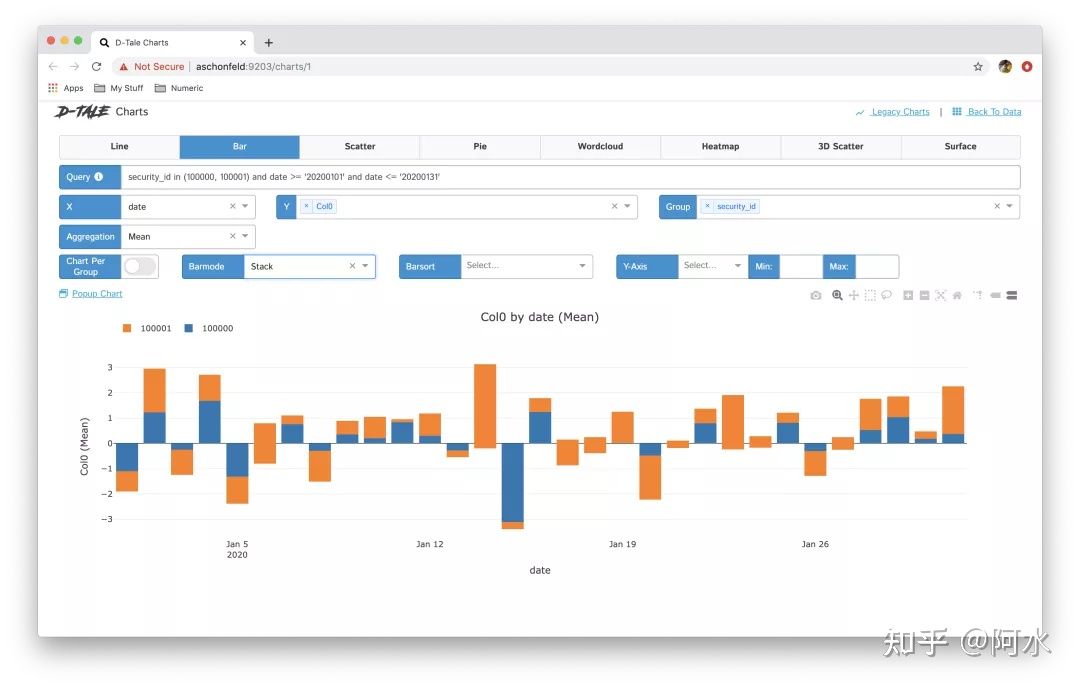
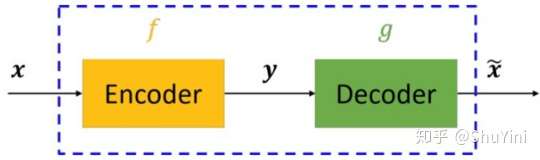
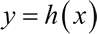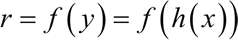那只是过去,阿笠博士在做这个 Voice Conversion
的时候啊,我们需要成对的声音讯号,也就是假设你要把 A 的声音转成 B
的声音,你必须把 A 跟 B 都找来,叫他唸一模一样的句子。
就 A 说好 How are you,B 也说好 How are you,A 说 Good morning,B 也说
Good morning,他们两个各说一样的句子,说个 1000 句,接下来呢,就结束了,就是
Supervised Learning 的问题啊,你有成对的资料,Train 一个
Supervised 的 Model,把 A 的声音丢进去,输出就变成 B 的声音,就结束了。
但是如果 A 跟 B 都需要唸一模一样的句子,念个 500 1000
句,显然是不切实际的,举例来说,假设我想要把我的声音转成新垣结衣的声音,我得把新垣结衣找来,更退一万步说,假设我真的把新垣结衣找来,她也不会说中文啊,所以她没有办法跟我唸一模一样的句子
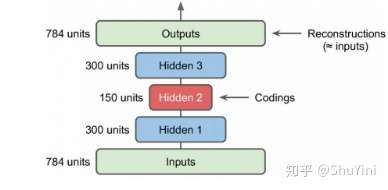
而今天有了 Feature Disentangle
的技术以后,也许我们期待机器可以做到,就给它 A 的声音 给它 B
的声音,A 跟 B
不需要唸同样的句子,甚至不需要讲同样的语言,机器也有可能学会把 A
的声音转成 B 的声音
接下来呢,就把我的声音的前 50
维,代表内容的部分取出来,把你老婆的,把你老婆的声音丢进 Encoder 以后,后 50
维的部分抽出来,拼起来,一样是一个 100 维的向量,丢到 Decoder
里面,看看输出来的声音,是不是就是你老婆叫你念博班的声音,听起来像是这个样子,Do
you want to study a PhD
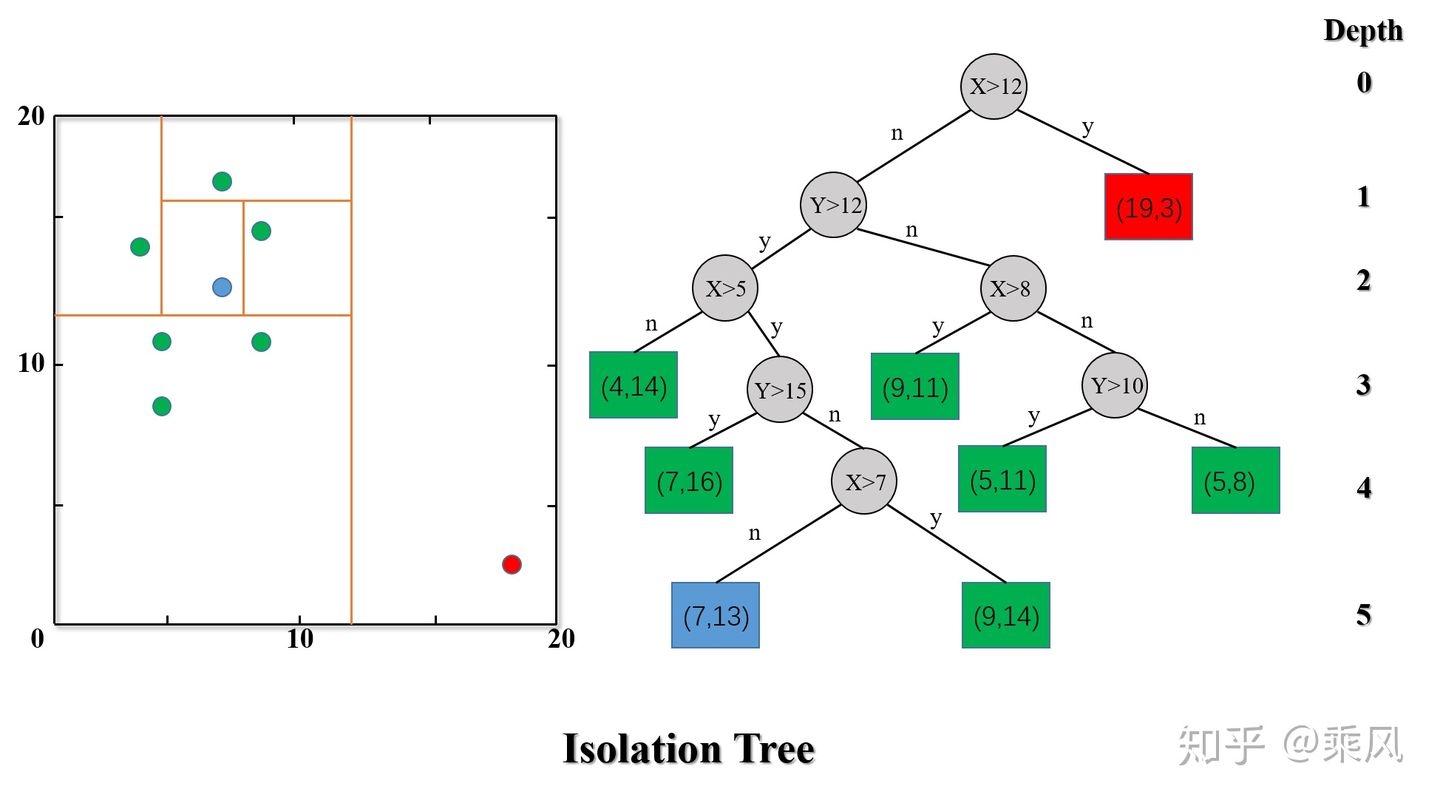
我们往往假设,我们有一大堆正常的资料,但我们几乎没有异常的资料,所以它不是一个一般的分类的问题,这种分类的问题又叫做
==One Class
的分类问题==。就是我们只有一个类别的资料,那你怎么训练一个模型,因为你想你要训练一个分类器,你得有两个类别的资料,你才能训练分类器啊,如果只有一个类别的资料,那我们可以训练什么东西,这个时候就是
Aauto-Encoder,可以派得上用场的时候了。
Log2vec: A Heterogeneous Graph Embedding Based Approach for
Detecting Cyber Threats within Enterprise, Fucheng Liu, Yu Wen,
Dongxue Zhang, Xihe Jiang (Chinese Academy of Science),Xinyu Xing (The
Pennsylvania State University),Dan Meng (Chinese Academy of
Science)
POIROT: Aligning Attack Behavior with Kernel Audit Records
for Cyber Threat Hunting, Sadegh M. Milajerdi (UIC),Birhanu
Eshete (University of Michigan-Dearborn),Rigel Gjomemo (UIC),V.N.
Venkatakrishnan (UIC)
Effective and Light-Weight Deobfuscation and Semantic-Aware
Attack Detection for PowerShell Scripts, Zhenyuan LI (Zhejiang
University),Qi Alfred Chen (University of California, Irvine),Chunlin
Xiong (Zhejiang University),Yan Chen (Northwestern University),Tiantian
Zhu (Zhejiang University of Technology),Hai Yang (MagicShield Inc)
MalMax: Multi-Aspect Execution for Automated Dynamic Web
Server Malware Analysis, Abbas Naderi-Afooshteh (University of
Virginia),Yonghwi Kwon (University of Virginia),Jack Davidson
(University of Virginia),Anh Nguyen-Tuong (University of Virginia),Ali
Razmjoo-Qalaei,Mohammad-Reza Zamiri-Gourabi (ZDResearch)
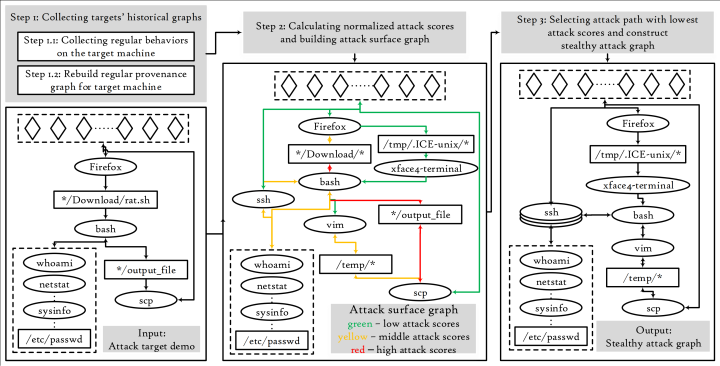
如何设计存储系统以权衡存储空间与查询效率之间的矛盾:如前面所说,高级持续性威胁往往是“low
and
slow”的,攻击的周期可能长达几十天。此外,为了保护系统安全,日志系统往往需要保存很长一段时间内的日志以便事后的取证(Digital
Forensic)分析。因此系统有很强的存储的日志的需求。对一个大公司来说,这可能以为着PB级的存储以及百万美元的开销。因此日志存储系统的设计和针对性的数据压缩算法也是必不可少的。
衰减:利用衰减的思路,安全分析人员通过控制检测点的传播轮数(保留时间),可以有效控制每次需要处理的图的规模,从而大幅度的降低的算法的复杂度。然而攻击者可以通过加长攻击链(增加攻击间隔)来避免被检测。需要注意的是加长攻击需要使得溯源图中节点的距离变大,如下图所示,常规的有核心控制节点的攻击图并不能真正拉长攻击链。这里可以使用的攻击技术报告DLL
side
loading、注册表自启动等等。值得一提的是,基于衰减的压缩方案往往和剪枝的方案共同使用,也意味着双倍的风险。
[1] Anderson B, McGrew D. Identifying encrypted malware traffic with
contextual flow data[C]//Proceedings of the 2016 ACM workshop on
artificial intelligence and security. 2016: 35-46.
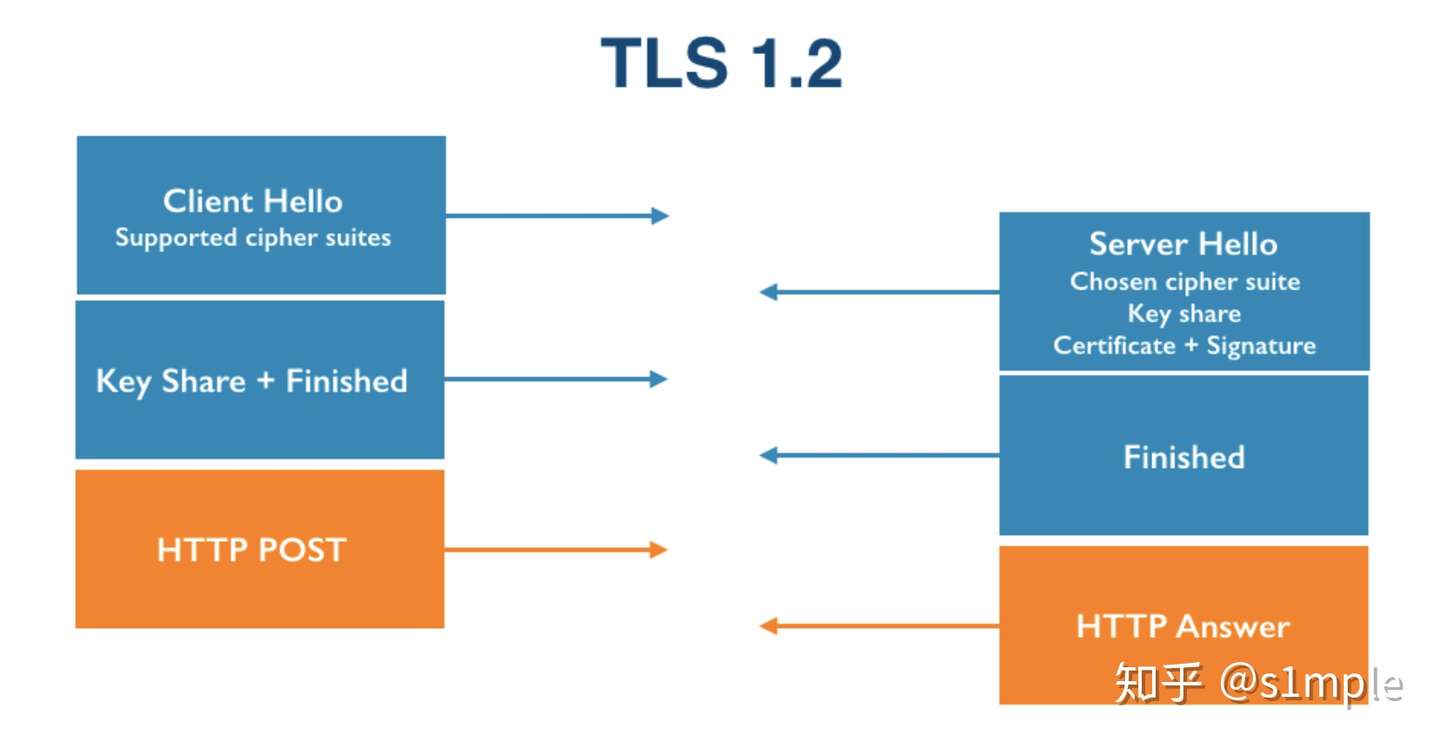
image-20220516100235456
在进行TLS握手时,会进行如下几个步骤:
Client Hello,客户端提供支持的加密套件数组(cipher
suites);
Server
Hello,由服务器端选择一个加密套件,传回服务器端公钥,并进行认证和签名授权(Certificate
+ Signature);
客户端传回客户端公钥(Client Key
Exchange),客户端确立连接;
服务器端确立连接,开始 HTTP 通信。
一、特征提取
1.1 可观察的数据元统计特征
传统流数据 (Flow Meta)
流入和流出的字节数和数据包数
源端口和目的端口
字节分布 (BD, Byte Distribution)
数据包有效负载中遇到的每个字节值的计数
提供了大量数据编码和数据填充的信息
字节分布概率 ≈ 字节分布计数 / 分组有效载荷的总字节数
特征表示:1×256维字节分布概率序列
分组长度和分组到达间隔时间的序列 (SPLT, Sequence of
Packets Length and Times)
单独的看每条流可能漏掉了流之间的关联行为即主机级别的行为,比如恶意软件在发出正常的访问谷歌流量后可能就要开始进行恶意传输。再比如,有少量正常流也会出现自
签名,如果我们单独看流,可能就会误判,但是如果我们基于主机提取特征发现同一
IP
下有多条流都是自签名,则我们就会有很大的信心认为这是恶意的。因此,我们将上一小节中流级别
的特征进行聚合,并以流为基本单位提取主机级别特征。
原文作者:Frederick Barr-Smith, Xabier Ugarte-Pedrero, et al.
原文标题:Survivalism: Systematic Analysis of Windows
Malware Living-Off-The-Land
原文链接:https://ieeexplore.ieee.org/document/9519480
发表会议:2021 IEEE Symposium on Security and Privacy
(SP)
文章目录:
摘要
一.引言
1.什么是离地攻击
2.APT中的离地攻击
3.提出五个关键问题
4.贡献(Contribution)
二.背景和相关工作
A.LotL Binaries
B.Scope of our Study
C.Related Work
三.MOTIVATION: 杀毒软件产品 vs
离地攻击技术
四.离地攻击流行性评估
A.Dataset Composition
B.Analysis Pipeline
C.LotL Technique Identification
D.Parameter Analysis to Identify Execution Purpose
问题5:What are the overlaps and differences in the behavior
of legitimate and malicious binaries with respect to the usage of LotL
binaries? How would this affect detection by heuristic AV
engines?
In this paper, we define a LotL binary as any binary with a
recognised legitimate use, that is leveraged during an attack to
directly perform a malicious action; or to assist indirectly, in a
sequence of actions that have a final malicious outcome.
==W. U. Hassan, A. Bates, and D. Marino, “Tactical
Provenance Analysis for Endpoint Detection and Response Systems,” IEEE
Symposium on Security and Privacy, 2020.==