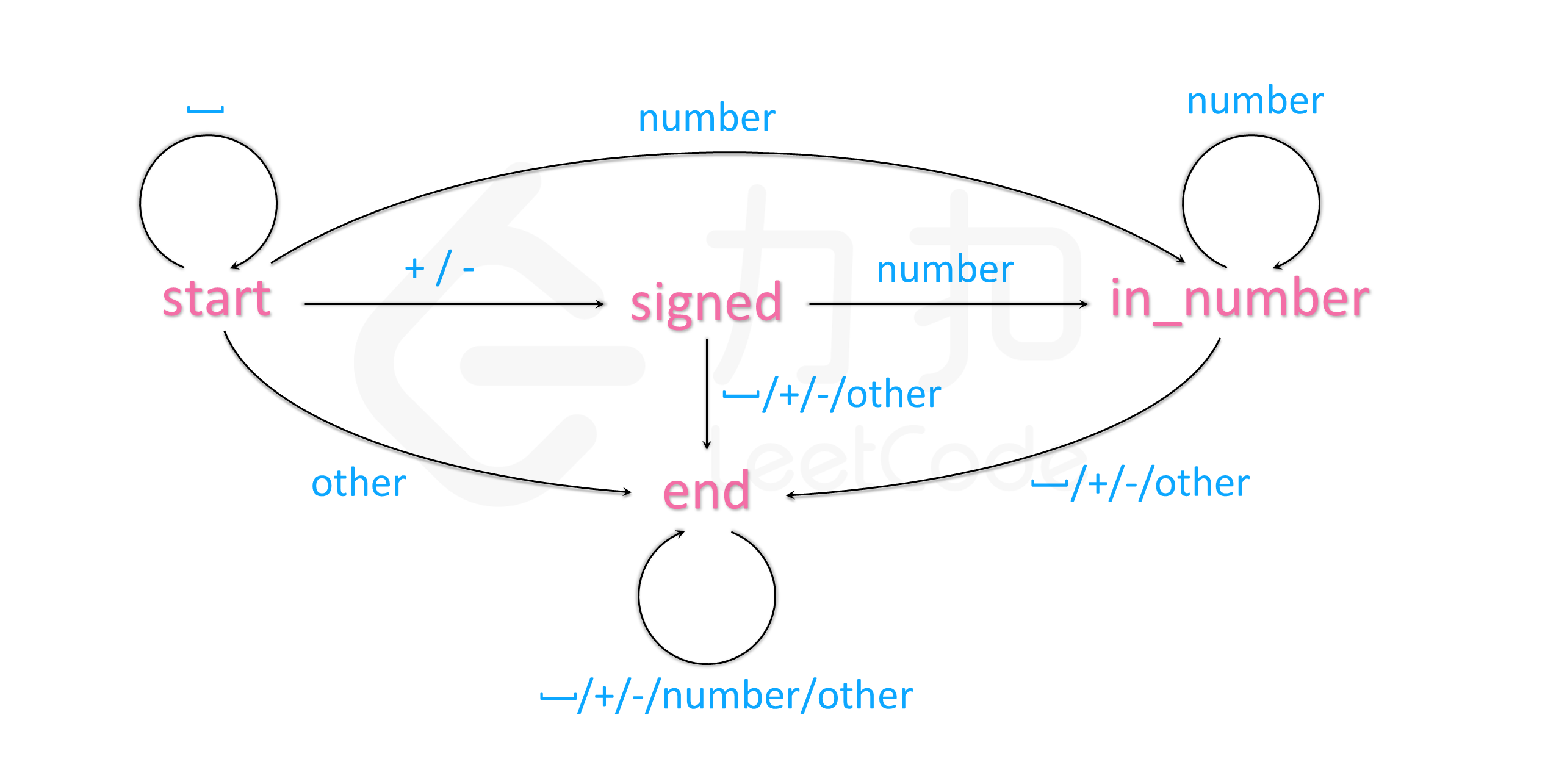
defisAlienSorted(self, words: List[str], order: str) -> bool: index = {c: i for i, c inenumerate(order)} returnall(s <= t for s, t in pairwise([index[c] for c in word] for word in words))
classSolution: defreverseLeftWords(self, s: str, n: int) -> str: return s[n:] + s[:n] defreverseLeftWords(self, s: str, n: int) -> str: # 列表遍历拼接 res = [] for i inrange(n, len(s)): res.append(s[i]) for i inrange(n): res.append(s[i]) return''.join(res) defreverseLeftWords(self, s: str, n: int) -> str: # 字符串遍历拼接 res = ""# 字符为不可变对象,每轮都新建 for i inrange(n, len(s)): res += s[i] for i inrange(n): res += s[i] return res
classSolution: defminWindow(self, s: str, t: str) -> str: s_len, t_len = len(s), len(t) if s_len < t_len: return"" # 0 不删除 sdict, tdict = defaultdict(int), Counter(t) left, conut = 0, 0 res = "" for i inrange(s_len): sdict[s[i]] += 1 if sdict[s[i]] <= tdict[s[i]]: conut += 1 while left <= i and sdict[s[left]] > tdict[s[left]]: # 加一个A就减一个A...(无用后缀) sdict[s[left]] -= 1 left += 1 if conut == t_len: ifnot res or (i - left + 1 < len(res)): res = s[left:i + 1] return res
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defisPalindrome(self, s: str) -> bool: n = len(s) left, right = 0, n - 1 while left < right: while left < right andnot s[left].isalnum(): left += 1 while left < right andnot s[right].isalnum(): right -= 1 if left < right: if s[left].lower() != s[right].lower(): returnFalse left, right = left + 1, right - 1 returnTrue
给定一个非空字符串 s,请判断如果 最多
从字符串中删除一个字符能否得到一个回文字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: defvalidPalindrome(self, s: str) -> bool: # 回溯, 广度优先 【字符串长度,暴搜必定超时】 defcheckPalind(l, r): while l < r: if s[l] != s[r]: returnFalse l += 1 r -= 1 returnTrue n = len(s) left, right = 0, n - 1 while left < right: if s[left] == s[right]: left += 1 right -= 1 else: return checkPalind(left + 1, right) or checkPalind(left, right - 1) returnTrue
给定一个字符串 s
,请计算这个字符串中有多少个回文子字符串。具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
classSolution: defcountSubstrings(self, s: str) -> int: # 双指针+中心扩散 result = 0 def_extend(s, i, j, n): res = 0 while i >= 0and j < n and s[i] == s[j]: # 确定中心点 i -= 1 j += 1 res += 1# 扩散过程也是答案 return res for i inrange(len(s)): result += _extend(s, i, i, len(s)) #以i为中心 result += _extend(s, i, i+1, len(s)) #以i和i+1为中心 return result
defcountSubstrings(self, s: str) -> int: # 动态规划 dp[i][j]: s[i:j] 是否为回文子串 # dp[i+1][j-1] -> dp[i][j] 遍历顺序 n = len(s) dp = [[False] * (n) for _ inrange(n)] ans = 0 for i inrange(n-1,-1,-1): for j inrange(i,n): if s[i] == s[j]: if j - i <= 1: ans += 1 dp[i][j] = True elif dp[i+1][j-1]: ans += 1 dp[i][j] = True return ans
defleftMargin(): # 左边界 left, right = 0, len(nums) - 1 while left <= right: mid = (left + right) // 2 if nums[mid] < target: # ... Ture # False ... left = mid + 1 else: right = mid - 1 return left if nums[left] == target else -1# 越界检验
二分查找右边界 [第一个 True ]
1 2 3 4 5 6 7 8 9
defrightMargin(): # 右边界 left, right = 0, len(nums) - 1 while left <= right: mid = (left + right) // 2 if nums[mid] > target: # ... False # Ture ... right = mid - 1 else: left = mid + 1 return right if nums[right] == target else -1
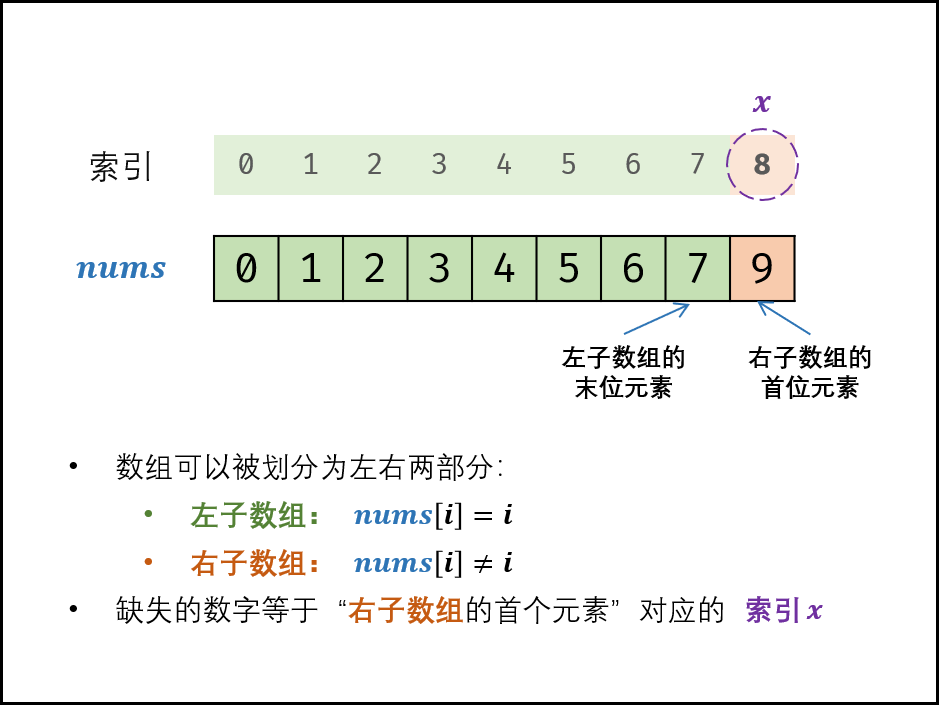
找出数组中重复的数字。==在一个长度为 n
的数组 nums 里的所有数字都在 0~n-1
的范围内==。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
哈希表 / Set、原地交换(空间0(1))
合理利用 val 和 key 的关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: deffindRepeatNumber(self, nums: [int]) -> int: dic = set() for num in nums: if num in dic: return num dic.add(num) return -1 deffindRepeatNumber(self, nums: [int]) -> int: i = 0 while i < len(nums): if nums[i] == i: i += 1 continue if nums[nums[i]] == nums[i]: return nums[i] nums[nums[i]], nums[i] = nums[i], nums[nums[i]] return -1
统计一个数字在排序数组中出现的次数。
找到目标值「最后」出现的分割点,并「往前」进行统计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defsearch(self, nums: List[int], target: int) -> int: left, right = 0, len(nums) - 1 # 求右边界 while left <= right: mid = (right + left) // 2 if nums[mid] > target: right = mid - 1 else: left = mid + 1 # 最后要检查 right 越界的情况 if right < 0or nums[right] != target: return0 ans = 0 while right >= 0and nums[right] == target : right -= 1 ans += 1 return ans
classSolution: defmissingNumber(self, nums: List[int]) -> int: i, j = 0, len(nums) - 1 while i <= j: m = (i + j) // 2 if nums[m] == m: i = m + 1 else: j = m - 1 return i
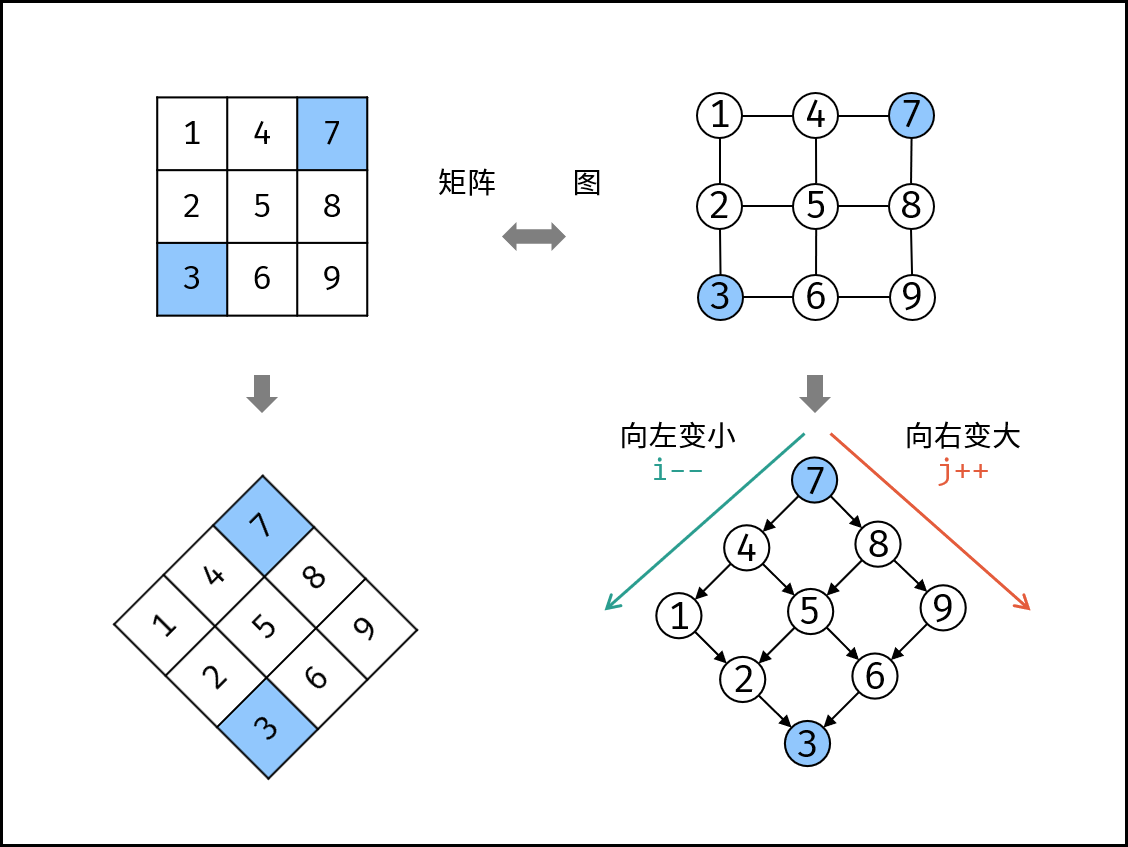
在一个 n * m
的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
我们将矩阵逆时针旋转 45° ,并将其转化为图形式,发现其类似于
二叉搜索树
1 2 3 4 5 6 7 8 9 10 11
classSolution: deffindNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool: i, j = len(matrix) - 1, 0 while i >= 0and j < len(matrix[0]): if matrix[i][j] > target: i -= 1 elif matrix[i][j] < target: j += 1 else: returnTrue returnFalse
classSolution: defthreeSum(self, nums: List[int]) -> List[List[int]]: # 排序 + 双指针 + 去冲 n = len(nums) nums.sort() ans = [] for i inrange(n): if nums[i] > 0: # 剪枝加速 break if i > 0and nums[i] == nums[i-1]: continue left, right = i + 1, n - 1 while left < right: cur = nums[i] + nums[left] + nums[right] if cur == 0: ans.append([nums[i], nums[left], nums[right]]) while left < right and nums[right] == nums[right - 1]: right -= 1 right -= 1 while left < right and nums[left] == nums[left + 1]: left += 1 left += 1 elif cur > 0: right -= 1 else: left += 1 return ans
classSolution: defminSubArrayLen(self, target: int, nums: List[int]) -> int: # 【前缀和 + 二分查找 o(nlogn)】 ifsum(nums) < target: return0 n = len(nums) pre = list(accumulate([0] + nums)) # itertools.accumulate() ans = n + 1 for i inrange(n + 1): cur = target + pre[i] """ left = bisect.bisect_left(pre, cur) """ left = i + 1 right = n while left <= right: mid = (left + right) // 2 if pre[mid] < cur: left = mid + 1 else: right = mid - 1 if left != n+1: ans = min(ans, left - i) return ans defminSubArrayLen(self, target: int, nums: List[int]) -> int: ifsum(nums) < target: return0 cur, res = 0, len(nums) + 1 i = 0 for j, var inenumerate(nums): cur += var while i <= j and cur >= target: if (t:= j - i + 1) < res: res = t cur -= nums[i] i += 1 return res
classSolution: defnumSubarrayProductLessThanK(self, nums: List[int], k: int) -> int: # 前缀和单调 + 二分查找 if k == 0: return0 k = math.log(k) pre = [0] for num in nums: pre.append(pre[-1] + math.log(num)) cur = res = 0 for i inrange(1, len(pre)): cur = k + pre[i - 1] j = bisect.bisect_left(pre, cur, lo = i) res += j - i return res defnumSubarrayProductLessThanK(self, nums: List[int], k: int) -> int: # 滑动窗口 n = len(nums) left, right = 0, n - 1 res = 0 i, cur =0, 1 for j, num inenumerate(nums): cur *= num while i <= j and cur >= k: # 左跟着右 cur //= nums[i] i += 1 res += j - i + 1 return res
狒狒喜欢吃香蕉。这里有 n 堆香蕉,第 i 堆中有 piles[i]
根香蕉。警卫已经离开了,将在 h
小时后回来。狒狒可以决定她吃香蕉的速度 k
(单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 k
根。如果这堆香蕉少于 k
根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉,下一个小时才会开始吃另一堆的香蕉。返回她可以在
h 小时内吃掉所有香蕉的最小速度 k(k 为整数)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defminEatingSpeed(self, piles: List[int], h: int) -> int: left, right = max(1, sum(piles) // h), max(piles) defcheck(k): count = 0 for pile in piles: count += ceil(pile / k) return count > h while left <= right: mid = (left + right) // 2 if check(mid): # ... Ture # False(r) ... left = mid + 1 else: right = mid - 1 return left
给你一个 n x n 矩阵 matrix
,其中每行和每列元素均按升序排序,找到矩阵中第
k 小的元素。 请注意,它是 排序后 的第 k 小元素,而不是第 k 个
不同 的元素。
classSolution: defkthSmallest(self, matrix: List[List[int]], k: int) -> int: # 优先队列 n = len(matrix) heap = [(matrix[i][0], i, 0) for i inrange(n)] heapq.heapify(heap) res = 0 for i inrange(k - 1): num, x, y = heapq.heappop(heap) if y != n - 1: heapq.heappush(heap, (matrix[x][y + 1], x, y + 1)) return heap[0][0] defkthSmallest(self, matrix: List[List[int]], k: int) -> int: # 二分查找 n = len(matrix) defcheck(mid): i, j = n - 1, 0 num = 0 while i >= 0and j < n: if matrix[i][j] <= mid: num += i + 1 j += 1 else: i -= 1 return num < k # 【第一个False】 left, right = matrix[0][0], matrix[-1][-1] while left <= right: mid = (left + right) // 2 if check(mid): left = mid + 1 else: right = mid - 1 return left
classSolution: defprintNumbers(self, n: int) -> List[int]: defdfs(index, num, digit): if index == digit: res.append(int(''.join(num))) return for i inrange(10): num.append(str(i)) dfs(index + 1, num, digit) num.pop() res = [] for digit inrange(1, n + 1): for first inrange(1, 10): num = [str(first)] dfs(1, num, digit) return res
给你一个整数数组 nums 和一个整数 k
,请你统计并返回 该数组中和为 k
的==子数组==的个数 。
-1000 <= nums[i] <= 1000
前缀和 + 哈希表优化
1 2 3 4 5 6 7 8 9 10
classSolution: defsubarraySum(self, nums: List[int], k: int) -> int: dic = collections.defaultdict(int) dic[0] = 1 res = preNum = 0 for i inrange(len(nums)): preNum += nums[i] res += dic[preNum - k] dic[preNum] += 1 return res
classSolution: defreverseList(self, head: ListNode) -> ListNode: # 迭代 cur, pre = head, None while cur: tmp = cur.next# 暂存后继节点 cur.next cur.next = pre # 修改 next 引用指向 pre = cur # pre 暂存 cur cur = tmp # cur 访问下一节点 return pre defreverseList(self, head: ListNode) -> ListNode: # 递归 defrecur(cur, pre): ifnot cur: return pre # 终止条件 res = recur(cur.next, cur) # 递归后继节点 cur.next = pre # 修改节点引用指向 return res # 返回反转链表的头节点 return recur(head, None) # 调用递归并返回
请实现 copyRandomList
函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next
指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者
null。
defaultdict(),空为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defcopyRandomList(self, head: 'Node') -> 'Node': # 拼接+拆分 【哈希表】 ifnot head: return head dic = collections.defaultdict() cur = head while cur: dic[cur] = Node(cur.val) cur = cur.next cur = head while cur: dic[cur].next = dic[cur.next] if cur.nextelseNone dic[cur].random = dic[cur.random] if cur.random elseNone# keyerror cur = cur.next return dic[head]
给定一个链表,删除链表的倒数第 n
个结点,并且返回链表的头结点。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defremoveNthFromEnd(self, head: ListNode, n: int) -> ListNode: dummy = ListNode(0, head) first = head second = dummy for i inrange(n): first = first.next while first: first = first.next second = second.next second.next = second.next.next return dummy.next
给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着
next 指针进入环的第一个节点为环的入口节点。如果链表无环,则返回
null。
classSolution: defdetectCycle(self, head: ListNode) -> ListNode: fast = slow = head while fast and fast.next: fast = fast.next.next slow = slow.next if fast == slow: fast = head while fast != slow: fast = fast.next slow = slow.next return slow returnNone
classSolution: defaddTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode: defreverseList(head: ListNode) -> ListNode: ifnot head: return head pre, cur = None, head while cur: tmp = cur.next cur.next = pre pre = cur cur = tmp return pre
ifnot l1 andnot l2: return l1 = reverseList(l1) l2 = reverseList(l2) more = 0 p = None while l1 or l2: # 倒序添加 val1 = l1.val if l1 else0 val2 = l2.val if l2 else0 total = val1 + val2 + more more, cur = divmod(total, 10) p = ListNode(cur, p) l1 = l1.nextif l1 else l1 l2 = l2.nextif l2 else l2 if more != 0: p = ListNode(more, p) return p
classSolution: defreorderList(self, head: ListNode) -> None: """ Do not return anything, modify head in-place instead. """ defreverseList(head: ListNode) -> ListNode: pre, cur = None, head while cur: tmp = cur.next cur.next = pre pre = cur cur = tmp return pre fast, slow = head.next, head while fast and fast.next: slow, fast = slow.next, fast.next.next mid, slow.next = slow.next, None left, cur = head, reverseList(mid) slow.next = None while cur: tmp = cur.next cur.next = left.next left.next = cur left = cur.next cur = tmp return head
classSolution: defisPalindrome(self, head: ListNode) -> bool: defreverseList(head: ListNode) -> ListNode: pre, cur = None, head while cur: tmp = cur.next cur.next = pre pre = cur cur = tmp return pre slow = fast = head while fast.nextand fast.next.next: slow, fast = slow.next, fast.next.next left, right = head, slow.next slow.next = None right = reverseList(right) while left and right: if left.val != right.val: returnFalse left, right = left.next, right.next returnTrue
classSolution: defflatten(self, head: 'Node') -> 'Node': # 栈迭代 if head == None: return head dummy = Node(-1, None, None, None) pre = dummy stk = [head] while stk: x = stk.pop() pre.next = x x.prev = pre if x.next: stk.append(x.next) if x.child: stk.append(x.child) x.child = None pre = x dummy.next.prev = None return dummy.next defflatten(self, head: 'Node') -> 'Node': if head == None: return head dummy = Node(-1, None, None, None) defdfs(pre: 'Node', cur: 'Node') -> 'Node': if cur == None: return pre pre.next = cur cur.prev = pre
classUnionFind: # 并查集 def__init__(self, n): self.parent = [i for i inrange(n)] self.count = n deffind(self, x): if self.parent[x] == x: return x self.parent[x] = self.find(self.parent[x]) return self.parent[x] defunion(self, x, y): x, y = self.find(x), self.find(y) if x != y: self.parent[x] = y self.count -= 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defnumSimilarGroups(self, strs: List[str]) -> int: # 相似的字符串 m, n = len(strs), len(strs[0]) un = UnionFind(m) for i inrange(m): for j inrange(i + 1, m): cnt = 0 for k inrange(n): if strs[i][k] != strs[j][k]: cnt += 1 if cnt > 2: break else: # 上下文管理器 un.union(i, j) return un.count