由不受信任的源产生的。
根据攻击者的攻击步骤,我们定义了下面包含攻击者目标和手段的策略(Detection Policy):
不受信任的代码执行:当一个拥有高code t-tag的subject执行或加载拥有低t-tag的object时,便会引发警报
被拥有低code t-tag的subject修改:当拥有低code t-tag的subject修改一个拥有高t-tag的object时,便会引发警报。修改的可能是文件内容或者文件名、文件权限等。
机密文件泄露:当不可信的subjects泄漏敏感数据时,将触发警报。具体地说,也就是具有sensitive c-tag 和 unkonwn code t-tag的subject在网络中执行写操作时会触发警报。
为执行准备不可信的数据:该策略由一个拥有unknown t-tag的subject的操作触发,该操作使一个object可执行。这样的操作会包含chmod和mprotect
一点优势:值得注意的是,攻击者的手段并不会因为数据或代码经过了多个中间媒介之后而被“稀释”。啥意思呢?举个栗子:对于不受信任的代码执行策略来说,如果直接从未知网站加载数据的话,当然会触发警报。但是,当这些数据是被下载、提取、解压缩,甚至有可能是编译之后再加载的,在经过了重重转化之后,只要数据被加载,该策略仍然能够被触发。随后再进行回溯分析,就可以找到漏洞利用的第一步。
(与其它探测器合作的能力)另外,其它检测器的输入可以很容易地被集成到SLEUTH中。比如说,某个外部的检测器将一个subject标为可疑,这个时候再SLEUTH中可以将该subject的code t-tag标为unknown,从而后面的分析都会受益。此外该操作也会保留图节点之间的依赖关系。
被不受信的代码执行所触发的策略,不应该被认为工作在静态环境中(需要动态匹配策略),静态环境意味着不允许新代码产生。实际上,我们期望可以连续地更新和升级,但在企业环境中,我们不希望用户下载未知代码。因此,下面会叙述如何支持标准化的软件更新机制。
本文开发了一个灵活的策略框架(policy framework),用于标签的分配、传播和攻击检测。我们使用基于规则的记法来描述策略,例如:
exec(s,o):o.ttag<benign→alert("UntrustedExec")
这条规则被触发的条件是:当一个subject s 执行了一个object o(比如文件),而o的t-tag要小于良性。 在该策略框架中,规则通常与事件关联,并且包含objects或subjects的属性的一些条件,这些属性包括:
name:使用Perl正则表达式来匹配object name和subject命令行
tags: 条件中可以放置objects或subjects的t-tags或者c-tags。对于subjects来说,代码和数据的t-tag可以分别使用
所有权和权限:条件中可以放置objects和subjects的所有权,或者objects和事件权限
不同类型的策略有不同的作用:
触发点(trigger points):为了更好地控制不同类型策略的匹配,我们将策略与触发点联系起来。此外,触发点允许有相似目的的不同事件共享策略。

上图展示了策略框架中定义的触发点,define表示一个新的object,比如一个新网络连接的建立、首次提及一个已经存在的文件、新文件的创建等。 (检测策略匹配过程)当事件出现时,检测策略就会被执行。后面,除非手动配置,否则仅当目标subject或object(某个信息流的终点,Target)发生变化时,检测策略才会被再次执行。
(标签策略)然后,标签策略按照指定的顺序进行尝试,一旦规则匹配,被规则指定的标签将会被分配给目标事件(Target,也就是subject/object)
回溯分析的目标是识别攻击的入口点,入口点是图中入度为0的节点,并且被标记为untrusted。通常是网络连接,但有时也会是其他形式,比如U盘中的文件。
回溯分析的起点是检测策略产生警报的地方。每个警报都与一个或多个实体相关,这些实体在图中被标记为可疑节点。反向搜索涉及对图的反向遍历,从而识别由可疑节点连接到入口点的路径。我们注意到,在这样的遍历和接下来的讨论中,依赖关系边的方向是相反的。反向搜索带来了几个重大挑战:
性能:依赖图可能包含数亿条边。警报数可以达到数千。在这么大的图上执行反向搜索,会消耗大量的计算资源。
多路径:通常,从可疑节点向后可访问多个入口点。然而,在APT攻击中,通常只有一个真正的入口点。因此,简单的反向搜索可能会导致大量的误报
标签可以用来解决这两个挑战。一方面,标签的计算和传播本来就是一种简洁的路径计算。另一方面,如果节点的标签值是unknown,那么该节点很有可能会构成攻击路径。如果节点A的标签是unknown,这意味着至少存在一条路径,从不受信任的入口点指向节点A,这样节点A就比其他拥有良性标签的邻居节点更有可能是攻击的一部分。使用标签来进行反向搜索,消除许多无关节点,极大地减少了搜索空间。
基于此,我们将反向分析当作最短路径问题的一个实例,标签被用来定义边的代价(cost)。一方面,标签能够“引导”搜索沿着攻击相关的路径,并远离不相关的路径。这使得搜索可以在不必遍历整个图的情况下完成,从而解决了性能方面的挑战。另一方面,最短路径算法通过选择最接近可疑节点的入口点(以路径成本衡量)来解决多个路径的挑战。 计算最短路径使用Dijkstra算法,当入口点被加入到路径中时,算法就停止。
代价函数设计:对于那些表示节点依赖关系的边,如果其标签是“未知”,则为其分配较低的开销;其它节点分配较高的开胶,具体地说:
与未知 subject/object 直接相关的良性 subject/object 表示图中恶意和良性部分之间的边界。因此,它们必须包含在搜索中,因此这些边的代价是0。
良性实体之间的信息流动不是攻击的一部分,因此我们将它们的代价设置得非常高,以便将它们排除在搜索之外。
不可信节点之间的信息流可能是攻击的一部分,因此我们将它们的代价设置为一个较低的值。它们将被包括在搜索结果中,除非由较少边组成的可选路径可用。
前向分析的目的是为了评估攻击的影响。通过从一个入口点开始,发现所有依赖于入口点的可能影响。与反向分析类似,主要的挑战是图的大小。一种简单的方法是,标记所有从入口点可到达的 subject/object,这些 subject/object 是通过反向分析得到的。不幸的是,这种方法将导致影响图太大。 在实验中,利用这种方法得到的影响图包含数百万条边,利用我们的简化算法可以降低100到500倍。
一个降低其大小的方法是使用距离阈值dth ,来排除那些距离可疑节点太远的点,分析人员可以调节该阈值。我们使用在回溯分析时使用到的 cost 。
(为什么回溯分析不考虑??)不同于回溯分析的是,我们考虑机密性。特别的,一条边两端的节点,一个由高机密性标签,另外一个具有低代码 integrity(可信度??) 标签(如未知进程)或者低数据 integrity 标签(如未知socket),那么为这条边分配代价为0;而当另一个节点由良性标签时,为其分配较高代价值。
现代信息系统中存在的众多漏洞一直是攻击者进行攻击的“关键”突破点,因此漏洞检测已经成为防守方的一门必修课。但常见的漏洞检测方法中,模糊测试覆盖率不足,基于符号执行程序的验证方法又对检测设备的性能有较高要求,此外漏洞发现后的补洞过程也极为耗时。
入侵检测与威胁分析系统的研发为对抗攻击提供了更直接、更快速的新方法, 能很大程度缓解上述问题。然而,现有的入侵检测系统大多依赖于提取自已有攻击的攻击特征,如入侵指标(Indicator of Compromise,IoC)等,其作为检测依据并未真正把握到攻击的要点,使得防御者总是落后一步。攻击者总是可以通过找到新的攻击面,构造多阶段多变的复杂攻击来绕此类检测。因此,安全研究人员和从业人员亟需重新考虑传统的入侵检测方案,设计出新一代更加通用和鲁棒的入侵检测机制来检测各种不断变化的入侵方式。
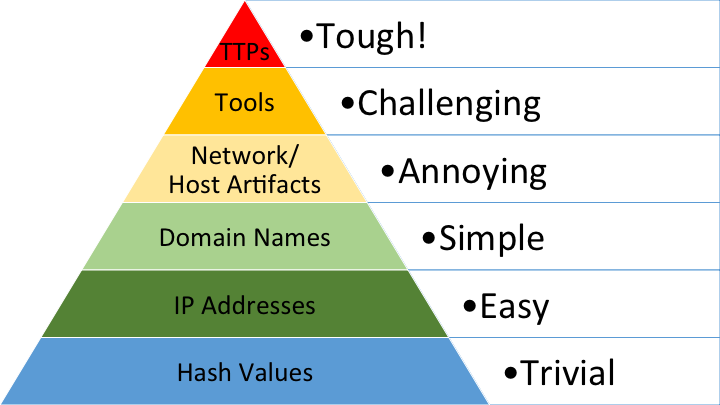
David Bianco很早便提出了入侵检测的 “痛苦金字塔模型”(如图1所示) ,研究指出相对于 “Hash 值”、“IP 地址”等底层入侵指标,“攻击工具” 和 “攻击策略、技术、流程(TTPs)” 等高层特征在入侵检测中有更大的价值,也更难以分析和改变。这是因为底层的入侵指标的出现更具偶然性,因此攻击者很容易改变这些指标来逃避检测。此外,无文件攻击和 “Live-off-the-Land” 攻击等攻击技术的出现,使得攻击行为涉及的底层特征与正常行为完全无法区分。而高层次特征中带有丰富的语义信息(包括攻击的方法、目标、利用的技术等),更具鲁棒性。对于攻击者而言,攻击策略、技术、流程(TTPs)与其最终的攻击目标直接相关,很难被真正的改变,因此对入侵检测更有意义。同时,语义信息可以很好的帮助安全分析人员理解攻击,包括入侵的途径、可能的损失等,从而针对性地做出对应的止损和弥补措施。
2015 年,美国国防部高级研究计划署(DARPA)启动的一项名为 “透明计算(Transparent Computing)” 的科研项目为上述问题的解决提供了可能性。该项目旨在通过将目前不透明的计算系统变得透明,辅助海量的系统日志建模,从而为后续的高层次程序行为分析和高效地入侵检测提供支持。具体来说,该项目将开发一套数据收集与建模系统来记录和建模所有系统和网络实体(包括进程、文件、网络端口等)及其之间的互动和因果关系(Causal Dependency)。这些实体和关系可以以图的形式表示,如图2所示,一般被称为 “溯源图(Provenance Graph)” 或者 “因果图(Causality Graph)”。

上图是一个利用Firefox漏洞进行入侵的溯源图例子:
溯源图是一个带有时间信息的有向图,两个节点之间可能有多条不同属性(包括时间和具体操作等)的边。该图准确的记录了系统实体间的交互关系,包含丰富的信息。前文提到的攻击图可以看作溯源图中提取并抽象后的,与攻击直接相关的部分子图。但需要指出的是,溯源图记录的并不是细粒度的数据流和控制流,而是可能的因果控制关系,因此在进行多跳的分析时会引入错误的依赖,导致核心的依赖爆炸问题,这也是基于溯源图入侵检测的核心问题。【难点】
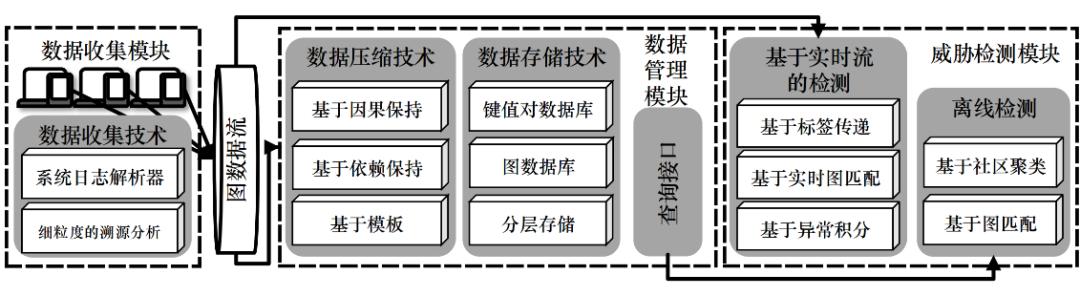
溯源图能很好地还原系统中的各种行为,使其成为了近年来入侵检测领域热门有潜力的研究方向。安全研究者在其基础上设计了多种模型来进行系统中恶意行为地检测与分析,包括 “数据采集、解析和压缩”,“数据存储与压缩”,和 “入侵检测和溯源分析” 在内的许多具体研究问题。我们整理了威胁分析与检测系统的整体框架,如图3所示。以下,我们将具体讨论框架的三个模块并对其中技术进行分析:
数据收集是所有检测和分析系统的基础。一般而言,基于溯源图的威胁检测系统会收集系统日志作为数据源,包括 Windows 的内置日志系统 Event Tracing for Windows(ETW)、Linux 的日志系统 Auditd等。基于依赖分析的方法的一个普遍的挑战是 “依赖爆炸问题”。错误的依赖会导致后续分析的开销与误报指数型增长,导致分析的失败,而细粒度的数据收集可以从根本上缓解这一问题。
ETW(Event Tracing for Windows):https://cloud.tencent.com/developer/article/1020029
系统日志为威胁分析提供了大量有价值的信息,然而其巨大的数据量给数据的存储和分析带来了很大的压力。因此在数据管理模块中,我们一方面需要提供 合理的数据存储模型来存储海量的数据并提供高效的查询分析接口,另一方面要尝试通过 压缩和剪枝去除冗余的数据。
数据存储模型 利用图结构存储溯源图是一种解决思路,但受溯源图规模限制,将图完全存储在内容内存中是不现实的,只能在小规模的实验中使用,无法大规模部署。因此,研究者们提出了将图中所有边视为数据流,每个边只处理一次,并利用节点上标签记录计算过程的方案。为了加以区分,我们将用图数据存储图的方案称为 “缓存图”,流式处理的方案为“流式图”。流式图方案存在优势的原因在于溯源图中边的数量远远大于节点数量,因此查询节点的属性效率比查询边的效率高得多。类似地,一些研究以节点作为键,边为值,将溯源图存储在查询效率更高的关系型数据库中,我们称之为 “节点数据库”。
数据压缩算法 溯源图上的数据压缩算法可以大致分为两类:一类是通用的压缩算法,尽可能地保持了溯源图的信息;另一类与检测和分析算法耦合,使用有较大的局限性,而本文主要分析前者。

溯源图提供了丰富的语义信息,支持多种检测分析方案,如表1所示。这些检测方案考虑了不同的攻击模型,针对不同攻击模型提出来不同的检测模型,大致可以分为几类:
恶意软件继续快速发展,每天捕获超过45万个新样本,这使得手动恶意软件分析变得不切实际。然而,现有的深度学习检测模型需要人工特征工程,或者需要很高的计算开销来进行长时间的训练,这可能会很难选择特征空间,并且很难再训练来缓解模型老化。因此,对探测器的一个关键要求是实现自动、高效的检测。在本文中,我们提出了一种轻量级的恶意软件检测模型SeqNet,该模型可以在原始二进制文件上以低内存进行高速训练。通过避免上下文混淆和减少语义丢失,SeqNet在将参数数量减少到仅136K时保持了检测精度。在我们的实验中,我们证明了我们的方法的有效性和SeqNet的低训练成本要求。此外,我们还公开了我们的数据集和代码,以促进进一步的学术研究。
恶意软件是一种严重的网络安全威胁,可能会对个人和公司系统造成严重损害,例如,急剧减速或崩溃、严重数据丢失或泄漏,以及灾难性的硬件故障。AVTest报告称,平均每天检测到超过45万个新的恶意程序和可能不需要的应用程序。[1]. 大量新的恶意软件变体使得手动恶意软件分析效率低下且耗时。为了更有效地检测恶意软件,许多研究人员提出了用于恶意软件分析和检测的高级工具[2,5,9,14]。这些工具通过对分析员的行为进行部分工作,帮助他们更高效地完成任务。然而,在处理如此大量的恶意软件时,这些解决方案无法从根本上减少工作量。为了解决这个问题,许多专家和学者将机器学习算法,尤其是深度学习应用于恶意软件检测和分类[7,12,15,16,18,22,26,28,34,37,45,50,51,53,55,58-60,62,63]。他们的努力为恶意软件分析神经网络的研究和实用的恶意软件自动检测做出了很大贡献。
然而,这些模型通常需要各种特征工程来帮助神经网络做出判断,这可能很费劲,并且容易丢失一些关键信息。为了实现更加友好和自动的检测,提出了基于二进制的方法[31,37,41,42]。两种流行的原始二进制处理方法是文件剪切和二进制图像转换。然而,这两种方法可能会遇到语境混乱和语义丢失,这将在后面讨论。
此外,模型老化是神经网络的一个关键问题[25,40]。与计算机视觉和自然语言处理不同,恶意软件正在不断快速发展。恶意软件检测是攻击者和检测器之间的斗争。随着恶意软件的不断发展,深度学习模型可能已经过时。例如,五年前训练的模型在今天的恶意软件检测中可能非常薄弱。神经网络很难识别看不见的恶意行为,这可能会导致较低的检测精度和更容易的规避。模型不可能预测未来恶意软件的特征,但快速学习检测新恶意软件的知识是可行的。因此,再培训模式成为缓解老龄化问题的少数方法之一。我们可以让神经网络快速重新训练,学习新恶意软件的新特征,以便识别新的攻击方法。
由于模型的结构和规模,再培训可能会耗费时间和计算量,而且如此高的成本可能会导致模型更新困难。此外,恶意软件检测是几乎所有电子系统中的常见操作,对于计算能力较低的设备来说,进行检测是必要的。例如,笔记本电脑或其他移动设备很难运行一个庞大的模型来扫描所有文件以检测恶意软件。这些要求表明,检测模型应该足够小和有效,使其更实用,以便我们能够快速重新培训或执行检测。此外,无需复杂特征工程的自动检测对于各种场景中使用的模型至关重要。
总的来说,我们的工作面临两个挑战:自动化和高效。检测模型应该足够自动化,并且几乎不需要人工特征工程。该模型的规模应足够小,以降低训练和检测成本。
在本文中,我们提出了一个有效的恶意软件自动检测模型,该模型只有大约136K个参数,我们称之为SeqNet。在没有人工特征选择的情况下,SeqNet可以仅基于原始二进制文件自动分析样本并找出恶意程序和良性程序之间的差异。较小的神经网络通常具有较少的参数,这可能会导致较低的学习能力。这可能是因为较小的模型往往更难适应从原始二进制文件到恶意域的复杂映射。这个问题可能会导致小型深度学习模型中恶意软件检测的准确性较低。
为了在减少参数数量时保持准确性,我们提出了一种新的二进制代码表示方法,以减少语义损失并避免上下文混淆。根据我们的方法,我们使SeqNet在无需特征工程的情况下,在可移植可执行(PE)恶意软件检测方面表现良好。基于这种表示方法,我们创建了一种新的卷积方法,称为序列深度可分离卷积(SDSC),以进一步压缩检测模型的规模。我们在一个大型PE数据集上对SeqNet进行训练,发现与许多现有的基于二进制的方法和模型相比,它具有很好的性能。我们还在进一步的实验中证明了我们的模型收缩方法的有效性。此外,我们还公开了我们的代码和数据集以供进一步研究,我们希望深度学习算法能够更好地应用于恶意软件检测。
我们在一个大型PE数据集上对SeqNet进行训练,发现与许多现有的基于二进制的方法和模型相比,它具有很好的性能。我们还在进一步的实验中证明了我们的模型收缩方法的有效性。此外,我们还公开了我们的代码和数据集以供进一步研究,我们希望深度学习算法能够更好地应用于恶意软件检测。
这是本文的布局。第2节介绍了深层恶意软件检测的主要方法和几个问题。第3节描述了我们应用于SeqNet的主要方法。第四部分阐述了我们的实验和相应的结果。
在本节中,我们将介绍使用深度学习进行恶意软件检测的背景。首先,我们列举了这方面的两种主要方法。然后进一步讨论了目前流行的二进制表示方法的几个问题。最后,我们解释了其中一种方法所基于的深度可分离卷积。
神经网络具有强大的学习能力,在计算机视觉和自然语言处理中得到了广泛的应用。深度学习算法已经被许多研究人员应用于恶意软件检测。据我们所知,我们认为有两种主流思想,类似于[47]。
基于特征的方法。在早期作品中,深度学习模型是从精心制作的恶意软件功能中训练出来的[7、15、16、18、26、28、34、58、63]。在检查可疑样本时,模型需要提取特定特征,以特定方式处理它们,然后检测恶意代码以给出结果。所选功能可以是API调用、控制流图(CFG)或任何其他能够反映程序操作的信息。的确,人工特征学习是神经网络识别恶意样本和良性样本之间主要差异的有效方法。然而,特定的领域特征只能从一个角度很好地描述样本的关键信息。它不能完全覆盖二进制代码的语义,甚至会引发严重的信息丢失。例如,仅使用API调用作为特性会导致模型忽略控制流。此外,精心设计的功能需要足够的先验知识,这需要专家仔细选择。因此,耗时的手动特征提取可能会限制基于特征的模型的使用,并使其难以对抗恶意软件的持续演化。
基于二进制的方法。与传统的特征工程相比,自动特征提取是神经网络的发展趋势之一,人工干预更少,性能更好。我们读取文件的二进制文件,直接将其发送到检测模型,无需或几乎不需要预处理。该模型将自动找到可疑部分,并将二进制文件识别为恶意或良性。这种方法可以更有效地避免人们分析恶意软件的需要,并更好地减少分析人员的工作量。此外,通过减少手动特征工程造成的损失,直接从原始二进制文件学习可能会更好地保留语义和上下文信息。
为了使我们的模型更加自动化,避免信息丢失,我们将重点放在基于二进制的模型上,SeqNet将原始二进制文件用作输入。此外,较低的计算开销可以使模型更好地适应恶意软件的演变,并扩展应用场景,例如在物联网环境中。我们将一种新颖但简单的二进制代码表示方法应用于SeqNet,并在减少参数时保持其性能。
在这一部分中,我们将介绍几种主要的二进制代码表示方法,它们适用于基于二进制的模型。将样本转换为神经网络的输入会显著影响模型的性能。因此,正确的二进制代码表示方法是基于二进制的恶意软件检测神经网络的重要组成部分。目前,人们提出了两种主要的方法来完全表示原始二进制码。
文件剪切。由于内存限制的限制,许多作品对最大文件大小设置了人为限制,这种方法是从二进制程序的开头提取一段固定长度的代码片段。如果二进制程序的长度小于所需代码段的长度,则该代码段的末尾将填充零。文件剪切会导致语义信息丢失,因为如果二进制文件的结尾比固定长度长得多,就会忽略它。然而,恶意代码通常位于二进制文件的末尾。例如,嵌入的病毒通常嵌入在受感染文件的尾部,这可能有助于它们逃避基于这种方法的模型的检测。为了缓解这个问题,Mal-ConvGCT[42]通过扩展代码段大小限制来提高MalConv[41]的性能。
二值图像转换。第二种方法将所有二进制代码转换为图像,并利用图像分类解决方案执行恶意软件检测。所有图像都可以使用双线性插值算法重新采样到相同的大小。然而,图像与序列不同,这可能会导致几个问题。我们认为这种方法会导致上下文信息混乱,下面列举了三个例子。
文件剪切导致的语义丢失和二值图像转换导致的上下文混乱阻碍了恶意软件检测模型的性能。这些问题可能会混淆神经网络,甚至误导它们做出截然相反的决定。通过缓解这些问题,我们可以帮助我们的模型在减少参数时保持其性能。
传统的卷积算法模拟动物视觉,在计算机视觉中具有很好的性能。这个简单的操作可以有效地提取图像中的视觉特征。低级卷积层检测图像中的纹理和简单特征,高级卷积层可以识别内容和整体语义[61]。这就是为什么计算机可以通过多个卷积层的叠加来识别复杂的物体。
然而,传统卷积所需的参数数量往往使得深度学习模型太大,无法应用于计算能力较低的设备。此外,参数过多的模型可能需要很长的训练过程。例如,VGG有超过1.3亿个参数,已经接受了2年的培训 3周[49]。如此庞大的模型不适合在普通设备上运行。
因此,我们将CNN架构应用于SeqNet,并将DSC的输入形式从2D调整为1D,从而更好地减少了训练参数的数量。因此,训练时间成本和新生成的模型的大小都进一步减小。我们的方法的细节在第3节中描述。
在本节中,我们将介绍SeqNet的详细信息。首先,我们概述了我们的方法。其次,我们引入了可以减少语义损失和避免语境混淆的序列表征。第三部分描述了SDSC如何压缩模型的规模。最后,我们详细介绍了SeqNet的体系结构。
SeqNet的目标是以较低的培训成本实现高效、自动的恶意软件检测。在整个培训和检测过程中,操作员不需要专业的恶意软件分析知识来执行手动领域特定的功能工程。实际上,我们直接将原始二进制文件输入SeqNet,SeqNet将自动分析序列并提取特征。SeqNet的输出是可疑样本的恶意可能性,输入样本是否为恶意软件取决于模型给出的可能性。
准确检测是恶意软件检测模型的基本要求。我们认为恶意软件检测不同于图像分类。恶意软件检测可能需要更多地关注几个关键的恶意代码,而图像分类可能更关注整体。根据这一理论,我们对SeqNet的主要设计要点之一是减少上下文混淆和语义丢失。我们使用原始二进制序列作为SeqNet的输入,这样可以避免上下文混淆,减少语义损失。
轻量级模型通常具有更广泛的应用场景和更快的检测性能。显然,小型模型的培训成本也很低。因此,压缩SeqNet的规模是必要的。新的卷积方法,称为序列深度可分离卷积(SDSC),有助于SeqNet满足这一要求。
输入格式对神经网络性能和模型大小至关重要。较大的输入往往导致较大的模型,适当的输入格式可以有效地提高神经网络的学习效果。SeqNet的输入是原始二进制序列,这些序列通过线性插值算法调整到相同的长度。原始二进制序列输入几乎不需要人工干预。在不转换为图像的情况下,很明显,我们可以避免上下文信息混淆,减少语义损失,如图所示

一个例子表明,序列表征可以解决上下文混淆和语义丢失的问题。在图像中,二进制指令“BF 01 00”在边缘被切断,但它仍保留序列中的形状。插值后,我们可以看到,图像强制加强了“56”与“00”之间的关系,其中“56”表示“推esi”,而“00”在“0F 85 93 00 00 00 00 00”中表示“jnz loc 1000DF90”,但它忽略了具有更强关系的指令,例如“推edi”和“mov edi,1”。在序列中,指令“56”与前端结合,而不是“00”,并且在物理上与“57”保持接近,后者表示“推edi”。在图像中,输入到卷积层之前添加的填充提供了不正确的位置信息,但在序列中,它标记了开始和结束。
在缩放到相同的长度之前,我们首先规范化整个序列,使元素的值介于-1和1之间,并以浮点格式存储。由于实数字段的连续性,浮点格式可以比整数格式代表更多的信息。因此,这个操作对于减少线性插值算法造成的语义损失是必要的,如图4所示。通过对数据集进行统计,我们发现大多数文件的大小约为256KB。因此,我们将所有输入序列扩展到2^18字节。
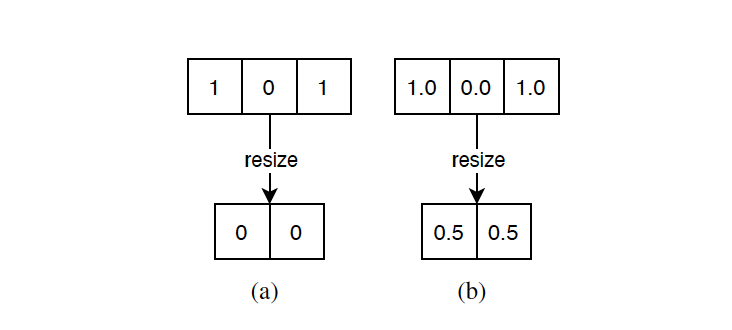
图4:如果我们在规范化之前调整序列的大小,结果不能代表原始二进制代码(a)中的所有信息。相反,如果我们在规范化后调整以浮点格式存储的序列的大小,我们可以有效地减少语义损失(b)。
在序列格式中,指令之间的所有信息都将得到正确和更好的保留。两条指令之间的物理距离反映了关系的真实强度。这种表示方法还利用了代码中的空间局部性,因为模型将更多地关注附近的指令,而不是那些相关性较弱的指令。因此,该模型在学习和检测时接收到的干扰较小。
使用序列特征而不是二进制图像转换的另一个原因是,可执行文件的前后相关性比平面相关性更明显。这就是为什么序列可以更好地代表程序。
序列输入格式不仅解决了语义丢失和上下文混淆的问题,还压缩了SeqNet的规模。SeqNet的卷积核只需要在只有一维的序列上提取特征。与处理一维输入相比,提取二维特征需要更大的卷积核和更多的计算。例如,如图2(c)所示,a 3 3用于图像的内核至少需要10个参数(包括偏差),而3 1序列中使用的内核只需要至少四个参数(包括偏差)。
基于序列输入和深度可分离卷积[21],我们提出了一种称为序列深度可分离卷积(SDSC)的方法,它需要更少的参数和更少的计算。在SDSC中,我们使用3 1个内核替换DSC中的2D深度卷积内核。通过使用SDSC层,SeqNet的尺寸比现有模型小得多。在下文中,我们分析了与DSC相比计算量的减少。
此外,SDSC的输入是一维数据,因此与DSC相比,它不太容易受到无关指令的影响。在实验中,我们发现SDSC具有良好的性能,并成功地保持了SeqNet的性能。基于SDSC,我们在SeqNet中使用了以下两种主要的卷积块架构。
SeqNet的构建主要基于SDSC,图6解释了该架构。为了减少参数的数量,我们使用更小的核和更深的结构,这也可以扩大感受野。标准SDSC块用于在对序列进行下采样时提取特征。对于第一个卷积层,我们使用单个公共卷积层嵌入原始输入,内核大小为3*1.我们设置大小是因为经常使用的CPU指令的长度通常是三个字节。对于高层特征,我们使用五个剩余的SDSC块进行分析,与完全连接的层相比,这也可以更好地保留上下文和空间信息。此外,残差SDSC块可以防止梯度消失,使模型快速收敛。最后两层是完全连接层和softmax层。全连通层用于对模型前端给出的分析结果进行分类。

在这个公式中,P表示转换后的结果,x表示softmax层的输入。对于池层,我们使用平均池。在我们的实验中,我们发现当剩余SDSC块的数量为5个,输入128个通道,并且完全连接的层的数量仅为1个时,该模型的性能最好。SeqNet输出样本的恶意可能性,如果可能性超过50%,模型将视其为恶意软件。根据输出,对于损失函数,我们使用交叉熵函数。SeqNet总共只有大约136K个参数,几乎是MalConv的十分之一,我们将在第4节中讨论。
建立良好的培训数据集对于评估SeqNet的性能至关重要。正确的标签和足够的样本是展示SeqNet学习能力的必要条件。对于样本类型,我们认为PE恶意软件是电子系统的主要威胁之一。此外,有很多PE恶意样本,很容易获得足够的PE样本。
因此,以下实验适用于一组PE文件,因为它们很普遍。在这项工作中,所有恶意样本都来自VirusShare[4]。齐安信公司提供了约10000份良性样本。我们还从真实的个人电脑中收集了许多良性样本,以模拟我们日常生活中的真实环境。为了确保良性样本中没有混合病毒,我们使用VirusTotal[6]检测所有文件。如果在VirusTotal报告中没有AV引擎将其视为恶意软件,我们将其视为良性样本。操作系统文件和恶意软件通常具有类似的行为,这可能会混淆检测模型,甚至会混淆训练有素的分析师[8]。因此,为了帮助SeqNet观察恶意程序和良性程序之间的一般差异,并使SeqNet更加健壮,我们添加了大约10000个系统文件作为良性数据。VirusTotal[6]也会检查系统文件,以确保它们是良性的。我们总共获得了72329个二进制文件的训练数据集,其中37501个恶意文件和34828个良性文件,以及24110个二进制文件的验证数据集,其中12501个恶意文件和11609个良性文件。
数据集中的所有文件都是PE文件,我们通过比较SHA256值来消除重复。我们将恶意和良性样本的比例设置为1左右,以确保结果可靠。例如,如果数据集只有恶意样本,模型可能会通过识别“4D 5A”来检测所有恶意软件。相反,如果我们向数据集中添加足够多的良性样本,模型就可以了解恶意样本和良性样本之间的真正区别。
在我们的实验中,我们从训练成本和准确性两个方面测量SeqNet。对于培训成本测量,我们使用参数的数量来表示模型的规模。更大的模型包含更多的神经元,需要更多的参数来构建。在训练和预测过程中,每个参数都会占用恒定的内存。因此,参数的数量显著影响模型训练和预测所需的记忆。为了准确测量模型推理的计算开销,我们通过输入一个随机二进制来计算每个模型上的浮点运算(Flops)。我们还通过记录一个历元所需的时间来测量模型的速度,包括训练和验证过程。
设置模型和培训设置会显著影响培训过程和结果。所有模型都经过70个阶段的训练,我们选择了过去30个阶段的验证结果,以获得平均精度和其他指标。我们将批量大小设置为32,并选择Adam[29]作为所有模型的优化器。为了保证训练的公平性,我们将交叉熵损失应用于所有模型。

我们选择几种最先进的基于二进制的方法作为基线。为了反映基于图像转换的模型的总体性能,我们选择著名的MobileNet[21]作为代表性模型。我们将程序转换为RGB图像作为MobileNet的输入。在转换过程中,一个字节映射一个通道中的一个像素。对于基于文件剪切的模型,我们选择MalConv[41]和MalConvGCT[42]。ResNet和MobileNet都是由Pytorh[39]实现的,我们使用ResNet18作为ResNet,而MobileNet v2作为MobileNet。我们使用MalConv和MalConvGCT作者提供的源代码,并将它们应用到我们的实验中。我们在每个模型的末尾添加一个softmax层,以便在验证时将结果转换为可能性格式。根据表1中的参数数量,我们可以发现SeqNet的最小参数仅为MalConv和Mal-ConvGCT的十分之一。此外,SeqNet在恶意软件检测方面保持了良好的性能。图7是精度和模型尺寸对比图,左上角的模型位置表明模型尺寸较小,精度较高。
精度还表明,SeqNet误解良性样本的可能性很低。此次召回意味着SeqNet可能有能力防止逃税。在训练过程中,我们发现大多数模型在第一个历元后达到90%的准确率。在我们的训练中,我们发现SeqNet只需要大约两分钟半就可以完成一个历元,而Mal-Conv大约需要一个小时。因此,我们可以看到,SeqNet的微小尺寸导致了较低的计算开销,基于卷积的体系结构加速了训练和推理。

接下来,我们将描述进一步的实验,以讨论SeqNet中的上下文混淆避免、模型收缩和架构设计。我们对SeqNet进行了几个简单的更改,以测试我们的假设。
我们还检查了SeqNet的健壮性,并将其与MalConv进行了比较。关于攻击深度模型有大量的研究[24,32,36,44,48,54,56]。然而,与针对图像相关任务的神经网络的传统攻击不同,我们不能直接在二进制文件上添加扰动,因为这可能会使二进制文件不可执行。此外,我们很难根据提取的特征[47]调整攻击策略以适应原始的二进制模型。因此,对于攻击策略,我们采用[30]中的方法,在输入端的填充部分注入一个短的有毒二进制文件。
由于Mal-Conv和SeqNet之间的输入格式不同,我们等效地采用了有毒二进制生成方法。与沿梯度选择最近的嵌入向量相比,SeqNet的毒药生成过程如下所示。
为了使攻击策略在有限的二进制长度下有效,我们从验证恶意数据集中随机选择了500个可用样本。我们将毒药的长度设置为32000字节,MalConv的整个二进制文件固定为16000000字节,并逐步增加毒药生成迭代次数。我们测试了SeqNet和MalConv错误分类的样本数量。结果如图9所示。我们看到SeqNet对有毒二进制攻击有很强的防御能力。我们假设这种现象是由于文件剪切方法中的填充部分造成的漏洞。基于文件剪切的模型在训练时经常会看到不完整的二进制文件。因此,文件剪切中的填充使攻击者有机会混淆模型,而模型不确定有毒二进制文件是否是样本的一部分。与文件剪切相比,我们的方法可以通过输入整个二进制文件来缓解这个问题。然而,我们认为这一理论仍需进一步验证,我们可能会在未来的工作中对其进行研究。
为了更好地理解SeqNet所学到的知识,我们随机选择了四个样本,并使用Grad CAM[46]解释技术生成热图,以便我们能够可视化哪个部分对结果影响最大。此外,我们还手动分析相应的样本,以验证SeqNet是否找到了正确的恶意代码。在手动分析中,我们通过IDA Pro[3]分解样本,精确定位恶意功能或代码。为了更好地绘制结果,我们提取了热图的关键部分,并对片段应用以下归一化公式。
其中X表示代码段。用于热图的激活图是由SeqNet的最后一个卷积层和ReLU层生成的,因为剩余的空间信息由卷积层编码。我们还在原始二进制文件上标记手动定位结果,以便更好地进行比较。图10显示了手动定位和基于梯度凸轮的解释之间的比较。我们看到,本地激活位置与分析人员定位的恶意部件接近,这反映了SeqNet可能会发现恶意代码并进行可靠的检测。在我们的解释中,我们发现在整个热图中有许多噪音。我们认为这可能是因为数据集中可能存在潜在的异常统计[10]和一些错误标签[43]。然而,遗憾的是,由于学术界对良性档案的忽视,我们很难收集到更多的良性样本。我们希望在未来的工作中能够探索这一现象。此外,我们还发现PE头通常会对SeqNet产生很大影响。这可能意味着PE头包含恶意软件中的恶意信息。更多细节见附录。
在这一部分中,我们将讨论我们的工作的局限性,并提出一些未来需要进一步研究的工作。
尽管SeqNet表现良好,但我们的工作仍有一些局限性。仍然是语义缺失。虽然我们有效地减少了语义损失,但SeqNet的输入仍然不能包含所有语义。如果序列太长,在插值过程中会对序列进行压缩,压缩后的序列不能代表所有原始信息。此外,如果序列太短,序列将被扩展,这可能会混淆SeqNet。SeqNet的体系结构决定了输入必须具有相同的大小,这是SeqNet的一个限制。
缺乏良性样本。我们面临的主要困难是缺乏良性样本。我们可以获得大量恶意软件收集网站,但很难找到权威的良性样本提供商。为了均匀采样,仅通过添加恶意样本来扩展训练数据集是不合适的,这可能会降低SeqNet的性能,并使实验结果不可靠。因此,很难在具有足够样本的更大数据集上训练神经网络。
标签的质量。除了缺乏良性样本,标签的质量可能是一个潜在问题。由于权威供应商寥寥无几,我们无法保证培训和验证数据集中的所有良性样本都正确标记。我们数据集中的所有恶意样本都是从VirusShare收集的,无需人工确认。几家报纸检查了恶意软件标签的质量,发现它可能达不到我们的预期[43]。虽然这些限制可能会对SeqNet的训练过程产生一些影响,但我们假设,几个不正确的标记样本不会显著影响整体性能。
可能存在的漏洞。对抗性攻击是大多数神经网络的风险,我们也不例外。有动机的对手可能会污染训练数据集,并逃避SeqNet的检测。此外,基于梯度的攻击是混淆深度学习模型的有效方法[17,30,32]。相反,这个问题也有很多解决方案[7,12,20,33,57]。虽然SeqNet可以抵御多次攻击,但我们仍然无法完全保证SeqNet的安全。此外,SeqNet的健壮性原则需要我们进一步探索。
我们提出了一种高效的恶意软件自动检测神经网络SeqNet。SeqNet的主要目标是实现自动、高效的检测,可以以较低的原始二进制文件培训成本快速进行培训。尽管如此,未来仍有许多工作需要完成。基于深度学习的恶意软件检测研究的最大障碍之一是缺乏工业规模的公共可用数据集。研究人员需要权威可靠的数据集,这些数据集不仅包含恶意特征,还包含原始二进制序列。我们将建立一个更大的数据集,以进一步评估SeqNet的性能。此外,还需要足够的良性样本进行进一步研究。我们认为,当使用深度学习模型进行检测时,恶意软件分析不仅应该关注恶意样本,还应该关注良性样本。由于神经网络是黑盒模型,恶意软件检测神经网络的可靠性可能会受到怀疑。虽然SeqNet给了我们很好的结果,但我们仍然无法完全解释原因。因此,在实践中使用深度学习算法检测恶意软件仍需进一步研究。通过我们的实验,我们认为神经网络在恶意软件检测方面可能具有巨大的潜力,我们期待着神经网络在这一领域取得重大突破。SeqNet的健壮性仍需进一步研究。我们仍然缺乏这方面的实验和研究。在未来的工作中,我们将更深入地探索该模型的稳健性,并对其进行更多的改进和分析。
基于二进制的模型。与传统的特征工程相比,自动特征提取是神经网络的发展趋势之一,人工干预更少,性能更好。Raff等人设计了一种称为MalConv的架构,它可以直接从原始PE二进制样本中学习,而无需手动选择特征[41,42]。Krc al等人设计了一个简单的CNN,可以从PE原始字节序列中学习,而无需特定领域的特征选择,这项工作获得了较高的AUC分数,尤其是在小型PE恶意软件样本上[31]。
在工业界,推荐算法和自然语言处理是结合非常紧密的两个技术环节。本次大赛我们推出创新赛制——NLP 和推荐算法双赛道:探究文本情感对推荐转化的影响。情感分析是NLP领域的经典任务,本次赛事在经典任务上再度加码,研究文本对指定对象的情感极性及色彩强度,难度升级,挑战加倍。同时拥有将算法成果研究落地实际场景的绝佳机会,接触在校园难以体验到的工业实践,体验与用户博弈的真实推荐场景。
比赛分为两部分:
1 | train_file = 'data/Sohu2022_data/nlp_data/train.txt' |

1 | train['text_len'].quantile([0.5,0.8,0.9,0.96]) |
大部分文本长度在562以内,在迭代过程中发现,输入到模型的文本越完整效果越好,所以可以尝试文档级的模型,比如ernie-doc或者xlnet等。

1 | sns.countplot(sentiment_df.sentiment) |

可以看出中性情感占到了绝大部分,极端情感最少。因为数据量比较大,大家可以使用一些采样策略:
重复标签:同一样本的标签有多个,然后按照多个实体情感对样本进行复制,得到每个文本以及标签,处理代码如下:
1 | lst_col = 'sentiment' |
1 | class LastHiddenModel(nn.Module): |
(xlnet) https://huggingface.co/hfl/chinese-xlnet-base
(longformer_zh) https://huggingface.co/ValkyriaLenneth/longformer_zh
(longformer-chinese-base-4096) https://huggingface.co/schen/longformer-chinese-base-4096
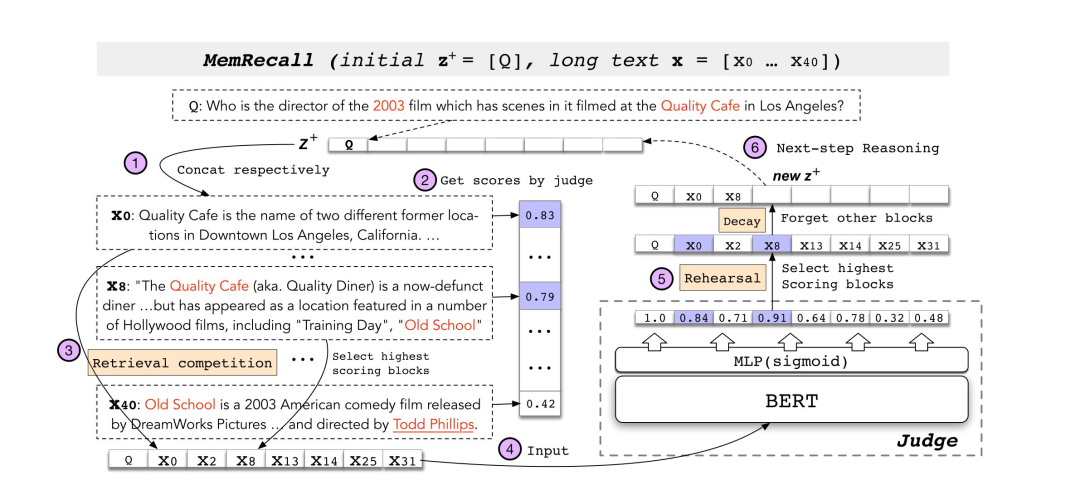
- XLNET分类模型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from transformers import XLNetModel
class MyXLNet(nn.Module):
def __init__(self, num_classes=35, alpha=0.5):
self.alpha = alpha
super(MyXLNet, self).__init__()
self.net = XLNetModel.from_pretrained(xlnet_cfg.xlnet_path).cuda()
for name, param in self.net.named_parameters():
if 'layer.11' in name or 'layer.10' in name or 'layer.9' in name or 'layer.8' in name or 'pooler.dense' in name:
param.requires_grad = True
else:
param.requires_grad = False
self.MLP = nn.Sequential(
nn.Linear(768, num_classes, bias=True),
).cuda()
def forward(self, x):
x = x.long()
x = self.net(x, output_all_encoded_layers=False).last_hidden_state
x = F.dropout(x, self.alpha, training=self.training)
x = torch.max(x, dim=1)[0]
x = self.MLP(x)
return torch.sigmoid(x)
第二部分:利用给出的用户文章点击序列数据及用户相关特征,结合第一部分做出的情感分析模型,对给定的文章做出是否会形成点击转化的预测判别。用户点击序列中涉及的文章,及待预测的文章,我们都会给出其详细内容。
1 | train = pd.read_csv('data/Sohu2022_data/rec_data/train-dataset.csv') |

训练集中每条样本包含pvId,用户id,点击序列(序列中的每次点击都包含文章id和浏览时间),用户特征(包含但不限于操作系统、浏览器、设备、运营商、省份、城市等),待预测文章id和当前时间戳,以及用户的行为(1为有点击,0为未点击)。
smapleId:样本的唯一id
label:点击标签
pvId:将每次曝光给用户的展示结果列表称为一个Group(每个Group都有唯一的pvId)
suv:用户id
itemId:文章id
userSeq:点击序列
logTs:当前时间戳
operator:操作系统
browserType:浏览器
deviceType:设备
osType:运营商
province:省份
city:城市
1 | def statics(data): |

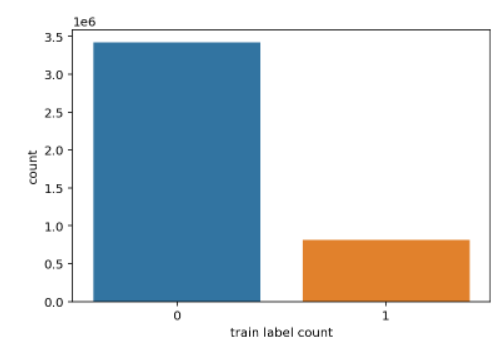
1 | sns.countplot(train.label) |
1 | amount_feas = ['prob_0', 'prob_1', 'prob_2', 'prob_3','prob_4' ] |
1 | # count特征 |
1 | # count特征 |
1 | # pvId nunique特征 |
基于deepctr实现DeepFM训练
1 | train_model_input = {name: train[name] for name in feature_names} |
1 | train_model = CatBoostClassifier(iterations=15000, depth=5, learning_rate=0.05, loss_function='Logloss', logging_level='Verbose', eval_metric='AUC', task_type="GPU", devices='0:1') |
没有哪个机器学习模型可以常胜,如何找到当前问题的最优解是一个永恒的问题。
幸运的是,结合/融合/整合 (integration/ combination/ fusion)多个机器学习模型往往可以提高整体的预测能力。这是一种非常有效的提升手段,在多分类器系统(multi-classifier system)和集成学习(ensemble learning)中,融合都是最重要的一个步骤。
一般来说,模型融合或多或少都能提高的最终的预测能力,且一般不会比最优子模型差。举个实用的例子,Kaggle比赛中常用的stacking方法就是模型融合,通过结合多个各有所长的子学习器,我们实现了更好的预测结果。基本的理论假设是:不同的子模型在不同的数据上有不同的表达能力,我们可以结合他们擅长的部分,得到一个在各个方面都很“准确”的模型。当然,最基本的假设是子模型的误差是互相独立的,这个一般是不现实的。但即使子模型间的误差有相关性,适当的结合方法依然可以各取其长,从而达到提升效果。
我们今天介绍几种简单、有效的模型结合方法。
让我们给出一个简单的分析。假设我们有天气数据X和对应的标签 \(\mathrm{y}\), 现在希望实现一个可以预测明天天气的模型 \(\psi\) 。但我们并不知道用什么算法效果最好, 于是尝试了十种算法, 包括
结果发现他们表现都一般,在验证集上的误分率比较高。我们现在期待找到一种方法,可以有效提高最终预测结果。
一种比较直白的方法就是对让 10 个算法模型同时对需要预测的数据进行预测, 并对结果取平均数/众数。假设 10 个 分类器对于测试数据 \(X_t\) 的预测结果是 \(\left[C_1\left(X_t\right), C_2\left(X_t\right), \ldots, C_{10}\left(X_t\right)\right]=[0,1,1,1,1,1,0,1,1,0]\) ,那很显然少数服 从多数, 我们应该选择1作为 \(X_t\) 的预测结果。如果取平均值的话也可以那么会得到 0.7 , 高于阈值 0.5 , 因此是等 价的。
但这个时候需要有几个注意的地方:
首先,不同分类器的输出结果取值范围不同,不一定是[0,1],而可以是无限定范围的值。举例,逻辑回归的输出范围是0-1(概率),而k-近邻的输出结果可以是大于0的任意实数,其他算法的输出范围可能是负数。因此整合多个分类器时,需要注意不同分类器的输出范围,并统一这个取值范围。
其次,就是整合稳定性的问题。采用平均法的另一个风险在于可能被极值所影响。正态分布的取值是 \([-\infty,+\infty]\) ,在少数情况下平均值会受到少数极值的影响。一个常见的解决方法是,用中位数(median)来代替平均数进行整合。
同时,模型整合面临的另一个问题是子模型良莠不齐。如果10个模型中有1个表现非常差,那么会拖累最终的效果,适得其反。因此,简单、粗暴的把所有子模型通过平均法整合起来效果往往一般。
不难看出,一个较差的子模型会拖累整体的集成表现,那么这就涉及到另一个问题?什么样的子模型是优秀的。
一般来说,我们希望子模型:准而不同 -> accurate but diversified。好的子模型应该首先是准确的,这样才会有所帮助。其次不同子模型间应该有差别,比如独立的误差,这样作为一个整体才能起到互补作用。
因此,如果想实现良好的结合效果,就必须对子模型进行筛选,去粗取精。在这里我们需要做出一点解释,我们今天说的融合方法和bagging还有boosting中的思路不大相同。bagging和boosting中的子模型都是很简单的且基数庞大,而我们今天的模型融合是结合少量但较为复杂的模型。
因此我们不能再简单的取平均了, 而应该给优秀的子模型更大的权重。在这种前提下, 一个比较直白的方法就是根 据子模型的准确率给出一个参考权重 \(w\) ,子模型越准确那么它的权重就更大, 对于最终预测的影响就更强: \(w_i=\frac{A c c\left(C_i\right)}{\sum_1^{10} A c c\left(C_j\right)}\) 。简单取平均是这个方法的一个特例, 即假设子模型准确率一致。
在4中提到的方法在一定程度上可以缓解问题,但效果有限。那么另一个思路是,我们是否可以学习每个分类器的权重呢?
答案是肯定,这也就是Stacking的核心思路。通过增加一层来学习子模型的权重。
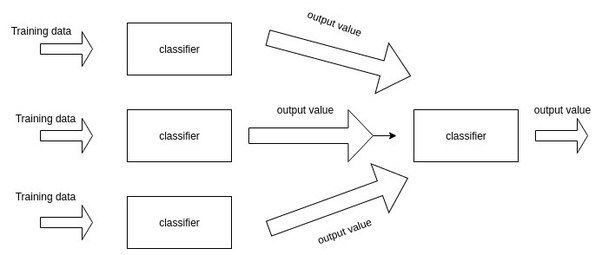
图片来源:https://www.quora.com/What-is-stacking-in-machine-learning
更多有关于stacking的讨论可以参考我最近的文章:集成学习总结-Stacking和神经网络。简单来说,就是加一层逻辑回归或者SVM,把子模型的输出结果当做训练数据,来自动赋予不同子模型不同的权重。
一般来看,这种方法只要使用得当,效果应该比简单取平均值、或者根据准确度计算权重的效果会更好。
python_mmdt:ssdeep、tlsh、vhash、mmdthash对比 : https://www.freebuf.com/sectool/321011.html
局部敏感哈希(Locality Sensitive Hashing,LSH)总结:http://yangyi-bupt.github.io/ml/2015/08/28/lsh.html
局部敏感哈希(Locality Sensitive Hashing,LSH)的基本思想类似于一种空间域转换思想,LSH算法基于一个假设,如果两个文本在原有的数据空间是相似的,那么分别经过哈希函数转换以后的它们也具有很高的相似度;相反,如果它们本身是不相似的,那么经过转换后它们应仍不具有相似性。
CTPH(ssdeep):Context
Triggered Piecewise Hashes(CTPH),又叫模糊哈希,最早由Jesse
Kornblum博士在2006年提出,论文地址点击这里。CTPH可用于文件/数据的同源性判定。据官方文档介绍,其计算速度是tlsh的两倍(测试了一下,好像并没有)。
当使用传统的加密散列时,会为整个文件创建一个散列。单个位的变化会对输出哈希值产生雪崩效应。另一方面,CTPH 为文件的多个固定大小段计算多个传统加密哈希。它使用滚动哈希。
tlsh:是趋势科技开源的一款模糊哈希计算工具,将50字节以上的数据计算生成一个哈希值,通过计算哈希值之间的相似度,从而得到原始文件之间的同源性关联。据官方文档介绍,tlsh比ssdeep和sdhash等其他模糊哈希算法更难攻击和绕过。
vhash:(翻遍了整个virustotal的文档,就找到这么一句话)“an in-house similarity clustering algorithm value, based on a simple structural feature hash allows you to find similar files”,大概就是说是个内部相似性聚类算法,允许你通过这个简单的值,找到相似的样本。
mmdthash:是开源的一款模糊哈希计算工具,将任意数据计算生成一个模糊哈希值,通过计算模糊哈希值之间的相似度,从而判断两个数据之间的关联性。详情前文1-5篇。
#### mmdthash:
通过重采样之后的数据,我们假设其满足独立同分布。同时,我们将重采样的数据,平均分成N块,每块之间的数据进行累计求和,和值分布近似服从正态分布,我们取和值高x位的一个byte做为本块数据的敏感哈希值。
51030000:D6E26822530202020202020202020202:
51030000是4字节索引敏感哈希D6E26822530202020202020202020202是16字节敏感哈希
简单应用如,索引敏感哈希可以转成一个int32的数字,当索引敏感哈希相等时,再比较敏感哈希的距离(如曼哈顿距离,将敏感哈希转成N个unsigned char类型计算敏感哈希,此时00和FF之间的距离可算作1,也可算作255,具体看实现)。
由于特征向量的维度是固定的,因此可以很方便的使用其他数学方法,进行大规模计算。
色情导流赛道 2ndSolution https://github.com/rooki3ray/2021BytedanceSecurityAICompetition_track1
随着互联网的快速发展,网络黑产特别是色情导流也日益增多,给用户带来了极大的伤害。色情导流用户发布色情/低俗内容吸引用户,并且通过二维码、联系方式、短网址等完成导流。本赛题旨在通过提供用户相关数据,运用机器学习等方法对色情导流用户进行识别,提高模型检测的效果。


from config import Config
import argparse
1 | . |
1 | set -x |
在真实的社交网络中,存在的作弊用户会影响社交网络平台。在真实场景中,会受到多方面的约束,我们仅能获取到少部分的作弊样本和一部分正常用户样本,现需利用已有的少量带标签的样本,去挖掘大量未知样本中的剩余作弊样本。给定一段时间内的样本,其中包含少量作弊样本,部分正常样本以及标签未知的样本。参赛者应该利用这段时间内已有的数据,提出自己的解决方案,以预测标签未知的样本是否为作弊样本。数据处理方法和算法不限,但是参赛者需要综合考虑算法的效果和复杂度,从而构建合理的解决方案。
赛题数据:本次比赛给出的数据是T~T+N 时刻内点赞、关注事件下按比例抽样数据以及其对应账号的基础特征数据。
评价指标:本赛题使用F1-score来评估模型的准召程度
首先明确本赛题实质上仍然是一个二分类的问题,我们也可以完全从此角度出来先构建出一个基础分类模型,然后再利用大量无标签的数据进行半监督学习来提升模型性能。
风险识别:第二名源代码 https://github.com/Ljwccc/ByteDanceSecurityAI
- 用户侧特征:
- 账户本身的基础特征
- 账户本身的特征计数统计
- 粉丝量、关注量、发帖量、被点赞量、最后登陆时间-注册时间 乘除交叉
- 从请求数据中提取出来的device_type, app_version, app_channel类别特征,直接作为静态画像使用
- 类别特征下的数值统计特征 min/sum/max/std
- 请求侧特征:
- 用户请求的时间序列特征, 时间差序列特征 min/sum/max/std
- w2v特征, 每个用户的请求ip序列建模
从序列特征中提取用户的设备信息、channel信息和app_version信息
1 | # 先 group |
类别特征
1 | # 类别特征 |
点赞量,关注量等交叉特征,直接梭哈所有乘除法
1 | num_cols = ['user_fans_num','user_follow_num','user_post_num','user_post_like_num'] |
类别特征下粉丝量、关注量、发帖量、被点赞量、请求数量的统计值
1 | num_cols = ['user_fans_num','user_follow_num','user_post_num','user_post_like_num'] |
用户请求序列特征
1 | user_request_list = user_request.groupby(['request_user'],as_index=False)['request_target'].agg({'request_list':list}) |
用户请求序列做一个embedding
1 | sentences = user_request_list['request_list'].values.tolist() |
合并基础特征和序列特征
1 | user_info = user_info.merge(user_action_feat,how='left',on='user') |
1 | folds = KFold(n_splits=10, shuffle=True, random_state=546789) |
1 | useless_cols = ['user','user_status'] |
随着在线社交网络的广泛普及,近年来用户数量也呈指数级增长。与此同时,社交机器人,即由程序控制的账户,也在上升。OSN的服务提供商经常使用它们来保持社交网络的活跃。与此同时,一些社交机器人也出于恶意目的注册。有必要检测这些恶意社交机器人,以呈现真实的舆论环境。我们提出了BotFinder,一个在OSN中检测恶意社交机器人的框架。具体来说,它将机器学习和图方法相结合,以便有效地提取社交机器人的潜在特征。关于特征工程,我们生成二阶特征,并使用编码方法对具有高基数的变量进行编码。这些特征充分利用了标记和未标记的样本。对于图,我们首先通过嵌入方法生成节点向量,然后进一步计算人类和机器人向量之间的相似性;然后,我们使用无监督的方法扩散标签,从而再次提高性能。为了验证该方法的性能,我们在由800多万条用户记录组成的人工竞赛提供的数据集上进行了广泛的实验。结果表明,我们的方法达到了0.8850的F1分数,这比最先进的方法要好得多
与报纸等传统媒体相比。社交机器人,即由程序控制的帐户,可用于保持社交网络的活跃。虽然OSN中存在有益的社交机器人,但一些恶意社交机器人的出现会产生有害影响。例如,一些人可以出于各种目的注册大量帐户,例如增加粉丝数量或恶意喜欢。这些恶意行为已成为威胁社交网络平台健康发展的重要信息安全问题[1-2]。因此,有必要检测那些恶意的社交机器人,也称为社交机器人检测。特别是,当前的大多数研究涉及Twitter和其他国外平台,而很少有研究调查中国的OSN。因此,众多学者致力于研究社交机器人的检测问题。当前与社交机器人检测相关的工作主要分为两类,即机器学习方法和基于图的方法。然而,这一主题仍然存在一些挑战:
1) 一般来说,大多数方法依赖于单个算法来识别社交机器人,由于数据集的多样性,这可能不是理想的选择。
2) 实际上,大多数数据都是未标记的,这表明标签的数量通常很小。因此,有效利用未标记数据是一个巨大的挑战。
为了应对上述挑战,我们在此共同考虑用户的配置文件、行为以及它们之间的关系。此外,我们将特征工程和图方法相结合,提出了一种检测社交机器人的集成机制BotFinder。首先,在数据集上进行特征工程以提取全局信息。然后,通过嵌入方法生成节点向量。然后,我们计算人类和机器人的向量之间的相似性。最后,为了进一步提高性能,我们采用了无监督方法(这里考虑了社区检测算法)。使用所提出的算法,我们可以轻松地检测这些机器帐户。
本文的贡献总结如下:
1) 首先,在节点数较多、边数较少的情况下,在绘制过程中可能会忽略一些单个节点。然而,机器学习方法无法学习拓扑结构。因此,我们结合机器学习方法和图方法来克服这些问题。
2) 其次,在特征工程中,我们试图获得二阶特征,并采用编码方法对具有高基数的变量进行编码,或者换句话说,包含大量不同值的变量进行编码。对于图,我们通过嵌入方法生成节点向量。然后,我们利用无监督方法扩散标签以提高性能。这些方法充分利用了标记和未标记的样本。
本文的其余部分组织如下。在第二节中,我们回顾了一些相关的工作。在第3节中,我们介绍了拟议的框架BotFinder。然后,在第4节中,我们详细描述了所研究的数据集,并在充分分析的基础上进行了实验。最后,我们在第5节总结了我们的研究。
在机器学习方法中,监督学习方法得到了广泛的研究。早期的反作弊算法仅利用用户配置文件或用户行为来构建模型。Breno等人[3]提出了一种使用人工神经网络进行数据预处理和挖掘的方法。Chang等人[4]提出了一种特征选择方法,然后使用决策树来检测机器人。Ganji等人[5]将K-最近邻(KNN)应用于信用卡欺诈检测。Ferrara等人[6-7]利用机器学习和认知行为建模技术分析了2017年法国总统选举和2017年加泰罗尼亚独立公投中的社交机器人。Denis等人[8]提出了一种用于检测Twitter上机器人的集成学习方法。 随着深度学习方法(LSTM、CNN等)的发展,研究人员也尝试开发新的方法来检测社交机器人,以进一步提高检测精度。通过将用户内容视为时间文本数据,Cai等人[9]提出了BeDM方法用于机器人检测。Kudugunta等人[10]提取了用户元数据和推文文本,这些数据被视为LSTM深度网络的输入。在实践中,大多数真实世界的数据都是未标记的,而无监督学习方法被广泛研究,这通常依赖于社交机器人的共同特征。Cresci等人[11-12]提出了一种基于DNA启发技术的改进方法,以模拟在线用户行为。陈等人[13]提出了一种无监督的方法来实时检测推特垃圾邮件活动。姜等人[14]提出了CATCHSYNC,仅使用没有标签的拓扑来检测可疑节点。Su等人[15]提出了物联网RU。Mazza等人[16]将转发的时间序列转换为特征向量,然后进行聚类。
机器学习方法只考虑节点的特征。然而,节点之间的关系也包含有价值和有用的信息。随着深度学习和图算法的发展,需要考虑图的拓扑信息以进一步改进。社交机器人具有图形聚合的特点。而社区检测用于发现网络中的社区结构,也可以看作是一种广义聚类算法。因此,社区检测算法可能适用于检测社交机器人。许多研究者对这一课题进行了不懈的研究。Guillaume等人[17]提出了一种基于模块化优化的启发式方法。李等人[18]提出了基于深度稀疏自动编码器的WCD算法。对于特征丰富的样本,很难充分挖掘特征中存在的信息。然后,提出了新的方法,首先将节点的拓扑信息转换为特征向量,然后使用机器学习算法进行训练和推理。例如,Lerer等人[19]提出的Pytorch BigGraph,Yu等人[20]提出的NetWalk,Grover等人[21]提出的Node2Vec,Pham等人[22]提出的Bot2Vec。此外,Kipf等人[23]提出了图卷积网络(GCN),对节点和网络拓扑的特征进行建模,Aljohani等人[24]将GCN应用于检测Twitter上的机器人。李等人[25]提出了用于网络免疫的BPD-DMP算法。聂等人[26]考虑了社交网络和发布内容;然后,他们提出了DCIM算法。高等人[27]对动态行为进行了表征,并提出了一种基于网络的模型。朱等人[28]研究了流行病在多层网络上的传播过程。Su等人[29]提出了检测车载网络中恶意节点的IDE。 大多数方法依赖于单个算法来识别社交机器人。在准确性和其他相关评估指标方面,以前的识别方法仍然有很大的局限性。
在本节中,我们主要介绍BotFinder,它主要包括三个步骤:1)我们在表格数据上表示特征工程技术;2) 我们推导节点嵌入,然后测量人类和机器人之间的相似性;3) 我们应用社区检测算法来进一步提高性能

图1详细说明了这些步骤。第一步,利用特征工程技术生成特征矩阵。第二步,我们使用图嵌入方法生成相似矩阵,然后合并这两个矩阵。然后,我们采用LightGBM[30]来训练合并矩阵并推断临时结果。第三步,我们应用社区检测方法生成部分结果,并使用这些结果校正LightGBM的结果。
在这里,我们试图获得二阶特征、时间间隔特征、计数编码和k倍目标编码。然后,我们应用LightGBM来训练获得的特征并推断临时结果。
二阶特征:为了表示表中分类变量的组合,我们假设二阶特征表示为 COUNT、NUNIQUE、RATIO
COUNT 反映了活动程度。具体来说,我们选择一对变量(即 V1和 V2),并预计记录这对变量在数据集中出现的次数。我们将其缩写为 COUNT(v1, v2)。例如,用户向使用设备类型( V1)iPhone12,1和应用程序版本( V2)126.7.0组合的人thump-up,这种组合在数据集中出现了k次。然后,使用iPhone12、1和126.7.0的用户将获得k的 COUNT值。【记录元组出现的次数】【并行化】
UNIQUE表明了给定范围内的多样性。我们使用一个变量( V1)作为主键,并在另一个变量(V2)中记录唯一类别的数量。我们将其缩写为 UNIQUE(V1)[V2] 。例如,对于使用device type( V1)iPhone12,1的用户,数据集中有k个不同的应用程序版本。然后,使用iPhone12,1的用户将获得 UNIQUE 值k。
RATIO描述计数比例。它计算为 COUNT(v1, v2) / COUNT(v1)。例如,device type(V1)iPhone12,1 和 app version( V2)126.7.0的组合在数据集中出现k次,device type(V1)iPhone12在数据集中出现V次。然后,所有使用iPhone12、1和126.7.0的用户将获得 k/v 的 RATIO 值。
时间间隔特性:请求时间间隔因用户而异。这里,我们主要考虑时间间隔的最大值、最小值、中值和和。
计数编码:计数编码是通过将类别替换为在数据集上计算的类别计数来进行的。然而,某些变量的计数可能相同,这可能导致两个类别可能编码为相同值的冲突。这将导致模型性能下降。因此,我们在此介绍一种目标编码技术。
K-折叠目标编码(或似然编码、影响编码、平均编码):目标编码是通过目标(标签)对分类变量进行计数。在这里,我们用目标的相应概率替换分类变量的每一类。为了减少目标泄漏,我们采用k倍目标编码。具体实现如下:
在这里,我们采用Node2vec[21]来获得用户的节点嵌入(向量),然后计算用户和标记用户之间嵌入的余弦相似性。相似度值表示两个用户具有相同标签的概率;例如,如果user1和user2之间的余弦相似性相对较大,则它们很可能具有高概率的相同标签。
然后,对于训练集和测试集中的每个节点向量C,我们计算机器人和人类之间的最大和平均余弦相似度,该相似度表示为一个向量。【Smax1、Smean1,Smax0,Smean0】

对于社区检测,我们采用典型的Louvain方法[17],将构建的图划分为社区。之后,我们将用以下规则标记社区:
[1] Guillaume L. Fast unfolding of communities in large networks[J]. Journal Statistical Mechanics: Theory and Experiment, 2008, 10: P1008.
1) 如果具有标签的用户属于同一社区,则社区中的所有用户都应该具有相同的标签。
2) 如果社区中的用户没有任何标签,或者用户具有不同的标签,我们将不会进行预测。
然而,预测可能不会覆盖所有用户。因此,该规则的性能是有限的。但该规则的结果比LightGBM更准确。通过将上述两个步骤结合起来,可以进一步提高性能。
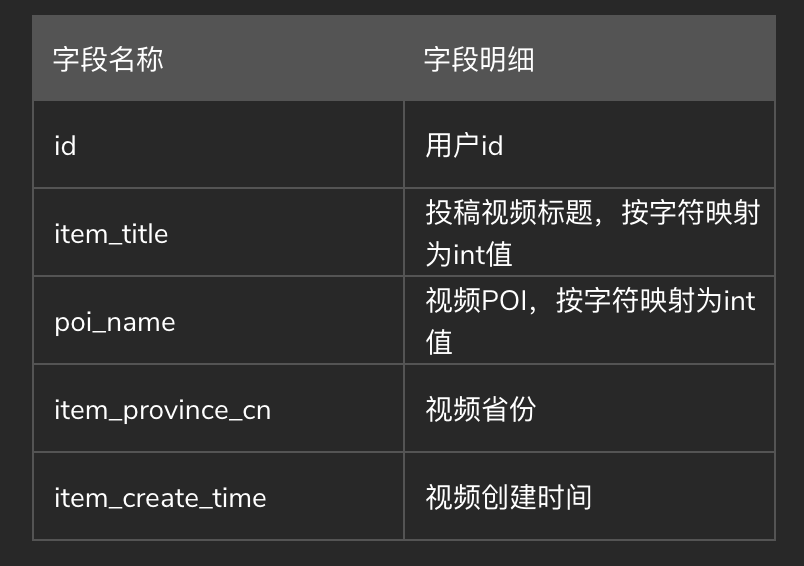
为了评估该机制的性能,我们从一个大型社交网络平台的数据中心收集了一个数据集(https://security.bytedance.com/fe/ai-challenge#/sec-project?id=2&active=1)。它包含超过800万条记录,包括用户配置文件和用户请求(关注或喜欢某人)。数据集的基本信息如表1和表2所示:表1显示了用户的个人信息(配置文件),而表2说明了用户的行为(请求),包括当时用于启动请求的设备和应用程序版本。
任务描述如下:给定用户配置文件及其请求。只有一小部分用户被标记。因此,我们必须建立一个合理、解释性和有效的模型来检测来自用户的恶意机器人。
本文提出了一种社交机器人检测方法BotFinder。为了验证所开发方法的性能,我们收集了一个包含800多万条用户记录的数据集。同时,应用机器学习和图方法从此类数据集中提取社交机器人的潜在特征。特别是,对于特征工程,我们生成二阶特征,并使用编码方法对高基数变量进行编码。在图方面,我们为账户生成节点向量,然后利用无监督方法(这里我们利用社区检测)扩散标签,以进一步提高性能。通过在收集的数据集上进行的实验,所提出的集成机制的有效性得到了相对较大的F1分数0.8850的保证。与现有方法相比,该方法的性能优越。