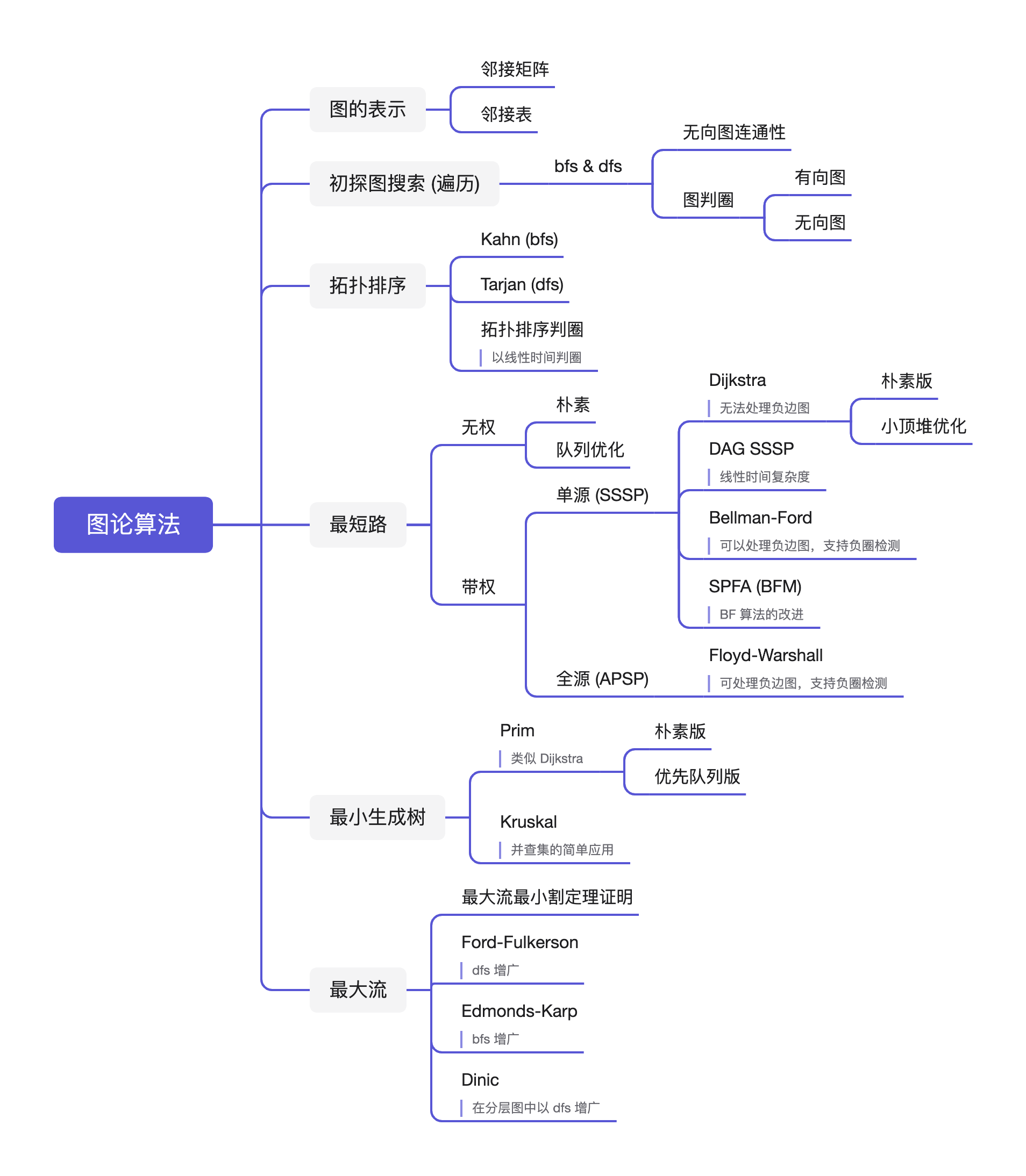
classSolution: defmaxAreaOfIsland(self, grid: List[List[int]]) -> int: # 深度优先搜索 空间复杂度o(m*n) m, n = len(grid), len(grid[0]) res = 0 defdfs(x, y) -> int: s = 1 grid[x][y] = 0 for i, j in [(x - 1, y), (x, y - 1), (x + 1, y), (x, y + 1)]: if i < 0or j < 0or i == m or j == n or grid[i][j]!=1: continue s += dfs(i, j) return s
for i inrange(m): for j inrange(n): if grid[i][j] == 1: res = max(res, dfs(i, j)) return res
有 n 个网络节点,标记为 1 到 n。给你一个列表 times,表示信号经过 有向
边的传递时间。 times[i] = (ui, vi, wi),其中 ui 是源节点,vi
是目标节点, wi 是一个信号从源节点传递到目标节点的时间。
现在,从某个节点 K
发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回
-1 。
classSolution: defnetworkDelayTime(self, times: List[List[int]], n: int, k: int) -> int: g = [[] for _ inrange(n)] for x, y, time in times: g[x - 1].append((y - 1, time))
dist = [float('inf')] * n dist[k - 1] = 0 q = [(0, k - 1)] while q: time, x = heapq.heappop(q) if dist[x] < time: continue for y, time in g[x]: if (d := dist[x] + time) < dist[y]: dist[y] = d heapq.heappush(q, (d, y))
ans = max(dist) return ans if ans < float('inf') else -1
存在一个 无向图 ,图中有 n 个节点。其中每个节点都有一个介于 0 到 n -
1 之间的唯一编号。给定一个二维数组 graph ,表示图,其中 graph[u]
是一个节点数组,由节点 u 的邻接节点组成。形式上,对于 graph[u] 中的每个
v ,都存在一条位于节点 u 和节点 v 之间的无向边。
二分图
定义:如果能将一个图的节点集合分割成两个独立的子集 A 和 B
,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B
集合,就将这个图称为 二分图 。
classSolution: defisBipartite(self, graph: List[List[int]]) -> bool: # 广度优先遍历 [推荐] n = len(graph) uncolor, red, green = 0, 1, 2 color = [0] * n for i inrange(n): if color[i] == uncolor: color[i] = red q = deque([i]) while q: node = q.popleft() nei = green if color[node] == red else red for j in graph[node]: if color[j] == uncolor: color[j] = nei q.append(j) elif color[j] != nei: returnFalse returnTrue defisBipartite(self, graph: List[List[int]]) -> bool: # 深度优先遍历 【不推荐】 defdfs(i: int, c: int): nonlocal res nei = green if c == red else red for j in graph[i]: if color[j] == uncolor: color[j] = nei dfs(j, nei) elif color[j] != nei: res = False
n = len(graph) uncolor, red, green = 0, 1, 2 color = [0] * n res = True for i inrange(n): if color[i] == uncolor and res: dfs(i, red) return res # def isBipartite(self, graph: List[List[int]]) -> bool: # # 并查集 【了解】
classSolution: defexist(self, board: List[List[str]], word: str) -> bool: m = len(board) n = len(board[0]) defdfs(x, y, index): if index == len(word): returnTrue for dx, dy in ((-1, 0), (1, 0), (0, -1), (0, 1)): nx, ny = x + dx, y + dy if0 <= nx < m and0 <= ny < n and board[nx][ny] == word[index]: board[nx][ny] = '/' if dfs(nx, ny, index + 1): returnTrue board[nx][ny] = word[index] returnFalse for i inrange(m): for j inrange(n): if board[i][j] == word[0]: board[i][j] = '/' if dfs(i, j, 1): returnTrue board[i][j] = word[0] returnFalse
defbacktracking(index,path,target): if index >= len(candidates) or target < 0: return if target == 0: # 收集条件 ans.append(path[:]) return for i inrange(index,len(candidates)): # 注意可以重复收集 path.append(candidates[i]) # 做选择 backtracking(i,path,target-candidates[i]) path.pop() # 取消选择 backtracking(0,[],target) return ans
classSolution: defpermuteUnique(self, nums: List[int]) -> List[List[int]]: # visited 记录访问节点的集合 n = len(nums) ans = [] vis = set() defbacktrace(tmp): iflen(tmp) == n: ans.append(tmp[:]) return for i inrange(n): if i in vis: continue if i > 0and nums[i] == nums[i - 1] and i - 1notin vis: # not in 保留顺序剪枝 continue vis.add(i) backtrace(tmp + [nums[i]]) vis.remove(i) nums.sort() backtrace([]) return ans
classSolution: defpartition(self, s: str) -> List[List[str]]: # 动态规划预处理 + 回溯全排列条件 n = len(s) dp = [[False] * n for _ inrange(n)] for i inrange(n): dp[i][i] = True for i inrange(n - 1, -1, -1): for j inrange(i + 1, n): if s[i] == s[j]: if j - i <= 1or dp[i + 1][j - 1]: dp[i][j] = True ans = [] defbacktrace(idx, tmp): if idx == n: ans.append(tmp[:]) return for i inrange(idx, n): if dp[idx][i]: tmp.append(s[idx: i + 1]) backtrace(i + 1, tmp) tmp.pop() backtrace(0, []) return ans
defcountOnes(x: int) -> int: ones = 0 while x > 0: x &= (x - 1) ones += 1 return ones
实现 pow(x,
n) ,即计算 x 的 n
次幂函数(即,xn)。不得使用库函数,同时不需要考虑大数问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defmyPow(self, x: float, n: int) -> float: # 快速幂 if x== 0: return0 res = 1 if n < 0: x, n = 1 / x, -n while n: if n & 1: res *= x x *= x n >>= 1# n // 2 return res
classSolution: defhammingWeight(self, n: int) -> int: res = 0 while n: res += 1 n &= n - 1 return res defhammingWeight(self, n: int) -> int: res = 0 while n: if n&1 == 1: res += 1 n >>= 1 return res
写一个函数,求两个整数之和,要求在函数体内不得使用
“+”、“-”、“*”、“/” 四则运算符号。
1 2 3 4 5 6 7
classSolution: defadd(self, a: int, b: int) -> int: # 无进位和: 异或运算^ 规律相同 # 进位: 与运算& 规律相同(并需左移一位) if b == 0: return a return add(a ^ b, (a & b) << 1)
classSolution: defsingleNumbers(self, nums: List[int]) -> List[int]: ret = functools.reduce(lambda x, y: x ^ y, nums) div = 1 while div & ret == 0: div <<= 1 a, b = 0, 0 for n in nums: if n & div: a ^= n else: b ^= n return [a, b]
classSolution: defsingleNumber(self, nums: List[int]) -> int: counts = [0] * 32 for num in nums: for j inrange(32): counts[j] += num & 1 num >>= 1 res, m = 0, 3 for i inrange(32): res <<= 1 res |= counts[31 - i] % m return res if counts[31] % m == 0else ~(res ^ 0xffffffff)
给定一个非负整数 n ,请计算 0 到
n 之间的每个数字的二进制表示中 1
的个数,并输出一个数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defcountBits(self, n: int) -> List[int]: # o(nlogn) defcountbits(x: int) -> int: ones = 0 while x > 0: x &= (x - 1) ones += 1 return ones return [countbits(i) for i inrange(n + 1)] defcountBits(self, n: int) -> List[int]: bits, high = [0], 0 for i inrange(1, n + 1): if i&(i - 1) == 0: high = i bits.append(bits[i - high] + 1) return bits
classSolution: defminNumber(self, nums: List[int]) -> str: n = len(nums) def_smallA(a, b): returnTrueif a + b < b + a elseFalse defpartition(l, r): pivot = random.randint(l, r) nums[pivot], nums[l] = nums[l], nums[pivot] base = nums[l] i = l for j inrange(l+1, r+1): # r+1 遍历到r if _smallA(nums[j], base): nums[j], nums[i+1] = nums[i+1], nums[j] # i + 1 与i前面的换 i += 1 nums[l], nums[i] = nums[i], nums[l] return i defquick_sort(l, r): if r - l <= 0: return mid = partition(l, r) quick_sort(l, mid - 1) quick_sort(mid + 1, r) nums = [str(num) for num in nums] quick_sort(0, len(nums) - 1) return"".join(nums).lstrip()
内置函数:cmp_to_key,单个元素并没有一个绝对的大小的情况
1 2 3 4 5
classSolution: deflargestNumber(self, nums: List[int]) -> str: nums.sort(key=cmp_to_key(lambda x,y: int(str(y)+str(x)) - int(str(x)+str(y)))) ans = ''.join([str(num) for num in nums]) returnstr(int(ans))
classSolution: defsortList(self, head: Optional[ListNode]) -> Optional[ListNode]: # 时间空间复杂度分别为 O(nlogn) 和 O(1) 【归并排序】 # 【切分数组】 ifnot head ornot head.next: return head slow, fast = head, head.next# 快慢指针【如何】初始化 while fast and fast.next: fast, slow = fast.next.next, slow.next mid, slow.next = slow.next, None# None截断 left, right = self.sortList(head), self.sortList(mid) # 递归 # 【合并链表】 h = dummy = ListNode(0) # 新建节点的合并 while left and right: if left.val < right.val: h.next = left left = left.next else: h.next = right right = right.next h = h.next h.next = left if left else right return dummy.next
classSolution: defmerge(self, intervals: List[List[int]]) -> List[List[int]]: n = len(intervals) intervals.sort(key = lambda x: x[0]) ans = [] ans.append(intervals[0]) for i inrange(1, n): if ans[-1][1] >= intervals[i][0]: if (t := intervals[i][1]) > ans[-1][1]: ans[-1][1] = t else: ans.append(intervals[i]) return ans
classSolution: defrelativeSortArray(self, arr1: List[int], arr2: List[int]) -> List[int]: defcmp(k): return (0, cmpDict[k]) if k in cmpDict else (1, k) cmpDict = {val:i for i, val inenumerate(arr2)} returnsorted(arr1, key = cmp)
defverifyPostorder(self, postorder: [int]) -> bool: # 分治递归 defrecur(i, j): if i >= j: returnTrue p = i while postorder[p] < postorder[j]: p += 1 m = p while postorder[p] > postorder[j]: p += 1 return p == j and recur(i, m - 1) and recur(m, j - 1)
return recur(0, len(postorder) - 1) defverifyPostorder(self, postorder: [int]) -> bool: # 单调队列 stack, root = [], float("+inf") for i inrange(len(postorder) - 1, -1, -1): if postorder[i] > root: returnFalse while(stack and postorder[i] < stack[-1]): root = stack.pop() stack.append(postorder[i]) returnTrue
给定一棵二叉树的根节点 root
,请找出该二叉树中每一层的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution: deflargestValues(self, root: TreeNode) -> List[int]: ifnot root: return [] q = deque([root]) ans = [] while q: k = len(q) tmp = float('-inf') for _ inrange(k): node = q.popleft() if (t:= node.val) > tmp: tmp = t if node.left: q.append(node.left) if node.right: q.append(node.right) ans.append(tmp) return ans
classSolution: deflowestCommonAncestor(self, root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode: ifnot root or root == q or root == p: return root left = self.lowestCommonAncestor(root.left, p, q) right = self.lowestCommonAncestor(root.right, p, q) if left and right: return root return left if left else right
classSolution: defmaxPathSum(self, root: TreeNode) -> int: ans = -inf defpathSum(root): nonlocal ans ifnot root: return0 left = max(pathSum(root.left), 0) right = max(pathSum(root.right), 0) if (t := root.val + left + right) > ans: ans = t return root.val + max(left, right) pathSum(root) return ans
classSolution: deflengthOfLongestSubstring(self, s: str) -> int: # 回溯 + set n = len(s) que = collections.deque() iflen(s) == 0: return0 que.append(s[0]) res = 1 tmp = 1 for i inrange(1, n): if s[i] notin que: tmp += 1 else: while que and que.popleft() != s[i]: tmp -= 1 que.append(s[i]) res = max(res, tmp) return res deflengthOfLongestSubstring(self, s: str) -> int: # 双指针 + 哈希表 dic, res, i = {}, 0, -1 for j inrange(len(s)): if s[j] in dic: i = max(dic[s[j]], i) # 更新左指针 i dic[s[j]] = j # 哈希表记录 res = max(res, j - i) # 更新结果 return res
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defdeleteNode(self, head: ListNode, val: int) -> ListNode: ifnot head: return head cur = dummy = ListNode(0, head) while cur.next: if cur.next.val == val: cur.next = cur.next.next break else: cur = cur.next return dummy.next
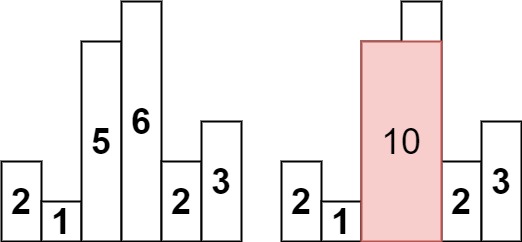
classSolution: defmaximalRectangle(self, matrix: List[str]) -> int: defmaximalhist(heights): heights = [0] + heights + [0] res, stack = 0, [0] for i inrange(1, len(heights)): while stack and heights[i] <= heights[stack[-1]]: tmp = stack.pop() if stack: weith = i - stack[-1] - 1 if (t := heights[tmp] * weith) > res: res = t stack.append(i) return res ifnot matrix: return0 m, n = len(matrix), len(matrix[0]) pre = [0] * n ans = 0 for i inrange(m): for j inrange(n): # if else 缩减 if matrix[i][j] != '0': pre[j] += int(matrix[i][j]) else: pre[j] = 0 ans = max(ans, maximalhist(pre)) return ans
classSolution: defasteroidCollision(self, asteroids: List[int]) -> List[int]: n = len(asteroids) stack = [0] for i inrange(1, n): while stack and asteroids[stack[-1]] > 0and asteroids[i] < 0: a = asteroids[stack[-1]] b = asteroids[i] if a + b < 0: stack.pop() elif a + b > 0: break elif a + b == 0: stack.pop() break else: stack.append(i) return [asteroids[i] for i in stack]
classSolution: defdailyTemperatures(self, temperatures: List[int]) -> List[int]: n = len(temperatures) stack, ans = [0], [0] * n for i inrange(1, n): while stack and temperatures[stack[-1]] < temperatures[i]: tmp = stack.pop() ans[tmp] = i - tmp stack.append(i) return ans